基于狄利克雷多项分配模型的多源文本主题挖掘模型
2018-12-14徐立洋黄瑞章陈艳平钱志森黎万英
徐立洋,黄瑞章,3,陈艳平,钱志森,黎万英
(1.贵州大学 计算机科学与技术学院,贵阳 550025; 2.贵州省公共大数据重点实验室(贵州大学), 贵阳 550025;3.计算机软件新技术国家重点实验室(南京大学), 南京 210093)(*通信作者电子邮箱rzhuang@gzu.edu.cn)
0 引言
在互联网发展早期,网络上可获取文本数据的渠道(数据源)较少,文本挖掘任务主要面向单源文本数据。随着互联网的快速发展,特别是移动互联网的普及率越来越高,几乎每个人都能上网获取资讯和发表观点, 因此出现了各种各样的文本数据生产渠道,如各种社交媒体、新闻门户、博客及论坛等。这些渠道时刻都在产生海量的文本数据,同时对这些文本数据源进行主题信息提取通常具有比较重要的应用价值, 如在网络新闻采编和网络舆情分析应用中,需要知道在每个渠道的主题分布,以及某个关注的主题在每个渠道的表现方式等。

此外还需要解决的一个问题是如何自动确定每个数据源中的主题个数。传统主题模型假设主题个数是已知的,因此在建模前需要事先设定需要学习的主题个数。通常对单源文本数据事先估计主题个数比较容易,但多源情况下,由于不同数据源之间可能具有较大差异,因此人为事先对每个数据源设定合理的主题个数比较困难。Huang等[2]指出,设定不合适的主题个数可能会严重影响模型准确率, 所以针对多源数据的模型能够根据每个数据源的数据特征自动确定主题个数是非常有必要的。
本文模型尝试通过扩展狄利克雷多项分配(Dirichlet Multinomial Allocation, DMA)[2]模型来解决上述三个问题。DMA模型是一个有限混合模型,当将其混合元素的数量趋于无穷大后,可以近似为一个狄利克雷过程混合(Dirichlet Process Mixture, DPM)模型[5],DPM是一个常用的非参贝叶斯模型,具有良好的聚类性质,在对聚类个数没有先验知识的情况下,能够自动确定最终的类别个数[6]。本文提出的多源狄利克雷多项分配(Multi-Source Dirichlet Multinomial Allocation, MSDMA)模型是在DMA模型的基础上作了一些扩展,使其能够学习主题知识结构的同时,保留主题在不同数据源中的词分布特点,并保留了DMA模型的非参聚类性质,最后利用Blocked-Gibbs参数学习方法自动学习出K值[2]。
总的来说,本文所做的贡献主要有如下3点:
1)提出面向任意数量数据源的主题挖掘模型,解决传统主题模型无法在多源情况下根据数据源自身特点进行主题挖掘的问题;
2)通过主题和词空间的共享实现数据源之间的信息互补,辅助提升高噪声、低信息量的数据源的主题发现效果;
3)根据数据源的数据特点自主学习出每个数据源的主题个数。
1 相关工作
主题挖掘一直是文本分析领域中的一项重要工作,它可以将文档从高维的词项空间转换到低维的主题空间,从而可以在主题空间实现对文本的聚类和分类以及文本核心内容提取等工作。目前研究者们已对单源文本数据的主题挖掘方法作了大量研究。特别是2003年提出的潜在狄利克雷分配(Latent Dirichelt Allocation, LDA)模型[9],对主题模型的发展具有十分重要的意义,近年来主题模型相关的工作大多是对LDA模型的扩展,但大多数模型主要是解决单源文本数据的主题挖掘问题。随着文本数据来源渠道的不断丰富,越来越多的研究者开始关注对多源文本数据(或多语料库)的主题建模问题。 