基于逆向工程的Android应用漏洞检测技术研究
2018-11-16许庆富谈文蓉王彩霞
许庆富,谈文蓉,王彩霞
(1.西南民族大学计算机科学与技术学院,四川 成都 610041;2.西南民族大学计算机系统国家民委重点实验室,四川 成都 610041)
随着Android系统在手机、TV、物联网等领域占有率的日益增长,吸引了大量的应用开发者上线自己的应用程序.由于许多应用开发者缺乏安全编码意识以及国内应用商店大多没有进行有效的漏洞检测措施,导致应用程序的漏洞从开发到上线一直得不到修复,从而容易受到攻击者破坏给平台及用户带来难以预估的损失.因此,如何有效的检测出APK安全风险漏洞成为移动平台漏洞检测技术的重要研究方向[1],结合漏洞特征分析后利用有效的检测技术挖掘已公布的或Zero-day漏洞.
研究漏洞检测技术前需要先探究漏洞的成因,由于漏洞形成的复杂性,实际的漏洞成因都不是仅仅由于Android平台的开放性或碎片化形成的,通常都是应用开发者安全意识淡薄和用户的不当使用造成的[2].通过逆向工程对大量的应用进行代码审计分析发现,应用开发者普遍存在对SDK API不合理使用的现象,容易导致AndroidManifest配置有误、组件暴露等漏洞.即使知晓信息安全意识,却对密码学技术结构的误解滥用,甚至把MD5消息摘要都理解成加密算法使用,导致开发出的应用程序漏洞百出.尽管Android系统本身也提供了多种机制来保障应用程序的安全,譬如sandbox机制大大降低了应用本身的攻击面,系统为每个应用程序开辟了一个独立的Dalvik虚拟机实例,保障了应用本身的资源数据无法被其它应用程序访问.但是程序运行在用户未知的系统环境下,android系统继承Linux内核的UID/GID(用户组ID)的权限模型将可能被ROOT超级用户所修改,再结合Hook技术便可对程序进行攻击,Android应用程序的安全性自然就无法保障.同时,AndroidManifest存在很多默认配置,都会导致应用漏洞的产生.例如,系统默认将Activity的export属性置为true,那么很有可能被恶意攻击者通过其它应用调用,导致用户隐私数据泄露.因此,应用开发者编码过程的疏忽又缺少对APK包安全隐患的检测,导致很多应用漏洞得不到及时修复,可能直到黑客利用攻击才被发现.
1 相关工作
针对Android应用的漏洞检测问题,国内外学者及科研机构进行了大量的应用安全漏洞检测技术相关的深入研究,普遍采用图1所示的相关检测技术[3-5].最近国外一名安全研究人员利用路径可达性发现微信支付SDK存在XXE漏洞,黑客可窃取卖家的关键安全密钥,购买东西时通过发送伪造信息来欺骗卖家而无需付费[6].B.Min等人[7]通过对支持向量机SVM的权限模型和函数调用关系分析,研究了一种基于机器学习的漏洞检测模型.P.R.K.Varma等人[8]利用K-means算法对1000个应用程序进行聚类分析,实现最小权限化静态漏洞检测分析框架,待检测应用程序申请的权值越大,则出现漏洞的可能性越大.P.Faruki等人[9]设计了检测工具MimeoDroid,采集程序运行的内存使用、网络交互、Manifest权限,来识别应用的安全风险.O.S.Adebayo等人[10]使用Apriori算法建立程序代码调用API的关联规则,将组建的函数调用关联规则与待检测Android程序进行比较,识别应用程序中潜在的漏洞.

图1 应用安全漏洞常用检测方法Fig.1 Common methods of detecting security vulnerabilities
以上研究针对Android应用的安全问题提出了各种检测算法和工具,反映出移动平台漏洞检测的技术正不断提高,但现有漏洞检测工具大多只对逆向代码进行简单的扫描,缺少涉及深层次的smali关键函数代码分析,造成部分漏洞不能有效地被检测出,尤其是面对着不断的Android版本迭代更新和漏洞变异,这些漏洞检测机制的覆盖面和适用范围变得不太令人满意.根据多家安全检测厂商(如MWR Labs、腾讯御安全等)调查报告[11]显示,Android应用程序潜在漏洞数量大、种类多等特点,单靠安全人员手动分析是不太现实的.而目前有效的Android应用漏洞检测工具极度缺乏,漏洞检测远远不足以满足市场需求.
