基于深度置信网络Otsu混合模型的自动云检测算法
2018-12-14尹浩宇刘颖健
邱 梦,尹浩宇,陈 强,刘颖健
(中国海洋大学 计算机科学与技术系,山东 青岛 266100)(*通信作者电子邮箱liuyj@ouc.edu.cn)
0 引言
国际卫星云气候计划(International Satellite Cloud Climatology Project, ISCCP)提供的数据表明,在使用卫星遥感技术获得的地球信息中,地球表面50%以上被云覆盖,云量占了很大的比率。云是一种重要的气候要素,云数据的收集和有云区域的检测可以帮助分析天气情况、环境变化,了解气候特征,对海表/地表大气研究以及海表/地表反演工作有很重要的意义。对云的检测与分类可以帮助有效防范与云相关的自然灾害,如台风、暴雨、雷电等,以减少生命财产损失。在某些研究领域,如海表温度反演,大量云的存在会影响遥感数据的可用性,从而降低数据的利用率, 因此,云检测问题已经成为卫星遥感数据应用首要解决的问题,做好云检测工作能为后续云剔除、云分类以及其他领域遥感数据的应用打下坚实的基础。
传统的云检测方法主要以阈值分割方法为主,云在可见光和近红外光谱中表现的特性是高反射率低亮温,利用这一特性,可以选择合适的阈值确定像素上是否有云[1-2]。随着遥感数据数量和种类的增加以及对云检测精确度要求的不断提高,固定阈值方法已经无法满足要求。动态阈值相对于固定阈值具有更好的灵活性、适应性以及可扩展性,出现了一些自动分割或自动阈值云检测方法[3-4]取代原有的固定阈值方法, 但是总体来说,目前已有的动态阈值方法自动化程度仍然较低,很难满足云检测的需要。 另一类传统云检测方法主要是根据云的纹理、形状、灰度等物理特征来进行分类。支持向量机(Support Vector Machine, SVM)[5]、Bag-of-Words 模型[6]、贝叶斯时空算法[7]以及逐步求精算法[8]等分类算法在云检测方面得到了较好的应用, 但是依据云的物理特征进行分类时,计算量大且较为复杂,需要的数据种类也较多。近年来,一些新兴的智能方法开始应用于云检测领域,主要是利用深度学习神经网络(Neural Network, NN)进行分类[9-10],综合多种算法模型也成为新的趋势[11-13]。新兴的智能云检测方法相对传统检测方法自动化程度得到了一定的提升,但是泛化能力相对较弱,尤其在数据受冰雪影响较大时,检测结果会产生较大偏差。
为了解决云检测领域存在的上述问题,本文首先针对云的遥感特性以及遥感数据特点进行分析,找出合适的判据以及判断方法,进行云的二值分割工作; 然后将深度置信网络(Deep Belief Network, DBN)与最大类间方差法Otsu相结合,提出一种自动云检测算法框架DOHM(DBN-Otsu Hybrid Model),采用自适应阈值代替传统人工标定固定阈值,从而实现云检测的全自动化。通过与SVM、概率神经网络(Probabilistic Neural Network, PNN)、神经网络(NN)、朴素贝叶斯分类器(Bayes)和普通DBN算法等5种常用方法进行实验对比,无论从可视化定性分析还是定量分析的角度,DOHM算法的云检测结果均表现最优。
1 云检测研究基础
1.1 云的遥感特性
在多光谱扫描辐射计得到的遥感数据中,每个像素点(Pixel)上的信息是该点的辐亮度信息,显示了在一定谱段内该像素点单位面积的辐射能量。组成成分不同,在光谱谱段的反射率等参数就会不同,所以可以利用这些特征来区分云和其他物质,具体可以利用以下三种特性:
1) 对比度特性(Contrast Signature), 利用不同成分在太阳光光谱波段(0.3~3 μm)的反射性能不同和在热红外波段(3~20 μm)红外辐射不同来区分不同的物质,反射性能与成分有关,红外辐射与温度有关。在本文涉及的海域上空云检测中,云和海表的反射率差距较大,相对于海表,云的反射率很高,在热红外波段,海表和云的亮温明显不同,利用这一点可以进行云区域的检测。
2) 光谱特性(Spectral Signature), 主要是同一种物质在不同波段的反射率有一定的区别,在热红外波段反射率随波长变化。云在每个波段的反射率较为均匀,但薄云在短波光谱段上反射率较强。
3) 空间特性(Spatial Signature), 主要是指不同物质在空间上表现出不同的变化规律。海表在面积几千平方公里的空间反射率变化不大,而云在几百米的空间反射率变化就很大。
1.2 数据集介绍
本文云检测所采用的数据集是AVHRR数据集,AVHRR是搭载在美国NOAA系列卫星上的高级甚高分辨率辐射计,空间分辨率能达到星下1.1 km。目前AVHRR已经由4个通道(channel)发展为5个通道,包含了可见光红色波段、近红外、中红外、热红外等多个波段,每一个通道都有不同的波长数据,总体来说,通道1和通道2为反射率,通道3~通道5为亮温数据,本文的研究中,实验数据选取经纬度范围分别为105.0°E~145.0°E, 10.0°N~50.0°N,具体如图1所示。

图1 实验数据经纬度范围
1.3 基本方法
1)DBN。
DBN起源于机器学习,它由Hinton在2006年提出,是深度学习神经网络中的一种。DBN模型由多个RBM (Restricted Boltzmann Machine)网络组成,通过训练的方式调节各个神经元之间的权重,可以让整个网络按照最大概率来生成训练数据。DBN由多层神经元组成,神经元有显性神经元和隐性神经元两种,显元用于输入,隐元又叫特征检测器(feature detector),用于捕捉来自输入层的数据的相关信息,提取特征。多个RBM堆叠便组成了DBN的基本结构。
DBN的训练采用逐层无监督训练法,每一层的RBM都单独采用无监督的方式进行训练,先充分训练第一个RBM,固定第一个RBM的权重和偏移量,以此重复多次,确保输入特征向量在映射到不同的特征空间时,能够最大程度保留原本的信息,这一步叫作“预训练”,预训练之后要进行微调(Fine-Tuning),微调过程在DBN的末层,主要是设置一个分类器,用于接收RBM的输出作为分类器的输入,采用有监督的方式训练分类器,训练过程中用Contrastive Wake-Sleep 算法[14]进行调优,能够准确高效地重构训练数据。
2)Otsu算法[15]。
最大类间方差法又叫大津法、Otsu算法,是一种经典的非参数无监督自适应阈值分割方法,该方法计算方便,不受图像亮度和对比度等因素的影响,是目前图像阈值二值化最理想的算法。Otsu算法根据目标和背景的灰度特征,将目标数据分为背景和前景两部分,计算两者之间的类间方差,类间方差可以用来说明灰度分布是否均匀,方差越大证明两部分之间的图像区别越大,当有一些目标和背景互相被检测错误时,两类之间的方差会减小,在Otsu中,一幅图像的灰度值为[0, 1, …,X-1],每个灰度值i像素个数为ni,总像素数是N,图像灰度均值为μr,Otsu算法就是确定一个阈值T,将图像上的像素点分成C1和C2两类,并且使得式(1)最大:
(1)
其中:ω1(T)和ω2(T)是事件发生的概率,μ1(T)和μ2(T)是内平均值,σ1(T)和σ2(T)是C1和C2的方差,分别定义为式(2)~(7):
(2)
(3)
(4)
(5)
(6)
(7)
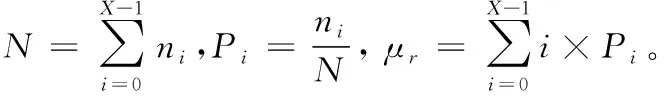
2 云检测研究
2.1 云检测算法框架DOHM
