基于改进LDA算法的测试用例优先级排序研究
2018-11-09
(湖南交通工程学院电气与信息工程学院,湖南 衡阳 421001)
0 引 言
软件开发团队通常会创建大型测试套件来进行软件测试,由于测试套件非常大,对每个源代码执行测试是不现实的。在这种情况下,开发人员需要对测试套件进行优先级排序,以便更容易发现未被检测到的错误测试用例。研究人员提出了许多自动化用例优先级技术 。静态测试用例优先级排序技术与大多数现有技术不一样,静态技术具有较低的成本、轻量级,适用于许多实际情况。然而,现有的静态测试用例优先级排序技术基本不使用测试用例中的元数据,如测试用例的语言数据。因此提出一种新的静态测试用例优先级排序算法,使用测试用例的语言数据来帮助区分它们的功能。算法采用基于改进LDA主题模型的文本分析算法,利用语言数据创建主题,并对包含不同主题的测试用例进行优先级排序。
1 系统模型
测试用例优先级排序是指对被测试系统的测试用例集合中的测试用例进行排序,目标是最大化测试用例故障检出率等目标。当测试用例集合的执行被中断或停止时,则优先级更高的测试用例就会被执行。给定测试用例集合T,T的排序集合PT,评估函数f,测试用例优先级排序的目的是对于所有的T′′∈PT,找到T′∈PT,使f(T′)≥f(T′′)。PT是关于T的所有可能优先级集合,f是决定给定优先级性能的评估函数。性能的定义可能会有所不同,这是因为开发人员在不同的时间会有不同的目标。开发人员可能首先希望找到尽可能多的错误,然后实现最大的代码覆盖率。一般来说,实现最优优先级排序[1]的主要步骤如下:
1)将每个测试用例编码为它所涵盖的内容。例如,编码后的测试用例可能是测试用例覆盖的程序语句。
2)使用距离最大化算法对测试用例进行优先级排序,以最大化覆盖率或多样性为目的
1.最大化覆盖率。对测试用例进行优先级排序,从而最大化所覆盖元素的数量,以测试尽可能多的测试用例,增加故障检测的机会。
2.最大化多样性。首先计算测试用例之间的相似度;然后通过最大化它们之间的不相似性来区分测试用例。相似度高的测试用例可能会检测到相同的错误,因此只需要执行一个测试用例。
黑盒静态优先级排序使基于测试用例的源代码的优先级排序。测试用例是基于其源代码的某些方面进行编码的,不需要执行信息、规范模型,只需要测试用例的源代码。此研究提出了一种新的黑盒静态测试用例优先级排序算法,利用了测试脚本中的元数据,即标识符、注释和字符串文字。然后将基于主题模型的文本分析算法应用到测试用例语言数据中,将测试用例抽象为主题,并计算测试用例对之间的相似性。主题模型算法能够从语言数据中发现的主题,该主题能够很好地表征源代码中的潜在功能。当两个测试用例包含相同的主题时,测试用例在功能上是相似的,并能检测到相同的错误。所提出算法的处理流程如图1所示。

图1 基于改进LDA主题模型的测试用例优先级排序算法流程
对测试用例集合进行预处理以提取其语言数据,包括了测试用例的标识符、注释和字符串文字。将主题模型应用到预处理后的测试用例集合,为每个原始测试用例生成一个主题向量,主题向量描述了测试用例被分配到每个主题的概率。根据主题向量计算测试用例之间的距离。最后使用距离最大化算法将测试用例的平均距离最大化。
2 基于改进LDA主题模型的优先级排序算法
提出一种改进的LDA(Enhanced Latent Dirichlet Allocation,ELDA)主题模型来表示文本数据和各种标记。在应用基于主题的测试用例优先级排序算法之前,需要对测试用例的文本进行预处理。删除测试用例中的特殊字符(如,&、!、+)、数字和编程语言的关键字,只留下标识符名称、注释和字符串文字。接下来,根据驼峰式命名法和下划线命名方案对标识符名进行拆分,例如将标识符“testCase”拆分为“test”和“Case”。然后把每个单词表示成简化形式。例如,将两个单词“tests”和“testing”表示为“test”。最后,去掉常见的停止词以减少测试用例词汇表的大小,从而在更干净的数据集上进行操作。
