基于机器学习方法的吉林大米产地确证模型研究
2018-11-19王靖会臧妍宇陈美文于合龙
王靖会 臧妍宇 曹 崴 崔 浩 郑 晖 陈美文 于合龙
(吉林农业大学信息技术学院1,长春 130118)
(吉林农业大学食品科学与工程学院2,长春 130118)
随着食品贸易的全球化发展和粮食供给侧改革的推进[1],具有原产地保护(Protected Designation of Origin,PDO)和地域特色标志(Protected Geographic Indication,PGI)的农产品在过去几年中受到普遍的认可[2]。吉林省地理标志大米由于其地理位置和气候环境独特,其米饭清香四溢、营养丰富,随着人们对健康和天然食品的需求日益增长,具有多重优势和独特品质的吉林大米闻名全国。然而,由于内在的商业价值和产地确证技术的欠缺,针对地理标志大米的欺诈和模仿已严重干扰了大米市场,因此,确定地标大米(地理标志大米)原产地已成为一个严重的社会问题,迫切需要进行吉林大米产地确证技术研究。
国内外文献表明,产地确证研究应用的机器学习技术主要有支持向量机[3]、人工神经网络[4]等技术。Alcázar等[5]为区分欧洲啤酒(德国、西班牙和葡萄牙)地理产地,利用线性判别分析和支持向量机对20种元素变量判别力进行了研究,结果显示,通过线性判别分析可在数据集中找出5个最有判别力的变量,结合交互算法可获得支持向量机模型最优超平面,模型的灵敏度和特异性分别(99.3 ±1.2)%、(99.5 ±0.8)%。Binetti等[6]对阿普利亚的四个最有代表性橄榄油品种进行了神经网络训练和验证,利用四个不同的数据集标准、两种隐藏层数量、5种神经元数量来验证预测因子,其结果表明,最小绝对收缩和选择算子算法作为预测因子的人工神经网络模型的准确率最高(88.2%)。Chung等[7]为研究区分亚洲大米地理产地的可行性,通过主成分分析和最小二乘判别模型评估6个国家的地理产地,其研究结果表明,主成分分析无法区分日本和菲律宾的大米,最小二乘判别模型可以区分韩国和其他国家的大米。Cheajesadagul等[8]通过主成分分析和判别分析对泰国香米和法国、印度、意大利、日本和巴基斯坦大米进行了产地分类,基于多变量的主成分分析结果显示,通过 B、Sr、Mo、Se、Cd、Cu、Mg 等元素可以区分泰国大米、欧洲大米和亚洲大米的地理产地,但主成分分析无法对泰国香米的北部、东北部和中部地区进行分类,判别分析方法可较好地区分泰国香米的这三个产区,结果显示对泰国东北部地区的分类精度最高(100%),对中部地区的分类精度最低(71.43%)。
