加权增量关联规则挖掘在通信告警预测中的应用
2018-11-22杨秋辉曾嘉彦樊哲宁张光兰
王 帅,杨秋辉,曾嘉彦,万 莹,樊哲宁,张光兰
(四川大学 计算机学院,成都 610065)(*通信作者电子邮箱yangqiuhui@scu.edu.cn)
0 引言
通信网络产生的大量数据如指令、告警,其中包含了对故障的检测预测十分有用的信息,通过对告警数据进行分析和挖掘,能够获得其中隐含的告警关联规则,当实时告警数据到来时,通过匹配告警关联规则,可对不久的将来可能发生的告警进行预测,从而指导网络故障管理。
当前,通信告警预测的解决方案主要有:基于神经网络的预测方法[1]、基于支持向量机的方法[2]、基于遗传算法的预测方法[3]、基于挖掘的时间序列预测方法[4-5]等。基于神经网络的告警预测技术具有较强的非线性映射能力和动态自适应能力;但是存在网络训练时间较长、难以选取输入变量和隐含层数及节点数、训练结果不稳定、容易陷入局部最优值等缺点。基于支持向量机(Support Vector Machine, SVM)的方法能在较少的样本上得到很好的预测效果;但是复杂度较高,并且存在过学习的问题。基于遗传算法的告警预测技术具有通用、鲁棒性强等特点;但是也存在随机性大、未成熟收敛、收敛速度低等问题。基于关联规则挖掘和序列模式挖掘方法的优点是不需要知道网络拓扑的关系,当网络拓扑结构发生变化时,可以通过对历史告警数据进行分析,自动发现新的告警模式,适应网络的变化,解决网络中出现的新问题;不足之处就在构建预测模型时需要多次扫描数据库,且候选项的数量巨大,导致构建效率较低。
本文考虑到不同属性、级别的告警表示的故障严重程度不一样,发出告警的网络节点在整个网络拓扑中的地位也不一样,因此,对通信网络告警数据进行挖掘时,需要综合告警属性和节点位置进行权值分配,从而实现对告警、故障的预测,使数据挖掘的结果对故障的分析、排查、修复更有参考价值。同时,由于告警数据库数据不断增加,带来两方面的问题:一是随时间增加,旧数据变得越来越不可信,因此要考虑数据新鲜度权值,适当增大新数据的权值比例;二是当数据增加时,重新挖掘原有告警数据库浪费时间、资源,因此,考虑对告警数据库进行增量维护,在利用原有的挖掘基础上,生成新的关联规则并删除旧的关联规则。基于上述需求,本文提出一种告警权值确定方法和基于自然序树(Canonical-order tree, Can-tree)的加权增量关联规则挖掘模型。
1 通信网络告警预测过程
加权增量关联规则挖掘的通信网络告警预测方案的流程如图1所示。

图1 本文方案的流程Fig. 1 Flow chart of the proposed plan
通信网络告警预测要对原始数据、增量数据、实时数据进行冗余去除、丢失处理和告警属性提取,并使用滑动时间窗将原始和增量告警数据库转换为事务数据库;结合网络拓扑结构的信息、已有知识对告警属性的认知和时序,为告警数据分配相应的权值,并建立数据表记录告警项的权值信息;将告警事务数据库中的事务信息压缩到Can-tree结构中,然后应用关联规则挖掘算法对Can-tree进行挖掘,生成告警关联规则,并将新增的事务数据添加到Can-tree结构中,再使用增量挖掘策略对Can-tree进行挖掘,并更新告警关联规则库;根据挖掘获得的告警关联规则建立预测模型,使用模式匹配的方法对未来一段时间会出现的告警进行预测,根据结果优化策略对预测结果进行优化,进行过滤和排序,并将优化后的预测结果呈现在用户界面上。本文将工作重心放在告警数据权值的确定、加权增量关联规则挖掘以及实时预测模型的构建上,以下进行详细阐述。