为了解决现有检测方法的漏检和效率问题,本文提出了一种基于逆向工程的CFG控制流图模型化特征提取算法和改进ReliefF特征选择算法相结合的Android应用漏洞检测技术.从反编译的smali静态代码段中采集原始特征集合,该特征集合要尽可能的提取待检测程序中所有有效特征,对漏洞检测的准确性有直接影响.再通过特征选择算法对原始特征码集进行降维处理以提高检测效率,得到漏洞特征向量集.另外整理分析漏洞呈现的特征和形式,构建漏洞特征匹配库,这样便可与漏洞特征向量集进行快速匹配,以匹配的相似度来判定应用中是否潜在安全问题.
2 Android应用漏洞检测算法设计
2.1 反编译获取smali静态代码
很多应用程序通过加固来防止APK包被逆向反编译,而目前的漏洞检测技术大都采用反编译的静态代码中进行漏洞扫描,没有脱壳的APK包显然不能有效的被漏洞扫描检测,故要先脱壳获取原始DEX文件.
针对已有的各种DEX文件脱壳技术[12]进行研究发现,脱壳方案要么只针对Dalvik虚拟机或ART虚拟机上的加固DEX文件,要么脱壳数据丢失不足.为了适配大多数加固的脱壳方案,本文设计研究了一种内存Dump的解决方案.APP程序运行时壳程序都会先脱壳加载原始DEX字节码文件,故在当前进程中必然保存着可推断出原始信息的DEX数据,只要利用Hook技术注入到目标程序的运行进程,监听到壳程序的动态脱壳过程时,运用Memory Dump或重建的技术手段,从内存中拦截提取原始DEX字节码文件.
依此原理研究Android系统源代码寻找Hook入口点,发现在ClassLoader类加载器中dexFindClass方法动态传入脱壳后的DexFile对象,故一旦在内存中Hook到该方法,就可以拦截被加固的原DEX字节码文件.如图2所示,利用Hook技术拦截ClassLoader的dexFindClass函数调用转换过程,在DexExtracter类中即可加载被加固DEX字节码文件.

图2 ClassLoader钩挂脱壳前后函数调用过程Fig.2 ClassLoader hook to intercept function call procedure
经过上面使用挂钩获取APP动态运行脱壳的DEX文件后,接着就可以针对该DEX文件进行逆向反编译,需要对DEX文件的编译打包过程和文件格式有深入的研究[13-15].本文使用shell脚本封装Apk-Tool、BakSmali和 AXMLPrinter进行自动化反编译APK包,各逆向工具反编译的状态流程如图3所示.将Dalvik可执行字节码反汇编为一种被称为smali的中间代码和Manifest文件,进而才能进行后续的安全性分析.

图3 APK逆向反编译转换Fig.3 APK reverse decompile transformation
2.2 提取原始特征码集
由上阶段将DEX文件反编译得到smali静态代码段后,需要通过还原smali静态代码的逻辑关系来充分提取特征之间的属性值,从中提取漏洞检测的原始特征码集是后续处理的基础.
假设在AndroidManifest文件和smali静态代码段中,把函数看成一个节点,函数之间的调用关系看成节点连接的有向边,这样就可以把函数调用关系及数据流抽象成CFG控制流图的数据模型[16].在数据模型中的函数调用关系能够反映程序内函数间的依赖关系,完整的函数调用关系可以更全面的提取漏洞特征数据.为此本文针对漏洞特征提取模块设计研究出一种基于CFG控制流图的特征提取模型.
将特征提取的CFG控制流图存储为一种抽象的数据结构:
定义1 函数(即CFG控制流图中的节点)fi的数据结构为三元组 fi,j= < fin,fout,feature > ,其中 i表示第i个函数,j表示第j个fi函数流,即一个函数节点同时关联j个函数;fin表示fi节点的入度;fout表示fi节点的出度;feature表示函数fi中提取的特征串.
定义2 漏洞特征码集D ={<x1,s,w >,<x2,s,w >,..., < xn,s,w >} ,其中 xn表示特征所属位置;s表示特征串.当漏洞特征为函数关系时,s=fi,j, fi,j即定义 1 中的 CFG 节点;特征提取按照一定的漏洞特征敏感值,赋予每个特征对应的权值w,特征权值越大,引起漏洞的可能性越大.
图4是一个Android应用程序的部分简化函数调用图,其中函数f4有和f5两个父节点,一个子节点f8,故 f4可提取的特征有 f4,1= < f2,f8,null > 和 f4,2= <f5,f8,null > ,则漏洞特征码集 D = { < f4,1,null,0>, < f4,2,null,0 >} ,其中 null表示当前节点没有提取到特征数据.
