基于生成对抗网络的信息隐藏方案
2018-11-22王耀杰杨晓元
王耀杰,钮 可,杨晓元
(1.武警工程大学 密码工程学院,西安 710086;2.网络与信息安全武警部队重点实验室(武警工程大学),西安 710086)(*通信作者电子邮箱wangyaojie0313@163.com)
0 引言
信息隐藏是将秘密信息以不可见的方式隐藏在一个宿主信号中,并在需要时将秘密信息提取出来,以达到隐蔽通信和版权保护等目的[1]。它主要用于特定双方的秘密通信,特别是在快速增长的社交网络中,有丰富的图像和视频作为载体,这为信息隐藏提供了更多的机会和挑战。图1是信息隐藏的典型模型。
当前常用的图像信息隐藏方法主要包括空域和变换域的信息隐藏方法。空域隐藏方法如图像最低有效位(Least Significant Bit, LSB)隐藏方法[2]、自适应LSB隐藏方法[3]、空域通用小波相对失真(Spatial-UNIversal WAvelet Relative Distortion, S-UNIWARD)方法[4]、HUGO(Highly Undetectable steganography)[5]、WOW(Wavelet Obtained Weights)[6]等;变换域方法如离散傅里叶变换(Discrete Fourier Transform, DFT)隐藏方法[7]、离散余弦变换(Discrete Cosine Transform, DCT)隐藏方法[8]、离散小波变换(Discrete Wavelet Transform, DWT)隐藏方法[9]等。

图1 信息隐藏的典型模型Fig. 1 Typical model of information hiding
传统信息隐藏方法都是通过修改载体来嵌入秘密信息,含密载体总会留有修改痕迹,导致含密载体难以从根本上抵抗基于统计的信息隐藏分析算法的检测。当人们设计隐写算法时,通常会考虑到隐写分析。例如,秘密信息应该嵌入到图像的噪声和纹理区域中,这样更加安全。但现有的隐写模式通常要求载体信息的先验概率分布,在实际中很难获得,也就是说抵抗隐写分析的设计未能在应用中很好地实现。因此,如何设计安全的隐写方案使含密载体从根本上抵抗基于统计的隐写分析算法的检测是研究人员面临的难题,也是研究的热点之一。
生成对抗网络(Generative Adversarial Network, GAN)[10]的特点是提取总结真实样本的特征,由噪声驱动来生成丰富多样的图像样本,这为信息隐藏的研究提供了新方向。在SGAN(Steganographic GAN)[11]和SSGAN(Secure Steganography based on GAN)[12]的启发下,本文提出了一种基于生成对抗网络的安全隐写方案,通过生成更合适的载体信息来保证信息隐藏的安全性。该方案首先用GAN中的生成模型(generative model)以噪声为驱动生成原始载体信息,其次将使用±1嵌入算法,将消息嵌入到生成的载体信息中,然后将含密信息与真实样本作为生成对抗网络判别模型D(discriminator D)的输入,对于判别性网络进行重构,同时使用判别模型S(discriminator S)来检测图像是否存在隐写操作。
本文的主要工作归纳如下:
1)提高含密信息的安全性。在本文中,将含密信息(steg(G(z)))与真实图像(χdata)作为生成对抗网络判别模型(discriminative model)的输入,对于判别性网络进行重构,从而使含密信息的安全性显著提高。与SGAN和SSGAN相比,本文方案使得攻击者在隐写分析正确性上分别降低了13.1%和6.4%。
2)生成的载体图像更丰富。本文改进原始GAN的框架,同时要通过调节式(5)参数α的值,使生成对抗网络和隐写分析检测达到均衡,从而更好评估生成图像的特性,使生成的图像更丰富。与对比方案相比,生成的载体图像更适合嵌入。
1 预备知识
1.1 生成对抗网络
GAN是 Goodfellow等[10]在2014年提出的一种生成模型, 其思想来源于博弈论中的二人零和博弈, GAN的结构如图2所示。主要由一个生成器和一个判别器组成,任意可微分的函数都可用来表示GAN的生成器G和判别器D[13]。
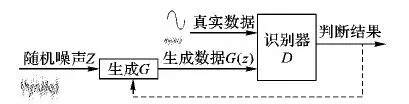
图2 GAN的结构Fig. 2 Structure of GAN