针对已有检测方法存在的问题,本文提出了DOHM算法模型,将深度学习神经网络DBN和自动阈值分割算法Otsu相结合,在保留了DBN算法的优点的同时,实现了阈值的自动选取。
DOHM框架的输入是维度为9的特征向量(v1~v9),分别为:5个通道数据、通道2和通道1的比值、通道3和通道4的差、通道3和通道5的差以及通道4和通道5的差。数据输入后便进入DBN训练部分,训练部分用于调整网络结构以达到最优,最后进入Otsu以自动确认阈值。
DOHM算法具体步骤如下:
1)输入特征向量(v1~v9),输入之后进行网络训练、调参和微调,用来确定最终的网络结构。以云检测为例,特征向量输入之后经过DBN的训练,最终确定的最优的网络结构为2层,第1层有6个节点,第2层有3个节点,相当于有2个RBM,各有6个、3个节点,训练过程中第1个RBM的输出作为第2个RBM的输入,各节点设置节点之间的权重,训练出来的参数将会传递给对应的NN。
2)在实验进入DBN最后一层时,加入Otsu算法,将DBN的参数作为Otsu算法的输入,以自适应的方法来自动确定阈值,根据这个阈值,能够确定最终数据的分类。
3)得到最终结果。
2.2 云检测实验设计
云检测实验步骤可以大致分为3部分: 第1部分是对输入的AVHRR(Advanced Very High Resolution Radiometer)数据进行预处理,包括数据的清洗、人工标注有云无云区域以及数据集的建立,数据清洗用来剔除无效数据,人工标注用来对像素点进行标记,标记后的数据中每个像素点都会有一个标签来表明自己是否是有云像素点,数据集的建立应当根据实验目的来选择合适的训练集和测试集;第2部分是特征提取,依据云的遥感特性以及DOHM中的网络特性来选取合适的特征,作为DOHM算法的输入;第3部分是DOHM的训练过程,这一部分主要是对DOHM网络进行训练,并不断调整网络结构以达到最优的实验结果,训练之后的DOHM便可以对输入进来的数据进行自动云检测工作。
1)预处理。
实验所用数据是AVHRR通道数据,涵盖了AVHRR的所有5个通道。地理位置上选取经纬度范围为105.0°E~145.0°E, 10.0°N~50.0°N的数据,如图1所示,时间跨度上包含了2011年全年的数据。
通道1~通道5的实验数据首先要进行一定的预处理,利用数据清洗判断是否是无效数据,若是无效数据标记并抛弃,得到有效数据后,进行第1步处理,即有云区域和无云区域的提取,提取后进行人工标记作数据标签,并根据特征数据库分别建立有云数据库和无云数据库,建立好数据库后设计实验所用的数据集,本实验将2011年12个月份的数据分别按月份标号1~12,作为实验所用数据集,按照实验规划分别建立训练集和测试集,根据特征数据库特性,提取特征向量作为DOHM的输入,预处理阶段步骤如图3所示。

图3 预处理步骤示意图
本文云检测实验将数据分为两部分用于交叉验证,训练集(Training set)和测试集(Testing set),训练集用于DOHM模型的训练,测试集用来检验网络分类的效果,训练集用于DOHM模型的训练,测试集用来检验网络分类的效果,本文实验将12个月的数据集分为6组,每组中选取了数据差别较大的两个月,具体如表1所示,每组中的两个月交替作为训练集和测试集,例如组1:1月作为训练集,7月作为测试集,然后交替,7月作为训练集,1月作为测试集,以此类推,一共进行了12次验证实验。
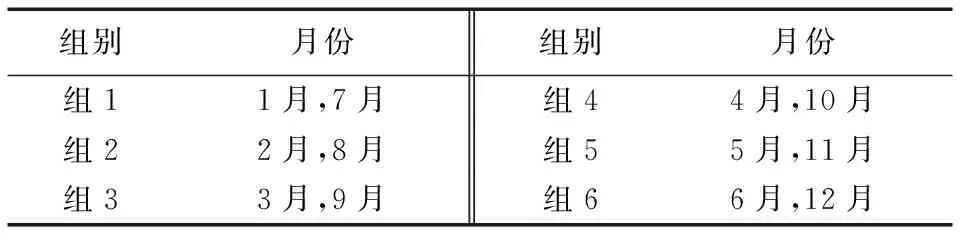
表1 数据集分组
每个数据集里都有一定比例的有云数据和无云数据,这样可以防止网络被严重偏置。由于目前存在的云检测算法都存在着一定的误差,所以为了保证数据的准确性,本文实验采用人工手动标记法来标定有云区域和无云区域。
