人工智能下复杂软件源代码缺陷精准校正
2023-09-20刘楷正乔阳阳王丽娟
刘楷正,乔阳阳,董 涛,王丽娟
(1. 郑州工商学院信息工程学院,河南 郑州 451400;2. 华北水利水电大学电力学院,河南 郑州 450046)
1 引言
现阶段,计算机软件在各个行业中都得到了广泛运用,其发展规模不断扩大,复杂程度也在不断地提高。随着网络技术的迅速发展,给软件工程领域带来了新的机遇和挑战[1]。目前来看,软件系统的发展规模越发庞大,系统的结构日趋复杂,如何保证软件代码安全、可靠地运行,始终是软件研究领域所关心的重点问题[2]。软件源代码缺陷问题影响着整个软件开发的过程,是十分重要的一个环节。由于软件缺陷问题所带来的损害通常并不只是经济上的损害,而是在重要的体系发生故障时,会危及人们的人身安全和财产安全[3]。因此,在软件开发应用前,对软件源代码缺陷进行校正,是当前软件工程研究领域的一个热点问题。
王晓萌等人[4]研究了一种利用多信道卷积网络进行源码缺陷识别的算法,利用word2vec、fasttext等词汇嵌入技术表示词汇间的矢量关系,并建立了一个完整的矢量表示模型,用来表达源代码的特征;该方法通过对源码中缺陷类型进行深入的卷积网络学习,构造出一种基于源代码缺陷类型的源代码故障分类器,从而达到对多类别代码缺陷的准确识别,用SARD和开放源码对其进行了检验。曹英魁等人[5]在解析代码过程中,结合ExpTrans.ExpTrans,以图表的方式实现了代码的自动转换,明确地指明了代码中变量间的相关性,并将图卷积网络与 Transformer体系相融合,提高了该模型的编码结构和相关信息,从而提高了代码转换的精确度。通过仿真证明了,ExpTrans在修改例数和精确度方面都有很大提高,准确率上升了20%左右。
基于以上研究背景,本文将人工智能技术应用于复杂软件源代码缺陷校正中,避免软件受到黑客攻击。
2 复杂软件源代码缺陷校正方法设计
2.1 分析复杂软件源代码语义
在复杂软件中,将源代码的终结符集合和非终结符集合定义为Σ和Ω,用D∈Ω代表源代码的开始字符,G为一个规则的代码集合,通常采用S->β形式表示,g代表源代码规则集G中终结符的形成概率,在源代码规则集的左部,g与非终结符形成概率的和为1,表示为:
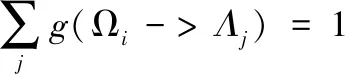
(1)
式中,Ωi代表源代码的非终结符,Λj代表复杂软件源代码的字符串。
根据概率学数学方程式[6],计算复杂软件中全部源代码的语义概率值Q(D),并将出现概率最大的语义概率值作为源代码语义分析的样本,利用语法分析器[7],对源代码的语言文本进行分析:

(2)
式中,Q(t,s)代表源代码最优的语义规则概率,t代表未进行标注的源代码语义样本参数,Φ代表复杂软件源代码语义分析过程中的符号流。