GAN从2014年提出后主要应用在无监督学习上,它能从输入数据动态地采样并生成新的样本。GAN通过同时训练以下两个神经网络进行学习(设输入分别为真实数据x和随机变量z):
1)生成模型G:以噪声z的先验分布pnoise(z)作为输入,生成一个近似于真实数据分布pdata(x)的样本分布pG(z)。
2)判别模型D:判别目标是真实数据还是生成样本。如果判别器的输入来自真实数据,标注为1;如果输入样本为G(z),标注为0。
GAN的优化过程是一个极小极大博弈(Minimax game)问题:判别器D尽可能正确地判别输入的数据是来自真实样本(来源于真实数据x的分布)还是来自伪样本(来源于生成器的伪数据G(z));而生成器G则尽量去学习真实数据集样本的数据分布,并尽可能使自己生成的伪数据G(z)在D上的表现D(G(z))和真实数据x在D上的表现D(x)一致,这两个过程相互对抗并迭代优化,使得D和G的性能不断提升,最终当G与D二者之间达到一个纳什平衡,D无法正确判别数据来源时,可以认为这个生成器G已经学到了真实数据的分布[13]。
因此在GAN的训练过程中解决了以下优化问题:
L(D,G)=Ex~pdata(x)[logD(x)]+
(1)
其中:D(x)代表x是真实图像的概率;G(z)是从输入噪声z产生的生成图像。
通过交替训练G与D实现联合优化式(1):在每个mini-batch随机梯度优化的迭代过程中,本文首先对D进行梯度上升,然后对G作梯度下降。如果用θM表示神经网络M的参数,那么更新规则为:
1)保持G不变,通过θD←θD+γD▽DL更新D:

Ez~pnoise(z)[log(1-D(G(z,θG),θD))]}
(2)
2)保持D不变,通过θG←θG-γG▽GL更新G:
(3)
GAN模型存在着无约束、不可控、噪声信号z很难解释等问题。近年来,在此基础上衍生出很多GAN的衍生模型。文献[14]中将GAN的思想扩展到深度卷积生成对抗网络(Deep Convolutional GAN, DCGAN)中,将其专门用于图像生成,还论述了对抗训练在图像识别和生成方面的优点,提出了构建和训练DCGAN的方法。Conditional GAN[15]能生成指定类别的目标。InfoGAN(interpretable representation learning by Information maximizing GAN)[16]被OPENAI称为2016年的五大突破之一,它实现了对噪声z的有效利用,并将z的具体维度与数据的语义特征对应起来,由此得到一个可解释的表征。
1.2 Wasserstein GAN
WGAN(Wasserstein GAN)[17]是GAN的衍生模型,主要从损失函数的角度对GAN作了改进。原始GAN采用交叉熵(JS散度)衡量生成分布和真实分布之间的距离,导致GAN在训练过程出现模型崩塌(mode-collapse)的问题。WGAN在理论上给出了GAN训练不稳定的原因,即交叉熵(JS散度)不适合衡量不相交分布之间的距离,接着使用Wassertein距离去衡量生成数据分布和真实数据分布之间的距离,主要理论贡献为:
1)定义了可以明确计算的损失函数,彻底解决 GAN训练不稳定的问题,不再需要小心平衡生成器和判别器的训练,基本解决了模型崩塌(mode-collapse)问题,确保了生成样本的多样性。
2)使用Wasserstein方法对 G&D 的距离给出了明确的数学定义。Wasserstein距离也称为转移度量或者E距离,它表示从一个分布转移成另一个分布所需的最小代价。
WGAN采用Wasserstein距离代替交叉熵(JS散度)[10]作为损失函数(loss function)。但在实际中直接计算Wasserstein距离是很困难的,因此使用Wasserstein距离的Kantorovich-Rubinstein对偶形式:
(4)
也就是说,Wasserstein距离实际上需要考虑所有的1-Lipschitz函数。如果考虑的是K-Lipschitz函数[18],则Wasserstein距离变为原来的K倍。一般来说,可以假定GAN的判别器D是K-Lipschitz函数,即优化D实际上是在某个K-Lipschitz函数集{fw}w∈W上寻找合适的函数(其中w为f的参数)。WGAN通过数学变换将Wasserstein距离写成可求解的形式,利用一个参数数值范围受限的判别器神经网络来最大化这个形式,就可以近似Wasserstein距离。在此近似最优判别器下优化生成器使得Wasserstein距离缩小,就能有效拉近生成数据分布与真实数据分布。
