信息熵约束下的视频目标分割
2018-11-23丁飞飞杨文元
丁飞飞,杨文元
(1.福建省粒计算及其应用重点实验室(闽南师范大学),福建 漳州 363000;2.数据科学与智能应用福建省高等学校重点实验室,福建 漳州 363000)(*通信作者电子邮箱yangwy@mnnu.edu.cn)
0 引言
视频目标分割是把前景物体从视频背景中分离出来[1],是计算机视觉研究中的一个重要内容,在视频检索编辑、目标跟踪、安防监控、智能交通等领域有着广泛的运用[2]。另一方面,视频目标分割也是其他计算机视觉如目标识别、跟踪、分类以及更高层次的语义分割理解等研究内容的基础。因此,对视频目标有效且高精度分割的研究就显得尤为重要。
由于应用的场景以及选取的分割目标不同,对视频目标分割并不存在标准化的评价方法[3]。根据分割任务,有基于运动信息的关键点轨迹跟踪[4]和基于聚类的无监督方法[1],也有基于光流对帧间标注信息传播的半监督方法[5],以及基于交互式分割的监督方法[6-7]。无监督的方法由用户自动输入视频,无需手工标记以及任何先验性信息就可自动处理大量的视频,并且它和应用更相关。半监督的方法则需要用户在某些帧间标注[8],然后向后续的帧传播这些标注信息,相对来说有更高的分割精度。而监督的方法更适合于特定的场景,且能够取得最高的分割精度,但计算的时间代价往往比较高。此外,这些视频分割方法多基于分析运动和外观信息并且假设运动的一致性。
然而,在处理视频目标分割过程中,由于不知道有关物体表观、尺度、位置等任何信息,再加上大多数视频目标多为无规则运动,目标外观随时发生变化,实际的应用环境也多为复杂的场景,这使得视频分割任务充满挑战[9]。目前有不少学者都在研究目标跟踪分割过程中的遮挡和形变等问题,他们通过构建图模型,并融合颜色信息、位置信息、时空图信息,从而实现对目标的有效跟踪分割,在处理目标形变、遮挡、快速运动和背景干扰等问题时具有较高的稳定性和鲁棒性。
在上述背景下,为了能够有效且更高精度地分割视频运动目标,本文提出一种信息熵约束下的视频分割方法。由于基于图论的视频分割方法遵循预定的目标模型并且可以把目标分割任务看成是像素标记的优化问题[10],而信息熵又能够度量样本纯度,因此:本文方法首先通过光流来模糊估计运动边界并根据文献[11]方法得到第一阶段的分割结果;然后综合分析外观信息建立外观高斯模型,在模型中引入信息熵约束,使得模型能够对复杂场景更加鲁棒;其次,信息熵最小化与整个能量函数模型最小化具有一致的目标,能够使前景和背景估计更加精确;最后通过最小化能量模型来获得相邻顶点精确的标签分配,从而得到有效以及更加精确的目标分割效果。
1 相关工作
基于图论的分割算法在图像分割领域得到了广泛的应用,它是一种基于能量最小化求解最优分割结果的交互式算法,其结果通常为全局最优解[10]。近年来,有许多学者把图论的分割算法运用到视频运动目标的分割,这些基于图论的视频分割方法都遵循相似的目标模型。
2001年,文献[12]中首先提出了能量优化算法Graph cut,算法中定义包含区域项和边界项的能量函数,通过最小化能量函数来实现前景背景分割;为了利用颜色信息和边界信息,2004年文献[13]中在Graph cut算法基础上提出Grab cut算法,通过少量的用户交互,不断地进行分割估计和模型参数学习,最终实现了较好的分割;2011年文献[4]中对颜色信息和边界信息进行精细化分析,通过结合运动信息和静态图像特征信息找出所有帧可能的目标区域,然后对这些可能区域评分排序,从而产生一系列关键视频段,同时在这些关键视频段中构建颜色外观和先验位置模型,最终通过能量函数最小化实现全自动的分割;2012年文献[8]中把超像素引入到视频目标分割,提出概率运动扩散传播标注信息的方法,通过对超像素增加标签一致性约束,在能量函数上增加由时间平滑项和空间平滑项两部分组成的互势函数,然后最小化能量函数来得到较高的分割精度;为更加鲁棒地处理快速运动、遮挡变形等视频分割挑战,2013年文献[11]中通过积分交叉算法得到视频目标内部像素点,同时在目标内部像素点构成的内外图中学习颜色外观和先验位置模型参数,最终实现全自动地视频目标分割;2017年,文献[9]在文献[11]的基础上,利用元胞自动机的思想对超像素水平的先验前景图细化,然后在细化的先验前景图上学习颜色外观和先验位置模型参数,最终最小化能量函数得到更高的分割精度。本文在上述文献的基础上,从信息熵的角度对先验前景图细化,并同文献[8]一样把超像素引入到视频目标分割,然后综合分析时空信息、位置信息和细化的外观信息,通过Grab cut迭代分割得到更加精确的分割结果。
2 信息熵约束下的视频分割方法
本文方法和大多数无监督方法一样,并不需要假设运动的一致性,只要前景物体与周围存在显著的运动差异,就可以通过计算光流来模糊估计运动物体的边界。本文方法包括两个阶段:1)计算光流得到前景目标的模糊运动边界;2)在目标模型中引入信息熵约束项来获得更加精确的前景背景像素标记。在第一个阶段,本文方法基于经典光流法[15]和文献[11]算法得到运动目标的内部像素点,从而得到前景运动目标的运动边界。在这个阶段,由于目标物体快速移动以及受遮挡等因素的影响,使得光流估计并不准确,无法得到精确的分割结果。第二个阶段,基于简单线性叠加聚类(Simple Linear Iterative Clustering, SLIC)算法[16]获得均匀的运动和表现后以超像素作为基本分割单元,然后基于图论分割的模型,构建类似文献[21]和文献[22]的能量函数。在构建外观高斯模型过程中引入信息熵约束,使得模型能够对复杂场景更加鲁棒;其次最小化信息熵与整个能量模型最小化具有一致的目标,通过最小化信息熵能够更加精确地评估像素点标记是背景还是前景。
2.1 计算光流确定运动边界
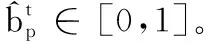
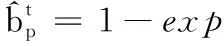
(1)