2)特征提取。
传统的云检测方法大多只选取某个通道或是某几个通道作为输入,从中提取特征向量,输入数据的单一容易导致网络训练不充分,致使检测结果出现偏差。为了克服这一缺点,本文选择了AVHRR全部5个通道数据,并且新构建了通道2和通道1的比值、通道3和通道4的差、通道3和通道5的差、通道4和通道5的差这4个特征作为DOHM的输入,如表2所示。
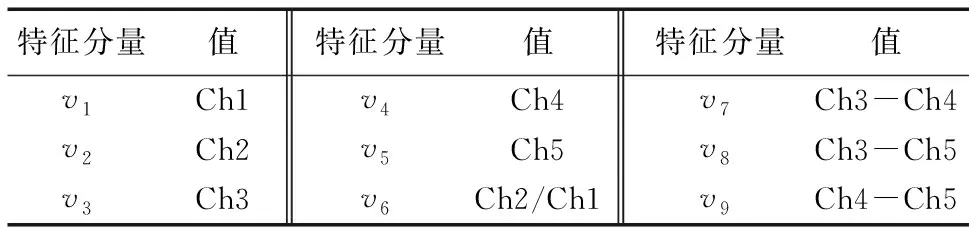
表2 DOHM的输入特征向量
由于大气中存在水汽,所以不同通道中的反射率和发射率也不同,总体来说,利用反射率参数要比发射率参数更能够有效消除数据上的不确定性。依据文献[16]可知,无云区域通道2和通道1的反射率之比在0.75以下,比值大于0.9小于1.1的是有云海域,所以,v6的阈值可以设置为0.8~0.9,薄云相对于大气来说,能够产生将对较大的差值,所以通道4和通道5的差值可以主要用来检测薄云,有云区域和无云区域在通道3和通道5表现出不同的特性,云在通道3的反射率更高而晴空在这个波段表现出很高的透明性,薄云在通道3上光学透射率会更高,此外,由于普朗克黑体辐射方程是非线性的,因此能够产生更大的v8差值,不仅在白天,夜间v8也可以用来作为判断是否有云的一个判据。
3)DOHM训练过程。
训练过程分为预训练和微调两步。文献[17]提出了一种逐层无监督的贪婪预训练方法,目的是能够在映射到不同的特征空间时,尽量保留最多特征向量的特征信息,输入向量(v1~v9)和第一层隐层单元构成了第一个RBM,第一个隐层单元含有6个神经元节点,训练之后将会得到一系列的参数传递至第2个RBM,第2个RBM单元含有3个节点,前1个RBM的输出是后1个RBM的输入,如此重复,直至网络训练完全。
预训练之后是微调,与预训练阶段的无监督训练方式不同,微调是有监督的训练过程,在每一层的RBM中,权值是单独的,即权值只要在该层达到最优的效果即可,而不用去保证整个网络达到最优值。DBN在训练开始前会随机初始化权值,特殊的训练方式使得DBN避免了局部最优化问题,减少了训练时长,提高了训练效率。将训练后得到的参数传递至对应的NN,最终的网络结构便是9-6-3结构,与传统的DBN方法不同的是,本文采用了Otsu自动阈值分割算法,能够在DBN的最后一层自动获取阈值,这使得DOHM模型减少了人工设定阈值的工作量,而且取得了更高的运行效率。
3 实验结果与讨论
为了更有效、更直观地展现DOHM模型的检测结果,本文选取了五种常用的云检测方法进行对比,从不同的方面给出实验结果以及讨论,这五种方法分别是:SVM、PNN、NN、朴素贝叶斯分类器(Bayes)和普通DBN算法。
3.1 可视化定性分析
为了尽可能全面有效地展现各个检测方法的优劣性,在时间的选择上,本文选择了不同季节、不同时间的例图进行比对,地点都是所取经纬度范围内海域,由于本文主要研究海域上空云检测,所以本文实验都已经将陆地自动屏蔽掉,并选取通道4作为原始对比图像。
图4和图5为6种方法的检测结果,其中子图(a)为通道4原图。通过对每次实验的六种方法检测结果进行横向对比,很明显可以看出,DOHM、DBN和SVM方法检测结果明显好于其余三种方法。仔细对比云检测的边缘处理和检测细节处理,DOHM的表现更好,NN表现最差,值得注意的是通过时间轴纵向相比来说,DOHM在冬季和初春季节表现不如其余季节,这可能是由于冬季和初春季节温度较低,高纬度海域有冰雪覆盖,而冰、雪在亮温通道表现出和云相似的性质,导致检测结果出现偏差,其余五种方法都或多或少出现了这个问题,但DOHM的表现仍然是较好的。综上所述,通过横向和纵向对比,DOHM方法在六种方法中检测结果最为优秀。