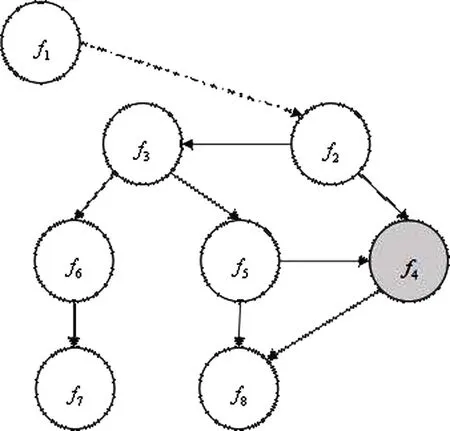
图4 CFG函数控制流跟踪Fig.4 CFG function control flow tracking
特征提取采用中断递归遍历所有可能执行的路径.从程序入口依次深度遍历,直到遇到多函数交互的时候,随机选取被调函数的一条执行路径,当该条可执行路径被完全的分析完后,回溯提取分叉路径上被调函数的其它未分析路径.将遍历的所有路径信息存储到树结构容器中,提取逆向还原的执行逻辑相关特征,构建APK包的漏洞特征码集D,便于后续特征选择的漏洞特征筛选.该模块的具体原理如算法1所示,首先提取APK包中的Manifest文件来初始化算法入口(第1-3行),取出启动Activity的分析路径节点;然后逐条分析节点上的语句(第5行),判断语句类型处理相应的逻辑操作(第7-9行).完成一条路径逆向分析后回溯到该条路径上被调函数的其它未分析语句代码(第12行);将Node函数的遍历过程提取相关特征更新到整个CFG树中,继续取下一个待分析路径节点分析(第13行).
输入:APK的Manifest配置文件以及入口节点函数
输出:漏洞原始特征码集D
1)methodAnalysis(entryNodes[]){
2)entryClassList = entryNodes.traversal();
3)curNode = entryClassList.firstNode;
4)parentNode = null;
5)while(entryClassList)
6) for each clazz in entryClassList do
7) switch(clazz.info)
8) case “iput-object”:赋值处理;break;
9) case “invoke-direct”:解析被调函数;break;
10) case “return”:函数返回;break;
11) end switch;
12) backtrace(); //回溯分析
13) parentNode.add(curNode);
14)end while
15)}
2.3 筛选漏洞特征子集
由特征提取阶段得到的原始特征码集中特征数量过大,但只有一部分特征数据之间的属性参数和关联规则对于最终的漏洞判定有决定作用,因此在原始特征码集中筛选具有分类能力的特征子集构成特征空间,降低特征空间的复杂度对于提高漏洞检测的精确性具有明显效果.还有如果不对原始特征码集进行特征选择,原始特征空间就会比较庞大,易造成特征空间维度爆炸问题,从而造成检测算法效率低下.
针对漏洞特征子集的提取问题,典型有效的策略是采用支持向量机(SVM)检测算法[17],但原始特征码集高维的特性,对SVM的分类效率有很大影响.故对检测模型进行优化,本文通过对漏洞特征数据相关性与特征权值的分析,提出了一种针对多特征数据的改进ReliefF算法进行降维匹配.ReliefF算法[18]的基本思想是利用特征提取阶段给原始特征码集的每一个特征赋予特征的敏感权值,根据特定规则迭代数次更新权值,最后按权值大小选择漏洞特征子集,使得敏感性较强的特征聚类到一个样本集中,而离散不易出现漏洞的特征样本.
假定漏洞原始特征码集D ={<x1,s,w >,<x2,s,w >,…, < xn,s,w >} 中的样本来自 y 个漏洞类别,其中 xi属于第 k类( k∈ {1,2,…,|y|} ).则ReliefF算法每次从原始特征码集D中随机取出一个特征xi,再从和xi同类的漏洞类别集中选择k个近邻特征Hj,其中0<j≤k,接着从y-1个不同漏洞类别集中均选择k个近邻特征Mj,其中0<j≤k.根据以下特征聚类规则修改Hj和Mj中特征权值:
dis(xi,Hj) < dis(xi,Mj) ,则该特征 xi对区分该漏洞类别和y-1类的最近邻是有用的,增加xi的敏感权值;
dis(xi,Hj) ≥ dis(xi,Mj) ,则该特征 xi对区分所属漏洞类别和y-1个漏洞类别的最近邻起干扰作用,降低xi的敏感权值.
