LOBSTER与MOG结合的目标检测方法
2018-12-20陈国军李开悦孔李燕
陈国军,李开悦,孔李燕,程 琰
(中国石油大学(华东) 计算机与通信工程学院, 山东 青岛 266000)
0 引 言
运动目标检测,即前景/背景分割,是计算机视觉中最基本的任务之一,尤其对于实时视频流的处理。在视频监控、行人检测、电影制作及人机交互等应用中,前景/背景分割作为一种预处理手段为后期图像处理奠定基础。
RGB-D相机提供的深度数据对室内场景下的目标检测具有重要的研究意义,因为它避免了基于颜色信息的目标检测方法带来的一些问题,如:光照变化,阴影及由于前景目标和背景颜色相似时产生的颜色伪装等。
但是,深度相机获取的深度图[1]分辨率低,噪声多,仅通过深度数据分割前景和背景,同样会产生一些问题。例如,由于物体表面反射、散射及遮挡等影响,深度测量并不总是有效;前景目标轮廓受到深度数据高水平噪声的影响;场景中的目标物体靠近背景时,产生深度伪装。
基于上述原因,有效地结合颜色和深度信息分割前景和背景[2-3],能够获得更加精确和可靠的分割效果,降低上述问题产生的影响。对此,文中提出一种有效的目标检测方法,该方法利用两种背景差分法分别作用于颜色图和深度图:基于改进的LBSP的背景差分法作用于颜色图;基于一种新的混合模型的背景差分法作用于深度图。将两种方法得到的二值图像以及差分后的Canny边缘检测图通过逻辑运算结合后,经过后期处理操作,将会提高目标检测的精度,获得更加完整的目标。
1 相关工作
随着计算机视觉技术的不断发展,运动目标检测技术得到了国内外专家学者的广泛关注,在传统的目标检测方法得到不断改善的同时,也出现了一些新的算法。在众多研究方法中,典型的有光流法、帧间差分法、背景差分法。
背景差分法(又称背景减法)是应用最广泛的目标检测方法,该方法检测速度快,提取的目标也相对完整,但其结果受背景模型的影响较大,因此,如何鲁棒性地构建背景模型并适时地更新该模型至关重要。近年来,国内外学者根据场景和应用情况的不同,对传统的背景差分法进行了改进[4-6],同时也提出一些新的方法。文献[7-9]中较为详细地描述了前景/背景分割算法。
Stauffer等提出的混合高斯背景建模方法[10]是背景建模方法的经典,该方法通常能够较好地适应复杂场景,后期许多学者对这种方法进行了改进(如Zivkovic[11]),算法的效率和鲁棒性都得到了提升。后来,许多学者提出了一些新方法,这些方法无需对视频序列的像素值进行任何概率估计的假设,其中包括Wang等提出的基于样本一致性(SACON)的背景建模方法[12],Barnich等[13]提出的基于像素点的视觉背景提取法(VIBE),Hofmann等[14]提出的PBAS(pixel-based adaptive segmenter)运动目标检测法。此外,Bilodeau等[15]提出在纹理空间中使用局部二值相似性模式(LBSP)检测运动目标的算法;St-Charles P L等[16]提出改进的局部二值相似性模式(LOBSTER)的运动目标检测算法。
