基于多指标模糊综合评价模型的小麦品质评估
2018-11-19蒋华伟周同星
蒋华伟 周同星
(河南工业大学信息科学与工程学院,郑州 450001)
品质状态的正确评估是小麦储藏和检测中的一个重要环节,也是粮食工作者和研究者最关心的问题,准确地判断出小麦的品质状态有助于粮食管理人员及时调整储藏条件、快速处理已变质的小麦,从而降低损失、提高储粮的安全系数。近些年来,国内学者在包括小麦在内的粮食储藏基础特性等方面做了大量的前期研究与探索,并取得了较大进步。如宋建民等[1]对小麦蛋白质品质和与蛋白质相关的因素如沉降值、筋力进行了研究;以及在常温、低温两组粮仓内,通过多年的实验证明脂肪酸值随着储藏时间按一定规律逐年升高,从而认为脂肪酸值是小麦储藏品质控制的指标之一[2-3]。张钟等[4]对小麦发芽前后的内部成分,如总淀粉、灰分及粗脂肪、容重和部分矿物质维生素等做了实验研究,经过数据分析得出发芽时间、水分、还原糖等不同因素对小麦品质的影响。
这些研究工作在一定程度上给出小麦在不同储藏时期内品质指标的变化,为小麦品质的评估奠定了基础,但是这些研究没有考虑小麦的各种生理生化指标在判断小麦品质的综合作用,仅分析单一的生理或生化指标,不能准确表达出小麦品质的真实状态。由于小麦的不同生理生化指标具有复杂的数量关系,且具有一定的模糊性,很难精确描述和计算,所以需要对各指标进行模糊处理[5-10],再进一步融合分析获得小麦品质的实际状况。尽管模糊数学分析方法在小麦品质处理方面涉及不多,但它已在建筑、机械等行业有着广泛的应用,如孙松[11]在轴承性能状况的评价中,采用了模糊评价模型等相关模糊数学方法,对轴承进行状态的定量化评价;黄必清[12]等也成功用模糊综合算法评价得出多级因素中海上直驱风电组运行的状态。这些研究工作虽然给出了对多指标因素的融合评价,但基本上都是采用专家征询法和经验法来确定各因素所占的权重系数,分析结果主观性比较大。
为了能准确表达小麦的品质状况,避免由单一因素判定和多因素集融合过程中所带来的误差[13-14],本研究尝试采用一种新的评估方法,即基于小麦的多个生理生化指标数据,通过对各指标因素集标准差的分析计算,得出权重系数,再引入劣化度[15-18]和隶属度函数,构建较为合理的小麦综合评价模型,求得多指标融合后的小麦品质状况,为小麦安全储藏和评价提供一定的技术支撑。
1 评价因素集和权重系数的确定
1.1 因素集的确定
