中文词语搭配特征提取及文本校对研究
2018-11-14陶永才海朝阳
陶永才,海朝阳,石 磊,卫 琳
1(郑州大学 信息工程学院,郑州 450001 2(郑州大学 产业技术研究院,郑州 450002 3(郑州大学 软件技术学院,郑州 450002)
1 引 言
随着网络技术的快速发展,各行各业开始将本部的工作职能与互联网相关联,人们已经习惯了从网络中获取需要的知识和概念.无论是专业文献还是政府机关的行文公告,对上下文的语义准确程度都有着极高的要求.如今针对文本校对的研究[1-5]相对比较充分,字词级别和语法级别的校对研究都取得了较大的进步.然而,对于一些对上下文语义要求严格的文章来说,更需要针对词语间搭配关系的校对方法,因此有必要研究检测词语间搭配关系的文本校对方法.
汉语的校对方法与英文有所不同,这是由于汉语的词语间搭配关系复杂,不仅和字词、语法相关,还受到语言环境的影响.例如:"移动"这个词,在不同的语境下,该词语所能搭配的词也会有所不同.如果是在谈论物理学时,"移动"这个词和"速度"、"加速度"以及"牛顿运动定律"等词语的关联性更强,即共同出现的可能性更高;如果是在谈论计算机科学时,"移动"与"互联网"的关联性更强;如果是人们在闲聊时提到,那么"移动"和"公司"的关联度就会更强.这就说明,同一个词在不同的语境下,会有不同的含义,词语间的语义关联也会随之改变,所以,在讨论真词错误的校对方法之前,必须要给定语境前提,这样建立起来的关联关系知识库才是有意义的.本文的目标就是研究在给定语境的条件下,如何让计算机能够以较高的质量进行中文文本词语搭配关系校对.
2 相关工作
由于涉及到语义、语法等方面的校对,真词错误校对问题的研究,一直是自然语言处理研究中的难点,也是中文校对的难点.词语的搭配关系主要受到语义成分、思维习惯、风俗习惯以及认知习惯等方面[7]的影响.如"移动"这个词,在不同的语境下有着不同的搭配关系,这可以说明,在进行真词错误校对时,是必须要给定前提语境的,如果不加限制地进行词语搭配关系检测,那么校对结果的可靠性就难以保证.
文献[2]结合统计和规则的方法,设计了基于N元邻接矩阵的检错模型,能够对长距离的文本错误起到较好地检错效果,但是,词义邻接矩阵的高维稀疏问题会影响到语义搭配错误侦测的效果;文献[5]结合传统的检错系统和HNC分析系统,提出了新的校对系统模型,对于语义错误具有较好地检测能力,但是,针对语义块的划分和组合等处理有可能会破坏文本的语义关联,影响其侦测能力;文献[8]建立了词语-义原搭配的模型,有效地提高了检错的正确率,但是面对一些长句时,难以检测其中的多元词语搭配关系.
上述研究中,各类研究方法在一定程度上提高了针对真词错误的检测、校对能力.但是通过对语句进行成分分析,抽取其中的语法结构,并与词语搭配关系结合的校对方法还没有得到更多的关注和研究.本文创新地结合语法和词语搭配关系,构建双重校对知识库,并优化校对评价指标,提高文本校对的能力.
3 基于词语搭配关系的文本校对模型
本文通过大量的研究发现,在特定的语言环境下,词语之间是存在一定的关联的,这种关联存在于语义、词语位置的相互影响之中.考虑到自然语言的随机性、弱相关性及有向性,可以采用N元马尔科夫链作为词语搭配关系的语言模型,采用词语间的互信息作为正相关联强度的评价标准.利用马尔科夫链来构建词语间的上下文关系知识库,是检测文本错误的基础.词语间的互信息和聚合度则是文本校对的主要参考标准.
由于在文本校对的过程中,词语的搭配关系受到了各种因素的影响,有些词语搭配关系的正确性容易判断,但是有些词语搭配是很难判断其正确性的.例如,常用词与专业名词之间的搭配,这样的搭配只会出现在特定的文章中,在整个语料库中出现的频率是非常低的,那么就很难学习到其中的词语搭配关系.为此,在校对过程中引入了词语聚合度的概念,与互信息共同作用,起到较好地校对效果.
