个人所得税缩减贫富差距的效应有多大?1
——基于CHNS调查数据和刀切法的动态评估
2018-11-05连洪泉高庆辉周业安
连洪泉 高庆辉 周业安
0 引言
各国在经济发展过程中不得不面对亟须迫切解决的社会和经济难题:日益悬殊的贫富差距,以及由此引发的各种社会治安、阶层冲突及社会矛盾等问题。如何采用合适的政策工具降低中低收入者的生活负担,加大对高收入者的调节作用,避免贫富差距进一步扩大,是各国政府需要慎重权衡取舍的重要政策选择问题,个人所得税也由此成为调整居民收入再分配的首选政策工具。而我国自改革开改以来,短短三十多年时间里,个人所得税从立法、开征到两税合并,工资所得税免征额调整了三次,从800元、1600元(2006年)、2000元(2008年)调整到3500元(2011年),个体工商户生产、经营所得税免征额也在相应改革年份中从19200元、24000元提高至42000元,税率结构从9级缩减为7级。总体来看,整个税制改革进程大刀阔斧,调整力度不可小觑。由此现实改革背景自然引发出两个问题:我国个人所得税政策所带来的收入再分配效应究竟有多大?它能否发挥政府意图缩减贫富差距的政策效果?
为更好研究我国个人所得税的收入再分配效应,准确得知个人所得税调节居民贫富差距的效果,亟须研究者充分利用居民微观层面的调查数据而非城镇住户调查的加总数据(岳希明等,2012)。国内已有一些学者借助国家统计局城镇住户抽样样本或者CHIPS等微观调查数据评估我国某个税制改革阶段的税收免征额设定及其税收累进性、实际发生或模拟不同免征额情境的税收再分配效应(岳树民等,2011;岳希明等,2012),或者估算某个时间段的基尼系数(杨耀武和杨澄宇,2015;等),这些研究为税收实践提供了非常宝贵的借鉴意见,也为这一领域的后续研究工作提供参照范本。然而,已有研究还明显欠缺我国三次税制改革的实际再分配效应的综合动态评估工作,唯一例外的是徐建炜等(2013),他们利用国家统计局的城市住户抽样调查数据综合评估1997—2011年我国城镇居民家庭的税前和税后基尼系数,分解、比较和评估我国个人所得税的纵向公平、横向公平、平均有效税率和税率累进性问题,研究发现我国个人所得税政策调整在提高税制累进性的同时也降低了平均有效税率,总体上它恶化了税收的收入再分配效应。
不过,对于我国三次税制改革的实际再配效应综合评估工作还是很有必要进一步进行深入的研讨。主要理由如下:首先,徐建炜等(2013)一文把税收的收入再分配效应简单分解为纵向公平效应和横向公平效应,而其中的横向公平效应实际上是横向不公平效应和再排序效应的总和,他们并没有严格依据其所参照的Aronson et al.(1994)分解公式把税收再分配效应分解为纵向累进效应(vertical progressivity effect,即徐建炜等(2013)论述的纵向公平效应)、横向不公平效应(horizontal inequity effect,即徐建炜等(2013)论述的横向公平效应)和再排序效应(reranking effect),因而他们对于税收的横向不公平效应的评估结果及判断是有瑕疵的(连洪泉,2015)。其次,徐建炜等(2013)的综合评估对象是以家庭而非个人作为核算单位,而个人所得税的征税对象是个人而非家庭,因而以家庭为核算单位并不能真正度量个人所得税缩减个人贫富差距的实际效果。第三,徐建炜等(2013)的论文只针对城镇居民估计而忽视了农村居民,这会明显低估我国的税收再分配效应。最后,徐建炜等(2013)采用的是国家统计局的城市住户抽样样本框,而学界对于基于官方抽样框和民间研究机构抽样框的基尼系数研究结果争议颇多(如甘犁,2013;岳希明和李实,2013;等)。另外,杨耀武和杨澄宇(2015)的研究结果发现,2008—2013年我国基尼系数连续五年下降的基本结论在采用自助法(bootstrap)进行区间估计之后并不能成立。这意味有关基尼系数的主要研究结论还需要经得起来自民间其他研究机构调查数据和其他统计方法的稳健性检验。
有鉴于此,本文利用CHNS微观调查数据并运用刀切法评估我国税制改革的收入再分配效应及其分配效应的动态变化。相对于已有研究,本文具有三个边际贡献:其一,本文严格按照Aronson et al.(1994)的税收再分配效应分解思路进行分解和评估,相对国内已有研究能够更加合理地评估我国税收再分配效应。其二,不同于国内评估税收再分配效应常用的直接样本估计或自举法(bootstrap)估计,本文提供了刀切法的估计结果及区间;这一估计方法可以在解决可能的有偏样本无偏估计问题同时,也为国内税收再分配效应究竟是改善还是恶化的争议结论提供一份新的经验证据。最后,本文试图通过与已有研究不同的微观社会调查数据和统计方法综合评估我国不同时段税制改革的税收再分配效应,这一评估结果并不只局限于城镇住户调查数据,而是包含城镇和农村住户,因而它可以为我国税制改革缩减贫富差异的政策意图提供一个全面的量化评估结果,并为如何进一步完善税制改革缩减贫富差距建言献策。
本文其余部分安排如下:第1部分简要概述有关税收的收入再分配效应及其分解效应,第2部分简要介绍CHNS调查数据和刀切法,第3部分评估我国税制改革实际的收入再分配效应及其分解效应的动态变化,最后一部分为本文的结论和政策建议。
1 文献回顾
学界往往通过基尼系数来刻画居民贫富差距,并以税前与税后收入的基尼系数比值或差额作为税收的再分配效应(redistribution effect,RE)度量指标。这一做法最早可追溯至Musgrave and Thin(1948),在他们看来,通过税后收入分配的公平系数与税前收入分配的公平系数的比值可判断税率类型,当这一比值等于1时税率为比例税率,大于1则为累进税率,小于1则是累退税率。Kakwani(1977)认为,如果采用基尼系数测度不平等,那么税前和税后收入的基尼系数差额或者比值确实可以成为税收累进性的一个简单指标。[注]需要指出的是,国内外学者普遍把税前和税后基尼系数差额称之为MT指数,这一说法主要源自Kakwani(1977)的论述,但是该指标并不存在Musgrave and Thin(1948)一文当中。鉴于这一说法已得到国内外已有研究的普遍认可,本文也认可这一说法。这一简单指标通用性强,可比性高,但是也存在两个不足:其一是基尼系数在测度收入差距方面存在瑕疵。它一方面很难测度收入分布变化的影响效应,另一方面却对中等收入人群的收入变化比较敏感。其二是这一指标很可能是税收的横向不公平和再排序效应等综合作用的结果。因为从理论上来讲,如果两人在税前收入相当,那么他们的税后收入也理应相当,即他们的税收待遇是一致的(Feldstein,1976)。但是在现实生活中由于偷税漏税、不同税源或不同税率等原因导致相同收入享受不同税收待遇,由此形成横向不公平效应。此外,不同等级的税率结构会使得那些收入处于同一税率等级上下的人在征税后的收入排序地位发生变化,形成所谓的再排序效应。因而,如何改善估计方法,从税收的再分配效应中分离出横向不公平效应和再排序效应,成为后续研究研讨的重点。
为此,Kakwani(1977)从理论和实证两方面证实税收再分配效应可以分离出平均税率和税收累进性的影响效应。他利用税收集中系数与税前收入基尼系数的差构造税收累进性K指数,并通过理论逻辑推导出再分配效应与税收累进性指数、平均税率的关系。通过对澳大利亚、加拿大、英国和美国1960和1970年代的税收收入再分配效应以及K指数和平均税率t所占比重分析,作者证实了这样一个核心结论:即税收缩减贫富差距的收入再分配效应不仅依赖普遍认可的税收累进性程度,同时也取决于该国的平均税率水平。
不同于Kakwani(1977)把税收的再分配效应精确分解为税收累进性和平均税率的影响效应,Aronson et al.(1994)则允许征税过程中存在税收评价误差,因而税后基尼系数将由三部分构成:不同收入群体的组间基尼系数、各个收入群体的组内基尼系数值和不同收入群组收入发生再排序的数值。基于此,Aronson et al.(1994)把税收的再分配效应(RE)分解为三种效应:垂直效应(vertical effect)、横向不公平效应(horizontal inequity effect)和再排序效应(reranking effect)。[注]公式表示为RE=V-H-R;RE为再分配效应,V为垂直效应,H为横向不公平效应,R为再排序效应。依据Aronson et al.(1994)的定义,垂直效应是指每个人均严格遵照税制纳税,一视同仁并且不存在差异,它正好等同于Kakwani(1977)的再分配效应。横向不公平效应完全来源于相同收入的人因接受不同税收处理条件而产生的结果;再排序效应则是由于不同收入群组接受不同税收处理条件而产生税后收入再排序,它可理解为是税收再分配效应分解为垂直效应和横向效应之后的残差项。
基于税收再分配的这三种效应分解公式,Aronson et al.(1994)研究了英国1978—1990年的税收再分配效应问题。他们的实证研究结果发现,再排序效应占税收再分配效应将近三分之一,这一效应远远超过了垂直效应。而当采用不同的模型或数据时,垂直效应明显上升,不平等税收导致的处理效应明显下降,但是再排序效应依然显著存在。这一实证结果质疑了英国个人所得税在1978—1990年的公平性问题。Wagstaff et al.(1999)则综合Aronson et al.(1994)和Kakwani(1977)的分解方法,把12个OECD国家的税收再分配效应分解为平均税率、税收累进性、横向公平效应和再排序效应。实证结果发现,丹麦和英国大体上有着相类似的垂直效应,差异性征税造成的横向不公平效应占再分配效应的比例,与垂直效应所占比例要小得多;不同国家的横向公平效应存在差异,这一差异主要取决于当地收入税收水平以及诸如抵押利息支出、保险费用等项目的税收抵免差异。