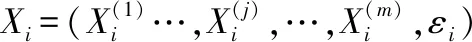
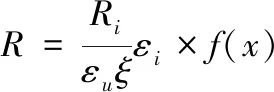
(3)
式中,f(x)代表源代码语言符号流的延续函数,即复杂软件源代码语义函数接收上一个延续作为新添加的参数。
通过对所有复杂软件源代码语义符号流的转化和解析,得出了源代码的语义过渡阶段函数Ud、条件转移函数KS,并依据所述的源代码中间变换进行了新的解析[8],从而得出了复杂软件源代码语义分析结果:
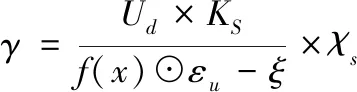
(4)
利用语法分析器,建立源代码语言的文本分析树,通过定义源代码语言文本中间转换执行流的延续,分析复杂软件源代码语义。
2.2 验证复杂软件源代码的程序标注
在对复杂软件源代码程序标注验证分析的过程中,首先需要采集源代码程序运行过程中的异常项信息,并获取异常信息出现次数,结合人工智能的计算机技术[9],计算出后验概率:
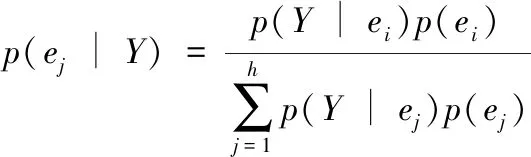
(5)
式中,p(Y∣ei)和p(Y∣ej)分别表示源代码程序Y在ei和ej状态下的条件概率,p(ei)和p(ej)分别表示ei和ej的后验概率。
对复杂软件源代码程序进行标注后,采用人工智能技术中的聚类算法再对复杂软件源代码的程序标注进行验证[10]。通过对样本集的匹配,组成N个新的复杂软件源代码样本集,从而获得M个源代码特征指标yj={y1j,y2j,…,ymj}T,则复杂软件源代码样本集可以通过N×M阶矩阵描述为:
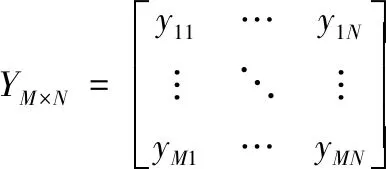
(6)
根据h个级别标准,对N个源代码程序的M个指标特征进行分类和识别[11],从而得到复杂软件源代码模糊矩阵表示为:
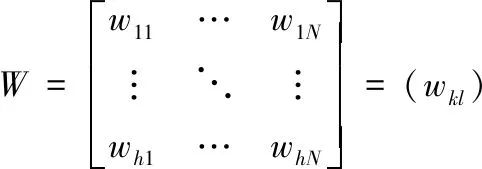
(7)
式中,wkl表示源代码程序l对应级别k的隶属程度。
假设,每个级别k内包含M个特征指标值,根据h个级别的标准,对M×h阶标准矩阵进行描述,表示为:

(8)
式中,uzk表示复杂软件源代码k指标满足z的标准指标值。
得到N条复杂软件源代码程序标注的标准指标集,将程序标注中待分类的指标集ψs与源代码程序库进行混合比对,通过对模糊矩阵的计算[12],得到程序标注的贴近度,设N×M阶的两个矩阵B(bij)和V(vij),则有:

(9)
通过上式可以得到复杂软件源代码程序标注与集合的贴近度,如果所获得的结果与所述精确的程序标注并不相符,那么,对复杂软件源代码程序标注集与每个样本集的贴近程度进行比较,如果所述的结果与程序标注样本集匹配,说明复杂软件源代码程序标注不存在问题,反之说明程序标注结果不准确。