2 告警权值确定
本文从三个方面考虑告警权值:告警级别、告警节点重要程度和告警数据的新鲜程度。假设告警数据的权值为w,告警级别权值是wα(0≤wα≤1),根据发出告警节点在网络拓扑中的重要程度赋予的权值是wβ(0≤wβ≤1),告警数据的新鲜程度权值是wγ(0≤wγ≤1),每种权值分别对应的系数为α、β、γ(0≤α,β,γ≤1),则告警权值:
w=αwα+βwβ+γwγ
(1)
三个权值系数α、β、γ表示了告警级别权值、源节点重要度权值和数据新鲜度权值在总权值中的比重,具体的数值需要网络管理员根据网络的实际情况和需求进行设置,在本文中分别设置为0.4、0.3、0.3。
2.1 告警级别的权值
本文根据在某通信公司提供的告警数据中,涉及了提示告警、次要告警、重要告警和严重告警四种不同的级别,并设置对应的权值为0.25、0.50、0.75、1.00。
2.2 告警发生的节点重要度权值
参考文献[6]提出的告警节点重要度权值确定方案,本文对节点的重要度的权值评估主要从两方面考虑:
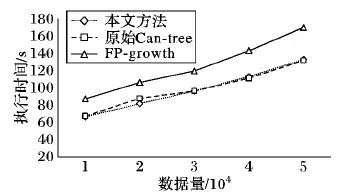
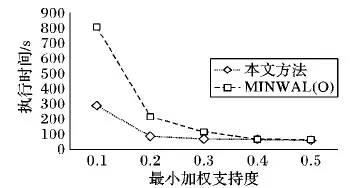
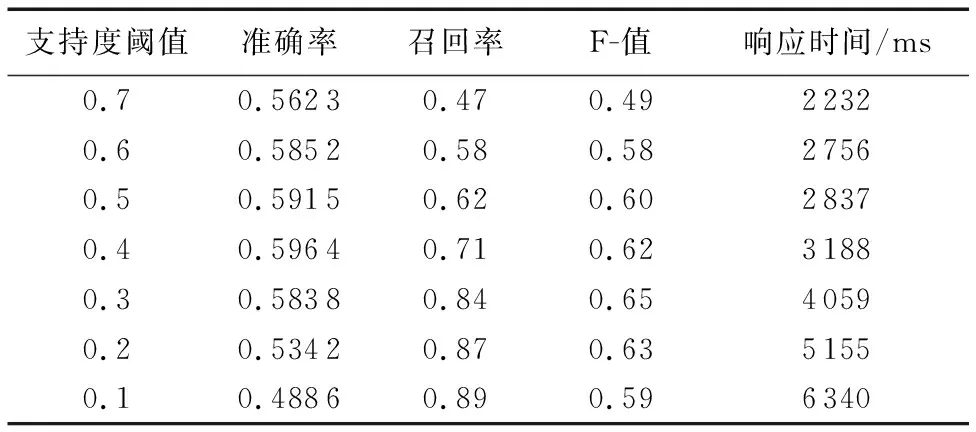
1)根据告警发生的节点分支数确定。分支数越大,网络上其他节点与该节点的业务关联越多,因此,节点分支数越大,其节点分配的权值越高;节点i的权值定义为i的分支数degreei(0 wβi=「degreei/degreemax⎤ (2) 2)考虑网络中的特殊节点。例如网络中某些承担关键服务的节点、两个子网的连接节点等,根据专家经验为这些节点指定权值。 参考文献[7]给出告警数据新鲜度权值确定方案,本文设现有原始通信告警数据库为DB,新增告警数据库为db,告警数据新鲜度权值为wγ。根据给定的时间单位(如年、季、月)将更新后的数据库DB∪db划分为n个时间段,那么第j(j=1,2,…,n)个时间段h_j的权值是: wγh_j=j/n (3) 对于历史数据中某一个数据项,其权值等于所在时间段h_j的权值。一个告警项可能存在多个时间新鲜度权值,在生成告警关联规则计算加权支持度时,需要对告警数据新鲜度权值求均值。现有告警项alarm,在时间段h1,h2,…,hn分别出现的支持度计数为S1,S2,…,Sn,那么告警项alarm的新鲜度权值是: (4) 通过数据预处理和告警权值确定,获得了原始告警事务数据库以及相应的权值信息,利用这些加工后的数据和信息,本文在Can-tree结构上进行加权关联规则挖掘。 对通信网络的告警数据库进行挖掘的目标,就是找出令人感兴趣的加权关联规则,然后进行应用。由于引入了权值,加权频繁项集的子集可能不再是加权频繁项集,在加权关联规则挖掘过程中并不能像传统的关联规则挖掘一样进行频繁项集的挖掘。文献[8]中首先提出了加权关联规则挖掘的MINWAL(O)算法,参照其定义,在加权关联规则挖掘中,令I为项的全集,Y为一个q-项集,且q (5) 如果包含Y的k-项集是频繁的,那么其最小支持计数应为: B(Y,k)=「Wminsup×|D|/W(Y,k)⎤ (6) 其中:Wminsup为最小加权支持度阈值;|D|是数据库事务总数。称B(Y,k)为项集Y的k-支持期望,令Bmin=min{B(Y,k)|q Support_count(X)≥Bmin(Y) (7) 时被称为加权潜在q-项集。 