上述过程迭代n次,求出原始特征码集D中各个特征的平均权值.通过设定阈值,当特征的平均权值大于阈值,说明该特征很大可能引发漏洞,则加入到新的特征子集中,从而起到降维的作用.
然而,上述特征选择过程并未考虑一个特征属于多个漏洞类别的情况,所以增加以下两个选择条件:
1)增加了权值更新影响因子 w1,t和 w2,t,表示特征xi对每个漏洞类别的关联关系,即多个API同时调用的概率,而无需检测某API调用后,其它相关API被调用的概率问题;
2)增加了最近邻多漏洞特征,针对样本xi所属k个漏洞类别,用h = {h1,h2,…,hk}表示,遍历h检索其类内最近邻Hj和类外最近邻Mj(C).
注:Mj(C)表示类C∉class(H)中第j个最近邻样本.
假设特征xi所属的各漏洞类别对其影响因子是相等的,将影响因子加入到ReliefF特征敏感权值修改公式中.在查找最近邻时,首先找到样本拥有的t个漏洞类别,记 l= (l1,l2,…,lt) ,然后依次遍历每个漏洞类别 li(i∈ {1,2,…,t}) ,查找其漏洞类别内最近邻H和类外最近邻M.这样就适配了一个特征属于多个漏洞类别的问题,伪代码漏洞特征选择过程描述如下:
输入:原始特征码集D,迭代次数m,漏洞类别数t,最近邻特征个数k.
输出:最优的漏洞特征子集S.
1)初始化特征权值影响因子 w1,t= 1 , w2,t=1/k,特征权向量W 置0,即W(A) = 0,A∈{1,2,…,n},n为特征权向量维数;
2)for i=1 to m do
在原始特征码集D中随机选择特征Ri,记该特征所属的漏洞类别 class(Ri) = h = {l1,l2,…,lt} ;
3)for j=1 to t do
4)在与特征Ri同类的集合中,遍历查找k个最近邻 Hj, j= 1,2,…,k;
5)对每个类C≠hj,计算与Ri不同类lj的k个最近邻 Mj(C) , j = 1,2,…,k;
6)for A=1 to n do //更新每个特征权值
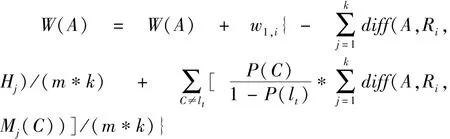
7) end for //转步骤 6
8) end for //转步骤 3
9)end for //转步骤 2
10)产生最优特征子集S,S=generate(D)
通过改进后ReliefF算法去除原始特征码集的冗余特征得到漏洞特征子集,后续与漏洞特征库进行正则匹配便可挖掘出应用中潜在的漏洞信息.
3 基于逆向工程的APK漏洞检测模型
依据上文研究设计的核心漏洞检测算法与技术,实现了基于逆向技术的Android应用漏洞检测模型以验证算法的可行性与正确性.该模型由自动化脱壳反编译、漏洞特征提取、漏洞特征选择、漏洞库匹配等主要模块组成,其系统架构如图5所示.算法由Python语言实现,并集成Django框架开发APK漏洞云检测平台.

图5 基于逆向工程的漏洞检测模型Fig.5 Vulnerability detection model based on reverse engineering
检测模型由各个功能模块层层递进协同分析处理.自动化脱壳反编译模块是漏洞检测的预处理阶段,为上层核心的漏洞特征向量化表达提供静态代码段,输入到特征提取模块进行分词截取出原始特征码集,得到的原始特征码集经特征选择模块进一步算法筛选关联后,使漏洞特征向量化构成特征空间.最后特征向量化数据与AVD漏洞库进行静态正则匹配,发现相似性高的特征向量化数据则可以判定该特征向量化代码单元存在漏洞,查找AVD漏洞库相应漏洞信息和修复方案,并从特征向量化数据中获取该漏洞所处的代码段位置.其中AVD(Android Vulnerabilities Database)漏洞库由人工分类整理已发现的Android应用漏洞信息,收录的漏洞按漏洞出现的机制归类,例如:组件暴露风险攻击、API误用、Intent注入等.
各主要模块的功能如下:
1)逆向反编译模块:漏洞检测模型的最初阶段,输入为APK包文件,对APK进行脱壳反编译出Manifest文件、资源文件、签名文件和smali静态代码,输出该APK包的反编译逆向数据.