(2)

(3)
式(3)表明像素p(i,j)与周围存在不同运动方向和速度,若变化差异大,那它很可能是运动边界。图1(a)~(c)显示了第一阶段通过计算光流得到运动边界的过程。
2.2 基于超像素点定义时空图
通常情况下,由文献[15]计算光流得到的运动边界并不完全覆盖整个物体,为此,需要利用文献[11]算法,结合点在多边形内部原理得到运动目标内部精确的像素点。具体做法为:针对给定的视频帧,首先让目标区域内的每个像素点每间隔45°向8个方向引出射线,计算每条射线与运动边界的交点数目,若交点数目为奇数,则判断该点在运动边界内部,否则判断该点在运动边界外部;然后统计每个像素点引出的射线与运动边界交点偶数和奇数的数目,通过投票来决定该像素点是否是运动目标内部的像素点,若像素点引出的射线奇数交点数目多于偶数交点数目,那就认为该像素点为内部像素点;最后对所有视频帧都运用上述算法,得到内部像素点图如图1(d)所示。
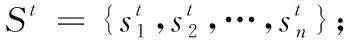
在定义能量函数过程中,先把视频序列看成是超像素水平的时空图(G),图的顶点s对应超像素点,图的边对应超像素的邻接关系,其包含时间上和空间上的邻接关系,两顶点之间边的权重对应超像素点分割时的代价,ωij定义[9]为:
(4)
其中:δ2设置为0.1;fi和fj分别对应CIB LAB颜色空间上相邻超像素点的平均值。