本文的基本思路是将语法规则知识库和以马尔科夫链为语言模型的词语搭配关系知识库相结合,建立中文文本的词语搭配关系错误检测及校对方法.首先,以语言学和统计学为主要方法,抽取语料库中大量的句子,分析成分、结构等信息,构建语法成分知识库;然后,根据词语间的位置信息和互信息,构建词语搭配知识库;建立起一个语法-词语关联的双层检测结构,利用规则和统计双重方法,检测文本词语搭配错误,并以互信息和聚合度作为校对的标准,以此给出文本词语搭配错误检测及相应的修改建议.词语搭配关系的校对框架如图1所示.

图1 基于语法成分知识库和词语搭配知识库的文本校对框架
4 语法成分知识库和词语搭配知识库的构建
文本校对通常会采用三种方法:
1)依据规则的方法;
2)依据统计学的相关方法;
3)规则和统计学相结合的方法.
目前主要的研究方法是以统计学为主,结合语法规则等语言学的相关知识,抽取文本中的特征项进行检测.本文研究发现,目前的校对方法,主要是集中抽取语句的特征项,然后以特征项为中心,检测特征项与搭配词之间的关联强度,此类方法没有考虑到整句的完整性,切断了语句内部的语法、语义关联,不能检测语句成分层面存在的问题,缺乏通用性.针对此类问题,结合目前一些优秀的方法理论,本文拟通过实验,提出一种结合语言学知识和统计学方法的语句成分规则抽取模型.
根据语言学的知识,完整的语句其中的词语成分是符合一定的规则的.汉语中,语句的成分信息不仅受到了词义的影响,词语所处的位置也会影响到语句表达的含义.所以在进行语法分析的时候,将句子作为一个整体,利用统计学的方法,从文章中抽取、学习各类型语句的语法模型.举例说明,在汉语中,一句话通常会以某个事物(名词N)或者某个行为(动词V)来作为句子的核心,辅以形容词(A)或副词(D)来刻画主语,除了主语之外,还会有动作或行为,这就是谓语,通常由动词(V)来作为谓语.除了以主语作为核心外,谓语、形容词都可以成为句子的核心.例如:"动人心魄地美","美"是形容词,"动人心魄地"则是副词,当形容词作为句子的核心的时候,一定会有副词与其搭配出现,而且,根据汉语的语言习惯,核心内容总是出现在一系列的修饰词(形容词、副词)之后.考虑到这样的特性,本文在构建语句成分模型的时候,优先构建各类核心词的短语搭配模型,然后通过学习短语之间的关联方式,如介词、连词等,通过词语间的互信息,构建出词性间的有向关联图,一个有向图就是一类句子的模型,通过大量的学习,就能够构建出大部分句子的成分模型.
通过以上的方式提取出的成分搭配信息,能够说明完整的语句中存在某种特殊的因素,使得句子中的词语之间相互吸引、组合,实现完整的语义表达.但是仅通过学习词性搭配,能够得到的信息较少,只能够初步检测句子是否出现语法性的错误,要进行语法级校对,还需要结合词性之间的关联程度,不仅要包含词性之间的影响,还要能够涵盖其位置信息.为此,本文提出一种描述词语间正向关联的关系模型,该模型以马尔科夫链为基础,结合词语间的互信息,描述其位置关系及搭配关系.该关系模型的示意图如图2所示.
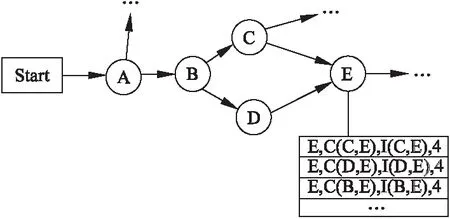
图2 词语间正向关联的关系模型
本文在进行词语搭配知识库的构建时,采用了同样的语句模型,来描述句子中的词语搭配关系.根据语言学的知识,当一个词语出现在句子中时,这个词一定和之前出现的某些词语之间存在一定的联系,所以在构建语句知识图时,必须要将前文对词语的影响考虑在内.本文提出的描述词语间正向关联的关系模型可以较好的契合要求.该模型的示意图如图3所示.
