基于三维矫正和相似性学习的无约束人脸验证
2018-11-23梁久祯
徐 昕,梁久祯
(常州大学 信息科学与工程学院,江苏 常州 213164)(*通信作者电子邮箱jzliang@cczu.edu.cn)
0 引言
虽然在部分公开的人脸数据集上,很多人脸识别算法已经取得了非常优秀的成绩,但这些成绩一部分是建立在严苛的实验环境基础之上的。现实中的人脸识别验证往往面临着训练数据有限、面部特征被遮挡、姿态变化、复杂的场景变化、光照变化等多方面的难题,很多传统的人脸识别验证算法在这种情况下表现得不是很好,因此现在越来越多的学者将研究的注意力转向了无约束条件下的人脸识别。
针对无约束人脸识别验证中的人脸姿态变化问题,文献[1-4]利用大量的训练样本来学习寻找姿势不变特征,并通过提取这些姿势不变特征来进行人脸识别,然而在人脸旋转角度较大的情况下,人脸图像在很大程度上被改变,很难寻找到姿势不变特征,因此人脸矫正方法被许多研究学者提出。人脸矫正是将图像中有姿态变化的非正面人脸矫正为正面人脸的过程,主要有两种方法:一种是基于二维视角的方法,另一种是基于三维人脸的人脸重建方法。
在基于二维视角的方法中,文献[5]中提出了一种将统计学习的思想引入到图像合成中的方法,该方法把稠密特征进行对应后再把研究对象表示成某一个线性空间的一个样本。在此基础之上,文献[6]中提出了关于线性物体类的概念,并将线性空间进行了具体化。
在三维人脸重建方法中,文献[7]使用一个标准的人脸模型和一个光照模型,首先利用主成分分析(Principal Component Analysis, PCA)的方法来进行人脸图像的特征提取,再通过贝叶斯函数确定模型中的参数,最后获得该人脸图像的三维模型,完成人脸矫正。文献[8]中利用图像中物体表面的明暗变化来恢复其表面各点的相对高度,完成物体的三维重构。尽管该方法可行,但它对于遮挡问题以及镜面的反射问题(眼镜)十分敏感,并且常常需要事先将面部区域从背景中分离出来。
与二维视角的方法相比,三维重建的方法精度更高,因此本文主要研究三维空间下的人脸姿态矫正问题。本文采用的三维矫正方法是一个固定不变的三维人脸模型,无需为每张图像中的人脸计算出对应的三维人脸模型,可以大幅降低算法的复杂度。
度量学习也就是常说的相似度学习,如果需要计算两张图像的相似度,如何度量图像之间的相似度使得不同类别的图像相似度小,而相同类别的图像相似度大就是度量学习的目标。近年来,针对人脸识别问题,研究人员也提出了一些基于度量学习的算法。文献[9]中提出了一种学习关联度量的方法,该算法在对样本特征进行了降维后,仍可以保留样本之间的近邻关系;还针对关联度量提出了相关嵌入分析(Correlation Embedding Analysis, CEA)模型和相关PCA(Correlation PCA, CPCA)模型。文献[10]中提出了余弦相似度度量学习(Cosine Similarity Metric Learning, CSML)模型,该模型利用样本间的余弦距离来进行相似度度量,能够有效地进行识别分类。文献[11]中提出了广义稀疏度量学习(Generalized Sparse Metric Learning, GSML)模型,该方法为许多有代表性的稀疏度量学习模型提供了一个统一的角度,并且可以将现有的许多非稀疏度量学习模型扩展到稀疏度量学习形式。文献[12]提出了一个相似性度量学习方法sub-SML(Simialrity Metric Learning over Subspace),该方法结合了马氏距离与相似性学习,旨在学习出更有利于分类的距离变换矩阵,该方法在无约束人脸验证上取得了不错的成绩。