在大米产地确证方面,研究对象大多限于地理空间距离较远的不同国家或省份,研究方法多采用主成分分析、判别分析等多元线性分析方法。我国现已拥有多个具有PDO/PGI认证的地理标志大米,其中多数产区具有相似的地域特征和属性,由于地区气候和地形特征等因素的制约,限制了水稻生产的集约化规模,又导致了稻作区域特征信息在地球化学因素、环境气候、加工因素和人为因素等方面的差异性和复杂性,现有的化学计量学结合多元线性模型无法有效解决产地分类问题。机器学习方法克服了参数和非参数统计方法的缺点,如空间自相关,非线性和过拟合[9],提高了空间模型的预测精度,尤其近年来,随着食品数据量的激增和产地分类研究的不断深入,目标元素的数量级别和样本处理量越来越大,考虑到大数据分析的发展趋势和食品认证现场数据的潜在需求,机器学习方法对于大米产地确证的重要性日益明显。
为探究不同机器学习方法建立的产地确证模型对邻近相似地域的分类效果,筛选出构建分类模型的特征变量,深层次挖掘数据中的隐藏模式,本研究对吉林省具有PDO/PGI认证的柳河大米与辉南大米进行数据挖掘研究,采用支持向量机、随机森林和人工神经网络三种机器学习方法进行模型开发,通过F-score进行变量评估和特征选择,为进一步建立吉林地理标志大米产地数据库及确证平台,探究农特产品产地确证体系提供参考。
1 材料与方法
1.1 数据来源
1.1.1 样本采集
本研究选择吉林省柳河县和辉南县作为研究区域,该区域位于北纬 42.28°N ~42.68°N,东经12125.73°E ~126.03°E。为避免在不平衡数据集中,分类器偏向大多数类,忽略了少数类的重要性,进而影响分类模型的预测性能,本研究采用空间分层采样方法在柳河县采集62个样本,辉南县采集58个样本,具体采样区域及采样点分布如表1所示。

表1 大米样本采集点分布表
1.1.2 仪器与试剂
JLGJ4.5砻谷机;HNMJ3碾米机;JXFM 110锤式旋风磨;AA-6300原子吸收分光光度计。
检测样本主要试剂包括硝酸、高氯酸、盐酸和氢氟酸溶液。
1.1.3 检测方法
根据我国 GB/T 14609—2008、GB/T 5009.91—2003、GB5009.12—2010 检测铜(Cu)、锌(Zn)、铁(Fe)、锰(Mn)、钾(K)、钙(Ca)、钠(Na)、镁(Mg)、铅(Pb)、镉(Cd)10种矿物质元素。
其中,Pb、Cd采用石墨炉原子吸收分光光度法,Fe、Na、K、Mg、Ca、Mn、Zn、Cu 采用火焰原子吸收分光光度法。
1.2 机器学习方法
1.2.1 人工神经网络