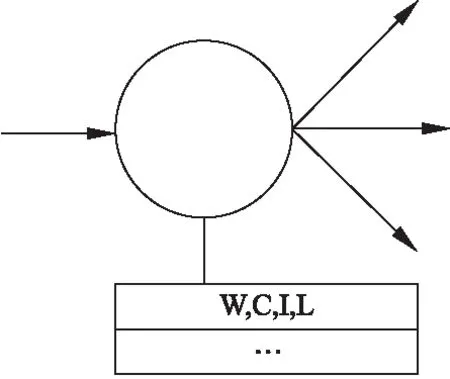
图3 元节点结构模型
如图3所示,节点中存储的信息分别为词语W,共现频数C,互信息I,位置信息L.
互信息的定义如式(1)
(1)
其中I(X;Y)为词语(或词性)x和y之间的互信息,p(x,y)为词语(或词性)x和y在语料库中,以当前的词语顺序共现的频率,p(x)、p(y)分别表示词语(或词性)x和y在语料库中各自出现的频率,其计算方法如式(2)、(3)所示:
(2)
(3)
其中,c(x,y)、c(x)和c(y)分别表示词x、y在语料库中出现的次数,以及x和y共现的次数;N表示语料库中出现的词语总数.在学习的过程中,有一些语句成分搭配、词语搭配只是偶然出现的组合,并不能认定为是值得学习的知识.所以关于互信息I(x,y)和搭配关系的共现次数c(x,y)的阈值的讨论是必不可少的,本文将于实验部分讨论I(x,y)的阈值ti以及c(x,y)的阈值tc.
算法1.语句成分、词语搭配关系抽取算法
输入:语料库D;阈值ti、tc
输出:语法成分知识库/词语搭配知识库
过程:
1.对D逐句扫描,将整句赋值给B;
2.对B逐词扫描,将B当前词语赋值给w,如果w是句子的第一个词,跳转至步骤3,否则跳转至步骤4;
3.检索知识库中的所有图的起点,是否存在与w相同的结点,如果存在,则返回步骤2;如果不存在,则建立一个新的结点,并将w存入结点并标记为起始结点,返回步骤2;
4.如果在对应的知识图中,没有对应w的结点,则建立一个新的节点,并将w存入结点,并在结点记录位置信息,建立该结点与其前驱结点的关联关系,跳转至步骤5;如果知识图中存在对应w的结点,则跳转至步骤5;
5.判断B是否到达末尾,如果是,继续向下执行;如果否,返回步骤2;
6.判断D是否到达末尾,如果是,继续向下执行;如果否,返回步骤1;
7.扫描所有知识图,统计每个结点出现的频次c(w),统计每个结点与其2个前驱结点的共现频数,如果共现频数小于阈值tc,则删除该结点及其关联关系,将其后继结点与其前驱结点关联,更新后继结点的位置信息;
8.扫描所有知识图,计算各结点与其2个前驱结点的互信息,如果互信息小于阈值ti,则删除该结点及其关联关系,将其后继结点与其前驱结点关联,更新后继结点的位置信息;
9.将所有保留的知识图存入知识库;
10.算法结束.
语句成分、词语搭配关系抽取算法的具体描述如算法1所示.
5 文本校对方法
在上述算法1构建的语法-词语搭配双层知识库的基础上,将利用各结点之间的互信息及待校对语句与知识库中语句模型的聚合度,对文本进行词语搭配校对,并给出校对建议.