在Aronson et al.(1994)的三种效应分解公式中,蕴含着这样的一个前提,即税收收入分布需要保证相同的税前收入划分为一组,而且在税前收入转换为税后收入过程当中,税制不仅不会影响这些群组的收入排序,也不会明显影响组内成员的收入排序。然而,假如现实生活当中的税制不仅能够改变税前近似收入群组的组内排序,而且也改变了全部收入群组的再排序时,此时Aronson et al.(1994)的分解方法就不能适用。为此,Urban and Lambert(2008)进一步修正Aronson et al.(1994)的税收再分配效应分解公式,基于再分配效应可分解为垂直效应、横向不公平效应及再排序效应的理论基础,他们进一步把再排序效应分解为Aronson et al.(1994)的再排序效应、组内的再排序效应和全部群组的再排序效应。考虑到克罗地亚政府在2000—2002年期间推行18个新的个人收入税收抵扣项目(PIT deductions)并且提高了家眷津贴,这些税改政策可能会影响税后的个人收入的再排序效应,因而作者收集了克罗地亚1997、2001和2003年的个人收入税收和社会保障缴纳数据分析税收的再分配效应,分析结果表明:单独由个人收入所得税造成的横向不公平和再排序效应非常有限,它只使得2003年的税收再分配能力下降不到3%。但是同时考虑个人收入所得税和社会保障缴纳,税收的再分配效应损失较大,2003年有12.4%的损失可归因于三种再排序效应。与此同时,实证分析结果还发现,构建相似收入群组所选用的区间组距会影响垂直效应、横向不公平效应以及再排序效应占再分配效应的比例值,由此引申出如何选择最佳组距以构建相似收入群组的进一步研究话题。
尽管已有研究呈现三种不同的税收再分配效应分解方法,不过Aronson et al.(1994)和Urban and Lambert(2008)的分解方法相对复杂,并且还存在相应适用前提,因而后续不少研究更多是运用税前和税后收入的基尼系数差额,或者采用Kakwani(1977)的计算方法测度不同国家或地区的税收再分配效应。例如,Caminada et al.(2012)运用税前和税后收入的基尼系数差额方法评估了欧洲20个国家1985—2005年的13个不同的社会转移项目和税收的再分配效应。实证结果发现,税收使得再分配效应下降17%, 而老年人退休和幸存者计划可以解释再分配效应60%的上升效应。Bird and Zolt(2014)通过对比北美、拉美、西欧、亚洲和非洲从1975—2002年3个不同时区段的税收结构和比例情形,发现个人收入税在发展中国家的税制当中发挥着非常小的作用。Verbist and Figari(2014)则研究欧盟15个国家1998—2008年的税收再分配效应,经验研究结果发现,税制对于再分配结果呈现复杂影响效应,一方面,边际税率的变化与税收再分配效应并不存在清楚趋势;另一方面,边际税率下降的国家,其个人收入所得税的累进性会随之增加;税收累进性和税率存在显著负相关关系,表明两者在影响再分配效应方面并非互补而是替代关系。更高收入不平等往往伴随着更低税率,这说明社会不平等程度越高的社会,对再分配的需求越小。
从国内研究来看,有关个人所得税的再分配效应研究主要集中于比较城乡、农村或城镇的税前和税后基尼系数(如李实和赵人伟,1999;岳希明等,2012),评估免征额变动的税收累进性或者税收的再分配效应(如彭海艳,2011;岳树民等,2011;岳希明等,2012;曹桂全和任国强,2014),而动态评估个人所得税的垂直效应和横向不公平效应的只有徐建炜等(2013)。考虑到我国个人收入所得税对于工薪所得和经营性所得实行两种截然不同的税率,它可能会使得税前收入相同的个体在征税后的个人收入排位发生变化,从而产生税收的再排序效应。因而,这一情形吻合Aronson et al.(1994)和Urban and Lambert(2008)有关税收再分配效应的分解要求,本文试图在综合借鉴Aronson et al.(1994)、Urban and Lambert(2008)和徐建炜等(2013)的基础上,在解决Urban and Lambert(2008)有关近似收入群组的划分难题的同时,运用刀切法动态评估我国的个人收入所得税的垂直效应、横向不公平效应和再排序效应。
2 个人所得税再分配效应的核算方法
2.1 税收再分配效应的核算方法
如前所述,现有研究主要通过计算税前收入和税后收入基尼系数,以二者之差来度量税收的再分配效应的指标,即:
RE=Gx-GN
(1)
其中,Gx表示税前收入的基尼系数,GN表示税后收入的基尼系数。Kakwani(1977)定义了税收累进性K指数,它是税收集中度系数CT与税前收入基尼系数Gx差额,公式表示为:
K=CT-Gx
(2)
税收集中度系数CT越高,说明收入增加导致纳税的份额越高,因此,当CT>Gx时,意味着税收增长速度快于收入增长速度,它表明税收关于收入的弹性大于1,因此税制是累进的。换句话说,当K>0,此时税制是累进的;并且K值越大,说明税制的累进性越强。与此相反,当K<0,说明税制是累退的。
在此基础上,Kakwani(1977)通过理论推导证明,再分配效应RE可以表示为平均税率t和税收累进性K指数的乘积,具体如下:
(3)
式(3)说明再分配效应取决于两个因素:平均税率t和税收累进性K。当税收累进性不变的时候,平均税率越高则税收的再分配效应越强;当平均税率不变的时候,税收累进性越强则税收的再分配效应越强。
当存在两种或多种税率时,此时征税会产生再排序效应。为此,Aronson et al.(1994)和Urban and Lambert(2008)把税收的再分配效应进一步进行分解。由于Urban and Lambert(2008)的分解更加详细,思路可以涵盖Aronson et al.(1994)的分解内容,其分解过程可以概括过以下三个步骤:
第一步,计算税前和税后基尼系数。对税前收入进行排序,该收入向量记为N1,按照N1计算得到基尼系数记为Gx,对应N1的税前收入集中度曲线的系数值为C1。按税后收入排序得到的向量记为N2,相应基尼系数记为GN,对应税后收入集中度曲线的系数值记为C2。
第二步,选择近似税前相等组(closepre-taxequalsgroups)并计算税收集中度系数。具体来说,按照固定的组距对税前收入进行划分,可以划分出不同收入人群,每个组将成为近似税前相等组。对每个近似税前相等组按照每个群组内的税后收入进行排序,该收入向量记为N3,该税后收入的集中度曲线系数值记为C3。对每个近似税前相等组按照它们的税后均值进行排序,而在每个群组内部则按照它们的税后收入进行排序,该收入向量记为N4,该税后收入的集中度曲线系数值记为C4。
第三步,构造平滑的税收份额并计算集中度系数。对于每个近似税前相等组,计算每个群组的税收占每个群组税前收入的份额g,然后用税前收入乘以(1-g),按税前收入排序由此构造出收入向量N5,该税后收入的集中度曲线系数值记为C5。对于收入向量N5的每个群组按照税后均值进行排序,而群组内则采用与N5一样的收入数值和排序,由此得到收入向量N6,该税后收入的集中度曲线系数值记为C6。
基于此,整个税收再分配效应的分解过程可以用公式表示如下。首先,如前所述,再分配效应分解为垂直效应、横向不公平效应和APK再排序效应,具体公式表示如下:
RE=V-H-RAPK
(4)
其中V为垂直效应,H为横向不公平效应,RAPK为APK再排序效应,三者计算分别如下:
另外,再排序效应RAPK可以进一步分解为AJL再排序效应RAJL,组内再排序效应RWG和组间再排序效应REG三者之和。
Urban and Lambert(2008)对于税收再分配效应的分解能够很好分离垂直效应、横向不公平效应和再排序效应,从公式当中可看出,横向不公平和再排序效应会导致收入再分配效应的损失。整个分解过程当中,最为核心的步骤在于如何选择近似税前相等组。Urban and Lambert(2008)的建议是先选择一个带宽(组距)后依据式(4)分解再分配效应,然后再依据式(8)评价每个再分配效应所占比重,不断重复计算不同带宽(组距),直至垂直效应V达到最大值,或者是画出所选择的不同带宽(组距)的各种再分配效应所占比重。尽管Urban and Lambert(2008)更倾向于推荐最后一种直观的画图方法,但是实际计算过程当中这一做法却不是最优方法,主要原因有二:其一是带宽(组距)选择量特别大,要画出每个带宽(组距)对应三种不同的再排序效应占比的工作量巨大,占用版面篇幅太多;二是Urban and Lambert(2008)是通过一个虚拟数据集来阐述再排序效应的三种可能性,实际中要画出这三种效应占比还要求实际数据确实能够发生组内再排序效应RWG和组间再排序效应REG。换句话说,任何一种税制要能够在近似相等组的组内和组间诱导出三种不同的再排序效应,然而理想的带宽(组距)选择是要使得垂直效应V达到最大值,此时再排序效应最小,实际数据很可能出现的情形是只有一种再排序效应。因而,我们退而求其次,通过选择不同带宽(组距)使垂直效应V达到最大值做法,同时呈现不同带宽选择对应的V值。
2.2 各参数标准误的估计方法——刀切法
无论是税前基尼系数、税后基尼系数还是再分配效应,它们实际上都是样本参数,在计算过程中,都应该汇报标准误差。然而标准误差计算相对复杂,这使得基尼系数或再分配效应的标准误差鲜有人汇报。考虑到标准误差计算的复杂性,我们尝试用非参方法估计我们计算参数的标准误差。常用估计方法有刀切法(jackknife)和自举法(bootstrap),其中刀切法是由Quenouille(1949)提出,它建立在再抽样理论基础上,应用范围广泛,主要用于估计未知总体分布的各种参数,适用于任何一种抽样方式进行抽样的样本,特别是容量较小的样本。Lenski and Service(1982)推导的数学证明表明,使用刀切法计算的方差将近似等于重复抽样的总体方差。Meyer et al.(1986)采用自举法和刀切法两种估计方法的对比研究发现,当抽样分布近似于正态分布时,这两种估计结果几乎一样;但是当抽样分布是负向有偏时,自举法和完全样本估计会产生明显有偏的估计结果,而刀切法的估计则是一致的。统计学界也有不少学者使用刀切法研究基尼系数标准误差和一致性问题。例如, Sandstrom et al.(1988) 就建议使用刀切法估计基尼系数的标准误差,Yitzhaki(1991)则改进刀切法对基尼系数标准误差的估计,减少了电脑的计算量;Berger(2008)则证明了刀切法估计基尼系数的一致性。为此,我们主要采用刀切法估计基尼系数和税收再分配效应的标准差,通过R程序软件实现估计结果。
刀切法原理是:对于未知分布的总体,从中抽取样本容量为n的样本,以样本统计量θn来估计总体参数θ会产生一定误差,尤其在小样本的情况下。为解决这样一个问题,可以将从原样本切去第i个个体后的计算得到的统计量记为θ-i。一般而言,估计值与实际值之间会相差一个常量(偏差)和一个无穷小量:

(14)
(15)
虚拟值的期望值等于总体参数减去一个无穷小量,由此表明它对总体参数的估计相对于θn更为精确。因此可用虚拟值的均值作为总体参数的一个无偏估计:
(16)
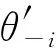
(17)
3 我国个人所得税再分配效应的核算结果
3.1 总样本抽样和评估结果
本文使用中国疾病预防控制中心营养与食品安全所(原中国预防医学科学院营养与食品卫生研究所)与美国北卡罗来纳大学人口中心合作的中国健康与营养调查(China Health and Nutrition Survey, CHNS)数据。该项目1989年得到美国国立卫生研究所(NIH)的资助,在辽宁、江苏、山东、河南、湖北、湖南、广西、贵州、黑龙江省疾病预防控制中心(防疫站、卫生监督所)的积极协作下合作展开,1989—2011年共进行了9次追踪调查。调查采用多阶段分层随机抽样方法;第一步是在中国东、中、西部地区随机抽取9个省(区)(1989—1997只有8个省份);第二步是按照收入的低、中、高等级将9个省(区)各县进行分层,依据权重样本表从各省(区)随机抽取4个县(1个高收入、2个中等收入和1个低收入)作为农村样本,各县除县城镇外再随机抽取3个村落分别代表高中低3个收入层次。对于城市样本,则抽取各省省会城市和1个低收入城市,并随机抽取各个城市的市区和郊区。第三步,对抽取到的农村和城市样本再按随机抽样法抽取社区样本,每个社区抽取大约20个家庭住户开展入户调查。不同年份的初级抽样单位(primary sampling units,以下简称PSU)有所变化。1989—1991年只有190个PSU,其中32个城市市区(urban neighborhoods)、30个低收入城市郊区(suburban neighorhoods)、32个镇(县城镇)和96个农村村落。1997年黑龙江省替代退出调查的辽宁省,2000年原先退出调查的辽宁省回归调查,PSU增加至216个,其中36个城市、36个低收入城市郊区、36个镇和108个农村村落。[注]数据源自官方网站 http://www.cpc.unc.edu/projects/china/about/design/survey。实际上每年的PSU都有稍微变化,具体可看官网每年PSU数据情况。
我们采用CHNS的个人收入调查数据展开分析。1989年CHNS调查了15917人,1991年只调查1989年调查样本住户,最终有14778人。1993年所有在抽样样本中的新住户构成抽样住户加入样本,最终13893人参与调查。1997年所有居住在抽样样本中的新住户也加入样本,新增住户替换不再参加调查的住户,增加新社区替换不再参与的社区,黑龙江省替换辽宁省,最终调查14426人。在2000年再次增加新住户、替换新社区、辽宁省再次回到调查样本,最终15648人参与调查。后续2004年、2006年、2009年和2011年大抵采用类似方法进行[注]截至2017年8月,CHNS官网公布的最新数据也只到2011年。。1997年是整个调查变化最大年份,基本上定型后续各年调查样本,为此我们采用自1997—2011年各年追踪调查数据。我们分析样本集中于18岁以上的所有成人调查问卷的收入情况。考虑到各年调查对于收入数据均是询问被试前一年的收入状况,因而个人收入数据对应的年份分别对应为1996年、1999年、2003年、2005年、2008年和2010年。
在CHNS的收入调查数据中,包含了城市样本和农村样本。其中城市居民收入主要包括了工薪收入、商业经营收入和其他收入;而农村居民收入则可能由工薪收入、商业经营收入、家庭菜园和果园、集体和家庭农业、渔业、家畜和家禽和其他收入构成。由于工资所得税和个体工商户生产经营所得税不一样,我们把城市和农村居民的工薪收入归为一类,把商业经营和其他收入归为另一类,由此得到表1分析城市和农村样本以年计算单位的人均收入和工薪基本信息。从表1容易看到,城市样本中的人均收入和人均工薪普遍高于农村样本,具体来看,城市的每年人均收入从1996年的5437元变动到2010年的28543元,每年人均工资从3682元变动到17088元;与此相反,农村的每年人均收入则相应从3767元变动到20663元,每年人均工资从1354元变动16221元。