在理论上,小麦品质评价因素的选择需要考虑到反映小麦生理生化特性的全部指标,但是在具体的计算中,所能计算的指标有限,所以应选取代表性强、测量方便、被研究与实验所认可的因素。本文基于以前对储藏小麦品质评价的研究基础,选取在小麦储藏和评价中起重要作用的因素如下:
脂肪酸:是小麦品质变化的重要生化指标,脂肪酸含量对小麦食用品质和种用品质都有很大影响;在小麦储藏期间,由于水解作用使脂肪酸值升高,种子生活力显著下降,一般它在物理性状还没有显示之前就已经引起品质的变化,意味着粮食劣变的开始。
降落数值:它是反映了小麦籽粒中a-淀粉酶活性大小的因素,它通过a-淀粉酶活性来显示小麦的生化活性。
沉降值:是小麦生理品质的重要指标之一,它与小麦的高分子质量谷蛋白亚基(HMW-GS)和谷蛋白大聚体(GMP)有着显著的相关性,与小麦面包品质有着直接联系,反映小麦中粗蛋白含量多少和质量差异。
还原糖:是反映小麦生化活性的重要因素,还原糖含量因淀粉水解上升,随呼吸消耗而下降。在储藏过程中,还原糖含量上升后再下降即意味着粮食劣变的开始。
发芽率:是小麦的生理指标,随着时间延长,种子丧失生活力,发芽率逐渐下降,一般发芽率高的小麦食用品质好,而食用品质好的发芽率不一定高,所以把发芽率当成一种参考指标。
本研究把脂肪酸值、降落数值、沉降值、还原糖和发芽率作为小麦品质评价模型的因素。
1.2 指标权重系数的确定
评价指标的权重反映了各因素对评价对象的重要程度,对各指标分配合理的权重是本文多指标模糊计算的关键。目前,在小麦品质评价的体系中关于指标因素的重要性还没有明确的界定,即在权重中占据比例的大小还没有统一的规定。本文从小麦的数据分布方面来构建合理的权重系数。
在获取实验数据前,由于不知道小麦品质的具体情况,小麦品质可能是优良,数据比较集中,标准差较小;也可能一部分品质已经发生了劣变,数据比较分散,标准差较大;而小麦指标与品质变化间隐含着某种规律,通过标准差来体现,需要由标准差来确定各指标权重系数。
因此,本研究拟根据数据内部的关系来确定各因素的权重系数,方法是分析计算因素集里的标准差的大小,若标准差较小,说明该因素的数据比较密集,它间接显示对应指标可准确反映小麦品质状况,就应赋予较大的权重系数;若标准差较大,则因素的数据分散,说明在指标本身或在测量过程中存在较大误差,应赋予较小的权重系数。