Can-tree中数据项的排序是事先指定的,不会受到数据更新的影响,也不会受到子节点支持计数的影响,如果数据项的排序确定了,Can-tree就是唯一的。因此,Can-tree的性质使得它非常适用于增量挖掘的,实现树结构的重复利用。本文结合邹力鹍等[9]提出的基于Can-tree的改进算法,即快速增量式关联规则挖掘算法(Fast Incremental Algorithm to Find Association Rules, FIAFAR),将加权关联规则的思想实现到算法中。改进思想主要体现在以下几点: 1)在原来的Can-tree设计中,由于只能够从父节点出发寻找子节点,当要得到某一项item的条件模式基,需要遍历整棵树结构,挖掘效率不高。因此,修改了树节点设计方法,将节点结构中的child指针修改为parent指针,逆转了指针方向,将树节点的遍历方向改变为自底向上进行,目的是减少剪枝时间和提高条件模式基的生成速度。 2)结合通信网络告警关联规则挖掘问题,将数据项的排序方式指定为根据数据项节点重要程度权值和项字典序组合的排序方式。由于节点的重要程度权值由节点分支数和专家经验确定,重要程度高的节点往往与之关联的网络节点较多,根据节点重要程度权值排序,当节点权值一样时再根据项的字典序排序,可以达到使更多的数据项共用前缀的目的,使Can-tree的压缩更紧凑,并且符合Can-tree排序方式不随挖掘数据集变化的要求。 3)FIAFAR对Can-tree改进后需要对数据库进行两次全面扫描:第一次扫描是获取各数据项及其支持计数,按照指定的排序方式对数据项进行排序并对项头表进行初始化;第二次扫描是将排序后的事务数据信息插入到Can-tree中。由于项头表中项的排序是已知的,因此项头表的建立和树结构的建立可以同时进行,在扫描过程中,将已经扫描到的事务数据按照指定排序方式排序,将新出现的项作为节点插入到项头表和树中,或对已出现的项进行计数值更新和指针链更新。本文对FIAFAR算法改进后,只需要通过一次的数据库扫描就完成Can-tree的构建,能减少构建树的时间。 3.3.1 对原始告警数据库的加权关联规则挖掘 改进后的Can-tree节点组成如下: ·项目名:item。 ·节点支持计数值:supcount。 ·由当前项指向前一项的节点:parent。 ·指向同名节点指针:back。 构建及挖掘Can-tree的步骤如下: 1)输入原始告警数据集,初始化树T的根节点为Null。 2)根据指定的排序方式初始化项头表T.head,该项头表的每一个节点T.head[i]记录第i项的支持计数值supcount和节点链信息list。 3)对数据库进行扫描,将事务数据按照指定的排序方式进行排序,然后按照建立前缀树的方式插入到T所标示的Can-tree中,并更新项头表中的节点和信息:现有支持计数为supc的事务trans,令事务trans中的每个数据项x,x的前一个数据项对应节点为pi,即pi为x在T中对应节点的父节点: ①判断x是否被项头表T.head记录,如果没有被记录,那么按照排序方式插入对应的head[x]节点到项头表; ②若x是trans中的第一个数据项,则pi为空,head[x].supcount增加supc; ③若x不是trans中的第一个数据项,且head[x].list节点链中存在一个节点N,N.parent=pi,则N.supcount增加supc;否则创建一个新树节点N,使其计数值设置为supc,并将N链接到其父节点pi,并修改head[x].list节点链,将新建节点链接到具有相同item的节点; ④令pi=N,为插入下一项作准备。 