ELDA算法是基于LDA文档主题生成模型进行改进,通过学习狄利克雷分布先验(Dirichlet priori)和标签之间的权重,ELDA能够处理半结构化和非结构化文档。语料库D={(w1,t1),...,(wM,tM)}中有M个文档,其中二元组(wi,ti)表示文档i,wi是文档i的词袋集合,ti是文档i的标签集合。目的是为语料库建立一个概率模型,该模型利用标签信息为相似的文档赋予极大似然。假设有概率矩阵P={pij}K×V,主题分布矩阵TD={tdij}L×K,狄利克雷分布超参数μ,狄利克雷分布参数π,以及伯努利先验参数η。L是指标签的数量,K是指主题的数量。用ϑd表示文档d的主题分布,用ξd表示文档d中标签的权重向量。提出的改进LDA(ELDA)算法如下所示。

算法1 改进LDA(ELDA)1: For k in K do //初始化概率矩阵2: pk~Dir(β);3: End for4: For t in T do //初始化主题分布矩阵5: tdt~Dir(α);6: End for7: For d in D do //对于每一个文档8: λ~Dir(μ);9: Calculate(Td); //用td生成Td10: εd~Dir(Td×π);11: Calculate(ϑd); //用εd生成ϑd12: For wdi in wd do //对于每一个单词13: zdi~Multi(ϑd);14: wdi~Multi(pzdi);15: End for16:End for
算法1中,Dir()是狄利克雷分布生成函数,Multi()是多项式分布生成函数。λ是标签的主题分布。接下来,定义Θd如下,
(1)
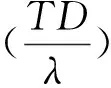
(2)
p(εd,z|wd,Td,TD,P,η,π,μ)=
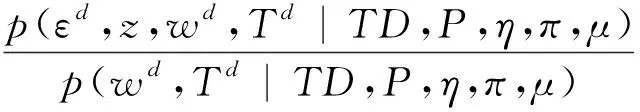
(3)
对公式(3)进行变形,能够得到文档d的边缘分布。为了提高计算边缘分布的效率,采用了基于平均场理论的变分期望最大化算法,Jensen不等式,得到边缘最大似然的计算公式如下
L=E[logp(T|η)]+E[logp(εd|Td×π)]+
E[logq(εd)]-E[logq(λ)]-E[logq(z)]
(4)
其中,q是如下所示的全分解分布
q(εd,λd,z|ξ,ρ,γ)=
(5)
使用曼哈顿距离作为距离的度量,而对于距离最大化算法,使用一个改进版的贪心算法(Elbaum et al. 2002)。首先利用公式(6)计算每两个测试用例之间的距离。
PairDis(tci,PS,Dis(tci.tcj))=
min{Dis(tci.tcj)|tcj∈PS,j≠i}
(6)
然后,对于距离较大的测试用例,将其中一个测试用例加入已排序集合PS。接下来,对于每一个测试用例,以迭代的方式将距离大的测试用例加入集合PS,直到所有测试用例都被确定了优先级。
3 实验及结果分析
为了验证ELDA算法的有效性,将本文提出的基于主题的算法与基于图形技术[2]、基于字符串的算法进行对比。从软件基础设施库(SIR)[3]中获得实验所需的三个测试数据集,每个数据集包括了故障注入的源代码、测试用例和故障矩阵,数据集的详细参数如表1所示。
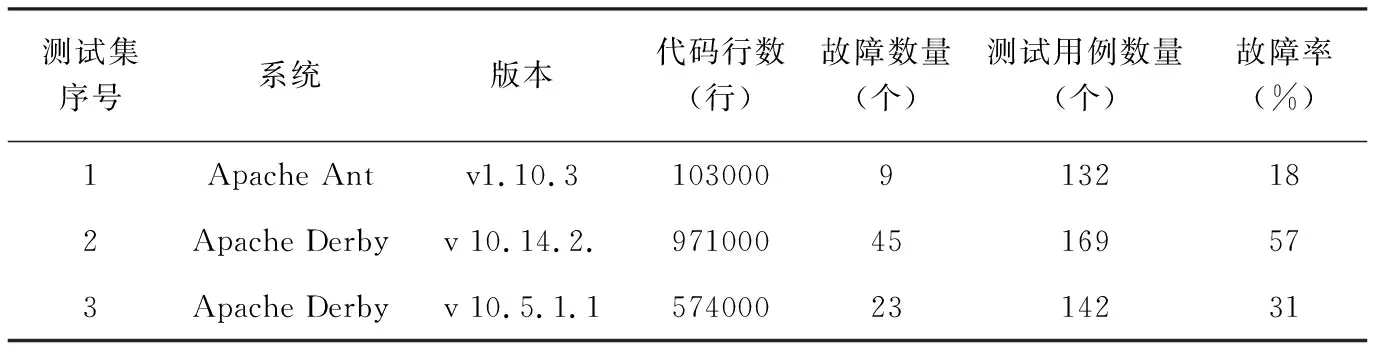
表1 测试数据集参数
利用表1的数据集来考察三种算法在平均故障检测率的性能差异,实验结果如表2所示。平均故障检测率是指优先级测试套件所检测到的故障百分比的平均值,计算方式如公式(7)所示。
(7)
其中,n是测试用例的数量,m是故障的数量,fi是在检测到故障i之前必须执行的测试数量。当测试用例优先级技术的有效性增加时(即使用更少的测试用例以检测出更多的故障),平均故障检测率AverF就会接近100。由表2可知,该算法ELDA具有最高的平均故障检测率。
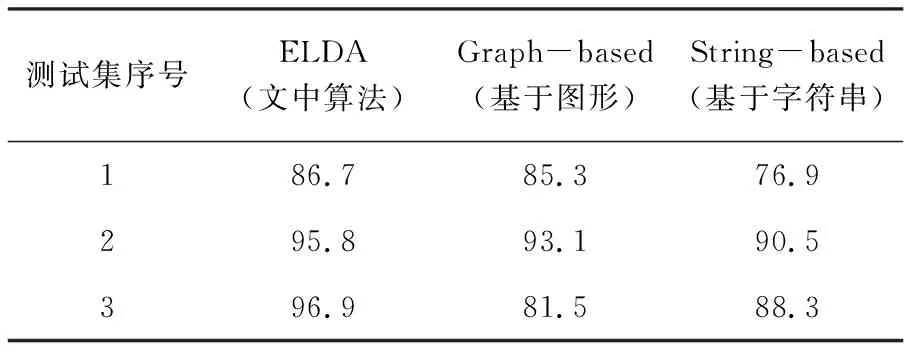
表2 三种算法的对比实验结果
4 结 语
针对静态黑盒测试用例优先级排序问题,提出了一种新的基于改进LDA算法的黑盒静态用例优先级排序算法,使用改进后的LDA主题模型算法将每个测试用例抽象为更高层次的主题。未来使用不同的距离度量以及采用基于进化算法的距离最大化算法来进一步优化基于主题的算法,并且将扩展案例研究以进一步验证算法的性能。