人工神经网络(Artificial Neural Network,ANN)是基于生物神经网络结构的非线性统计数据建模工具,由一组相互关联的计算单元或人造神经元组成[10-11]。其中反向传播人工神经网络(Back -Propagation Artificial Neural Network,BP -ANN)因其体系结构简单,模型构建方便,计算速度快被广泛应用。BP-ANN模型的体系结构如图1所示。

图1 反向传播人工神经网络结构图
1.2.2 随机森林
随机森林(Random Forest,RF)是一种集合学习算法,其主要思想:首先,利用bootstrap抽样方法(有放回)从原始训练集D中抽取k个样本集{},且每个样本容量均与原始训练集一致;其次,对k个样本集建立k个决策树模型形成森林,每一个决策树模型均从M个属性中随机选取m(m<<M)个属性,得到组合的分类器,利用k个模型对测试集分别进行分类,得到k种分类结果;最后对k种分类结果累计投票决定其最终分类结果[12]。这种分类方法大大降低了计算成本,加快了运算速度[13]。
1.2.3 支持向量机
支持向量机(Support Vector Machines,SVM)是一种二元分类器,其主要思想是建立一个超平面作为决策曲面,使得正例和反例之间的隔离边缘被最大化,即求最优分类超平面[14]。这不仅减少了预测误差的可能性,而且还降低了过度拟合的风险[15]。
在支持向量机中可以使用核函数解决非线性分类问题,等价于将数据映射到高维空间并定义分割超平面。常用的核函数有:多项式核函数(Polynomial Kernel Function)、径向基核函数(Radial Basis Function,RBF)、Sigmoid 核函数等。
1.3 特征选择方法
所有的原始变量对于建立分类模型并非都有积极作用,其中存在一些与数据集分布不相关的噪声数据,这些冗余噪声会降低模型的分类性能并增加分类器的计算成本,同时变量间的多重共线性也会影响分类模型的预测准确度。特征选择是常见的降维方法,基本思想是从原始数据集中选择最优的特征变量子集去构建分类模型,不仅能够提高模型的泛化能力、可理解性和计算效率,而且降低了“维度灾难”的发生频率[16]。F-score算法是典型的特征选择方法,其本质是选取类内差异小,类间差异大的特征[17],可以通过衡量特征子集在两类之间的分辨能力,从而实现有效特征的选择。F值越大表明该属性的辨别能力越强,对分类模型的贡献率就越大。F值的计算如公式(1)所示。
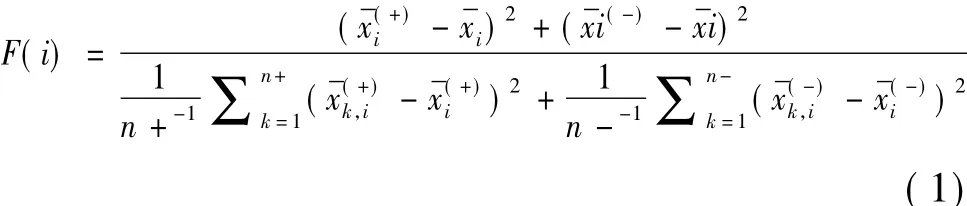