目前,大量的研究表明词语搭配在自然语言处理中发挥了重要的作用[8],通过学习词语间的搭配关系,不仅有助于研究语义表达,还能够发现词汇之间的特殊关联.算法1中构建的语句模型是大量词汇之间构成的有向图,有可能存在某个结点关联其后的数个结点,在进行校对时遇到这种情况,只凭借节点间的互信息给出校对建议明显是不够的.为此,本文引入聚合度的概念和互信息搭配,来衡量词语搭配的可靠程度.聚合度的定义如下:
定义1.聚合度:设x与y为待校对的词语搭配,x为前结点,其后关联的结点集合为X,该集合与y的匹配程度称为聚合度,用PD表示,其计算公式如公式(4)所示:
(4)
其中N为集合X中结点的数量,CXi,y的定义如式(5)所示:
(5)
当聚合度越趋近于1时,则表明在知识库中x和y搭配的可能性越大,那么进行校对时搭配正确的可能性就越高;当聚合度越趋近于0时,则表明x和y搭配的可能性越小,在校对时搭配正确的可能性就越低.
本文在进行语法-词语搭配双重检测时,首先对待校验的文本逐句进行检测,并依据"互信息+聚合度"的方法对语句的词语搭配进行评价并给出校对建议."互信息+聚合度"的表达式如式(6)所示:
PDI(x,y)=α×I(x,y)+β×PD
(6)
PDI为互信息和聚合度对搭配关系的综合影响,其中α和β分别为互信息和聚合度的权重并且α+β=1.设θ为PDI的阈值,当PDI≥θ时,认为y和x的词语搭配是正确的,否则认为是错误的.对于阈值θ的选择将于实验部分进行讨论.
算法2.语法校对算法
输入:待校对文本T
输出:语法错误信息
过程:
1.将T逐词转换为其词性,获得文本T′;
2.对T′逐句扫描,将整句赋值给B;
3.对B逐词扫描,将B的当前词语的词性赋值给w,如果w是一个句子的第一个词,则跳转至步骤4;否则跳转至步骤5;
4.检索语法成分知识库所有的起始结点,如果没有找到与w相匹配的结点,则标记整句,返回步骤2;否则,记录所有匹配的起始结点,返回步骤3;
5.依次检索每个起始结点所对应的词性搭配图,如果能够找到一条路径和B相符合,则证明该句子不存在语法错误,返回步骤2;
6.如果不能找到这样一条路径,则说明该句子中存在语法错误,标记整句,如果该句子是T′的最后一句则继续执行,否则返回步骤2;
7.整理T′的标记信息并输出,记为GW;
8.算法结束.
语法校对算法如算法2所示.
根据算法2得到的输出结果,可以判断文本出现的语法错误的部分,一定存在词语搭配错误,需要优先进行校对并给出校对建议.对于没有检测到语法错误的部分,将继续进行词语搭配校对.
算法3.词语搭配校对算法
输入:待校对文本T
输出:词语搭配错误信息集CE,校对建议集AP
过程:
1.对T逐句扫描,将整句赋值给B;
2.对B逐词扫描,将B的词语按照句子中的顺序赋值给Ai(i=0,1,2,...),当i=0时,跳转至步骤4;否则跳转至步骤5;
3.检索词语搭配知识库中所有的起始结点,如果能够找到相匹配的结点,则i=i+1,返回步骤3,如果不能找到相匹配的结点,则标记整句,返回步骤1;
4.计算Ai与Ai-1的PDI,如果PDI≥θ,则i=i+1,返回步骤2;否则,将Ai标记,i=i+1,继续执行;
5.当前一个词语Ai-1出现词语搭配错误时,根据所有位置信息为i-1的结点中所存储的互信息来计算Ai与Ai-2的PDI,如果PDI≥θ,则认为此处无错误,取消Ai-1标记;否则跳过位置信息为i-1的结点,计算Ai与Ai-2的PDI,如果PDI≥θ,将所有与Ai和Ai-2相关联且位置信息为i-1的结点写入AP,跳转至步骤7;否则,i=i+1,继续执行;
6.此时连续两个词出现错误,需计算Ai与Ai-2的P重复步骤6,由于连续错误的词数达到2,则认定整句错误,标记整句,返回步骤1;
7.判断Ai是否为B的最后一个词,如果不是,返回步骤2;如果是,判断B是否为T的最后一个句子,如果不是,返回步骤1;如果是,继续执行;
8.将所有标记的句子写入CE并与AP建立关联,输出CE和AP;
9.算法结束.
词语搭配校对算法如算法3所示.