引入人工智能领域的计算机科学技术,计算复杂软件的后验概率,利用模糊矩阵计算源代码缺陷的贴近度,验证复杂软件源代码的程序标注。
2.3 设计源代码缺陷校正算法
假设nDs表示源代码缺陷数量,nC表示复杂软件源代码总行数,Os表示复杂软件源代码缺陷校正密度,其计算公式为:
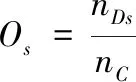
(10)
根据复杂软件源代码缺陷特征数据的计算结果,对源代码缺陷进行预处理,表达式为:
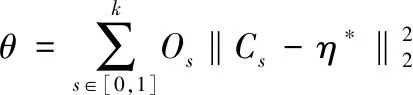
(11)
式中,Cs代表复杂软件源代码缺陷校正的能力,η*代表复杂软件源代码缺陷率,k表示一般常数。
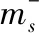
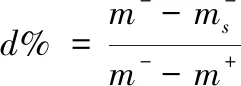
(12)
式中,d%表示复杂软件源代码缺陷的欠抽样处理结果。如果结果d%=0,说明复杂软件源代码缺陷没有进行校正操作;如果d%=50%,说明复杂软件源代码缺陷数据比正常数据的数量要多百分之五十;如果d%=100%,则说明复杂软件源代码缺陷校正效果良好,即复杂软件源代码缺陷数目趋向为零。
假设A和C分别表示复杂软件源代码缺陷校正变量,对复杂软件源代码缺陷信息进行处理[14],得到复杂软件源代码缺陷特征关联度信息,具体计算公式为:
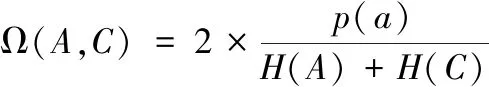
(13)
式中,H(A)和H(C)代表复杂软件源代码缺陷特征变量,p(a)代表复杂软件源代码缺陷特征取值为a的校正概率;如果Ω(A,C)∈[0,1],当Ω(A,C)越大时,表明复杂软件源代码缺陷之间的关联度较高,相反,如果Ω(A,C)越小,则说明复杂软件源代码缺陷特征间的关联程度越低。
基于人工智能中的数据依赖性分析理论[15],提取出复杂软件源代码缺陷校正分区依赖关系,表示为:
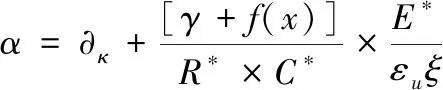
(14)

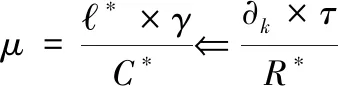
(15)
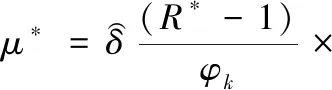
(16)
式中,φk代表复杂软件源代码缺陷校正的初始化函数,ϑc代表复杂软件源代码缺陷校正过程中的内存模型,μ*代表校正系数。
综上所述,根据复杂软件源代码的缺陷密度,利用人工智能聚类算法,预处理了源代码缺陷特征,依据人工智能的数据依赖性分析理论,提取出源代码分区的依赖关系,结合代码转换,实现复杂软件源代码缺陷的校正。
3 仿真分析
3.1 仿真环境