图4 六种方法在2011- 08- 10T05:08云检测结果

图5 六种方法在2011- 12- 02T12:11云检测结果
3.2 定量分析
直观对比展现DOHM检测结果优势之后,还需要对检测结果作进一步细致的定量分析。定量分析要对网络的分类结果进行验证,为了检验网络分类的准确性和鲁棒性。
1)正确率和标准差。
正确率是对12次测试实验正确率取均值,标准差是这12次测试实验正确率的标准差,可以从这两方面分析各种方法的准确性和鲁棒性。六种云检测算法的正确率如图6(a)所示,标准差如图6(b)所示。正确率能够直观表现一个算法的准确性,而标准差能够在一定程度上说明算法的鲁棒性,标准差越小,说明算法更健壮。从图6综合来看,DOHM模型在六种方法里正确率最高且标准差最小,说明该方法在保证算法健壮的同时达到了检测正确率最高的目的。SVM方法的正确率不如DBN和DOHM高,NN、PNN和Bayes方法的标准差比其他三种方法高出很多。值得注意的是,综合正确率和标准差来看,DBN和DOHM方法的结果差距并不大,但是DOHM在DBN基础上实现自动阈值分割的同时又能提高正确率,已经极大地提高了DBN方法的适应性和可扩展性。

图6 六种方法的实验性能比较
2)虚警率和漏检率。
为了更好地分析各方法的综合检测结果,本文使用虚警率(False Alarm Rate, FAR)和漏检率(Miss Rate, MR)来进一步分析DOHM检测结果,虚警率和漏检率定义分别如式(8)、式(9)[18]所示:
FAR=NC/MC
(8)
MR=CN/TC
(9)
其中:NC是无云像素点被检测为有云像素点的个数,MC是检测出的所有有云像素点个数,CN是有云像素点被检测为无云像素点的个数,TC是海表面所有有云像素点个数。根据定义,计算出的具体数值对比情况如表3所示。
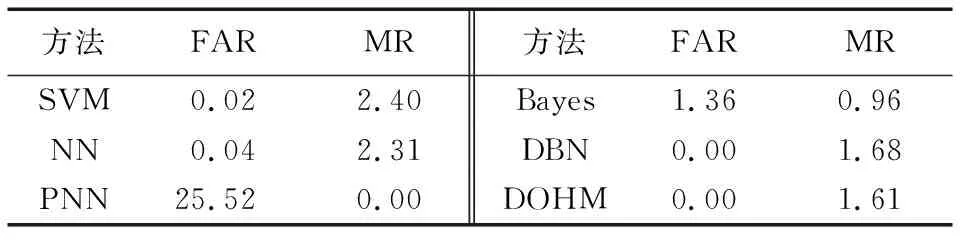
表3 六种方法的FAR和MR %
虚警率FAR和漏检率MR是一对相互矛盾的指标,理想状态下希望这两个指标都达到最低, 但实际上,由于这两个指标的矛盾性,很难找到一种方法使这两个指数同时降到0,一般情况下都是在保证一个错误率在某个值以下,让另一个错误率尽可能得小,尽量平衡好两者之间的关系。在本文实验中,由于更注重的是检测的准确度,所以虚警率和漏检率中本文更关注虚警率的大小。从表3中可以看出,DBN方法和DOHM方法的虚警率都达到了0,再单独比较这两种方法的漏检率,DOHM的漏检率相对更低,所以综合这两个指标,DOHM方法表现更好。值得注意的是,在漏检率MR中,指数最低的是PNN方法,但是其虚警率高达25.52%,说明该方法没有很好地平衡虚警率和漏检率之间的关系。
根据实验结果分析,DOHM较好地平衡了虚警率和漏检率之间的关系,在六种检测算法中,DOHM的云检测结果表现最好。
4 结语
本文提出了一种基于DBN和Otsu的自动云检测算法框架——DOHM,该模型综合使用了DBN和Otsu算法,减小了算法的人工干预程度,在实现自动云检测的同时,正确率可提高至95%以上,不论是定量分析还是可视化定性分析,DOHM都在与目前主流检测方法的对比中取得了很好的成绩,有着广阔的应用前景。云检测工作是遥感数据利用的第一步,是后续云剔除、云分类的基础,不仅有助于更好地了解云的形态和结构,还能提高遥感数据的利用率。
随着计算机技术和卫星遥感技术的发展,对云检测精度的要求越来越高,单一的云检测算法已经无法满足目前云检测应用发展的需求,未来检测方法趋于多样性、综合性、自动化。利用基于机器学习的检测算法解决云检测相关问题成为未来发展的主要趋势,深度学习神经网络将会成为未来检测识别算法中的主力军。
致谢 感谢中国海洋大学卫星地面站提供卫星资料。