6 实 验
6.1 实验数据
实验采用北京大学计算语言学研究所*1http://download.csdn.net/download/zxlxstly/669716#,2008-10-06公开的《人民日报》标注语料库(约1900万字).该语料库包含人民日报1998年上半年的新闻,属于新闻性质语料,用词规范,语句标准,并且已经完成校对、分词及词性标注等加工,符合本文实验要求.
6.2 实验环境
实验分为相关参数的确定和算法评价两部分,实验配置如下所示:CPU为Intel Core i7-4790 3.60 GHz,8G内存,1TB硬盘,操作系统为win7,Java版本1.7.0,实验平台为10台计算机组成的计算集群.使用matlab进行数据处理,版本为matlab 9.0.
6.3 相关参数的确定
需要确定的参数包括:互信息的阈值ti、共现频数的阈值tc、互信息和聚合度的权重α和β以及互信息和聚合度综合评价PDI的阈值θ.
6.3.1 互信息和共现频数阈值
要确定互信息和共现频数的阈值,需要将语料库中所有的搭配关系抽取出来(共计155328个),提取其中的互信息和共现频数,形成一个2×155328的矩阵,每一列为一组搭配关系的互信息和共现频数,以图表说明其分布情况,如图4所示.

图4 互信息-共现频数分布图
根据互信息-共现频数分布图,可以发现其分布基本满足正态分布,分析图4可得,当互信息和共现频数分别在[2.8,3.4]、[2,2.5]之间取值时,ti和tc的区分能力相对较好,因此,可以将互信息的阈值ti和共现频数的阈值tc分别设置为3.2和2.
6.3.2 PDI相关参数
根据上文可以得知,互信息的值大于3.2,而聚合度的最大值为1,为了缩小互信息和聚合度之间的数值差距,取α:β=1:4,即α=0.2、β=0.8,既可以保持互信息的主导作用,又可以增加聚合度对PDI的影响.
进行PDI阈值的选择时,为了更好地进行比较,本文将不同阈值下的校对算法的准确率、召回率和F值绘制成图表,如图5所示.

图5 准确率/召回率/F值
分析图5可知,当阈值取到0.71时,F值达到极大值,因此可以取θ=0.71.
6.4 文本校对算法实现与评价
为验证本文算法的校对效果,本文基于MyEclipse和SQL Server 2008,采用Java语言编程实现.完成了一个用于进行文本校对的信息处理平台,并获取一定的测试语料对算法性能进行测评.实验分为三个部分:无错误文本测试集校对实验、错误文本测试集校对实验和常规文本测试集校对实验.
6.4.1 无错误文本校对实验
为了检测算法对于无错误文本的检测能力,从语料库中随机抽取了50条新闻,作为测试集进行测试.测试发现,校对算法没有在测试集中发现词语搭配错误,这说明该算法能够正确区分文本中是否存在词语搭配错误,但是算法是否存在过度拟合等情况还需要进行错误文本校对实验和常规文本校对实验.
6.4.2 错误文本校对实验
由于目前缺少权威性的文本错误测试集合,国内外有关中文文本校对的研究都是自行构建测试集合.因此,本文整理了某个中文问答系统的咨询日志并进行人工标注,作为测试集合.测试集合包含10000条咨询记录,其中文本错误417处.
本文采用检错准确率(P)、检错召回率(R)、检错F值以及校对正确率(A)四项作为对算法性能的评价指标,其计算方法如公式(7)-公式(10).
(7)
(8)
(9)
(10)
根据上述评价指标的计算方法,得出本文的实验结果,本文也对相关文献[2,15]所介绍的方法进行实验,并在本文的数据集上进行了验证,发现结果不如原文中给出的实验结果好,所以仍采用原文的实验结果,实验结果比较如表1所示.