1.4 模型评估方法
为评估分类模型的性能,通常将数据分成两组子集,一组用于训练模型,一组用于测试训练的模型。训练集数量一般选取样本总数的2/3[18-20]。
1.4.1 K 折交叉验证
K折交叉验证技术是常用的评价模型方法,能够解决过度适应的问题,因此被广泛应用于分类器性能评测领域[21]。其主要思想是将原始数据集随机分为K份大小相近但不相交的数据集,将K-1份数据集作为训练集,剩余的1份作为测试集,通过训练集得到一个分类模型,然后用测试集调整参数Wi,i=1,…,m,即每一个个体分类器的权重因子,基于训练集得到的分类模型就可以通过测试集来进行评估[22]。为了获得稳定的结果,将该过程重复n次,根据n次检验的平均正确率作为模型分类的最终结果。
1.4.2 混淆矩阵
混淆矩阵是一种用可视化方式来呈现算法性能的评价标准,它通过矩阵描述样本数据的真实类别属性和预测结果的关系[23]。混淆矩阵由真正例(True Positive,TP)、假正例(False Positive,FP)、真反例(True Negative,TN)、假反例(False Negative,FN)四部分组成,总样本数为四者之和。分类模型的准确度、灵敏度和特异度三个性能指标的计算如公式(2)、(3)、(4)所示。

式中:TP为真正例;TN为真反例;FP为假正例;FN为假反例。
2 结果与讨论
本研究以R语言实现BP-ANN、RF及SVM的建模过程,建立柳河大米及辉南大米的产地确证模型。为保证数据划分的随机性和一致性,运用R3.4.2软件内的sampling程序包中的strata()函数实现分层抽样,将原始数据集的120个样本以2∶1的比例划分为训练集和测试集,并保证来自于柳河与辉南的大米样本比例一致,80个训练集样本用于模型的建立和优化,40个测试集样本用于外部精度检验。
2.1 大米矿物元素的差异性
柳河县与辉南县大米样本的矿物质元素检测含量如表2 所示,两产地中的 Cu、Zn、K、Ca、Na、Pb、Cd八种矿物质元素之间存在极显著差异(P<0.01),Mn元素表现为显著性差异(P<0.05),Mg元素和Fe元素差异性不显著,由此可知两产地之间的Cu、Zn、K、Ca、Na、Pb、Cd、Mn 具有其各自的特征,存在一定的差异性,采用矿物元素指纹信息进行产地确证具有可行性,可进一步探讨。
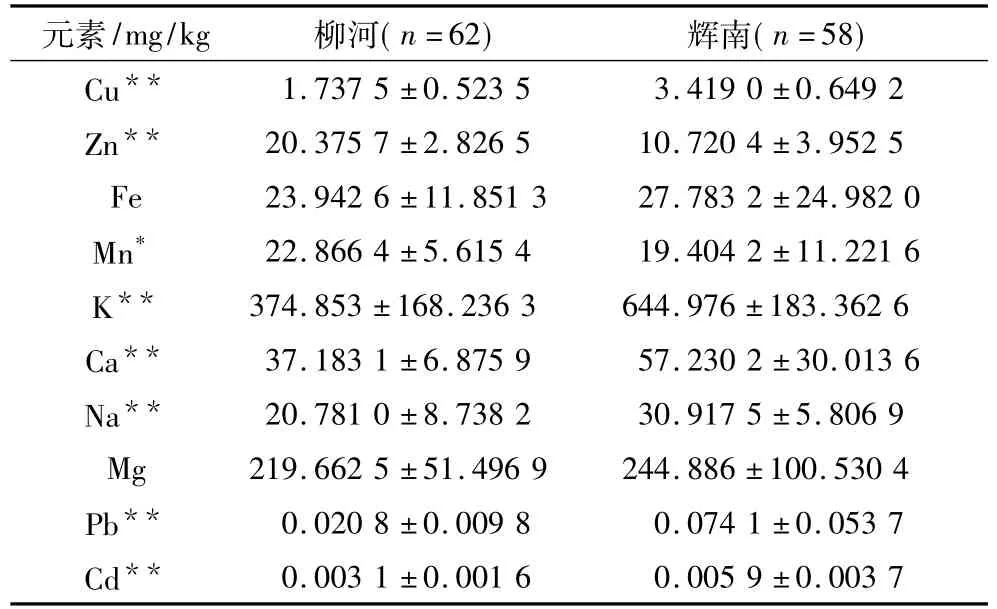
表2 柳河大米和辉南大米的矿物质元素含量
2.2 模型建立与优化
2.2.1 BP -ANN 模型