本文将三维人脸矫正与相似性学习方法相结合,提出了基于三维矫正与相似性学习的人脸验证方法sub-SL(Similarity Learning over subspace),并通过实验验证了本文方法的有效性。本文的主要工作有:
1)通过三维人脸矫正将无约束图像中的多姿态人脸矫正为标准的正面人脸。完成矫正的图像中的人脸部分均处在图像的中心区域,利用这一特性对图像进行裁剪,可以将人脸从背景中分离出来。
2)通过个体内部子空间的投影,使得特征类内变化小而类间变化大,再结合相似性学习算法,能够更有效地度量两张图像之间的相似度。
1 相关工作
1.1 个体子空间投影
对样本特征进行基于个体内部子空间的投影可以减小样本类内变化,扩大样本类间变化,从而更有利于区分相似图像对与不相似图像对。首先,定义个体内部协方差矩阵为:
(1)
令Λ={λ1,λ2,…,λk}和V=(v1,v2,…,vk)为CS的最大的k个特征值及对应的特征向量。特征到k维的个体内部子空间的映射过程定义:
(2)
需要注意的是,这些特征是通过特征值的倒数来进行加权的,这些特征值对大特征值的特征向量进行惩罚,从而减小特征的变化,即个体内变化。
1.2 相似性度量学习

(3)
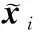
对该f(M,G)函数进行化优化之后可以得到sub-SML的目标函数:
(4)
ξt≥0;∀t=(i,j)∈U
2 基于dlib的三维人脸矫正
文献[13]中提出了一个利用单一、不变的3D人脸模型[14]来进行人脸矫正的方法,其核心思想是利用3D人脸模型作为中介,将输入的人脸图像中的人脸区域投影到一个由3D人脸模型生成的标准坐标系(3D模型的合成的正面脸)中后,再利用像素采样生成一个矫正后的正面人脸。在矫正过程中,需要寻找到输入图像与3D模型表面点之间的一个对应关系,也就是需要找到输入图像与3D模型的正面2D人脸图像各像素点之间的对应关系,因此需要借用人脸特征点来完成这个对应关系的预测。
2.1 人脸图像预处理
近年来,国内外的学者提出了很多高效精确的特征点检测方法,例如主动表观模型(Active Appearance Model, AAM)[15-16]、监督梯度下降法(Supervised Descent Method, SDM)[17]、dlib库[18]等。本文测试了几种当前比较流行的人脸检测方法,在权衡了检测速度与准确率后选择dlib库来进行人脸的特征点检测。dlib库会在框定人脸位置的同时定位出人脸的特征点,由dlib库检测出的人脸特征点共有68个,如图1所示,分别分布在眼睛、眉毛、鼻子嘴巴以及下颚轮廓上。
针对无约束图像中可能出现的一张图像上出现多张人脸的问题,需要一个预处理操作来完成目标人脸的筛选工作。通常情况下,作为拍摄者目标人物的人脸在图像中应该占据着比较大的空间,因此在一张图像有多张人脸的情况下,目标人物的人脸相对于照片中其他人脸来说占的空间应该更大。但是dlib库用以定位人脸的人脸框并没有考虑到人脸图像中的人脸大小问题,不适合进行目标人脸的筛选工作,如图2所示,所以本文对人脸图像用VJ(Viola and Jones)算法[19]再次进行人脸定位,对定位出的人脸框的大小进行排序,选取最大的人脸框作为该图像的目标人物,并保存该人物的68个特征点。