由于5个因素是反映储藏小麦品质变化的不同指标,物理含义有别,数量值差别较大,虽然每个因素数据的标准差可以独立地反映对应指标的分散程度,但是并不能作为权重系数的指标作为计算,本文设计出一种算法来解决这个问题,具体步骤如下:
1)计算各参数的基本数据,包括各评价因素的平均值 ai,标准差 bi,缩放后的标准差 ci(i=1,2,3,4,5,分别代表降脂肪酸值、降落数值等评价因素)。
2)经计算选脂肪酸值的标准差b1=c1作为标准化的基准,将其他四个因素的标准差缩放到与脂肪酸值同一数量级。
3)求其他各因素缩放标准差ci,将ai与a1的比值作为放缩的依据,再对各标准差bi进行放缩计算,具体计算公式如下。

4)由于标准差越大的值,数据内部相关度越低,该因素数据的信服力也较低,所以把1/ci作为权重系数,组成权重系数矩阵A。

2 品质指标的归一化
由于评价指标参数的物理意义和单位都不相同,例如文中储粮品质的五个指标的单位、量级和物理意义明显不同,为了能够对这些指标因素进行综合对比分析,应将初始数据值进行归一化处理。考虑各指标所代表的特定物理意义,需要选择某一指标作为统一衡量的标准,将不同量级的储粮数据输出到0~1之间的数值,而劣化度函数在统一度量方面有着优势,文献[6]和文献[7]通过相关计算分析体现了这一作用,本文将引入并改进劣化度函数(越小越优型、中间优型和越大越优型三种劣化度函数)作为处理五个储粮指标的算法。由于本模型评价的是一批小麦的总体品质状况,单个小麦的数据并不能反映总体的品质特征,取该批小麦每种因素集的平均值x作为劣化度函数参数x的值,根据这五个指标参数的不同特点,分别采用下面相应的劣化度函数。
小麦脂肪酸值和降落数值会随着时间的推移使小麦品质劣变程度变大,所以这两个指标参数采用越小越优型的劣化度函数。计算中涉及最大值xmax和最小值xmin的估计。其劣化度函数为:
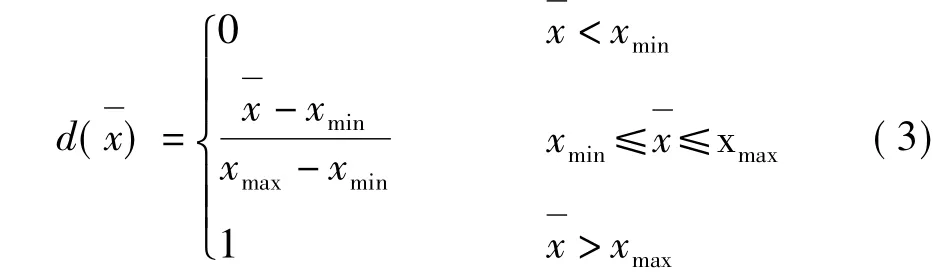
小麦的还原糖含量在储藏过程中变化趋势是先增加后减少,但最终含量与最初的相比,变化幅度不大,所以这个指标参数采用中间优型的劣化度函数。需要估计该变量的最佳范围[xa,xb],其中xa和xb是由历年小麦数据统计获得。其劣化度函数为:

发芽率表达小麦种子的生活性,沉降值代表的是小麦蛋白含量,这两个值越大越好,所以这两个指标采用越大越优型函数。其劣化度函数为:
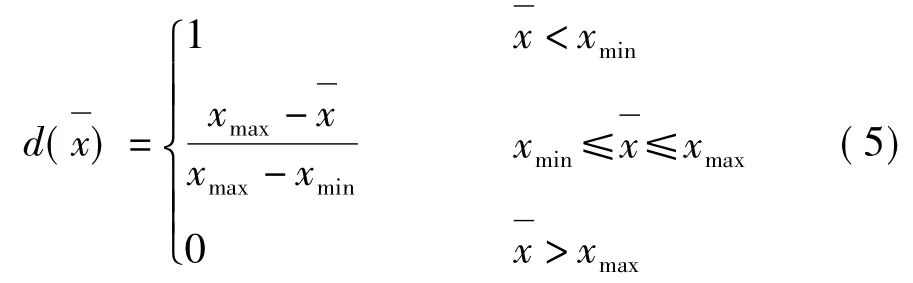