本研究运用R3.4.2软件的AMORE程序包建立3层BP-ANN模型。按照变量个数及输出类目设定输入层为10,输出层为1,根据网络训练时间和模型泛化能力设置中间层的隐层数为1。隐含层节点数对于建立BP-ANN模型至关重要,根据公式(5)计算出其选择区间为4~14,经遍历后获得隐层节点个数与BP-ANN模型准确率的变化曲线,如图2所示。从图2中可以看出,隐层节点数为6时,此时模型的分类能力最好,分类准确率为72.5%;当隐层节点数为7时,此时模型的分类效果最差,分类准确率仅为45%。所以,建立10-6-1结构的BP-ANN

式中:L为隐含层节点数;n为输入层节点数;m为输出层节点数;a为0~10之间的常数。
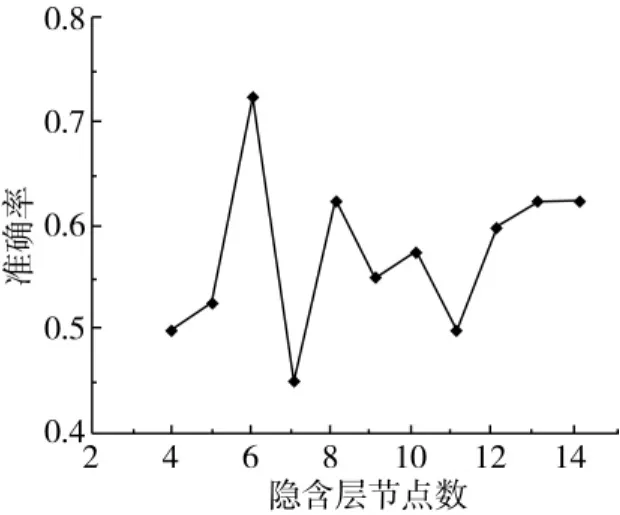
图2 BP-ANN中不同隐层节点数的模型准确率
产地确证模型能够达到产地分类的目的,但是分类效果一般,尚需要进行进一步优化验证,提高模型的分类能力。
2.2.2 RF 模型
本研究使用R3.4.2软件中的Random Forest程序包建立RF模型。随机特征变量个数mtry和决策树数量ntree两个参数的值直接影响RF模型的性能,需要选取最优参数值进行模型训练。特征变量mtry的值,通过实际模型的袋外估计误差进行选择,通常选择误差最小的mtry值,特征变量ntree的值则选择误差区域稳定时的值,此时建立准确率较高的RF模型。随机森林mtry和ntree值误差寻优的过程如图3和图4所示。当mtry=3时,此时模型袋外误差估计值最小,最小误差为0.001 89;当ntree=500时,此时模型袋外误差估计值开始趋于稳定,不再随着tree值的增加而波动。因此,选择mtry=3,ntree=500建立随机森林模型,此时模型的准确率可达到为100%,可以准确的对柳河和辉南两产地进行分类。
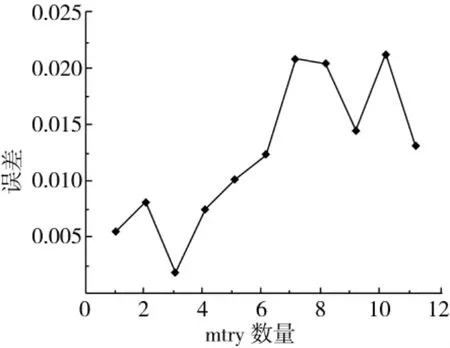
图3 mtry参数寻优

图4 ntree参数寻优
2.2.3 SVM 模型
本研究使用R3.4.2软件中的e1071程序包建立SVM模型,选择对噪声数据有良好抗干扰能力的径向基核函数(Radial Basis Function,RBF)。RBF核函数建模时需要设置核函数gamma值和惩罚因子cost值,这两个参数对核函数的性能有很大的影响[24]。gamma值和cost值的寻优过程如表3所示。从表3中可以看出,当gamma=0.062 5,cost=1时分类模型误差最低,此时,error=0。因此gamma参数值确定为0.062 5,cost参数值确定为1,此时建立的SVM模型准确率可达100%。