为了验证所研究方法在校正复杂软件源代码缺陷时的性能,采用PyTorch开源框架对复杂软件源代码进行编写,编程语言为Python 4.2,环境参数为PyCharm+PyTorch。
3.2 实验对象
在3.1节的实验环境下,本文选择Siemens复杂软件作为实验对象进行验证,复杂软件程序的基本信息如表1所示。
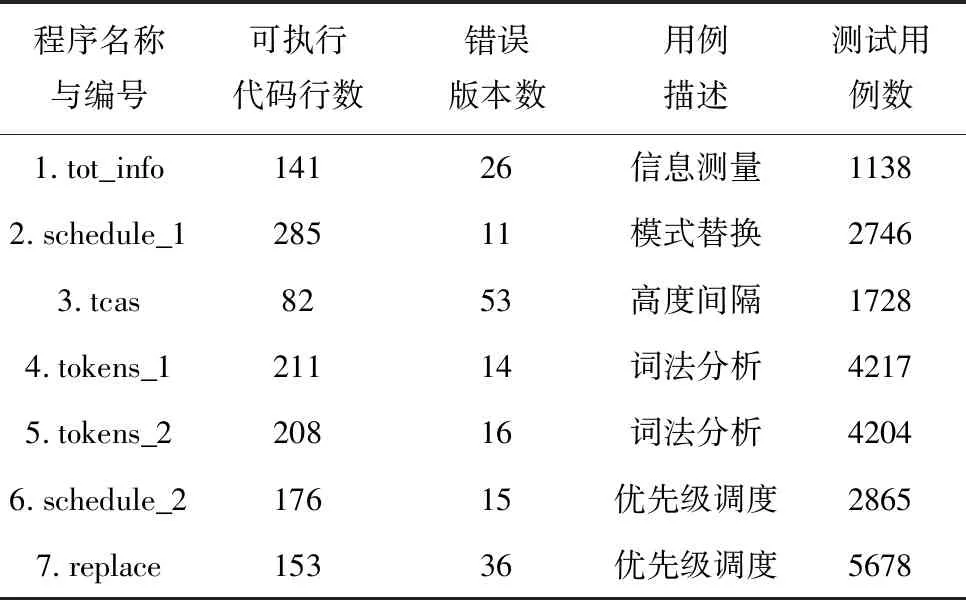
表1 复杂软件程序的基本信息
3.3 测试复杂软件程序的运行效率
采用所研究方法对复杂软件的源代码缺陷进行校正之后,测试了表1中各个程序的运行效率,为了突出所研究方法的优越性,引入基于深度卷积神经网络的校正方法和基于结构信息增强的校正方法作对比,结果如图1所示。
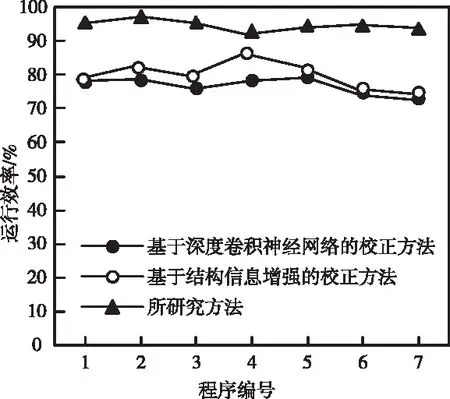
图1 复杂软件程序的运行效率
根据图1中的结果可知,由于Siemens复杂软件在运行过程中的安全性较低,会导致源代码存在缺陷,从而影响软件程序的运行效率,利用所研究方法对Siemens复杂软件源代码缺陷进行校正,可以将软件程序的运行效率提高到90%以上,避免软件程序出现卡顿的现象,而基于深度卷积神经网络的校正方法和基于结构信息增强的校正方法的运行效率低于所研究方法,说明所研究方法具有更高的应用价值。
3.4 性能对比
进一步测试复杂软件源代码缺陷的校正准确率和召回率,结果如图2和图3所示。
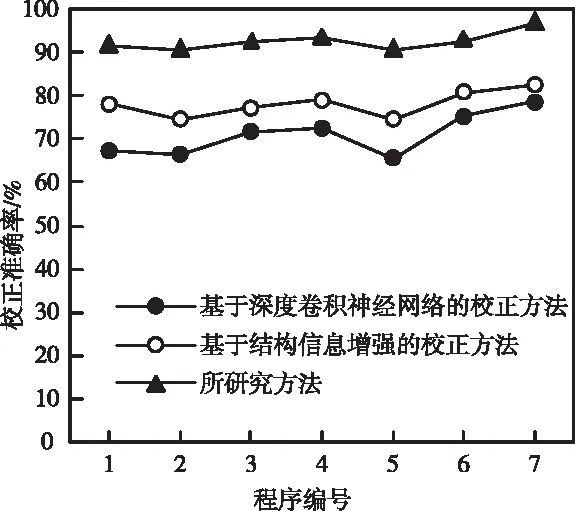
图2 复杂软件源代码缺陷的校正准确率
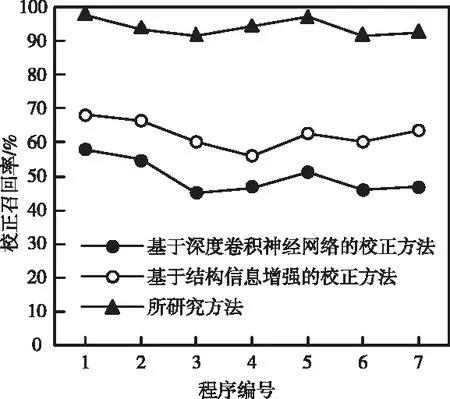
图3 复杂软件源代码缺陷的校正召回率
从图2中的结果可以看出,与基于深度卷积神经网络的校正方法和基于结构信息增强的校正方法相比,所研究方法可以将复杂软件源代码缺陷的校正准确率提高到90%以上,能够准确对源代码缺陷进行校正,降低复杂软件出现漏洞的概率。
图3中的结果显示,采用基于深度卷积神经网络的校正方法和基于结构信息增强的校正方法时,复杂软件源代码缺陷的校正召回率在70%以下,会出现误检的情况,而采用所研究方法时,复杂软件源代码缺陷的校正召回率能够达到90%以上,能够保证复杂软件的稳定运行。因为所研究方法根据复杂软件源代码的缺陷密度,采用人工智能技术中的聚类算法预处理源代码缺陷特征,并依据数据依赖性分析理论,提取出源代码分区的依赖关系,实现了复杂软件源代码缺陷的校正。
4 结束语
本文提出了基于人工智能的复杂软件源代码缺陷校正仿真,经过仿真分析发现,所研究方法具有较高的缺陷校正准确率和召回率,能够保证复杂软件的稳定运行。但是本文的研究还存在一定不足,在今后的研究中,需要对复杂软件的注入攻击进行检测,通过提高复杂软件源代码的安全性,避免复杂软件源代码出现缺陷。