图1 由dlib检测出的68个特征点的分布Fig. 1 Distribution of 68 feature points detected by dlib

图2 dlib算法和VJ算法所检测并标注出的人脸框Fig. 2 Face frames detected and marked by dlib and VJ algorithms
2.2 三维人脸矫正
对于一个给定了面部纹理的3D模型,利用相机标定原理,通过指定一个投影矩阵CM=AM[RMtM],可以生成该3D模型在不同姿态下的2D人脸合成图,其中:[RMtM]是由旋转矩阵RM和平移向量tM组成的外部矩阵,AM为内部矩阵。文献[13]通过一个指定的投影矩阵CM生成了该3D模型的正面人脸视图, 本文将该合成的正面人脸作为参考坐标系使用,该正面人脸同时也作为参考图像IR使用,该参考图像及其特征点分布如图3所示。

图3 参考图像及由dlib检测出的68个特征点的分布Fig. 3 Reference image and its distribution of 68 feature points detected by dlib
在生成参考图像IR时,为图像中的每个像素点p′存储其对应的三维坐标P=(X,Y,Z)T,这两点之间的对应关系可由式(5)得到:
p′~CMP
(5)
对于输入的测试图像IQ,记pi=(mi,ni)T为测试图像的特征点的二维坐标,对参考图像IR同样也使用dlib进行特征点检测,并记其特征点坐标为pi′=(mi′,ni′)T,通过式(5)可以得到参考图像特征点pi′所对应的在3D人脸模型上特征点的3D坐标Pi=(Xi,Yi,Zi)T。
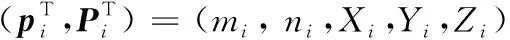
由于部分图像的人脸姿态变化较大,因此矫正后的人脸图像的鼻翼部分以及侧面脸部分会存在像素缺失的问题。针对这一问题,文献[13]对矫正后的人脸图像进行了条件性人脸对称来弥补像素缺失的问题,如图4所示。所谓条件性人脸对称,就是有选择性地进行人脸对称操作,这样可以避免在进行人脸对称时,将一些不该进行对称的部分进行对称(例如眼镜,只出现在半边图像中的人手或一些其他的遮挡物)。为了避免不自然的面部表情,眼部区域在对称过程中同样也是被排除在外的。

图4 人脸对称操作Fig. 4 Face symmetry operation
虽然人脸对称操作可以在一定程度上解决矫正后像素缺失的问题,但它也在一定程度上破坏了人脸本身的面部结构,会对人脸的识别造成一定的影响,所以本文不对矫正后的图像进行人脸对称操作。
3 基于个体子空间的相似性学习
在人脸验证中,保持算法对噪声以及个体内部变化的鲁棒性是一个非常具有挑战性的问题。为了使得提取出的图像特征对于噪声鲁棒,最普遍的是采用主成分分析(PCA)法进行降噪,将图像特征降到d维。为了减小个体内部变化对识别认证结果带来的影响,采用子空间投影法,进一步将d维特征脸映射到个体内部子空间。d特征脸到k维内部个人子空间(k≤d)的映射过程已在1.1节进行了详细介绍,本文只考虑k=d的特殊情况。
3.1 相似性学习算法
根据文献[12]以及最近的研究,可发现相似度函数
sG(x,y)=xTGy
(6)
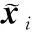
(7)