图1 两个阶段的分割过程Fig. 1 Two stages of segmentation process
2.3 引入信息熵约束实现目标精确分割
根据第一阶段得到的分割结果和前面定义的时空图,利用超像素作为基本分割单元。为评估每一个超像素标记的准确性,定义如下能量函数:
E(L)=ΓA+l1ΓP+l2ΓS+l3ΓT+l4ΓD
(5)
其中:ΓA为外观模型项,是对超像素属于前景或背景的一种概率估计;第二项ΓP是为精确标记前景目标位置而建立的位置模型项;ΓS和ΓT分别是在时空图边集上定义的空间平滑项和时间平滑项,让分割在时空上变得更加平滑;ΓD是本文方法为获得更加精细的外观模型而定义的信息熵约束项;l1~l4分别为各项的权重系数,设置l1=1.5,l2=2 000,l3=1 000。

(6)
其中:λ1设置为0.000 1;第一个参数项exp()表示超像素在时间上的权重;第二个参数项表示超像素点通过内部像素点计算出的属于前景的比例。估计完前景和背景模型后,外观模型项ΓA为超像素取相应标记时的负对数,可表示为:
(7)
外观模型融合了整个视频序列的信息,因此它能够比单单使用光流得到更精确的分割。然而当前景和背景颜色相似时,对超像素标记的准确性就会下降,则运动目标分割容易受到干扰,而内部像素点能够近似表明前景目标的位置。式(5)中ΓP项就是通过累加所有内部像素点而建立的位置模型项,得到的位置模型如图1(g)所示。根据运动信息,算法通过帧间内部像素点的传播来得到更精确的位置先验,定义位置更新公式[9]为:
(8)
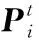
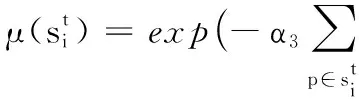
(9)
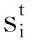
(10)
式(5)中:ΓS和ΓT分别为空间平滑项和时间平滑项,ΓS是定义在同一帧中空间上相邻超像素的边对应的权重,ΓT是定义在相邻两帧中通过光流连接的相邻超像素的边对应的权重,根据文献[11]定义ΓS和ΓT:
(11)
(12)
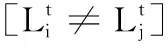
式(5)中最后一项ΓD为分析外观信息建立外观高斯模型时引入的信息熵约束项,得到的更精细外观模型如图1(f)所示。熵是度量样本集合纯度最常用的一种指标,信息熵越小,样本纯度越高;信息熵越大,对样本判断的不确定性就会变大[14]。根据熵的定义,类似地定义ΓD:
(13)

时空图上定义的能量函数融合了位置信息、时空图信息以及更精细的外观信息,通过对各模型项求解可确定时空图上各边初始分割时的代价,然后利用GrabCut算法[13]进行迭代估计得到所有超像素点精确的标记,从而完成对视频目标精确分割,分割结果如图1(h)所示。
3 实验与分析
为了验证本文方法在复杂环境场景下能够有效地分割运动目标并且具有较高的鲁棒性,在DAVIS数据集上(480p)[3]做了定性定量分析实验。DAVIS数据集[3]包含了50个高分辨率的视频序列以及手工标注的标准分割,涵盖了一系列复杂环境场景和视频分割挑战。实验时选取4个具有代表性的视频序列(480p):Video1(blackswan)背景中的水时刻发生变化;Video2(hike)前景背景颜色相似,光照条件也发生变化;Video3(bmx-bumps)视频目标快速运动;Video4(breakdance-flare)前景目标动作特征复杂,外观发生变化。实验结果如图2所示。实验环境为:Intel i7-3770 @ 3.40 GHz,8 GB内存,Windows 7环境下使用Matlab 2014a实现。
为了定量评价本文方法的分割结果与DAVIS数据集[3]提供的标准之间的相似性,采用归一化相关系数(Normalized Cross-correlation, NC)来度量分割效果。根据文献[20],度量公式定义为:
(14)
其中:G为数据集提供的标准,G′为本文算法的分割结果,它们的大小均为P×Q。NC取值为0~1,其值越接近1,表示G与G′之间越相似,其评价结果如表1所示。