然而,大多数研究者对此类问题的研究兴趣点在于如何通过数据源之间的信息辅助提升目标数据源的主题发现效果[8],本质上还是为了解决单一数据源的建模问题。例如在文献[11]中提出的二元狄利克雷模型(Dual Latent Dirichlet Allocation, DLDA)通过引入辅助数据源对目标数据源提供辅助信息,从而提升目标数据源的主题发现效果;文献[8]中提出的DDMAfs(Dual Dirichlet Multinomial Allocation with feature selection)模型通过引入长文本数据集来辅助提升短文本数据集的聚类效果;文献[12]中将数据来源指定为Twitter和雅虎新闻两个语料库。以上提到的研究内容均对数据源的数量或来源作出了严格的限定,其目的是为了更好地对目标数据源的数据进行主题建模,本质上并没有真正解决多源文本数据的主题建模问题。
在针对多源文本数据的主题模型中,文献[13]提出的mLDA(multiple-corpora LDA)模型通过扩展LDA,使不同数据源共享相同的主题-词分布参数,从而使得主题知识对于整个语料库来说是统一的,忽略了主题在不同数据源中所特有的特点;文献[14]中提出的mf-CTM(multi-field Correlated Topic Model)使不同领域的语料库共享相同的主题分布参数,但不同语料库具有独立的主题-词分布参数,这虽然完全考虑了主题在不同数据源中的特点,但难以保证同一个主题在不同数据源中具有概念上的一致性;文献[1]提出的Probability Source LDA模型同时扩展了LDA的主题分布参数和主题-词分布参数,让数据源之间可以共享主题分布以及主题-词分布,使得模型可以学习出每个数据源的主题结构,并保证主题在数据源之间具有一一对应关系,同时保留了主题在数据源内的特征,这与本文提出的MSDMA模型的目的相似,但该模型需要有数据源分布的先验知识,增加了建模的复杂度。此外,分层狄利克雷过程(Hierarchical Dirichlet Process, HDP)模型也常用于对多源文本数据的分析[4],其主要目的是发现不同源数据中主题的隐含关联模式。
上述提到的大多数方法均需要事先确定每个数据源的主题个数K,而即使在单一数据源的情形下确定一个合理的K值也是比较困难的,这需要建模者浏览所有的文档数据才能作出合理的估计,因此在多个数据源的情况下显得更为困难。此外,不合理的K值估计可能会严重误导模型的聚类过程,最直接的解决办法就是用不同的K值训练模型,然后选取测试数据集中使得似然概率最高的一个[16]。另一种方法是为K设定先验参数,然后计算出K的后验分布[17]。文献[2] 基于DMA模型,利用Blocked-Gibbs对模型参数进行采样学习,当进入一个新的观测数据时,该数据的类别(主题)可以从已经存在的类别中生成,也可以生成一个新的类别。
2 多源狄利克雷多项分配模型


图1 多源狄利克雷分配模型的图模型表示

符号说明α主题分布的狄利克雷先验参数θ全局主题的多项式分布参数Zsm数据源s中分配给文档m的主题,s=1,2,…,S, m=1,2,…,Msxsm数据源s中第m篇文档S数据源数量Ms数据源s中的文档数量, s=1,2,…,Sβk主题k的词分布的狄利克雷先验参数, k=1,2,…,Kφsk主题k在数据源s中的词分布参数,s=1,2,…,S, k=1,2,…,KV词典大小K主题个数Nsk数据源s中属于主题k的文档数量Nsk,w数据源s中,单词w被分配给主题z的次数,s=1,2,…,S, k=1,2,…,K, w=1,2,…,V