随着Kinect相机的出现和使用,深度数据被应用到目标检测过程中。Kinect相机获取的深度图用图像表现出来,即为灰度图,因此,深度数据可以用到大多数基于颜色数据的背景差分算法中。文献[17-21]将深度数据引入背景差分法,结合颜色和深度信息来实现前景和背景的分割。Massimo Camplani等[17]提出基于两个单像素统计分类器结合的前景/背景分割策略,这两个分类器分别基于颜色和深度数据,通过一个加权均值将两个分类器的输出结果结合起来。同年,J. Gallego等[19]提出一个结合颜色和深度信息的前景/背景分割系统,该系统中使用了两种高斯混合模型,其中前景模型是基于颜色空间和深度空间的,两种模型通过贝叶斯框架结合起来。文献[19]的方法比较简单,在颜色图和深度图中用VIBE算法分别提取目标前景,然后用逻辑或运算将两者结合起来。文献[20]中提出的方法来源于文献[10],将深度信息和振幅信息作为额外的颜色信息加入混合高斯背景模型中。
尽管文献[17-21]都是结合颜色和深度数据检测运动目标,但这些方法在同时存在颜色伪装和深度伪装的情况下,取得的目标精度并不理想。因此,文中提出在颜色图和深度图中使用不同的背景差分法,得到对应的二值图,同时在颜色图中使用Canny边缘检测算法,将差分后的结果图与前面得到的两种二值图相结合,经过后期处理得到最终的检测目标。
2 背景差分
背景差分法相对于其他方法能更好地提取前景目标。文中的数据处理流程如图1所示。
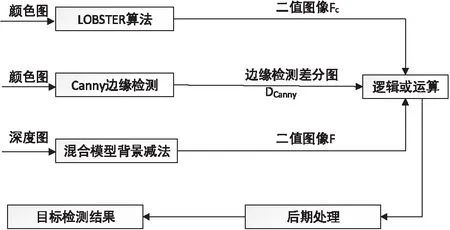
图1 数据处理流程
2.1 基于LOBSTER的背景差分法
基于LOBSTER的背景差分法是由St-Charles P L[16]等提出,是一种改进的LBSP算法。该方法借鉴了VIBE[13,22]算法的思想,加入邻域空间信息,并与LBP算子[23]进行结合。
计算LBSP的核心思想是比较中心像素点与邻域像素的相似性,然后进行编码,其计算公式为:
(1)
(2)
其中,ix,y表示中心像素(x,y)处的像素值,ix,y,p表示(x,y)的第p个邻域像素的值,文献[24]详细描述了LBSP特征值的中心像素及其邻域像素的位置信息;Tr为相对阈值,相似度阈值(Tr·ic)随着中心像素的变化而变化,相比恒定阈值,能够提高LBSP的精度。在计算LBSP特征值的过程中,如果ix,y与ix,y,p属于同一区域(称为intra区域),得到intra-LBSP算子;如果ix,y与ix,y,p不在同一区域(称为inter区域),得到inter-LBSP算子。
由于在LBSP特征值中加入了邻域像素和中心像素的对比,该方法对噪声更具鲁棒性。intra-LBSP和 inter-LBSP的计算,能够同时获得纹理和像素值的变化。
基于LOBSTER的背景差分法,与VIBE算法的思想一致,不同的是,文中将LBSP特征值和像素值同时用于背景差分算法中。此外,在对某像素(x,y)进行背景建模时,把该像素的LBSP特征值及其邻域像素的LBSP特征值同时加入到背景模型MLBSP(x,y)中,在与MLBSP(x,y)对应的原图像像素的背景模型Mc(x,y)中加入(x,y)的像素值。详细的背景建模过程可见文献[24]。当前帧中某一位置的像素与背景模型匹配的个数超过给定阈值Tmin时,该像素才最终被判定为背景。式(3)为像素类别的判断公式。
F(x,y)=