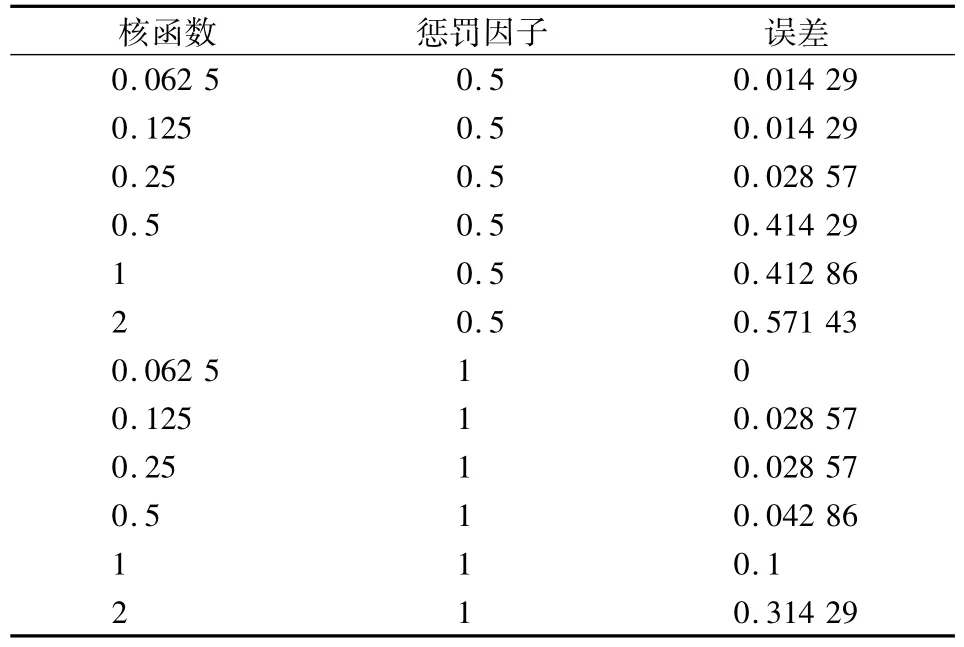
表3 SVM参数寻优
2.3 特征变量选择
通过F-score算法,对10种矿物质元素(Cu、Zn、Fe、Mn、K、Ca、Na、Mg、Pb、Cd)进行特征选择,结果如图 5所示,各元素的 F-score值分别为:Cu=7.593 2,Zn=2.991 9,Pb=2.644 6,Ca=2.179 4,Cd=0.769 3,K=0.661 49,Na=0.345,Mn=0.097 5,Mg=0.061 5,Fe=0.026 9,10 个元素的整体平均值为 1.737 1,其中 Cu、Zn、Pb、Ca 4 个元素的F-score值大于整体的平均值,对于建立大米产地确证模型具有较高的贡献率,可作为建立模型的特征变量。

图5 两个产区大米中矿物元素的F分数
2.4 模型性能评估
三个模型的建立与优化均在相同的训练集中,而测试集从未参与任何模型的建立,训练集和测试集样本均通过分层抽样等比例抽取,因此基于测试集的三个模型的分类精度可以有效代表模型对未知样本的预测能力。
本研究中混淆矩阵的预测类别和真实类别设置如表4所示。根据每个模型的分类混淆矩阵,计算相应的准确率,灵敏度和特异度,进而评估模型的预测性能。其中,准确率表示柳河产区及辉南产区大米样本整体的分类精度,灵敏度表示柳河产区大米样本正确分类的精度,特异度表示辉南产区大米样本正确分类的精度。

表4 柳河大米和辉南大米产区分类的混淆矩阵
在计算出F-score值的基础上,建立特征变量集合K,K={k1,k2,…k10},子集k1仅包含贡献率最高的元素,子集k2包含贡献率前两名的两个元素,依此类推,最后一个子集k10包含所有原始变量,即变量子集 k1={Cu},k2={Cu,Zn},… ,k10={Cu,Zn,Pb,Ca,Cd,K,Na,Mg,Mn,Fe},通过逐步添加属性变量训练模型,能够观察到每个属性变量对模型预测性能的影响。
在10次10折交叉验证下,按照F-score值得到的变量子集,依次对BP-ANN、RF和SVM 3个模型进行评估比较,得到准确率的变化如表5所示。从表中准确率判断,仅用 Cu元素建立的产地确证模型就达到了较高的分类精度(BP-ANN:94.29%;RF:87.40%;SVM:91.52%);RF 模型和SVM模型的分类精度随着特征变量的增加而提高,其中 RF 模型在变量子集为 k6(Cu、Zn、Pb、Ca、Cd、K)时判别准确率达到100%,SVM在变量子集为k3(Cu、Zn、Pb)时即可达到判别准确率为100%,同比BP-ANN模型的分类精度则有较大变化,在k2变量子集时,判别准确率为99.17%,k3变量子集中虽然增加了Pb元素,但判别准确率并没有变化,而随着其他矿物质元素变量的逐步增加,模型的分类精度反而呈下降趋势。