最小化上述关于G的经验误差将有利于相似图像对与不相似图像对的区分。加入正则化框架来避免过拟合,学习一个鲁棒的、并且有区分性的相似度量函数,约束要优化的参数:
(8)
其中:γ为正则化系数;I为单位矩阵。为了便于在更大的可行域内求解,通过引入松弛变量,式(8)可重新定义为:
(9)
ξt≥0; ∀t=(i,j)∈U
式(9)即为本文算法sub-SL的目标函数的完整形式。
3.2 相似性学习算法优化
目标函数(9)是一个凸优化问题,下面对其进行优化。利用拉格朗日对偶性,引入乘子α和β,目标函数(9)可以改写为:
(10)
通过对G和ξ求偏导,可以得到:
(11)
αt+βt=1
(12)
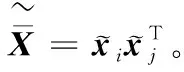

(13)
式(13)是一个标准的二次规划(Quadratic Programming, QP)问题。
4 实验结果与分析
LFW(Labeled Faces in the Wild)人脸数据库[20]是为了研究无约束环境下的人脸识别问题而建立的数据库,该数据库中包含5 749人的13 323张图像,其中有1 680人拥有两张以上的人脸图像。该数据库中的所有图像都是网络搜集而来的。该数据库中的人脸图像姿势、光照变化很大,包含了不同年龄段的人群,面部遮挡问题大并且场景复杂多变,是人脸识别领域中非常具有挑战性的一个数据库。
本文选择LFW数据库为实验对象,实验平台是Intel Core i5-6300HQ CPU 2.30 GHz, RAM 8 GB的PC,64位Windows 10系统和Matlab 2016b以及Ubuntu 16.04和pyhton 2.7。
4.1 关于三维人脸矫正的实验
首先是针对人脸矫正进行的实验,在2.2节中提到,文献[13]有一个步骤是人脸对称,而本文选择省略这一步骤。为了验证人脸矫正以及人脸对称操作是否有效,本文在LFW数据库的基础上另外准备了4组数据集,分别是:1)7080-raw数据集,在这个数据集中的图像只进行了人脸矫正而没有进行人脸对称,图像大小为70×80;2)7080-sym数据集,在这个数据集中的所有图像在进行人脸矫正后还进行了人脸对称操作,图像大小为70×80;3)9090-org数据集,这个数据集是由文献[13]的作者提供的,数据集中所有图像都经过了人脸矫正以及条件性人脸对称,图像大小为90×90;4)LFW-a(Labeled Faces in the Wild-a)数据集[21],该数据集中的所有图像都由商用对齐软件进行了人脸对齐,图像大小为250×250;5)LFW数据库,即最原始的LFW数据库,数据库中的所有图像都未作任何改动,图像大小为250×250。图5展示了同一个人的同一张原图在这5组数据集的差异。
实验选择局部二值模式(Local Binary Pattern, LBP)描述子对这5组数据集分别进行特征提取,并且选取了目前比较流行的分类算法如最近邻(Nearest Neighbor, NN)算法[22]、支持向量机(Support Vector Machine, SVM)[23]、SVDL(Sparse Variation Dictionary Learning)[24]以及sub-SML算法[12]和本文算法sub-SL对这5个数据集进行识别分类,以此作为三维人脸矫正算法的一个评价标准。实验选取100人,每人6张图进行训练,4张图进行测试,并将提取的特征统一降到200维(随机选取的维度),实验结果如表1所示。