WGAN对原始GAN的具体改进为:1)判别器最后一层去掉 sigmoid;2)生成器和判别器的loss不取 log;3)每次更新判别器D之后,把D中参数的绝对值截断到一个固定常数;4)采用RMSProp(Root Mean Square prop)[19]、SGD(Stochastic Gradient Descent)替换基于动量的优化算法 momentum和Adam(Adaptive moment estimation)。
WGAN既解决了训练不稳定的问题,也提供了一个可靠的训练进程指标,而且该指标确实与生成样本的质量高度相关。但是采用WGAN模型生成的图片离现实图片还有差距,后续还需要进一步研究。
2 本文方案模型
在SGAN和SSGAN工作的启发下,本文引入一个新的基于WGAN信息隐藏(Steganography based on GAN, Stego-WGAN)方案,包含一个生成网络和两个判别网络。具体功能为:
生成器网络G:以噪声为驱动,通过机器学习生成近似真实数据样本的图像作为载体信息。
判别器网络D:与SGAN和SSGAN方案不同,该方案为将含密信息(steg(G(z)))与真实样本作为判别模型D的输入,对输入的样本鉴别真伪。
判别器网络S:与SSGAN方案相同,本文也使用复杂的GNCNN(Gaussian-Neuron Convolutional Neural Network)[20]来评估生成的图像的合适性,同时确定被检图像是否存在隐写操作。本文Stego-WGAN模型如图3所示。
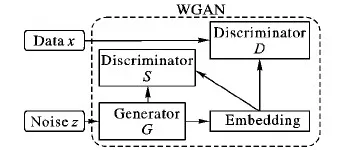
图3 Stego-WGAN模型Fig. 3 Stego-WGAN model
本文用S(x)代表判别模型S的输出,用Stego(x)表示将一些秘密消息嵌入到载体信息x中的结果。
为了使生成模型G生成可用于信息隐藏的逼真图像,本文迫使生成模型G与判别模型D和S相互竞争,不断迭代优化。该模型数学表达式如下所示:
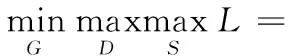
α(Ex~Pdata(x)[logD(x)]+
Ez~Pnoise(z)[log(1-D(Stego(G(z)))])+
(1-α)Ez~Pnoise(z)[logS(Stego(G(z)))+
log(1-S(G(z)))]
(5)
本文将D和S两者组成凸函数,并由参数α∈[0,1]调控生成图像的真实性和隐写分析准确性。初步实验结果表明,对于α≤0.7时,生成的图像是视觉质量很差,与噪声相似[11]。
2.1 网络结构
对于生成网络G,它用于生成安全的载体信息。 本文使用一个全连接层和四个卷积层,然后是双曲正切函数作为激励层。G网络结构如图4(a)所示。
对于判别网络D,它用于评估含密图像的质量特性。 本文使用四个卷积层和一个全连接层。D网络结构如图4(b)所示。
对于判别网络S,它用于评估生成图像的适用性。本文首先使用预定义的高通滤波器进行滤波操作,主要用于隐写分析;然后是四个卷积层,用于特征提取;最后进行判别分类,分类的结构里也包含一个全连接。S网络结构如图4(c)所示。
2.2 更新规则
本文采用SGD[21]更新规则,具体步骤如下。
a)对于生成模型G:ωG←ωG-rG▽GL,它由式(6)计算:
b)对于判别模型D:ωD←ωD+rD▽GL,它由式(7)计算:

Ez~Pnoise(z)[log(1-D(Stego(G(z,ωG)),ωD))]}
(7)
c)对于判别模型S:ωS←ωS+rS▽SL,它由式(8)计算:
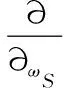
log(1-S(G(z,ωG),ωS))]
(8)
更新G不仅使判别模型D的错误率最大化,而且使判别器D和S的线性组合的差错率最大化。

图4 模型网络架构Fig. 4 Model network architecture
3 实验结果与分析
3.1 实验数据准备
在本文实验中,使用公开可用的CelebA(CelebFaces Attribute)人脸数据集(Ziwei Liu&Tang,2015),其中包含200 000张图像;输入的随机噪声z为(-1,1)上的均匀分布。实验平台为谷歌的人工智能学习系统Tensorflow v0.12,计算显卡为NVIDIA1080。