根据不同因素集的类型,由小麦的具体数据分别求出劣化度函数需要的极值和最佳范围,再将各因素的五个平均值x分别带入上函数,得到劣化值d=[d1,d2,d3,d4,d5]。
3 隶属度及评价矩阵
根据储藏小麦品质评价的实际需要,本文在应用模糊评价方法处理时,将小麦品质状态分为“优”“良”“中”“差”四个评价等级,建立如下评语集:

经过劣化度处理后的指标取值处于[0,1]之间,还要选取能够涵盖这些劣化度取值的隶属度函数。常见的隶属度分布函数有矩形、梯形、高斯、正态和岭型分布。考虑到优、良、中、差四中隶属度要互有交叉重叠的模糊区域,且希望数值在模糊区域能向两边靠拢得快一点,以便有较大的区分度,满足这些条件的只有高斯分布和岭型分布;由于高斯分布参数要求严格不易获得且计算复杂,所以采用岭型函数(升岭型、中间岭形和降岭形)来计算各指标对不同评价等级的隶属度。由岭形函数的特性,数值较小的数据用降岭形分布处理,数值较大的数据用升岭型数据,中间分段的数值采用中间岭形分布。
根据本文前面对储粮品质的描述、劣化度的计算和岭形函数的分布特点,对评价为优的数据应采用降岭形分布,评价为良和中的采用中间型岭分布,差评价的隶属度采用升岭型分布。考虑到隶属函数要有一定的交叉性,并且交叉重叠率要保持在一定的范围内,本文令交叉重叠率为0.2,如在降岭形分布函数中,其处理的是0~0.3之间的数据。对于劣化度小于0.1的数据,令函数值为1,表示其对于优的隶属度为100%;对于劣化度大于0.3的数据,令其函数值为0,表示其对于优的隶属度为0;而0.1~0.3之间的数据,属于优和良之间的模糊区间,其属于优的隶属度由公式(6)计算,属于良的隶属度由公式(7)计算。所以优、良、中、差四种评价对应的岭形函数中互有交叉重叠,表达各数据在不同评价中的隶属度。岭型函数公式如下,图1为其分布图。
1)降岭形分布函数如下:

2)中间岭形分布函数如下,它分为良和中两个部分组成:
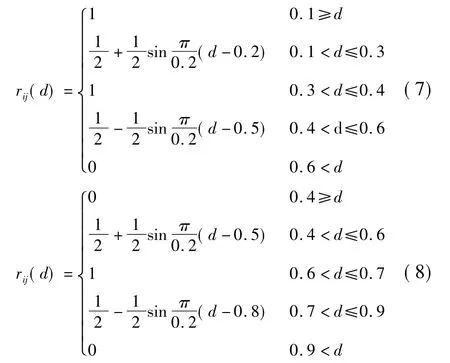
3)升岭形分布函数如下:
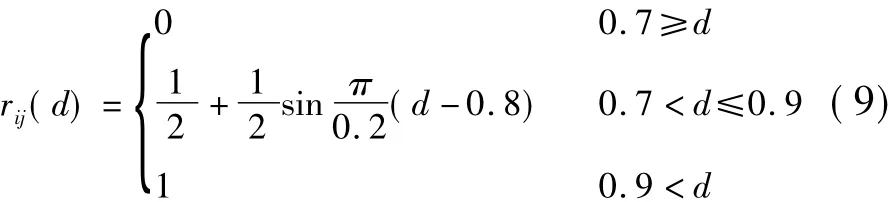
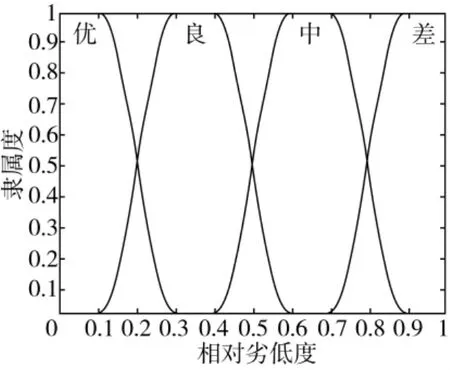
图1 各隶属度对应的岭型函数
其中d是之前通过劣化度函数求出的各指标劣化度值;i=1,2,3,4,5 代表的是第 i个因素指标在某一种岭形分布下所属的隶属度;j=1,2,3,4表示的是某个因素指标在第j个岭型分布下所具有的隶属度。综合起来分析,rij即是第i个指标在第j个岭形分布函数下所对应的隶属度。