表1 分析样本信息
注: 人均收入是各项收入加总的人均值。增长率是人均收入的名义增长率。工薪占比是当年所有工薪收入除以当年所有总收入的比值。人均收入和人均工薪的单位为每年,人均只是针对所有就业人员的算术平均值。
由于样本数据中缺少缴纳的个人所得税数额这一变量,因此本文借鉴徐建炜等(2013)研究方法,根据居民报告的不同类型税后收入,按照对应税率表,反推出每个人的应纳个人所得税额,由此反推得到应纳税额和相应的税前收入。基于此,我们可以利用样本计算相应的基尼系数和再分配效应,并且使用刀切法得到总体基尼系数以及再分配效应和标准误差估计结果和区间,具体如表2所示。

表2 税收再分配效应的估计结果
注: 括号内为刀切法估计的参数标准误差,参数的估计区间是95%的置信区间。
从表2可看出,我国税前和税后收入基尼系数在1996—2005年总体上呈现上升状态,从收入差距过大区间(基尼系数处于0.4~0.5之间)进入到收入差距悬殊区间(基尼系数大于0.5),连续多年位居收入分配差距“警戒线”(基尼系数大于0.4)之上。在2006年和2008年税改之后,税前和税后收入基尼系数开始缓慢下降。而从税收再分配效应来看,再分配效应从税改之前最高的0.015,增加至2008年和2010年的0.021,这说明两次税政政策的再分配效应有所提高,可以起到缩减收入分配差距的效果。
我们根据Urban and Lambert(2008)分解方法对每年税收再分配效应进行分解,具体见表3。由表3可知,垂直效应占再分配效应比例从1996—2005年均呈现上升状态,2006年和2008年的税改政策,使得垂直效应上升了,不过从垂直效应占比来看,它在2008和2010年总体下降了;与此相反,横向不公平效应在2003年达到最高占比0.051%,随后开始下降,税改之后下降至0.019%。再排序效应占比从1996—2005年一直处于上升状态,2005年达到最高值0.211%,并且它都超过了横向不公平效应,税改之后开始下降然后有所回升,至2010年回升至0.134%,但已小于2005年的高峰值。总体上来看,在税改的再分配效应中,垂直效应起主导作用,其次是再排序效应,最后是横向不公平效应。两次税改提高了垂直效应数值的同时,也降低了横向不公平效应和再排序效应。
依据Kakwani(1977)对税收再分配效应的分解公式,我们可以得到表4的分解结果。由表4可知,1996年至2008年的平均税率一直呈现上升状态,2008年的个税改革使得2010年的平均税率t下降0.001。与此相反,税收累进性K指数从1996—2005年一直则呈现下降状态,2006年和2008年的个税改革则使得税收累进性K指数上升。换句话说,2006年和2008年的税收再分配效应,主要是以提高税收累进性和平均税率的方式实现。
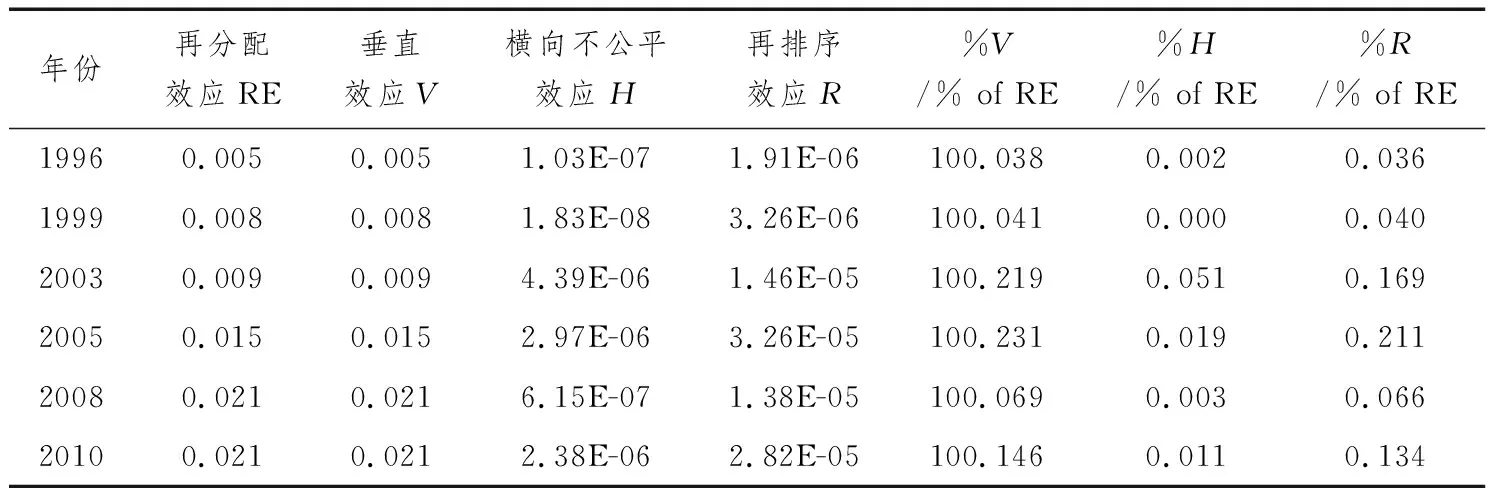
表3 再分配效应估计: 三种效应分解结果
注: 表3中对收入分配效应分解的计算,采用以每一年使得垂直效应V最大的组距。[注]表3报告的是采用的使垂直效应V最大的组距,各年份之间的组距可能会有所不同。笔者也尝试不同年份采取相同的组距来分解税收再分配效应,多次尝试的结果与表3基本一致(因为表3中的V已经是所有组中最大的V),因此这个结果是稳健的。