4)构建完成后,保存一份Can-tree树的节点索引信息用于增量挖掘。 5)从项头表最下面的item开始,沿着head指针链构造item的条件模式基。 6)遍历过程中,读取告警项权值记录表,修剪非频繁节点。 7)构造加权条件Can-tree。 8)递归挖掘每个加权条件Can-tree,直到Can-tree为空或Can-tree中只有一条路径,输出告警加权频繁项集,并根据加权置信度的概念生成告警关联模式。 9)记录每个item的挖掘结果和加权支持度参数。 10)整理挖掘结果,保存到告警关联规则库。 3.3.2 对增量Can-tree的加权关联规则挖掘 Can-tree中节点的顺序不会受到数据量变化或最小加权支持度阈值变化的影响,因此,当有新的增量告警数据库db需要挖掘时,按照以下步骤执行。 1)输入增量告警数据集,对增量告警数据集进行预处理,并计算各数据项的权值。 2)获取上次挖掘的Can-tree节点索引信息,恢复上次挖掘建立的未修剪的Can-tree。 3)遍历新增告警事务数据集,按照指定的排序方法对事务数据中的项进行排序,并根据构建Can-tree算法将新数据插入到树中,对Can-tree中的数据进行增量更新。 4)判断前次挖掘和本次增量挖掘的最小加权支持度是否发生变化: ①若发生变化,对整个Can-tree重新挖掘,并更新告警关联规则库。 ②若未发生变化,则利用上次挖掘的关联规则结果记录进行增量挖掘。自下而上遍历项头表中的item,与上次挖掘的项头表进行比较,根据item的计数值是否发生变化,分为两种情况:发生变化(包括上一次挖掘中item计数值为0的情况),那么重新构造当前item的条件模式基,重新挖掘包含item的频繁项集,并更新规则库;未发生变化,说明增量数据集中没再次出现数据item,那么只要对上一次挖掘中包含item的关联规则结果进行加权支持度和加权置信度的更新,并淘汰已经低于加权支持度阈值和置信度阈值的规则,并更新规则库。 5)保存当前挖掘建立的Can-tree结构和各item对应的结果集合,用于下次的增量挖掘。 对增量告警数据库的挖掘,增量策略主要体现在两方面:一是利用上次挖掘建立的Can-tree树结构,通过已有信息重建Can-tree树,节省了再次扫描原始告警数据库的时间;二是在生成加权关联规则过程中,利用了上一次挖掘的结果集合,对没有发生支持度计数改变的item的挖掘结果不需要重新挖掘,只需再次计算其加权支持度和置信度是否满足阈值即可。通过重复利用上一次挖掘的信息,算法提高了挖掘效率,节省了挖掘时间。 表1 告警数据样本Tab. 1 Alarm data samples 通过对告警事务数据库的关联规则挖掘,可获得满足用户参数的告警关联规则。告警预测结合实时告警数据和告警关联规则,进行规则匹配,对不久的将来可能发生的告警进行预测。 在告警预测之前,需要对实时告警数据进行预处理。相比历史告警数据的预处理,由于不需要对实时告警数据进行关联规则挖掘,因此预处理步骤较为简单,不需要结果滑动时间窗口的处理和权值计算,只需要对告警数据进行清洗即可。 在一定的时间窗口宽度width内,如果告警集合CausationSet出现了,那么告警集合CausationSet在下一个时间窗口内出现的可能性为b。因此,在实时告警预测中,如果在同一个时间窗口内的实时告警数据能够全部匹配CausationSet中的每一个项,即CausationSet中的每一个项都在同一个实时告警时间窗口内出现了,那么就可以推出在接下来的时间内,CausationSet会出现,且概率为b。 