假定背景模型中(x,y)处的颜色样本集为{Mc1,Mc2,…,McN},intra-LBSP样本集为{MLBSP1,MLBSP2,…,MLBSPN};BG表示背景像素,FG表示前景像素;#{·}表示符合条件的像素个数;Tmin表示给定的比较阈值;p(x,y)表示当前帧在(x,y)处的像素强度,L1函数用来计算Mci(x,y)和p(x,y)之间的L1距离;LBSP(x,y)表示当前帧在(x,y)位置处的inter-LBSP算子,H函数用来计算MLBSPi(x,y)和LBSP(x,y)之间的汉明距离;TC是颜色阈值,TLBSP是汉明距离阈值。
2.2 基于混合模型的背景差分法
Kinect相机获取的深度数据与光照、阴影等因素无关,只与物体到相机间的距离有关,因而可以采用Stauffer[10]提出的混合高斯建模方法(简称MOG算法)作用于深度数据,构建基于深度数据的背景模型。虽然该方法能够通过调整像素的模型参数来适应受噪声影响的深度数据,但由于噪声点的值变化较大,用该方法来分割背景和前景物体,也会造成错误的检测结果。为降低噪声对目标检测精度的影响,文中分别为有深度值和无深度值的像素建立不同的背景模型,从而得到一个混合的背景模型。
对于深度数据中的无深度值的像素(称为“孔洞像素”),如果在连续的一段时间内,某一处的像素一直是孔洞像素,文中认为该点的像素为恒定孔洞像素,也被视为背景点。深度值表现了目标或背景物体与相机间的距离,因此,同一位置处的像素值在不同的时刻按照大小进行有序的排列,值最大的表明距离传感器最远,表现为背景,即μt=max(Dk),k∈[0,t];同时,如果前后两帧的像素值之差超过一定值,则说明有异常值出现。根据此原理,在前N帧图像背景建模过程中,背景模型不断更新,其步骤如下:
(1)背景初始化:B0=D0(第一帧为初始背景)
(2)背景模型更新:
if:Dt+1(x,y)=0
Bt+1(x,y)=0;count(x,y)++;
if:count(x,y)≥Thc
BN(x,y)=0;(恒定孔洞)
if:Dt+1(x,y)≠0
if:Bt(x,y)=0
Bt+1(x,y)=Dt+1(x,y);count(x,y)=0;
else:
if:|Dt+1(x,y)-Bt(x,y)|≥Thd·Bt(x,y)
Bt+1(x,y)=min(Dt+1(x,y),Bt(x,y));
else:
Bt+1(x,y)=max(Dt+1(x,y),Bt(x,y));
其中,Bt+1(x,y)、Dt+1(x,y)分别表示t+1时刻(x,y)处的背景值和当前深度值;count(x,y)为(x,y)处的计数器,记录像素值连续为0的帧数,用来判断该处像素是否为恒定孔洞像素;Thc表示孔洞的判定阈值(是一个表示帧数的值),其值的大小受到N值的影响,N越大Thc也越大;Thd为相对阈值,当背景发生变化时,阈值(Thd·Bt(x,y))也发生变化,用该阈值来判断当前像素值是否为异常值,更具鲁棒性。
经过上述背景建模产生一个背景模型BN,该背景在后期过程并不是一成不变的。从第N+1帧开始进行背景差分,同时背景模型(BN)也会更新。如果t时刻,背景模型中(x,y)处的像素为恒定孔洞,若t+1时刻(x,y)处像素值不为0,则该处像素被判定为前景像素,否则为背景像素;如果t时刻,背景模型中(x,y)处的像素不为恒定孔洞,t+1时刻该处像素的分类算法采用Stauffer[10]提出的混合高斯建模方法。其前景/背景分割具体步骤如下:
(1)if:Bt(x,y)=0(恒定孔洞)
Bt+1(x,y)=0;
if:Dt+1(x,y)≠0(只要当前像素不为0,那么视为前景)
FD(x,y)=255;
else:
FD(x,y)=0;(否则,视为背景)
(2)else:(MOG算法)
if:FD(x,y)=0(当前像素被判定为背景,背景模型中匹配的高斯函数参数更新)
υi,t+1=υi,t(1-α)+α;
else:(当前像素被判定为前景,不匹配的高斯函数中只有权值更新,其余参数不变)
υi,t+1=υi,t(1-α);
高斯分布重新排序:γi=ωi,t/σi,t;
前B个高斯分布被选为背景模型:
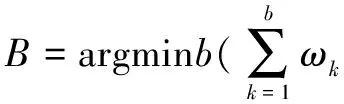
其中,MOG算法中背景模型的似然函数为:
其中,K表示高斯分布数量(一般取3~5间的数);α表示学习率(0<α<1),决定了适应场景变化的速度,场景变化越快,α越大;υi,t表示第i个高斯函数在t时刻的权值,其均值为μi,t,∑i,t表示其协方差矩阵。
2.3 Canny边缘检测差分图
由于深度图的分辨率低,边界受噪声影响较大,而Kinect获取的彩色图的分辨率高,边界更加完整。Canny的目标是找到一个最优的边缘检测算法。文中采用Canny边缘检测方法作用于彩色图,得到差分后的边缘检测图,为获取较好的边界,在边缘检测图上进行形态学膨胀操作,得到最终的Canny边缘检测差分图DCanny。计算公式为:
DCanny=ICanny-BCanny
(5)
其中,ICanny表示当前帧边缘检测图;BCanny表示作为背景的边缘检测图,文中取图像序列的第一帧为背景边缘检测图。
2.4 后期处理
经过2.1-2.3节后,用逻辑或运算将三部分得到的图像结合,得到较为完整的前景目标,但目标图像中可能会出现部分的噪声及孔洞,因此需要经过后期的处理操作。文中采用的后期处理操作包括:中值滤波(3*3)、腐蚀膨胀、4-邻域孔洞填充。
3 实验结果与分析
文中采用假阳率FPR、假阴率FNR、准确率Precision、召回率Recall、F-measure参数作为评价指标。为验证该方法的有效性,将MOGziv[11]、PBAS[14]、VIBE[13]算法分别作用于颜色图和深度图,得到对应的二值图,然后通过逻辑或运算将得到的二值图结合,得到三种方法的分割结果图。将用文中方法得到的结果图与上述三种方法得到的结果图以及单独用颜色和深度数据得到的结果图进行了对比。数据来自Massimo Camplani等提供的数据集,针对要解决的问题,只在ColCamSeq和DCamSeq图像序列上进行对比。
3.1 定性分析
ColCamSeq场景旨在测试当存在颜色伪装时文中方法的性能。图2(a)、(b)分别表示用Kinect相机获取的该场景中的颜色数据和深度数据,其中一个白色的盒子在一个白色平板前面移动,而白色平板属于背景。图3展示了不同算法在ColCamSeq上得到的分割结果图。从图中可以看出,单独使用颜色数据得到的FNR值较高,获取的目标不太完整,在目标区域出现空洞;PBAS算法和VIBE算法的FPR值较高,分割结果要比原目标区域大;而文中方法降低了FNR和FPR的值,使获得的目标更加完整,检测精度更高。