2)特征提取模块:将逆向数据解析抽象为CFG控制流图的函数调用关系,分析应用内部逻辑和程序流程,提取函数API的相关属性特征,输出漏洞的原始特征码集.
3)特征选择模块:代码实现特征选择算法,从原始特征码集中筛选得到关键特征,降低特征维度数量,进而构建特征空间,输出特征向量化数据.
4)AVD漏洞库和CVE更新模块:收录了已公开发现的Android漏洞特征数据,并从各大漏洞共享平台获取更新漏洞库数据.
5)系统匹配模块:正则对比特征选择模块输出的特征向量化数据和AVD漏洞库提供的漏洞特征信息,判断应用是否存在漏洞,输出挖掘出的漏洞信息和对应的修复方案.
6)漏洞评估模块:依据检测出的漏洞信息分析该应用的风险等级,生成相关漏洞修复意见的应用漏洞检测报告,供APK提交者下载.
4 实验与结果分析
为了验证本文研究的漏洞检测机制的有效性,实验采用对比策略对检测模型进行实验,以客观反映系统性能和漏洞的检测精度,检测精度包括检测加固dex、SQL注入、日志泄露风险等多漏洞类别验证.
4.1 实验环境
检测模型程序部署在2.26GHz主频的32核数Intel Xeon处理器和32GB内存的工作站,软件环境:Windows Server 2012 R2,Python3.5,JDK8.
4.2 实验对象
实验的测试样本集包括150个从Google应用商店爬取的榜单应用和针对漏洞类别构造的100个含有漏洞的缺陷应用.批量上传到检测模型上扫描,对其检测日志进行统计分析,结果显示150个榜单应用中出现8个应用在扫描过程中出现异常,实际有效检测样本数为142个,主要由于开发者对APK程序进行保护,导致Python XML DOM库不能解析异常文件格式.
4.3 实验结果与分析
为验证检测模型的系统性能,图6右侧散点图统计了应用扫描所需的时间,数据表明应用大小与扫描时间成正相关的关系,且市面上应用大小普遍在20M-60M之间.静态逆向解析过程中,平均扫描时间在10min左右,最慢扫描时间需要20.2min,最快扫描时间也要2.8min,其中扫描加固程序还要加上动态脱壳耗时,扫描时间比普通程序更长.
为验证检测模型的检测精度,漏洞检测100个构造的缺陷应用样本,然后对所有样本检测到的漏洞数进行统计,统计结果如表1所示,检测精度由检测出的漏洞数与应用中实际存在的漏洞数的比值.分析原始特征码集的数量级与检测精度的关系,如图6左子图,当特征数量在一定范围内时,漏洞检测的精度随特征数量的增加而提高,但当特征数量超过检测模型的阈值后,漏洞检测的精度随特征数量的增加而变得不太理想.