为了进行隐写分析,首先对数据集进行预处理,将所有图像裁剪为64×64像素,将90%的数据作为训练集,并将其余的作为测试集,训练集由A表示,而测试集由B表示。使用Stego(x)来表示将一些秘密消息嵌入到载体信息x中的结果,那么嵌入秘密信息后得到训练集A+Stego(A)和测试集B+Stego(B),即得到380 000张用于隐写分析的训练样本,并将剩余的20 000张作为测试样本。
同时,使用±1嵌入的隐写算法,有效载荷大小为每像素0.4位,本文随机选择文章作为嵌入的文本信息。
本文使用了所有200 000张裁剪样本用于训练Stego-WGAN模型。 图5为经过7个训练周期后,Stego-WGAN模型和SSGAN模型产生的图像。

图5 Stego-WGAN和SSGAN模型生成的人脸图像Fig. 5 Generated face images by Stego-WGAN and SSGAN
实验结果表明,本文提出的Stego-WGAN模型生成的图像的视觉质量相同,但人物多样性更丰富,明显优于对比方案。
3.2 实验设置
在本节中,将描述Stego-WGAN模型结构。由C2D-BN-LR表示卷积神经网络的以下结构块:Conv2d→Batch Normalization→Leaky ReLU。
判别模型D和判别模型S具有相似的结构:4个C2D-BN-LR层→1个全连接层(1个神经元)→Sigmoid函数(用来计算一个输出)。生成模型G结构是:1个全连接层(8 192个神经元)→4个C2D-BN-LR的反卷积层→tan(x)函数层(计算正则化输出)。
对Stego-WGAN模型进行训练,采用基于Adam的优化算法,学习率为0.000 2,更新变量β1=0.5,β2=0.999。在每次训练中,先更新一次判别器D的权重,再更新两次生成器G的权重[12]。
实验中,除了steganalyserS之外,本文还使用一个独立的steganalyserS*。定义了一个专用于隐写分析应用的滤波器F(0)[11]如下:
(9)
本文也使用RMSProp优化算法训练steganalyserS*,学习率为5×10-6,并更新变量β1=0.5,β2=0.999。以二进制交叉熵的形式来表示损失函数。
3.3 实验结果分析
在第一个实验中,本文比较生成图像与真实图像作为信息载体的安全性。首先将秘密信息嵌入到真实的图像中,使用steganalyserS*分类器进行分类;然后将秘密信息嵌入到生成图像中,也使用相同参数的steganalyserS*分类器进行分类。
实验结果如表1所示,在抗隐写分析方面,与真实图像隐写分析正确率88.37%相比,含密图像的表现明显优于真实图像;与SGAN和SSGAN相比,本文方案使得隐写分析正确性分别降低了13.1%和6.4%。可以得出本文方案生成的图像更加安全,更适合成为信息隐藏的安全载体。

表1 在生成图像上steganalyser S*的准确性 %Tab. 1 Accuracy of steganalyser S* trained on generated images %
在第二个实验中,为进一步验证生成样本的安全性,本文使用Qian网络结构,设置不同的先验噪声分布作为输入,然后用steganalyserS*分类器对各自的生成图像进行实验。具体实验设置如下:
1)使用相同的先验噪声分布;
2)使用一些随机选择的先验噪声分布;
3)使用与2)相同的先验噪声分布,同时改变WGAN周期数。
实验结果表明:实验条件1)下对生成的图像训练结果准确率为82.3%;条件2)下准确率为77.5%;条件3)下准确率为74.9%。通过改变不同的噪声输入和训练周期,可以使检测的准确性分别降低4.8%和2.6%。输入不同噪声分布,改变训练周期,本文方案生成的图像安全性进一步提高,可以更有效抵抗隐写分析。
经过对比可得:Stego-WGAN模型生成的图像更合适作为载体信息,同时更加丰富,视觉质量进一步提高。实验结果表明,新的信息隐藏方案在抗隐写分析和安全性指标上明显优于对比方案。
4 结语
本文提出了基于生成对抗网络的Stego-WGAN信息隐藏方案,为信息隐藏生成更合适、更安全的载体信息,基本上解决含密载体会留有修改痕迹的问题。使用CelebA数据集评估了Stego-WGAN方案的性能,实验结果表明Stego-WGAN方案在抗隐写分析、安全性上有良好表现,能够生成更高视觉质量的图像,有效抵抗隐写分析算法的检测。同时,本文首次改变了生成对抗网络的原始基本架构,为生成对抗网络在信息隐藏领域的应用提供了新思路。而如何改进生成模型G的结构,提高生成图像的性能,是下一步的重点研究工作。