实时告警预测算法主要步骤描述如下: 1)读取实时告警数据,对实时告警数据进行预处理。 2)从关联规则库中读取告警关联规则,并存储到相应的数据结构中。 3)设置一个窗口宽度为width的时间窗口,时间窗口是一个长度为width的时间区间[StartTime,EndTime],将读取的第一个告警(E0,T0)的时间T0作为时间窗口的开始时间,即时间窗口区间为[T0,T0+width],依次读取告警实时数据,将告警数据放入时间窗口内,直至下一个告警超出时间窗口范围为止。 4)遍历告警关联规则,将时间窗口内所有的告警数据项集合s依次与关联规则的前件项进行匹配,判断关联规则前件中的全部项是否在集合s中都出现了,如果是,输出对应的预测结果;否则遍历下一条规则,再次进行匹配,直至遍历完所有的规则。 5)将时间窗口进行滑动,读入一个新数据(Ei,Ti),将新数据的时间戳Ti设置为EndTime,那么窗口的StartTime=EndTime-width=Ti-width,此时窗口区间为[Ti,Ti+width],清除窗口数据结构内超时的告警数据,然后将StartTime重新设置为窗口内时间最早的告警(Ek,Tk)时间戳Tk,更新窗口的EndTime获得新的时间窗[Tk,Tk+width]。然后尝试再次读入新的实时告警数据,直至下一个新的告警数据超出时间窗区间范围为止,重复步骤4)~5),直至所有的实时告警数据处理完毕。 6)处理预测结果集合,对预测的重复结果进行过滤,然后按照加权支持度、加权置信度参数进行排序并展现到用户界面,算法终止。 本文以某通信公司提供的通信网络告警数据为样本,表1展示了告警数据样本,对告警数据的特点进行分析,按照告警数据格式和分布规律进行数据仿真,仿真时长为2个多月,产出约20万条告警,包括了220个网络节点的296个不同的告警类型。 表2 告警级别数量表Tab. 2 Alarm numbers of each alarm level 本文使用数据挖掘领域中常用的模型性能度量标准对网络告警预测结果进行评估,包括了告警预测的准确率(Precision)[10]、召回率(Recall)[11]和F-值(F-Measure)等指标,使用响应时间(Response time)[12-13]作为告警预测效率的评价指标,对网络告警预测方案进行综合的评估。另外,对于增量挖掘算法的时间效率,使用算法的执行时间进行衡量。 实验数据包括两部分:一部分是原始告警事务数据集DB,另一部分是增量告警事务数据db,原始告警数据和增量告警数据共同组成更新告警事务数据集,即DB∪db。设置支持度阈值为0.3,置信度阈值为0.7。 5.1.1 与原始CAN-tree算法、FP-growth算法的比较 从图2~3可看出:对单一数据集而言,本文方法时间效率介于Can-tree算法和FP-growth算法之间,相对于改进前的原始Can-tree算法,明显提高了挖掘效率。 图2 原始告警数据集的建树时间比较Fig. 2 Can-tree construction time comparison of original alarm data set 图3 原始告警数据库的挖掘时间比较Fig. 3 Mining time comparison of original alarm data set 从图4~5可看出:本文方法在对更新告警数据库进行挖掘时,执行时间最低,挖掘地效率最高。从长远的目标来看,增量数据集越频繁地加入数据库,增量挖掘算法的时间效率越高,能够有效节省资源。 