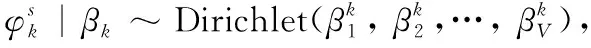
2)采样θ|α~Dirichlet(α/K,α/K,…,α/K);
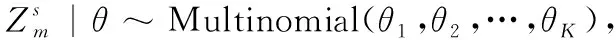


(1)
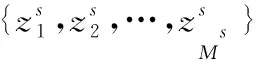
(2)
其中
因此,当对所有数据源中的文档进行主题分配后,得到整个语料库的近似生成概率:
(3)
3 基于Blocked-Gibbs的参数学习方法
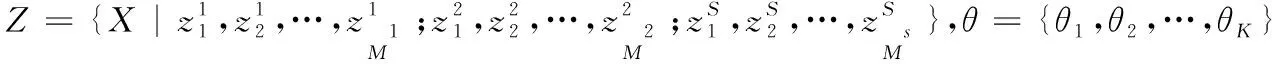
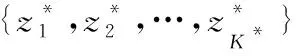
(4)
2)以下列狄利克雷参数采样新的θ:
(5)
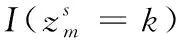

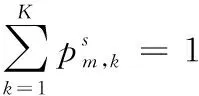
(6)
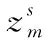
4 实验与分析
本章分别设置了两组实验来验证本文方法: 第一组实验使用了模拟数据集对模型性能进行测试; 第二组使用Paper和Twitter的真实数据集。
4.1 度量标准
两组实验中,本文均使用归一化互信息(Normalized Mutual Information, NMI)[18]作为主题发现效果的度量标准。NMI通常被作为聚类模型聚类效果的评价指标。由于模型假设每篇文档属于一个主题,因此同一个主题下面的所有文档可看作一个类,所以利用NMI来进行度量,其计算公式如下:
其中:D是文档篇数,dh是实际类别h中的文档篇数,cl是聚类类别l中的文档篇数,dhl是同时属于实际类别h和聚类类别l的文档篇数。NMI的取值范围为0到1,NMI值越接近1说明聚类效果越好,当NMI=1时,聚类结果完全与实际类别相符[2]。
4.2 模拟数据集实验
4.2.1 模拟数据集生成方法介绍
本文采用文献[19]中提到的利用狄利克雷过程的Stick-Breaking方法来产生模拟数据。首先,设定K个主题,记为{π1,π2,…,πK}。每个πK表示为一个基于单词的多项式分布,记为πK=(u1,u2,…,uV),其中uw表示单词w在主题k中出现的概率大小,V表示词典长度。对其中一个主题k的生成过程如下:
1)以均匀概率从词典中随机抽出N个词并按抽取的先后顺序进行标记,得到长度为N的单词序列(w1,w2,…,wN)。
2)对每个单词赋予一个概率值:
a)对第一个单词w1,令u1=l1,其中l1~Beta(1,ξ)
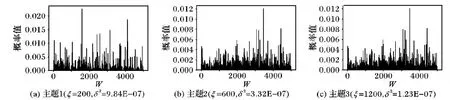
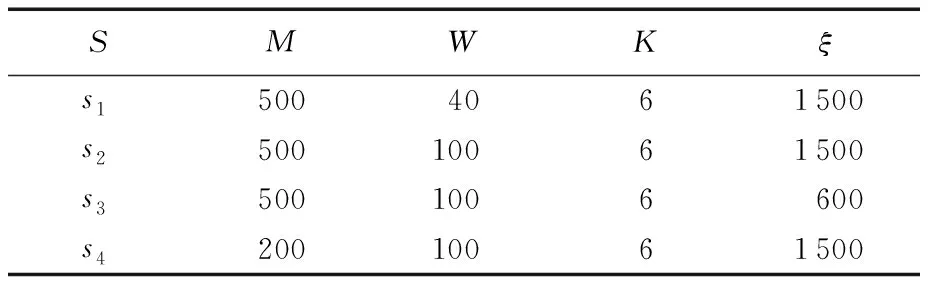
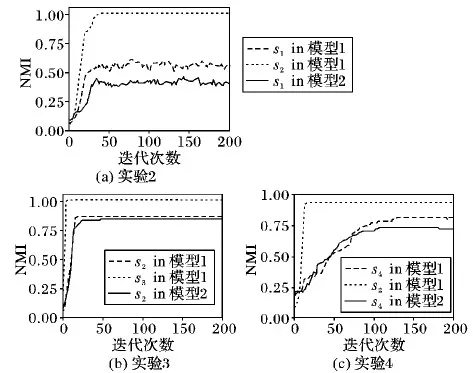
b)对单词wl(2≤l 需要注意的是,在上述过程中,参数的大小决定了主题中单词概率的离散程度: 离散程度越高,概率越倾向于集中在少数单词上面,主题词就越明显; 离散程度越低,每个单词分配到的概率越均匀,主题词越不明显。对应地,当ξ值越大时,主题词越不明显,模型越难识别出该主题。 图2为不同ξ得到的词概率分布图,可见随着ξ的增大,词的概率分布越均匀,概率值的方差越小。 图2 ξ 的取值对模拟主题的词分布的影响 4.2.2 模拟数据集介绍 根据上述方法,以5 000维词典,生成4个不同类型的数据集,每个数据集的具体参数如表2。 