表4 再分配效应估计: 两种效应分解结果
注: 括号内为刀切法估计的参数标准误差,参数的估计区间是95%的置信区间。
我们按照税率表以确定的税后收入反推税前收入,假设只存在单一的税种(工薪税或经营税),那么在不存在偷税漏税的前提下,不会产生任何横向不公平或者再排序效应。因为高收入的个体尽管在累进税制下需要缴纳更高的税负,但是边际税率小于1将会导致其增加的税收绝对不会超过其增加的收入;此外,单一税种也不会出现同一收入遭遇不同税收待遇的情况。因而,若实行单一税种,那么横向不公平效应和再排序效应都应当等于零,个税的收入再分配效应将与垂直效应相等。换言之,表3所呈现的横向不公平效应和再排序效应,实际上是由于工薪税和经营税两类税率导致的结果,并且由于这两种不同税率及其累进性形成了如表4所示的平均税率t和税收累进性K指数。那么,工薪税和经营税各自的有效税率和税收累进性究竟如何呢?表5呈现了工新税和经营税各自的税率和税收累进性结果。
从表5可知,1996—2005年的工薪税和经营税的税收累进性K指数大体呈现下降状态,与此相反,工薪税和经营税的平均税率t大体上呈现上升情形。而2006年和2008年的个税改革对于工薪税和经营税产生差异影响效应。工薪税的税收累进性K指数先升后降,平均税率先降后升;而经营税的税收累进性K指数先降后升,平均税率先升后降。由此我们可以看出,税改对于工薪和经营两类收入的差异调整的方向,主要体现为平均税率和税收累进性此升彼降的权衡取舍。