将d带入rij(d)的函数中,每个劣化度d值均在4种岭形计算一次,5个劣化度值分别计算可以得到一个5×4的矩阵,获得如下的隶属度矩阵R。
由于矩阵R是由所有因素的劣化度和隶属度分析组成的,可以看作是对各因素的评价矩阵,由于各因素重要程度不同,所以需要对各因素加权。
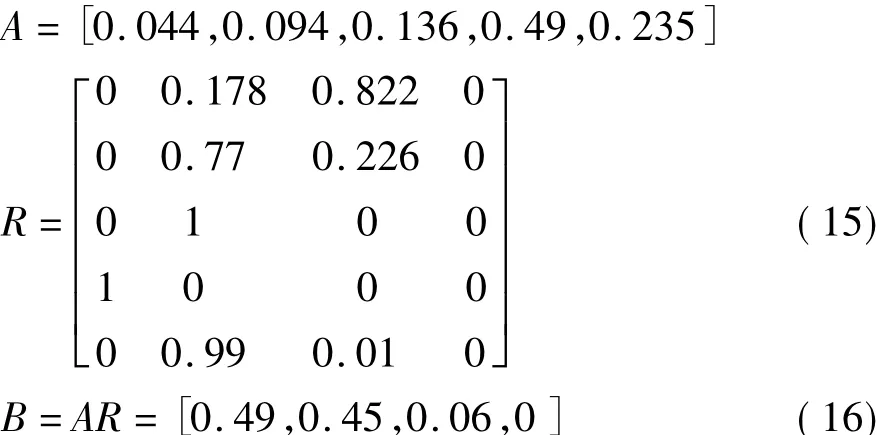
由权重系数A与评价矩阵R合成对所有因素的综合模糊评估矩阵,即通过B=AR,得到小麦品质在{优,良,中,差}状态空间中的隶属评价值(即最终的评估结果)。

4 实验设计及数据测试
4.1 实验材料
选用河南省农科院培育的中筋麦(周麦22),高筋麦(郑麦9023),收获于2016年。
4.2 实验试剂
氢氧化钾;无水乙醇;乙酸钠;溴酚蓝;重铬酸钾;硫代硫酸钠;邻苯二甲酸氢钾等(试剂等级皆为CP,化学纯)。
4.3 主要仪器设备
PQX型多段可编程扔气候箱;锤式旋风磨恒温水浴锅;1010-3星鼓风恒温干燥箱;HY-2调速多用振荡器;SPX-150生化培养箱等。
4.4 实验环境
将小麦清理干净后,每500 g装入纱布至于人工气候培养箱进行模拟储藏。根据测试中对水分的要求,在整个测试期间,使整个小麦湿度保持在12.5%左右,所对应的相对湿度范围为65% ~75%,为了模拟室温下小麦的储藏效果,用空调、加热器等方法,把小麦环境温度控制在25℃左右,并与室温储藏进行对照。
4.5 小麦生理生化指标的测定依据
小麦脂肪酸值根据GB/T 15684—2015测定。
小麦降落数值根据GB/T 10361—2008测定。
小麦沉降值根据GB/T 21119—2007测定。
小麦还原糖根据GB 5009.7—2016测定。
小麦发芽率根据GB/T5520—2011测定。
4.6 测量结果
将这两种小麦各分成5份,对不同指标分别测试,得到如表1和表2所示的数据。
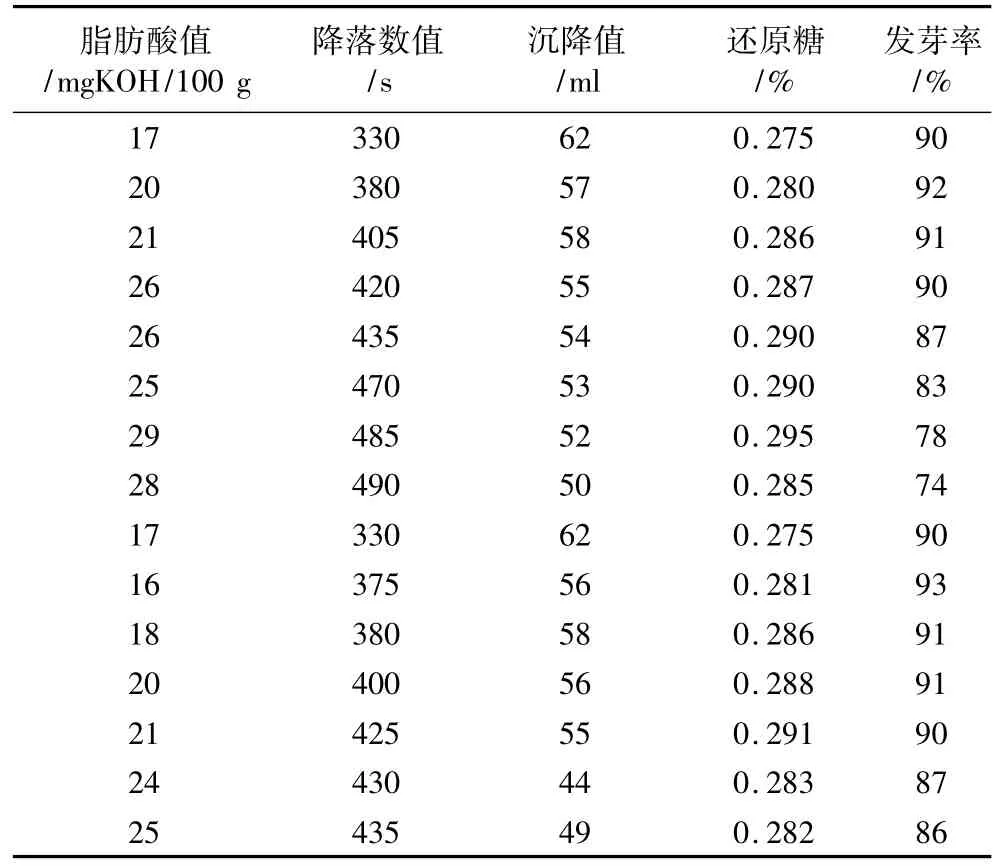
表1 周麦22生理生化指标