图6 实验样本漏扫结果Fig.6 Experimental sample vulnerability scan results
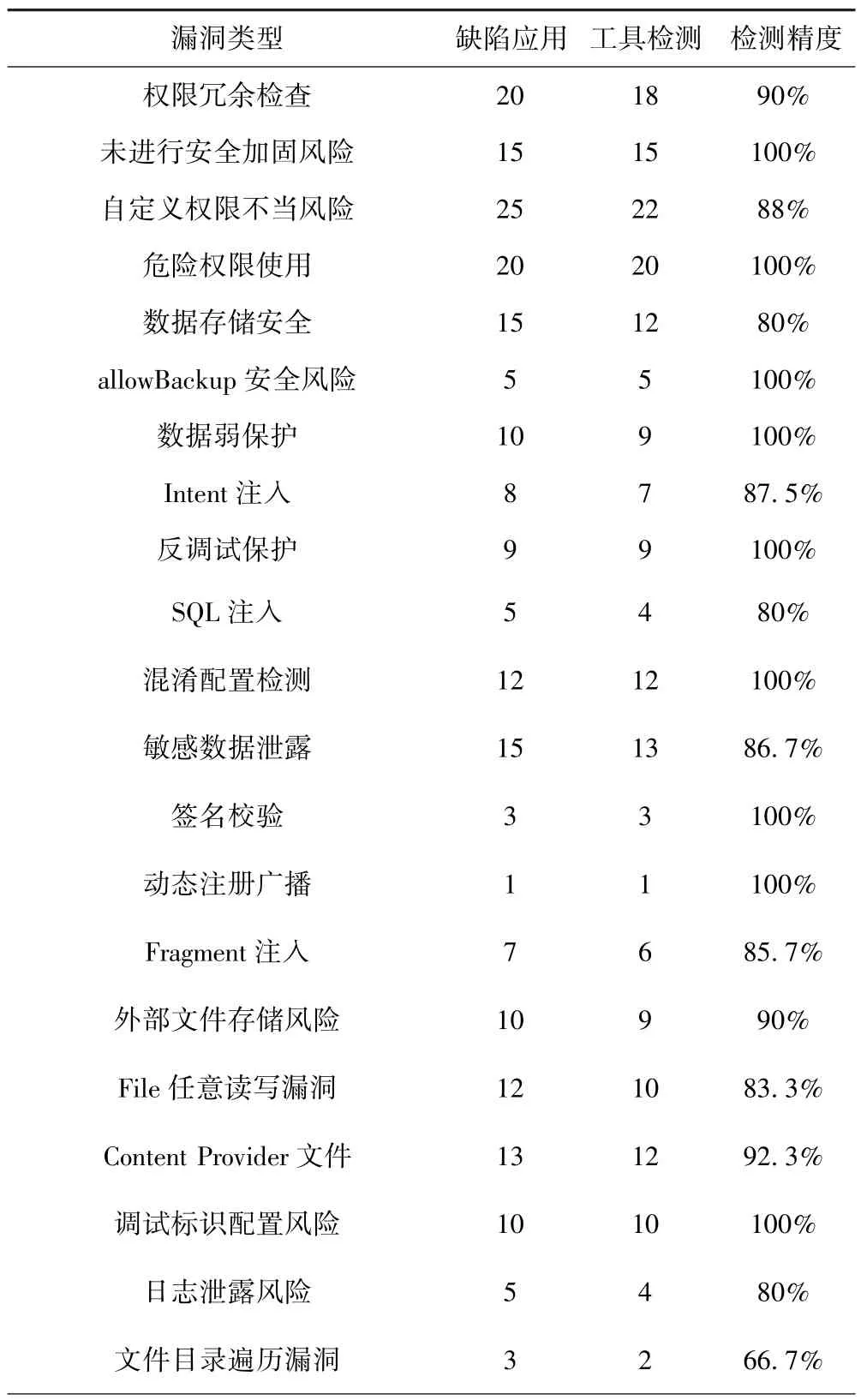
表1 缺陷应用检测结果Table 1 Vulnerability application scan results

漏洞类型 缺陷应用 工具检测 检测精度隐式Intent风险 6 6 100%PendingIntent误用风险 11 10 90.9%Intent Scheme URL攻击漏洞 13 11 84.6%WebView密码明文保存漏洞 1 1 100%WebView组件远程代码执行漏洞 8 7 87.5%WebView忽略SSL证书错误 1 1 100%WebView XSS攻击风险 13 11 84.6%SSL允许所有域名漏洞 12 12 100%信任任意证书漏洞 2 1 50%未使用HTTPS协议的数据传输风险 1 1 100%AES/DES弱加密风险 5 5 100%Hash算法不安全 1 1 100%随机数使用不当风险 2 2 100%Native动态调试漏洞 3 2 66.7%Shell命令风险 10 10 100%Root权限风险 5 5 100%Zip文件遍历漏洞 7 6 85.7%
构造的缺陷应用样本通过市面上的加固平台加固保护处理后,检测程序依然能扫描被加固程序中包含的漏洞,故具有自动化脱壳和扫描隐藏dex文件的能力.从表1可以看出,检测模型对各漏洞类别所构造的缺陷应用的平均漏洞检出率达91%,对于一些较复杂漏洞检测需要多特征关联起来判定,当特征数量级较大时,存在不同特征互相干扰影响检测结果,导致漏洞检测出现漏检误报的现象.
实验总结:检测模型总体的漏洞检测性能符合预期目标,对于大部分常见漏洞都能很好的检测出来.但对于漏洞库中没有的漏洞信息,检测模型便很难检测出来,需要及时更新漏洞库数据,对于检测率的提高影响很大.
5 结语
本文在研究总结了Android应用漏洞检测技术的优点和不足的基础上,提出了一种基于逆向工程的应用程序漏洞检测方案,运用内存挂钩技术实现加固APK脱壳,设计了CFG控制流图的特征提取策略并改进ReliefF算法的漏洞特征选择方法,最后与AVD漏洞库进行正则匹配便找出对应漏洞位置.实验结果表明该检测技术的漏洞挖掘能力符合预期要求.下一步针对漏洞库未知漏洞出现漏检问题,将通过结合深度学习的相关技术,使检测平台能够实现对部分未知的漏洞做出预测.