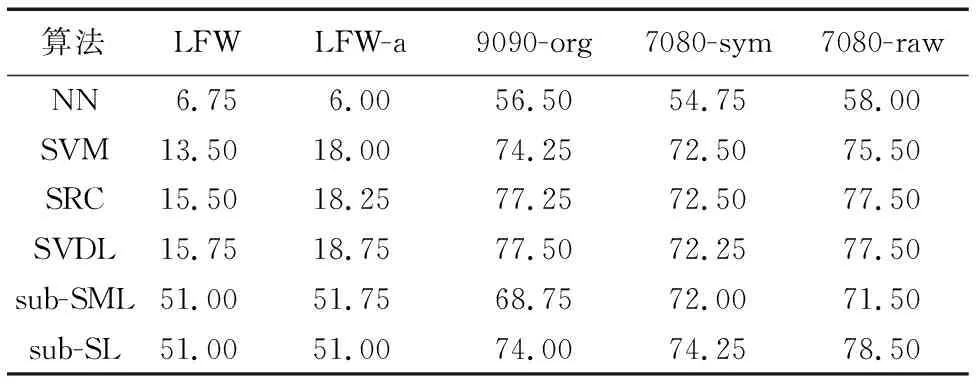
表1 特征维度为200时5组数据集在不同算法上的识别率 %Tab. 1 Recognition rates of 5 datasets under different algorithms with 200 feature dimension %
从表1可以看出:1)在6种不同的算法上,进行了人脸矫正的数据集(例如9090-org、7080-sym和7080-raw)都要比没有进行人脸矫正的数据集(例如LFW,LFW-a)的表现好得多,这一结果表明人脸矫正可以很大程度地提高识别率。2)数据集7080-raw在大部分情况下比7080-sym的表现更好,这一结果验证了人脸对称的做法会在一定程度上破坏人脸的面部结构,从而影响到识别结果,因此本文在人脸矫正后不进行人脸对称的做法是合理的。

图5 同一原图在五组数据集中的差别Fig. 5 Differences of same original picture in five data sets
4.2 相似性学习实验
本文采用的是基于个体子空间的相似性学习算法(sub-SL)。为了验证本文的sub-SL方法的效果比sub-SML方法[19]以及单独的度量学习方法更好,本节将针对该方面进行实验。
下面先简单介绍基于个体子空间的度量学习方法(sub-ML)的目标函数:
(14)
ξt≥0; ∀t=(i,j)∈U
实验选取LBP以及基于局部三值模式(Local Ternary Pattern, LTP)描述子分别对数据集7080-raw中的图像进行特征提取,为了研究特征维度对算法的影响,本文用PCA对特征进行降维,并选取了150、200、250、300、350、400这6个维度。同时,为了研究训练样本数量对于测试结果的影响,本节设计了两个实验:
1) 在该实验中,选取250对相似图像与250对不相似图像组成训练集进行训练,并选取125对相似图像以及125对不相似图像组成测试图像集进行测试。利用LBP进行特征提取的实验结果如表2所示,利用LTP进行特征提取的实验结果如表3所示。
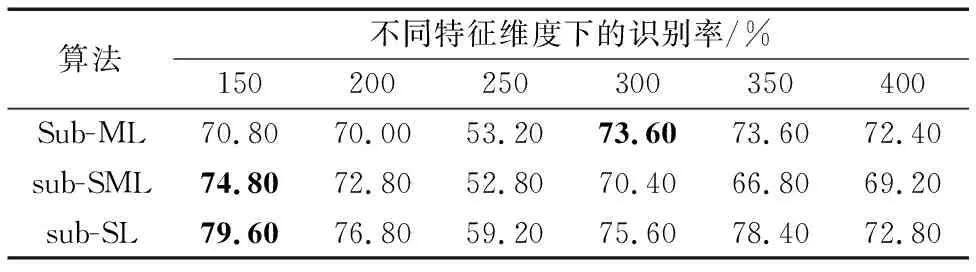
表2 基于LBP的不同特征维度下数据集7080-raw在不同算法上的识别率(训练样本少)Tab. 2 Recognition rates of different algorithms on dataset 7080-raw with different feature dimensions based on LBP (small training samples)
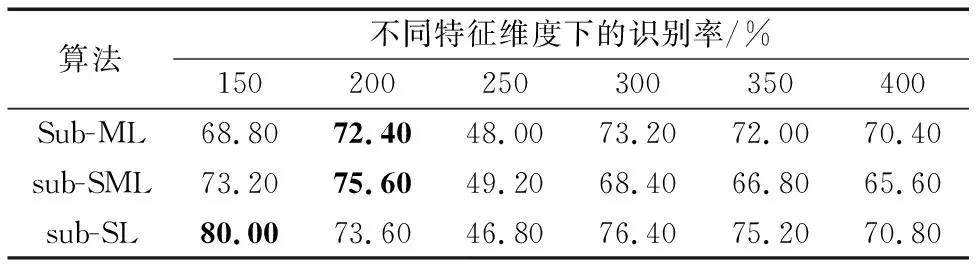
表3 基于LTP的不同特征维度下数据集7080-raw在不同算法上的识别率(训练样本少)Tab. 3 Recognition rates of different algorithms on dataset 7080-raw with different feature dimensions based on LTP (small training samples)