表1 在DAVIS数据集上的定量分析结果Tab. 1 Quantitative evaluation video segmentation results on DAVIS dataset
从图2可以看出,本文法在一些复杂场景下能够取得比较高的分割精度,表1中的数据也显示了本文方法与标准之间的相似度比较高。如在目标发生快速运动(Video3)以及外观产生变化(Video4)时都能对目标进行有效的分割,这与表1中Video3和Video4的数据也吻合;而在其他视频序列,如在Video1背景(水)发生快速变换和Video2光照条件发生变化时,本文方法能得到更加精确的分割结果。图示四个视频序列多帧的分割结果也表明本文方法具有比较高的稳定性和鲁棒性。
文献[4]和文献[23]都定义了能量函数模型,然而文献[4]的能量函数模型中并未考虑时空图信息,文献[23]在能量函数中增加了先验显著性检测,在一些数据集中能够取得比较好的效果,但并未对外观模型信息作精细化分析。为了进一步验证算法的分割精度和鲁棒性,本文结合文献[4]和文献[23]给出的实验结果,在标准数据集SegTrack[17]上做了定性定量对比实验。SegTrack[17]标准数据集包含6个不同的视频序列并涵盖了多种不同的场景,能够较为全面地衡量算法在不同场景下的分割能力。和大多无监督方法一样,实验中选取前5个视频序列,实验结果如图3所示。从图3可以明显看出:本文方法在一些帧中能够取得比较高的分割精度,如在快速运动的目标(Cheetah)中;文献[4]有不同程度丢失目标的情况,而文献[23]在前景目标(Monkey)动作特征复杂的情况下,分割效果不佳。在其他视频序列,如Girl,虽然本文方法在脚的一部分有丢失,但在其他身体部位的分割却非常精确。
为了更加客观地评价本文方法的有效性,根据文献[3]所述的两类主要视频分割评测标准:区域相似度和轮廓精确度,进行了定量分析实验。直观上区域相似度度量标注错误像素的数量,而轮廓精确度度量分割边界的准确率。由于SegTrack数据集[17]内的视频序列分辨率较低,因此选取每个视频序列的平均每帧错误分割的像素点个数来量化[18]评测本文方法。实验对比结果如表2所示,计算公式[19]如下:
error=XOR(F,GT)/N
(15)
其中:F为算法分割的结果;GT为数据集中提供的标准分割结果;N为视频序列帧的数量。
计算方式如下:根据文献[4,23]给出的分割结果以及SegTrack数据集[17]给出的标准,利用式(15)进行求解。由于文献[23]给出的结果是灰度图像,因此先对图像作二值化预处理,这和文献[23]给出的实验结果略有不同。
从表2可以看出,本文方法在处理快速运动的目标(Cheetah)和前景目标(Monkey)动作特征复杂的场景下都有不错的表现,这和图3定性分析的结果吻合。在其他视频序列,如Girl,本文方法虽然错误分割的像素点个数相对比较多,但从图3也能看出,除了脚的一部分发生丢失,在其他部位的分割效果都比较好。针对Girl视频序列错误分割的像素点个数相对比较多的情况,其产生原因可能是由于目标外观发生变化,划分超像素时产生过分割。

图2 本文方法在DAVIS数据集视频序列的分割结果Fig. 2 Segmentation results obtained by the proposed method to video sequences from dataset DAVIS

图3 本文方法与其他方法在SegTrack数据集上的定性比较结果Fig. 3 Qualitative comparison of the proposed method with other methods on dataset SegTrack

表2 在SegTrack数据集[17]上定量比较结果Tab. 2 Quantitative results and comparison with other methods on dataset SegTrack[17]
4 结语
本文提出信息熵约束下的图论视频分割方法,综合分析了运动信息、外观信息、位置信息、时空图信息。首先把目标分割任务看成是像素标记的优化问题,在分析外观信息时引入信息熵约束项,从而增强目标模型对背景噪声和复杂环境的鲁棒性;然后通过最小化能量模型来获得更精确的分割效果。实验结果也测试了本文方法的有效性和鲁棒性,然而在目标外观发生变化或遮挡的情况下,相对于对比算法,本文方法分割精度并不是很高。后续工作将着重分析该视频场景以及进一步考虑在划分超像素时如何避免过分割的问题。