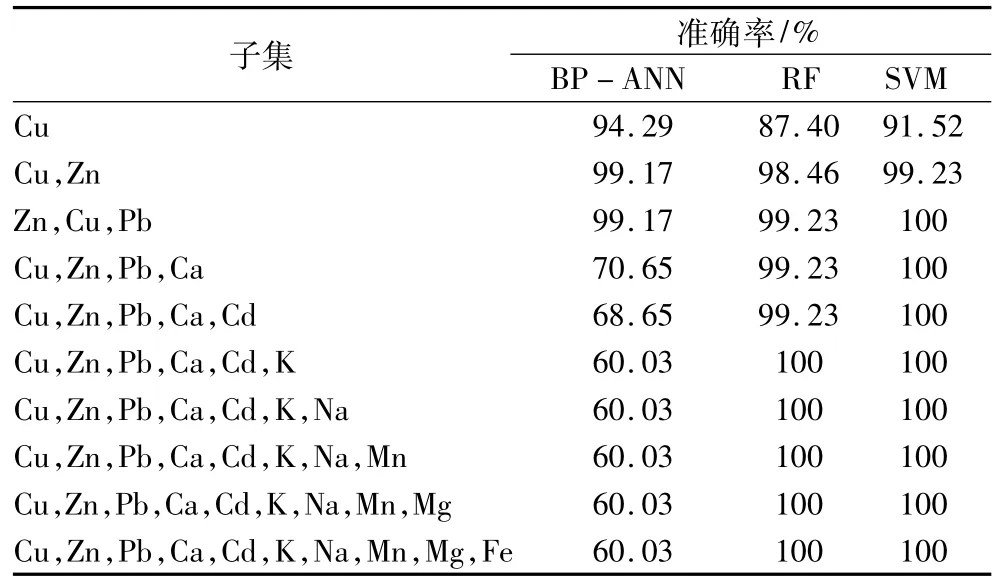
表5 使用不同的变量子集的模型分类精度
BP-ANN、RF和SVM选取其准确率最高的变量子集结果,计算其对应的灵敏度和特异度,结果如表6所示,RF模型和SVM模型的灵敏度均为100%,而BP-ANN的灵敏度98.61%,存在将柳河大米数据错分成辉南产地的情况。三个模型的特异度均为100%,模型预测性能优异。
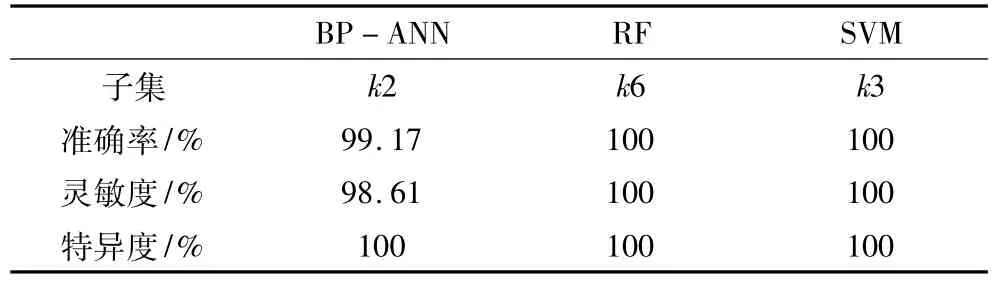
表6 大米产地确证模型的最佳性能比较
从检测成本及运算代价上评价,选择Cu和Zn两个变量建模时三个模型均达到了很高的预测精度,此时 SVM(99.23%)>BP-ANN(99.17%) >RF(98.46%);从预测准确率上评价,SVM与RF均可达到100%,而BP-ANN最高精度为99.17%,略逊于其他两个模型。
三种机器学习方法就柳河县与辉南县两个产地确证而言,各自的最佳模型分别是:用(Cu,Zn,Pb)训练出来的准确率100%的SVM模型,用(Cu,Zn,Pb,Ca,Cd,K)训练出来的准确率100%的RF模型,以及用(Cu,Zn)训练出来的准确率99.17%的BP-ANN模型。
3 结论
研究结果表明,采用机器学习方法建立的产地确证模型是有效的,BP-ANN、RF和SVM三种模型均达到了较好的预测性能。通过三个模型之间交叉验证结果和混淆矩阵结果的比较可得到,RF模型和SVM模型分类精度优于BP-ANN模型。SVM模型相比于RF模型对变量更加敏感,能够以更少的特征变量建立柳河与辉南的产地确证模型。
值得关注的是,在区分柳河县与辉南县的大米样品过程中,Cu元素在整个模型建立过程中起着重要的作用,尽管随着特征变量的逐渐增加,模型的性能有所提高,但不能忽视单个Cu元素就达到了较高的分类精度,可以将其作为代表该地区空间特征的典型变量。
本研究中BP-ANN、RF和SVM产地确证模型的建立与比较和建模特征变量的选择对于开发该区域地理标志大米数据库及确证平台有积极意义,随着样本数据量与空间特征维度的不断扩充,机器学习方法将更能展现其强大的学习能力,产地确证模型也将不断完善。该方法能够为我国农特产品质量安全保障、地理标志产品品牌权益保护以及建立健全产地确证体系提供一定的参考。