从表2~3可看出:a)对算法sub-SML与sub-SL而言,用LTP进行特征提取后的最高识别率比用LBP进行特征提取的最高识别率稍微好一点。b)在特征提取方法为LBP时,算法sub-SL的最高识别率为79.6%(特征维度为100),要高于sub-SML的最高识别率73.6%(特征维度为300)和sub-ML的最高识别率74.8%(特征维度为100);在特征提取方法为LTP时,算法sub-SL的最高识别率为80%(特征维度为100),同样高于sub-SML的最高识别率75.6%(特征维度为200)和sub-ML的最高识别率72.4%(特征维度为200)。c)特征维度的变化对实验结果也是存在一定影响的,一般情况下随着维度的增加,准确率也有所增加,但在到达一定程度后,维度的增加也会造成噪声的增加,因此算法准确率也会受到影响。
2)在该实验中,选取625对相似图像与625对不相似图像组成训练集进行训练,并选取125对相似图像以及125对不相似图像组成测试图像集进行测试。利用LBP进行特征提取的实验结果如表4所示,利用LTP进行特征提取的实验结果如表5所示。
从表4~5可看出:a)用LTP进行特征提取后的最好的实验结果比用LBP进行特征提取的最高验证准确率要好。用LBP进行特征提取的实验结果中,三种算法的最高验证准确率相同,但用LTP进行特征提取的实验中可以看出算法sub-SL的表现要比sub-SML和sub-ML好得多。b)特征维度的变化对实验结果也是存在一定影响的,一般情况下随着维度的增加,准确率也有所增加,但在到达一定程度后,维度的增加也会造成噪声的增加,因此算法准确率也会受到影响。
综合以上两个实验可以看出:训练图像对的数量对于最终的测试结果还有一定的影响,训练样本数量多的情况下,测试结果会更好一点;在大部分情况下,用LTP进行特征提取要比LBP进行特征提取时的实验结果更好一些,而算法sub-SL的表现比sub-SML与sub-ML的表现更好。

表4 基于LBP的不同特征维度下数据集7080-raw在不同算法上的识别率(训练样本多)Tab. 4 Recognition rates of different algorithms on dataset 7080-raw with different feature dimensions based on LBP (large training samples)
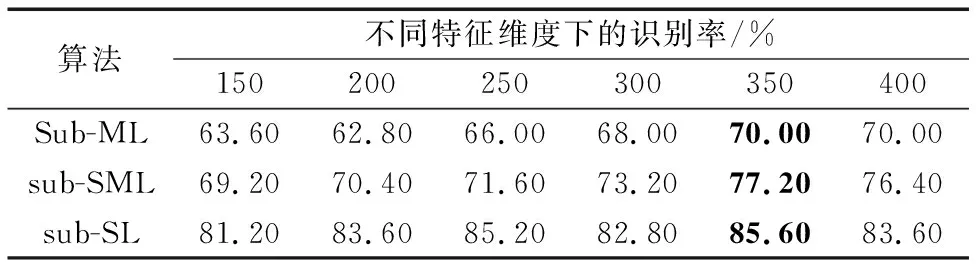
表5 基于LTP的不同特征维度下数据集7080-raw在不同算法上的识别率(训练样本多)Tab. 5 Recognition rates of different algorithms on dataset 7080-raw with different feature dimensions based on LTP (large training samples)
5 结语
本文针对无约束图像的人脸验证问题,结合三维人脸矫正以及基于个体子空间的相似性学习方法,提出了基于三维矫正与相似性学习的人脸验证方法。该方法中的三维矫正能够有效地应对无约束图像中人脸姿态变化大以及背景复杂的问题。通过本文的实验结果可以看出,相对于以往度量学习中常用的欧氏距离,相似度函数能够更有效地度量两张图像之间的相似度,因此本文方法能够有效地应对无约束图像的人脸验证问题,获得良好的验证结果。本文只使用了相似度函数,如何让相似度函数与其他距离度量函数相结合,更有效地进行距离度量,从而获得更优秀的识别结果,将是今后的研究方向。