表5 工资税与工商税各自的税收再分配效应: 两种效应分解结果
注: 括号内为刀切法估计的参数标准误差,参数的估计区间是95%的置信区间。
3.2 进一步的研究和讨论
首先,我们对于组距选择是否影响本文的再分配效应结果进行稳健性检验。Urban and Lambert(2008)对克罗地亚个人所得税收入再分配效应的分解研究发现,随着组距增加,个人所得税的垂直效应会呈现先增加后下降的过程。为此,我们在实证中也进行类似的尝试,对每一年份的个人所得税再分配效应分解时采取不同的组距,由此观察所得到的垂直效应变化情况,具体如图1所示。

图1 不同组距对应的垂直效应
图1结果印证了Urban and Lambert(2008)关于垂直效应会随组距的不同而变化的结论。具体来说,当组距较小时,扩大组距使得每组包含的个体数增加,将会增加更多的组内再排序效应,因此会有产生更大的再排序效应,进而形成更小的垂直效应;但是随着组距的不断增加,一方面组内再分配效应无法持续扩大,另一方面组距增加使得组数变小导致组间的再排序效应下降,因而总体的再排序效应呈现下降结果,这会使得分解出来的垂直效应相应增加。换句话说,组距使得组内和组间再排序效应存在此增彼减关系,最终可以形成一个最小的再排序效应,由税收再分配效应分解公式可知此时的垂直效应最大。
上文当中我们对于各年收入再分配效应的分解是采取了使得每年的垂直效应能够达到最大的组距,因而每年组距取决于各年的收入分布状况,每年最优组距可能是不同的。基于图1结果是否意味着上文核算结果存在瑕疵呢?为此,我们进一步进行稳健性估计。我们尝试选取可以使得各年垂直效应较大的各年相同的组距,结果发现估算结果与上文表3的估算结果并无太大差异。[注]由于与表3没有明显差别,为节省篇幅表格在此省略。对此感兴趣的读者可向作者索取。
考虑到CHNS每年追踪调查的抽样样本会发生变化,基尼系数和税收再分配效应的估计结果变化也可能源于抽样问题,而不单单是税改导致的结果。[注]这一稳健性检验想法源自于匿名审稿人的建议,在此也对审稿人提供这一宝贵的修改建议表示由衷感谢。为此,我们以1997年的抽样家庭作为固定抽样单位,从后续各年当中筛选出一直参与调查的抽样家庭,并对子样本进行估计,由此得到表6的估计结果。对比表2和表6估计结果,可以发现两者数值差异不大,而变动规律大体一致。具体来说,在2005年税改政策之前,税前和税后基尼系数一直在增加,税改政策之后,税前和税后基尼系数一直下降。而再分配效应一直在增加,直至2010年才有所减少,这是唯一一点与表6不一样的地方。
表7同样进行子样本的再分配效应分解结果。与表3对比来看,可以发现税改政策再分配效应的三种效应的影响规律基本一致。具体来说,垂直效应、横向不公平效应和再排序效应在税改政策之前一直呈现递增趋势,2006和2008年税改政策之后,三种效应明显下降,2010年有小幅回升,但没有超过税改政策前的峰值。

表6 固定家庭抽样的子样本再分配效应估计结果
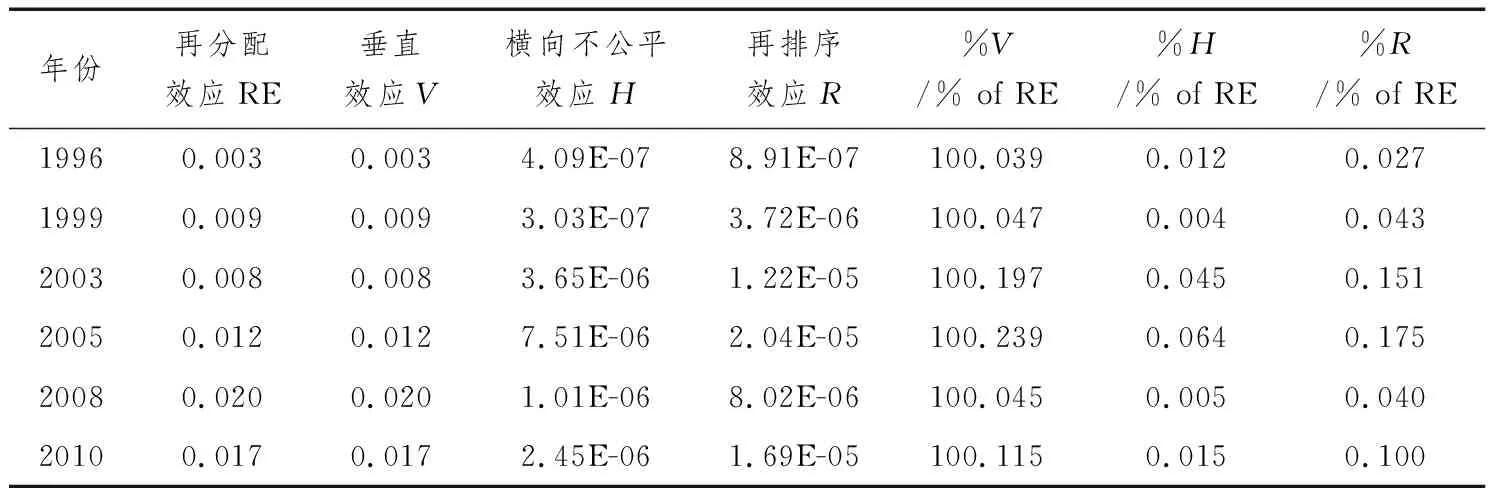
表7 固定家庭抽样的子样本再分配效应分解结果
表8和表9同样进行子样本的再分配效应的税率和税收累进性K指数分解结果。对比表4和表8,可以发现税改对于税率和税收累进性的影响效应也是一致的。具体表现为,平均税率和税收累进性在税改前一直下降;税改之后,2008年税率上升,2010年税率又下调,而税收累进性在这两年则上升。对比表9和表5,也可发现工薪税和经营税的平均税率和税收累进性同样存在着此增彼减的一致变动规律。

表8 固定家庭抽样的子样本再分配效应之税率和税收累进性分解结果
总的来看,固定家庭抽样的稳健性检验结果表明,抽样样本的随机变化只是稍微影响了数值大小,但是不会影响整个税改制度对税收再分配效应及其分解结果的影响结果。本文主要分析结果是稳健的。