表2 模拟数据集参数说明 表2中M为每个数据集的文档篇数,W为数据集中每篇文档的单词数量,K为每个数据集的主题个数。以s2(M=500,W=100、ξ=1 500)数据集为标准数据集,其信息量和噪声水平为标准情况;s1中每篇文档的单词数量限定为30,可用来表示一个短文本数据集;s3的ξ较小,因此可以表示一个主题信息明确的数据集,即主题-词分布中噪声词的概率较小;s4中的文档篇数最少,仅为200篇,因此可以表示一个缺少样本信息的数据源。 4.2.3 模拟数据实验结果 该部分利用模拟的4个数据集做了4组不同的实验。 实验1中,用MSDMA模型同时对模拟生成的4个数据源进行主题聚类,聚类结果如图3所示。 图3 MSDMA(s1,s2,s3,s4)的NMI和K值变化轨迹图 从图3可以看出,图3(a)中每个数据源的NMI值随着迭代次数的增加而增加,由于s3的主题信息比较明确,因此NMI值提升速度较快并率先达到1; 而s1由于是短文本数据集,每篇文档的有效信息量较少,因此NMI值较小。图3(b)中噪声最低的s3能准确地将主题个数收敛到6时,与实际情况相符。 实验2中,建立了两个模型:模型1的数据包含s1和s2,即长文本与短文本的融合。模型2的数据仅有短文本数据集s1。实验结果如图4所示,模型1中短文本数据源s1的NMI值整体高于模型2中s1的NMI值。为了消除随机因素影响,本文同时对两个模型训练了10次,每次迭代200次,得到模型1中短文本的NMI比模型2中的提升约4%,说明该模型能通过数据融合,利用长文本数据源的信息辅助短文本数据源,提升短文本的主题发现效果。 图4 MSDMA中不同数据源组合方式下的NMI变化轨迹 实验3中,同样建立了两个模型:模型1包含s2和s3两个数据源,即高噪声与低噪声数据源融合。模型2的数据仅包含s2。图4(b)的结果表示,模型1中s2的NMI值明显高于模型2中s2的NMI值。为了消除随机因素的影响,本文同时对两个模型训练了10次,每次迭代200次,得到模型1中s2的NMI值明比模型2中s2的NMI值提升约10%。实验结果表明,该模型能通过数据融合,利用低噪声数据源的信息辅助高噪声数据源从而提升主题发现效果。 实验4中也建立了两个模型:模型1的数据包含s2和s4,模型2的数据仅包含s4。s4仅包含200篇文档,与s2相比信息量较少。实验结果见图4(c),模型1中s2的NMI值明显高于模型2中s2的NMI值。通过10次的模型训练得到模型1中s2的NMI值比模型2中的提升约3.6%,说明在该模型中,在相同数据质量的情况下,数据量较少的数据源能够利用数据量较多的数据源信息。 4.3.1 数据集介绍 本文使用了以下两个真实数据集AMpaperSet和TweetSet来对本文提出的模型进行测试: AMpaperSet 该数据集是将文献[20]中使用的AMiner-Paper数据集中的论文摘要截取出来形成的一个数据集,并从中随机抽取了1 500篇作为实验数据集,其中包含了三个不同的研究领域,分别是“graphical image”“computer network”和“database research”。 TweetSet 本文从“JeSuisParis”“RefugeesWelcome”和“PlutoFlyby”这三个热门话题的Twitter中包含的URL爬取了5 577 篇文章,同样随机抽取1 500篇得到TweetSet语料库。 将得到的数据集均去除停用词以及在全局语料库中出现频率低的词[21]。 表3 真实数据集描述 4.3.2 真实数据实验结果 本文设置了两个实验来验证模型在真实数据集上有效性。 