图2 Kinect采集的图像序列

图3 ColCamSeq第928帧分割结果
DCamSeq场景是为了测试当存在深度伪装时文中方法的性能。图3(c)、(d)分别表示该场景的颜色数据和深度数据,人的手逐渐靠近档案柜,而档案柜是背景中的一部分。从图4可以看出,由于图中存在深度伪装,单独使用深度数据得到的FNR值很高,检测到的目标不完整;同时,手和档案柜颜色也较相似,仅用颜色数据取得的分割效果并不十分理想,对比其他方法得到的结果精度也不理想;而文中方法在结合Canny边缘检测的差分图后,得到的目标轮廓更加完整,FNR和FPR值都相对较低。
综上所述,文中方法在存在颜色伪装和深度伪装的情况下,得到的分割效果要优于对比的几种方法。

图4 DCamSeq第974帧分割结果
3.2 定量分析
表1、表2展示了文中方法与对比方法在ColCamSeq和DCamSeq图像序列上的精度分析。在数据集中提供了手工绘制的真值图,选取其中一部分真值图像与文中方法所得结果图进行了对比分析,其中选取ColCamSeq中第847帧到1 081帧中的39帧,在DCamSeq中选取第839帧到1 199帧中的61帧。由于数据集中的数据为图像序列,所以结果分析以参数的平均值形式表现。
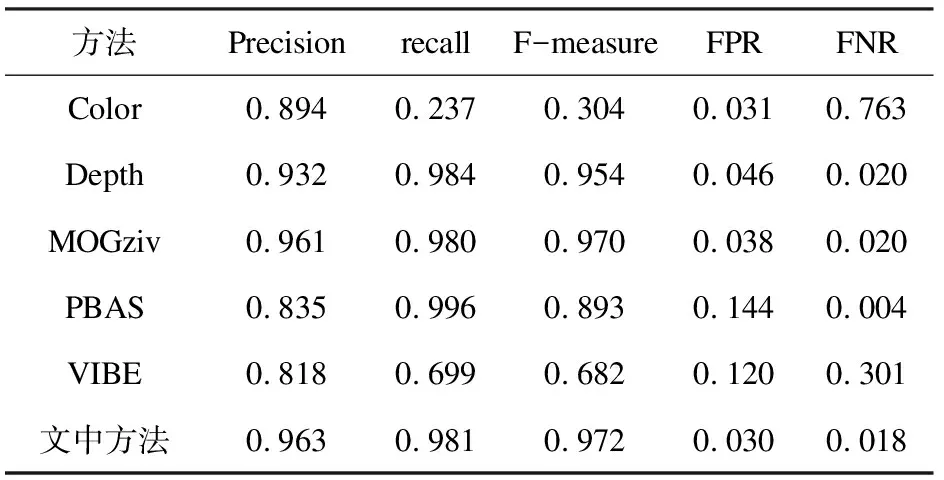
表1 ColCamSeq的检测精度
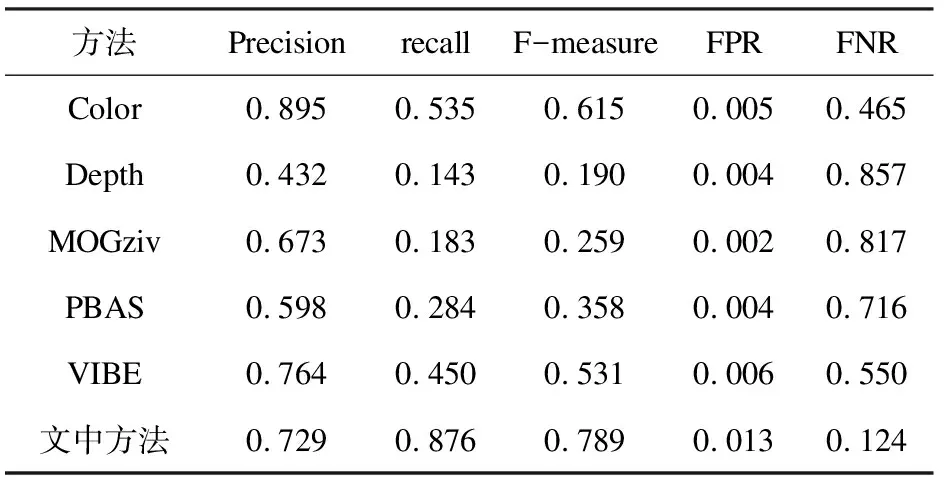
表2 DCamSeq的检测精度
表1表明,在存在颜色伪装的情况下,Z. Zivkovic提出的混合高斯背景建模的方法能够取得较高的Precision、Recall、F-measure值,其检测结果较好;文中方法得到的FPR和FNR值比MOGziv方法都低,其他的参数结果也都优于Z. Zivkovic提出的方法。
表2表明,在存在深度伪装的情况下,只使用颜色数据取得的结果较好,虽然文中方法取得的FPR值较高,但Recall和F-measure值要明显高于其他对比方法。
根据上述分析可知,文中方法在存在颜色伪装和深度伪装的情况下,均能较好地分割前景目标和背景,而且分割精度较高。
4 结束语
针对场景中存在的颜色伪装和深度伪装问题,提出一种融合颜色和深度数据检测目标的方法。与其他方法不同的是,文中在颜色和深度数据分别采用不同的目标检测方法,在颜色图中用基于LOBSTER的背景差分法,得到分割后的二值图;在深度图中用提出的基于混合背景模型的背景差分法,得到分割后的二值图;同时,还用差分后的Canny边缘检测图来补充目标轮廓;最后,通过形态学滤波、孔洞填充、腐蚀膨胀等后期操作完善分割结果。实验结果表明,该方法在测试数据集上比其他对比方法获取的目标更加完整、精度更高。同时,在结果图中噪声点依然存在,尽管在2.2中对孔洞像素单独进行背景建模,也处理了部分异常值,减少了部分噪声,但并未对差分过程中出现的异常值进行处理,因此,增加了结果分析中的FPR值。后期工作中会针对上述问题做进一步改善。同时,还会通过超像素分割方法,来加快算法执行的速度,从而提高目标检测的实时性。