本研究在生理生化指标测试前,已经对这批小麦的容重、水分,色泽、气味等指标进行了初步的测量,实验结果表明其品质为优良。表1和表2的指标测试值在一定的波动,但数据基本都落在合理的区间内;另外还利用实验测试获得各指标数据,通过文献[19]计算评价、以及用现有标准测定方法[1,4,20]进行分析,发现对测试数据的评价结果也基本吻合。特别是本文所测量数值大都分布在文献[19]的取值范围附近;当然也有部分降落数值变化幅度较大和少量发芽率偏低,但对各指标数据进行综合对比分析后,本次测试的两种小麦品质也基本可评估为优。
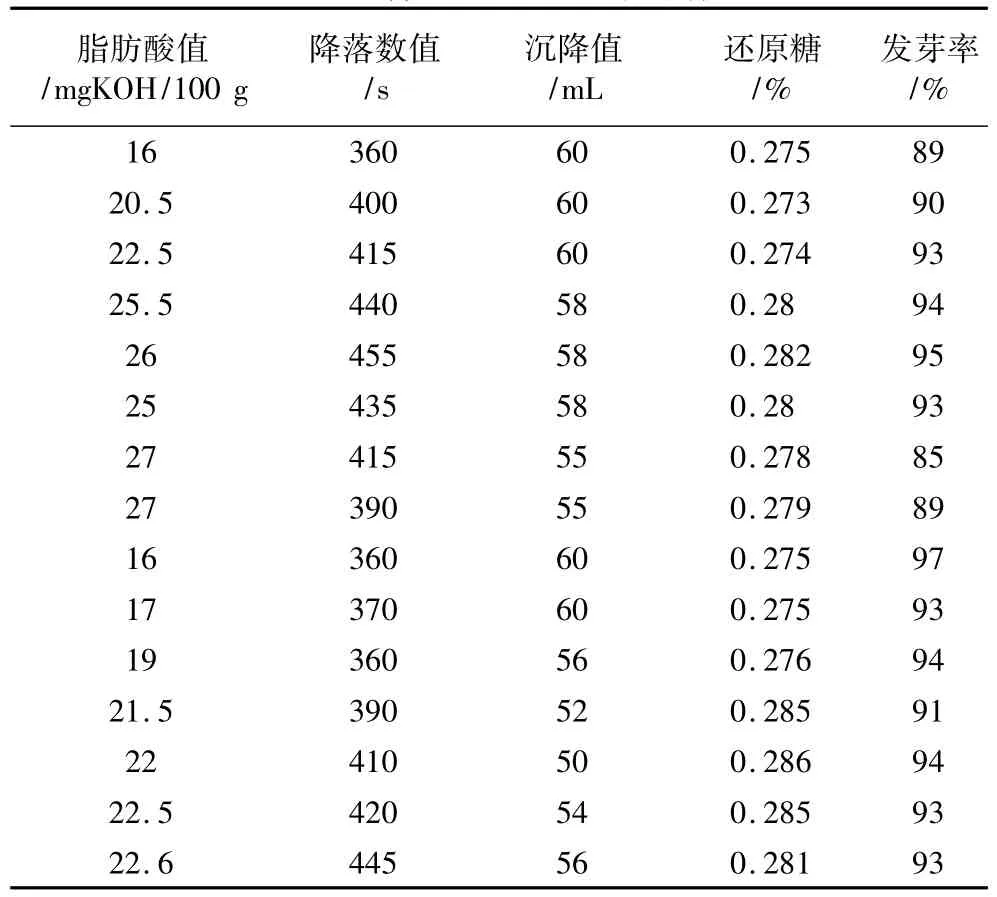
表2 郑麦9023生理生化指标
5 模型计算
5.1 因素集构建及权重系数计算
本研究主要选取表1中的5种指标参数进行处理(对表2中郑麦数据也采用类似计算过程),分别标记为 u1,u2,u3,u4,u5,由它们构成小麦评估因素集U={u1,u2,u3,u4,u5}={脂肪酸值,降落数值,沉降值,还原糖,发芽率}。
由公式(1)可以计算出缩放后的标准差ci和对测试数据处理获得的相关结果,显示于表3中(下表各指标单位同表1,2)。
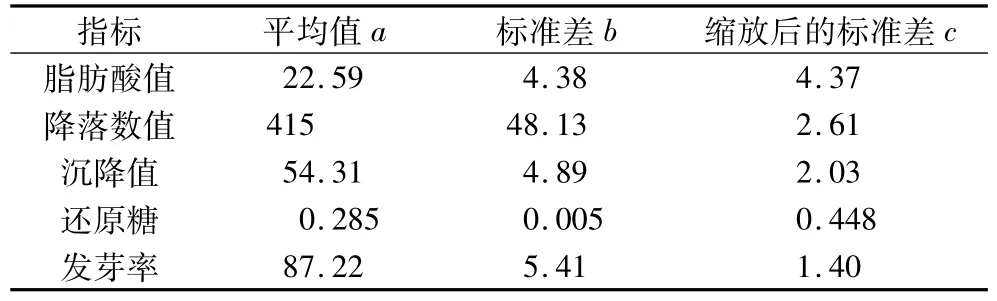
表3 指标因素参数
由表3得到间接反映权重系数的矩阵C。
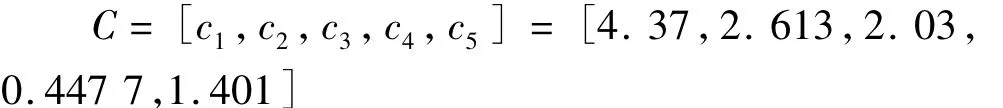
再根据公式(3)求得权重系数A。

5.2 劣化度和隶属度计算
通过对表1的数据分析,经计算后得到劣化度函数所需要的极值和最佳范围值,如表4所示。
表4 指标劣化度参数
将表1中的各指标参数的平均值x={22.6,415.7,54.5,0.284,87.75}分别按照函数类型代入劣度函数公式(3)(4)(5)可得出对应的劣化值d(x):
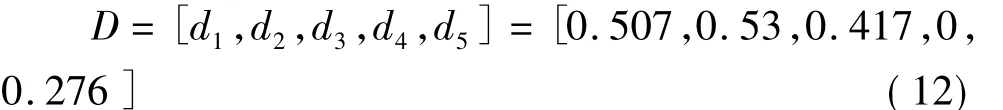
接着再将D代入隶属度函数(6)(7)(8)(9),可以计算获得如下隶属度矩阵:

最后通过对权重系数A和隶属度矩阵R的合成,可以得到评价矩阵:
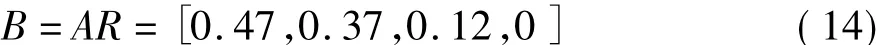
同理对表2中的数据进行计算处理后也获得如下的权重系数、隶属度矩阵和评价矩阵:
6 结果与分析
主要对周麦22计算结果进行分析(表2中郑麦数据的计算结果分析类同)。
6.1 标准差分析