表9 固定家庭抽样的子样本工薪税和经营税分解结果
最后,我们对于我国个人所得税的再分配效应进行跨国比较。表10呈现了本文和发达国家的再分配效应、两种效应及三种效应的分解结果。从表10可以明显看出,我国税改前2005年的税收再分配效应跟法国相一致,均为0.015;而税改后2010年的税收再分配效应为0.021,它明显高于法国和瑞士,介于意大利和瑞士之间。其他发达国家的税收再分配效应均显著高于我国2010年的税收再分配效应。从平均有效税率和税收累进性的分解结果来看,不管是税改前还是税改后,我国的平均有效税率明显低于各发达国家,税收累进性则明显高于各发达国家。从三种效应分解所占的比重来看,我国个人所得税的垂直效应、横向不公平效应以及再排序效应的占比均明显低于各发达国家。这说明,我国个人所得税的再分配效应相对于发达国家还有一定差距,这一差距主要体现在平均有效税率较低而税收累进性较高;它导致税收的税收再分配效应较低。但是我国的税收再分配效应最大程度地降低了税收的不公平性问题。一言以蔽之,我国个人所得税侧重于税收公平性的考量,而缩减贫富差距的效应相对发达国家来说还有很大的作为空间。

表10 再分配效应的跨国比较: 中国VS发达国家

续表

我们也把本文估计得到的税前和税后基尼系数和再分配效应跟其他国家进行对比,具体结果如表11所示。从表11可以看出,不管是欧洲各国如英国、德国和意大利,还是诸如南北美洲国家如巴西、哥伦比亚、秘鲁、加拿大以及澳大利亚等国,税前基尼系数均处于0.4~0.6之间,这说明贫富差距悬殊成为各国共同特征,然而由于采取了截然不同的再分配政策,税后基尼系数呈现截然不同特征。其中一类如巴西、哥伦比亚、秘鲁和危地马拉等美洲国,再分配效应有限,这使得税后基尼系数依然处于高位。与此相反,另外一些欧洲和北美洲国家,诸如加拿大、美国、德国和意大利等,它们所实行的税收或收入转移等再分配政策效应明显,这极大地降低了税后基尼系数结果。对比来看,中国2010年前的税前基尼系数跟这些国家相接近,但是税改的再分配效应非常有限,这使得税后的贫富差距问题依然很严峻。表11的结果也表明,税前基尼系数高并不可怕,最重要的是如何通过合法、合理和长效的税收或转移支付手段降低居民可支配收入的贫富差距。

表11 税收再分配效应的跨国比较: 中国VS世界各国

续表
注: 表中的中国数据来自于本文前文估计结果,并四舍五入保留三位小数点。其他数据转引自Wang and Caminada(2011)的表2和表3部分数据。
3.3 城市和农村的税收再分配效应比较
考虑到CHNS可以识别出城市和农村两个子样本,为此我们进一步对城市和农村两个子样本进行税收再分配效应估计,具体估计结果如表12所示。由表12可以看出,农村的税前和税后基尼系数分别高于城市的税前和税后基尼系数,而税收再分配效应的效果在农村明显低于城市。换句话说,农村贫富差距的程度明显高于城市,而个人所得税收对于这种贫富差距的改善效果在农村明显低于城市。而从税改政策前后对比来看,在2006和2008年税改政策之前,农村和城市的税收再分配效应差距很大,后者几乎是前者的两倍;而在2008年税改政策之后,农村和城市的税收再分配效应效果差距在明显缩小。这意味着税改政策明显提高了缩减农村贫富差距的效果。

表12 税收再分配效应: 城市VS农村

续表
注: 括号内为刀切法估计的参数标准误差,参数的估计区间是95%的置信区间。
表13和表14提供了城市和农村税收再分配效应的分解结果。由表13容易得知,城市和农村的垂直效应、横向不公平效应和再排序效应均呈现先升后降再回升的状态,两者共同点在于税改使得2008年的三种效应在城市和农村均呈现明显下降趋势,尽管2010年后有所回升,但具体数值分别低于税改前的峰值。从表14的平均税率和税收累进性K指数来看,城市平均税率呈现倒U型状态,2008年达到最高值,随后下降;而税收累进性K指数则先降后升,税改前达到最低值,税改后税收累进性增加。从农村来看,平均税率一直在增加,税收累进性大体上先降后升,税改前税收累进性达到最低值,税改后有所提高。换句话说,城市和农村的平均税率在税改前后呈现明显不同变化方向,而税收累进性变化是相同的。

表13 税收再分配效应之三种效应分解: 城市VS农村
注: 括号内为刀切法估计的参数标准误差,参数的估计区间是95%的置信区间。%V表示垂直效应占再分配效应的比重,%H表示横向不公平效应占再分配效应的比重,%R表示再排序效应占再分配效应的比重。

表14 税收再分配效应之两种效应分解: 城市VS农村

续表
注: 括号内为刀切法估计的参数标准误差,参数的估计区间是95%的置信区间。
表15则呈现出城市和农村工薪税和经营税的平均税率和税收累进性K指数分解情况。由表15可知,城市和农村的工薪税税收累进性K指数在税改前呈现一直下降趋势,税改之后有所上升,而工薪税平均税率税改前一直在增加,税改后则先降后升。经营税平均税率在城市和农村也同样呈现相同的变动状态,一直上升至2008年达到最高值,2010年后开始下降,而经营税的税收累进性则正好相反,一直下降至2008年,然后2010年上升。对比来看,在税收累进性方面,经营税K指数在农村大体上高于城市,工薪税K指数则是农村大体上低于城市。在平均税率方面,工薪税和经营税平均税率在农村普遍低于城市。
注: 括号内为刀切法估计的参数标准误差,参数的估计区间是95%的置信区间。
最后,表16对比了我国基尼系数估计的不同结果。首先可以看到,国家统计局所提供的2003—2011年基尼系数一直位于0.4~0.5之间,徐建炜等(2013)利用国家统计局的城市住户抽样调查数据得到城镇的税前和税后基尼系数则在0.3~0.4之间,本文基于CHNS的城市样本估计结果则表明,不管是税前还是税后基尼系数均明显大于徐建炜等(2013)的估计结果,而小于国家统计局披露的全国基尼系数结果。与此相反,本文所得到的农村样本基尼系数估计结果明显高于国家统计局披露的全国结果,也明显高于本文的城市样本。另外,从税收再分配效应的估计结果来看,本文所得到的税收再分配效应是徐建炜等(2013)估计结果的1.5倍至2倍。因而,与徐建炜等(2013)的结论所不同的是,我们基于CHNS和刀切法的估计结果表明,2006年和2008年的税制改革确实有缩减贫富差距的效果。但是,相对于发达国家来说,我国税制改革缩减贫富差距的效应还有很大作为空间。