实验1中,将MSDMA模型与主流的传统文本聚类模型进行了对比,来验证MSDMA模型在主题建模过程中考虑数据源自身的特点与传统主题模型相比,能够更有效地对主题进行刻画。首先考察了K-Means文本聚类模型和分层狄利克雷过程模型(HDP)在这两个数据集上的主题挖掘效果,并将它们设定为基线模型, 其中HDP模型是一个常用的非参贝叶斯模型,能够针对多组文本数据的聚类和分析[15]; 然后对比了GSDMM(Gibbs Sampling algorithm for the Dirichlet Multinomial Mixture)模型[22],该模型假设每篇文档只属于一个主题,这与本模型的假设类似。各模型的聚类效果如表4所示(表中结果均为10次训练结果的平均值)。 表4 4种模型在AMpaperSet和TweetSet数据集上的NMI值 表4结果表明MSDMA的聚类效果明显好于基线模型K-means和HDP。GSDMM单独对AMpaperSet建模得到的NMI略高于MSDMA,但对TweetSet的NMI却明显低于MSDMA, 证明了在MSDMA建模过程中,TweetSet能够借鉴AMpaperSet中的主题知识辅助自身进行主题发现。图5是MSDMA模型学习出的每篇文档的主题。 图5 AMpapreSet和TweetSet中每篇文档所属主题的预测结果 从图5中可看出,从AMpaperSet中发现2个主题,聚类的类别标号为k1和k11; 从TweetSet中发现6个明显的主题,类别标号分别是k2,k5,k11,k13,k15和k23。 实验2对MSDMA模型学习出的主题在每个数据源中的词分布形式进行了研究,以验证模型能够保留主题在数据源中的用词特点。图5中可以看出,模型对AMpapreSet的聚类效果较好,因此本文从AMpapreSet中选取了2个聚类效果明显的主题和,同时选取TweetSet中相同编号的主题,并展示了两个数据源中每个主题出现概率最高的15个词: 主题1主要描述了计算机网络(computer network)相关的内容,AMpaperSet对该主题的描述更偏向于专业的计算机网络技术,如模型、算法、架构等方面;而TweetSet中则更偏向于网络安全、隐私、邮箱等社会话题。 主题2是与图形图像(graphical image)相关的主题,在AMpaperSet中对该主题的描述也更偏向于计算机图形学专业术语;而在TweetSet中,则表现为与旅行、拍照、穿着等生活化场景相关。 表5 同一编号的主题在两个数据源中的词分布差异比较 该实验表明,与传统主题模型只能对某主题学习出统一的词分布相比,本文提出的MSDMA模型能够保留数据源的整体特点,学习出该主题在各数据源中特有的词分布形式。 本文针对多源文本数据,提出了一种基于狄利克雷分配的多源文本主题发现方法。该方法在主题建模过程中能够有效利用数据源特征,根据数据源特点发现同一个主题在不同数据源中的词项分布的区别,同时利用数据源之间的信息互补在一定程度上解决噪声和信息量不足的问题。此外传统主题模型的训练结果较大程度依赖于主题个数K的经验设定,本文提出的基于DMA模型的方法保留了DMA模型的非参性质,利用Blocked-Gibbs参数学习方法自动学习出K值,且每个数据源的K均考虑了数据源自身数据特点。最后通过实验验证了该方法同时对多源文本进行主题挖掘的效果优于主流模型。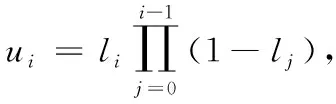

4.3 真实数据集实验




5 结语