在由标准差求权重系数时,发现还原糖与发芽率的标准差最小,一方面是因为在相近品质小麦中它们的测试数据比较靠拢,反映储粮品质比较可靠;另一方面,可能是在数据的读取和测量上比较精准。相比较而言,还原糖更能有效的表达储粮品质。沉降值、脂肪酸值和降落数值的标准差比较大,沉降值和降落值受实验环境影响较大,它们的测量存在着较大误差;尤其是脂肪酸值的测试数据具有极大的不稳定情况,且它的分布与小麦品质状况不一定具有良好对应关系,相同的脂肪酸值可能会对应不同状况的小麦。所以脂肪酸在权重系数中占的比例最小,还原糖所占比例最大。
6.2 劣化度分析
分析劣化度计算结果可以发现,由于它对数据的归一化是根据数据的极值和最佳范围值来决定的,这样就有可能造成两种误差:
其一,在测量数据时,可能因操作方法的不当而获得了一个或几个极值数据,尽管这些数据对统计平均值造成的影响很小,但是在对数据进行归一化时,由于公式的特性,就会造成数据整体的劣化度值偏大或偏小,这样对该因素的整体评价就会带来很大的影响。如本文中降落数值的最小数值330与第二小数值375的差别很大,但它的最大值和第二大值之间的差距则没有这么明显,最小值的偏差使得在用公式(3)计算后的降落数值劣化度趋小。
其二,在各个数据分布都较为集中时,如本文数据中的发芽率,其所有数据都极为相近,这样在进行计算时,极大值和极小值会导致整体结果偏向于均值,原本能反映品质极好的数据,通过劣化度计算后,得到的结果可能并不真实显示品质状况。
6.3 权重系数与劣化度分析
综合分析各指标的权重系数和劣化度时可以发现,其数值的大小在一定程度上呈现此消彼长相互限制的关系,具体如图2所示。

图2 劣化度和权重系数的关系
权重系数是由反应数据离散程度的标准差计算而出的,而劣化度受数据中的极值影响很大。在具体计算中,离散度偏大的数据会导致劣化度变大,同时其权重系数却会变小,通过后来的加权计算,会消除这一误差使得数据较为准确,即通过权重系数和劣化度的结合应用,在一定程度上,抵消了由于数据的离散而造成的误差。如脂肪酸值和降落数值经计算后其标准差比较大,从而导致权重系数很低,然而它们的劣化度相对比较高,最终计算得到的数值趋于平庸,使得综合评价结果仍比较合理。
6.4 标准差与隶属度分析
本文提出了用数据的标准差来间接表示因素集的重要程度和用隶属度表示指标的优良程度的方法。通过对文中数据的计算分析后发现如图3所示的结果(规律):还原糖标准差很小,其对应优的隶属度极高;发芽率标准差较小,其对应为优和良的隶属度;脂肪酸值等对应的标准差很大,其对应的只是良和中的隶属度。由此可以得出:在已知小麦品质较好的情况下,因素集的标准差越小,其对应优或良的隶属度值越大,从而说明本文采用的由标准差计算权重系数的方法是较为合理的。