表16 我国基尼系数不同结果对比
注: 为与国家统计局公布的基尼系数做对比,对基尼系数的估计结果均四舍五入保留三位小数点。
4 结论
众所周知,在个税税制保持不变而居民收入快速增长时期,一部分人会从低税率层级向高税率层级递进。此时税制会产生 “双刃剑”效应:一方面税收累进性可能由于不同税收收入层级的变化而下降,另一方面平均税率会上升。税收累进性和平均税率的权衡取舍,最终目的是为了缩减不同收入人群的贫富差距,但是却容易产生相似收入人群因为不同税收或税率而产生纵向不公平、横向不公平或者再排序效应等税收公平性问题。缩减贫富差距和税收公平性的权衡取舍由此成为税制改革亟须着重考量的重要问题。我国在1996—2010年间所实施两次税改政策效果如何,是否能够起到缩减贫富差距并且兼顾公平目的?本文基于CHNS的1997—2011年的微观社会调查数据,运用刀切法实证评估了我国1996—2010年间的个人所得税税收再分配效应。评估结果发现,我国1996—2010年的税前基尼系数处于收入差距过大甚至是收入悬殊区间,而2006年和2008年两次税改政策主要通过提高税率和税收累进性方式提高了税收再分配效应。两次税改对于工薪税和经营税直接体现了平均税率和税收累进性的权衡取舍问题。具体来说,工薪税的税收累进性是先升后降,平均税率先降后升;而经营税的税收累进性是先降后升,平均税率先升后降。从税收公平性来看,税改政策提高税收垂直效应数值的同时,也降低了税收的横向不公平效应和再排序效应。固定家庭抽样的子样本分析结果表明,总样本分析所得到的主要结论具有稳健性特征。而与世界各国的税收再分配效应对比分析结果则发现,我国税收体制带来的再排序效应和横向不公平效应最低,税收体制最大限度地兼顾了公平性问题,但是由于税收的平均税率较低,税收累进性较高,导致我国税收再分配效应缩减贫富差距的功能较弱,税改政策还依然存在很大的作为空间。
我们也进一步细分了我国城市和农村的税收再分配效应差异。评估结果发现,农村税前和税后基尼系数明显高于农村,而税收再分配效应在农村明显低于城市,两次税改政策则缩减了这一再分配效应的差距。城市和农村的平均税率在税改前后呈现明显不同的变化方向,而税改则同样提高了城市和农村的税收累进性。在工薪税和经营税方面,经营税的税收累进性在农村大体上高于城市,工薪税税收累进性则是农村大体上低于城市;与此相反工薪税和经营税的平均税率在农村普遍低于城市。税改对于农村和城市工薪税和经营税的变动影响与总样本的变动影响具有相类似特征。从税收公平性来看,税改同样降低了农村和城市的再排序效应和横向不公平效应,提高了税收的垂直效应。总的来看,两次税改确实可以起到缓解城市和农村的贫富悬殊问题,但是其再分配效果还有很大的作为空间。
由于我国当前的税收征管主要是以单位代扣代缴的源泉扣缴为主、纳税人的自行申报为辅,现有个人所得税征管方式和已有调查数据结构使我们很难针对性地分析纳税人对于个人所得税免征额调整而产生群聚(bunching)问题(Kleven,2016)。所谓群聚问题,通俗来讲,就是由于政府调整个人所得税免征额,导致相当一部分纳税人将自己的应纳税所得控制在某一个或某几个边际税率对应收入上限的下方,以减少由于收入的微小增长带来的边际税负的跳跃性上升[注]这一建设性意见来源于本文匿名审稿人的修改意见,本文作者对审稿人提供这一个富有重要创新意义和启迪价值的修改意见及其文献来源由衷表示感谢。。正如匿名审稿人指出来的,如果存在群聚(bunching)问题,势必会作用于个人所得税免征额调整对于收入差距的真实影响。我们认可这一看法,但是受限于已有技术、能力和条件,对于在实证评估中如何构建反事实分布进行平滑并识别潜在的群聚问题表示束手无策。不过,我们认为,对于企业所得税来说,企业或单位作为纳税主体有进行避税和盈余管理的动机和激励,群聚问题会非常重要。但是对于我国个人所得税来说,单位或组织为个人进行避税的动机和激励较弱,群聚问题的产生主体很难发生于源泉扣缴的单位或组织,更有可能发生于具有自行申报资格的纳税人身上。而对于那些具有自行申报资格的纳税人来说,在我国当前个人所得累进纳税的制度框架下,想要合法而不违法地控制自己应纳税所得实际上也意味着让自己税后可支配收入减少,这会减少这类人采取这类行为的具体激励,或者说增加了这一行为的操作成本。实际上,我们很难通过已有微观社会调查数据甄别出什么样的被试属于这类控制应纳税所得或者可能隐匿或隐瞒某类收入的纳税人,这一识别工作即便是税务机关也无能为力。
然而,毋庸置疑的是,群聚问题确实会使得我们可能低估现实贫富差距的悬殊水平和税收再分配效应。这对于个税制度改革提出了更高程度的要求。在我们忽视了群聚问题依然得到居高难下的税前基尼系数条件下,如何发挥个人所得税缩减社会贫富差距的重要功能,这成为后续个税改革无法回避的重要问题。我们认为,现阶段我国的个税改革新举措,应该坚持以缩减贫富差距为主,兼顾税收公平性为辅,加大对高收入者的调节作用,降低中等收入者的生活负担,扶助低收入甚至负收入者,与此同时,强化农村税收再分配功能。另外,新个税改革不能老是停留在平均税率和税收累进性此增彼减的权衡取舍问题上,而应该大刀阔斧地改变现行的分类计征个人所得税的税制结构,借鉴和推行发达国家的综合所得个税制度。此外,新个税改革方案可以考虑增加税前抵扣项目,诸如赡养老人、重大疾病医疗支出、子女教育、租房房租和购房按揭贷款利息等家庭支出可考虑列为税前抵扣项目,以兼顾税收公平性原则适当改变中低收入人群的收入排序。最后,新个税改革方案可以逐步试点、推进和完善个人纳税信用和自主申报制度,通过纳税信用积分和配套激励制度引导我国公民的纳税信用意识,强化我国公民纳税义务,减少自行申报纳税人控制应纳税所得的激励,增加自行申报纳税人隐匿或者瞒报收入的违法成本,进一步完善我国个税的申报、监督和征税制度。