5.1.2 与加权关联规则算法MINWAL(O)的比较 从图6~7可看出:本文方法和MINWAL(O)随着最小加权支持度升高(加权频繁项集变少),执行时间快速下降然后逐渐趋于平衡,而本文方法的变化趋势比MINWAL(O)平缓得多;随着数据库的增大,本文方法和MINWAL(O)的执行时间变长,本文方法增长较为缓慢,并且时间效率上优于MINWAL(O)。因此,本文方法具有较好的挖掘效率和伸缩性。 图4 更新告警数据库的建树时间比较Fig. 4 Can-tree construction time comparison ofupdated alarm data set 图5 更新告警数据库的挖掘时间比较Fig. 5 Mining time comparison of updated alarm data set 图6 不同最小加权支持度下执行时间比较Fig. 6 Execution time comparison with different minimum weighted support 图7 不同数据量的执行时间比较Fig. 7 Execution time comparison with different amount of data 考虑实际的告警数据产生速率以及预测结果的输出时间,将告警数据的设置告警时间窗口大小为30 min,比较本文方法在不同的加权支持度阈值下的挖掘效果如表3所示。 表3表征本文方法在不同加权支持度阈值情况下告警预测的表现。可以看出,随着支持度阈值降低,准确率缓慢上升后逐渐下降,这是因为随着加权支持度阈值的降低,挖掘出的告警关联规则越多,当加权支持度阈值过高时,由于挖掘出的告警关联规则太少,较难进行有效预测;当加权支持度阈值过低时,挖掘出的告警关联规则大幅增加,导致预测的准确率降低。召回率随着加权支持度阈值的减小而增大,这是因为加权支持度阈值越小,挖掘出的告警关联规则模式越多,正确预测的告警数量也越多。对于算法预测的响应时间,可以看到,随着加权支持度阈值降低预测响应时间逐渐增加,这是因为支持度阈值越小,生成的告警关联规则就越多,实时告警与关联规则匹配需要的时间就越多。但告警预测时间一直保持在秒级范围内,可以满足用户快速获取告警预测信息的需求。 表3 本文方法在不同的加权支持度阈值下的挖掘效果对比Tab. 3 Mining effects of proposed algorithm with different weighted support thresholds 为提高通信网络告警预测的准确度、缩短预测模型的训练时间,本文提出了基于Can-tree的加权增量挖掘的告警预测方案。实验结果表明本文方案能有效地预测网络告警,并通过本文提出的权值确定方案提升告警预测的价值,在较短的时间内完成挖掘和预测工作,使网络管理员能够提前作好保护、预防等措施,减少网络故障引起的损失,提高网络的可靠性和稳定性。本文方案还存在一些不足之处,未来的研究方向和工作包括但不限于:告警权值的考虑还可以更全面;使用滑动时间窗口处理告警数据库时,可以添加对告警数据的自适应调整的窗口宽度、步长策略;在告警预测阶段,考虑加入机器学习的算法,提高预测的准确率和可信度。2.3 告警数据新鲜度权值
3 加权增量关联规则挖掘
3.1 相关概念
3.2 算法改进思想
3.3 算法描述


4 实时告警预测
4.1 实时告警数据预处理
4.2 实时告警预测
5 实验分析

5.1 关联规则挖掘算法的性能比较实验




5.2 告警测试方案的有效性实验
6 结语