图3 因素标准差和隶属度的关系
6.5 评价矩阵分析
图4 表达了本文中小麦品质评价矩阵计算过程,即用数据标准差计算出的权重系数和数据劣化度计算出的隶属度分别加权计算后得到最终的评价矩阵。
公式(13)中矩阵R的每行对应图4中不同指标的隶属度柱形图,它表示各因素在优、良、中、差的隶属程度。如矩阵R中第一行表示脂肪酸值在良和中的隶属度分别为0.45、0.55,对应优和差的隶属度为0,所以在图4中脂肪酸对应良和中两个柱状图。同理降落数值、沉降值、发芽率对应相应的两个柱状图;由于还原糖只有优的隶属度,所以在图4中,还原糖仅对应评价为优的柱状图,其他三个柱状图为0。
图4中的折线图对应公式(11)中的权重系数矩阵A,它评价的是文中五个因素在品质状态空间中的重要程度。
把每个因素权重系数和其对应的评价隶属度相乘,并将这5个计算结果相加后就是评价结果;经过四次同样运算,分别得到品质状态对于优、良、中、差的隶属度,具体见图4中左上的饼图。
根据文中对评价矩阵B的计算分析可知:b1=0.47是矩阵中数据最大的一个,由最大隶属度原则可知小麦品质状况属于“优”可能性最大,对应状态空间中的品质“优”,在图4的饼图中可以清楚的看到“优”所占的比例最大,这与“4.5测量结果”获得的周麦品质接近“优”相符合。
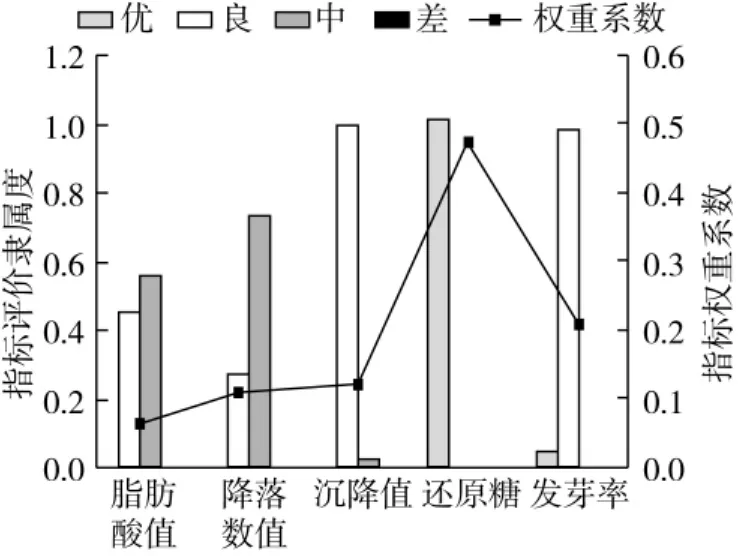
图4 小麦品质评价矩阵合成
表2的郑麦9023数据经过模型计算,b1=0.49,优所占的比例最大,可以判定其品质也为优,这也与之前“4.5测量结果”中郑麦品质基本一致。
7 结论
针对储藏小麦检测和评估的需要,本研究通过对周麦22和郑麦9023多生理生化指标进行了分析研究,建立了模糊融合评价模型,通过应用数据间标准差的计算降低了由劣化度所导致的误差,最终由模糊评价获得了储藏小麦的品质状况,在状态空间中对应品质都为“优”,它显示了计算分析模型接近真实情况,结果比较可信,在一定程度上可以为粮仓的检测和评估提供帮助。
本研究采用五个代表性的指标,仅对它们进行了模糊融合计算分析,在分析储粮品质状况上还存在着一些误差;在生物学上,这五个指标间存在着复杂的联系,还需要对这些因素进行深入的调研,找出其生物学下的内在联系和相关系数,由此判断其权重系数才有更加科学的依据,这也是下一步将要研究的方向和重点。