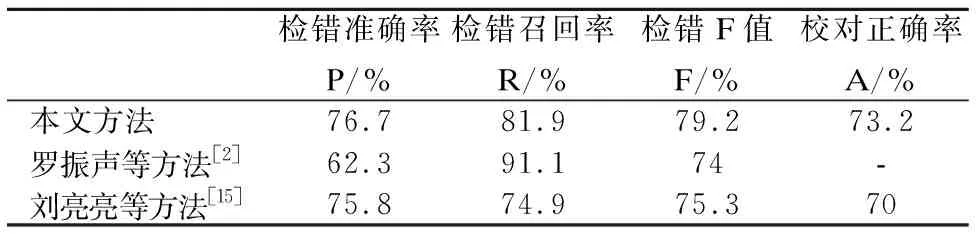
表1 实验结果比较
文献[2]采用了基于实例、统计和规则的语义级文本查错方法,通过语法分析,得到文本的句子成分,在语料库中检索与句子结构相似的实例,计算两者的相似度进行查错;同时,建立词义的N元邻接矩阵,计算语义平均概率和语义转移概率进行查错.召回率偏高主要是因为其测试语料不仅存在语义错误,还包括语法和构词等错误,并且语义错误在整个语料中所占的比例较小.
文献[15]通过对文档进行向量化,对文本进行相似度计算和模糊匹配,得到一个模糊词集合,如果模糊词集合为空,说明文本正确;如果不为空,那么模糊词集合就是修改建议.该文献中的召回率并不理想,主要是因为模糊分词和模糊匹配对非词错误的检查效果非常好,但是面对真词错误时,模糊匹配的方法非常容易误判.
根据表1的实验结果,本文能够对错误文本起到较好地校对作用,没有过度拟合等情况出现.
6.4.3 常规文本校对实验
经过上述实验可以发现,在对无错误文本测试集、错误文本测试集的测试实验中,算法都能够起到比较好的校对作用.为了进一步测试算法对书籍文章的校对效果,本文收集了实验室的10篇硕士论文初稿作为测试集合.经过测试,检测出其中存在227处错误,通过人工校对,其中166处错误确实存在,检错准确率为73.13%.为了确定召回率,对10篇文章进行了精读,发现其中实际存在289处错误,召回率为78.55%.对校对结果进行分析后发现,166处错误中有115处错误得到了正确的修改意见,校对正确率为69.36%.所得结果略低于表1中的实验结果,这是由于训练语料集合是以日常书面用语为主的《人民日报》新闻体裁语料,测试集合为问答系统的用户咨询记录,该记录中也是以日常书面用语为主,所以能够起到相对较好的校对效果.而选择的硕士论文是计算机专业的相关内容,在词语搭配方面,与日常书面用语存在一定的差别,造成了实验结果的差异.
上述实验表明了,由于引入了聚合度和互信息双重阈值限制,使得算法的检错准确率和校对准确率有了一定的提升.而语法和词语搭配双重检测机制也在一定程度上保证了算法的召回率.
7 结束语
本文介绍了一种综合使用了语言学和统计学等方法,通过建立语法-词语搭配的双层检测结构,规则和统计相结合,检测文本词语搭配错误,并以互信息和聚合度作为校对标准的文本校对模型.本文利用了马尔科夫链作为文本的基本模型,通过互信息等参数来构建词语搭配有向关系知识库,综合互信息和聚合度等参数构建语法-词语搭配双重检测体系,能够在一定程度上保证文本校对的召回率、准确率及检错的正确率.
但是,在以上研究中,由于马尔科夫链本身复杂度以及数据量的限制,本文的方法对于距离较近的词语搭配能够起到较好地校对作用,而对于一些长距离的词语搭配关系很难起到校对作用;对于句子的成分缺少有效的分析,只是对于词性间的搭配关系进行了提取;对于词语搭配关系也没有进行相关的语义分析,使得知识库中存在错误的词语搭配关系,这对文本校对的准确率造成了一定程度的影响.
由于选取的训练语料库是1998年上半年《人民日报》的标注语料库,其内容属于标准的新闻题材文本,对于目前网络中带有"口语化"成分的网络文本而言,本文的校对模型和算法的效果并不理想.不过目前已经有针对网络用语的研究在进行中,后续会加强相关的研究,尝试设计适用于长距离文本的语言模型、加强对于语句成分和语法的分析以及词语搭配关系的语义分析等研究工作,进一步提高文本校对方法的准确性.
