个体学习与新体验品的动态定价: 连续统消费者的情形
2018-11-05翁翕尹训东许敏波
翁翕 尹训东 许敏波
0 引言
很多提供新产品和新服务的企业采取的定价策略是初始时以低价格或者变相的价格优惠来吸引消费者,这种低价格通常会在持续一段时间以后最终转向一个高价格。比如最近广受关注的滴滴打车价格问题,滴滴公司在起步阶段,为了吸引私家车、出租车和消费者使用自己的打车软件,通过对私家车和出租车的大量补贴来吸引消费者,消费者在低价格的吸引下尝试使用该软件,这种低价格会持续一段时间让更多的消费者获得消费体验。现在滴滴公司逐步放弃了这种优惠补贴,相当于取消低价格转而实行高价格*以北京为例,2015年6月滴滴顺风车上线时,收费标准为起步10元,每公里1元。2015年9月,北京地区顺风车起步10元,每公里1.3元。2016年8月底,起步费调整为3公里之内12元,之后每公里1.5元。。
本文建立了一个有连续统消费者的新体验产品的垄断动态定价模型来研究新产品的最优定价策略。我们的分析表明上述先低价后高价的定价策略符合最优动态定价模型的预测,同时我们也证明了,相较于社会福利最优的定价策略,这种垄断者追求利润最大化的均衡定价所实行的低价格时间过短,过早地实行高价格会造成社会福利损失。除了滴滴公司的例子,还有很多提供新服务和新产品的厂商也采取了类似的价格策略,最初利用低价吸引消费者,一段时间后再提高价格。比如团购刚兴起时团购网站的价格优惠,小区内新建的超市和理发店等等。虽然有些企业并不是严格意义上的垄断企业,但他们都在一定程度上有拥有市场的力量。我们构建的垄断动态定价的理论框架,有助于帮助理解这些企业的定价模式,并对政府选择合适的产业政策以促进社会福利提供理论依据。
本文关注的是新体验品,也即消费者和垄断厂商都不知道该产品能给消费者带来多大效用,每个消费者需要通过体验后才能发现自己是否和新产品匹配。在每个时间点,消费者都可以选择是体验新产品还是无风险产品(或常规产品)。消费者体验新产品后所获取的收益(或效用)有不确定性,获取了正收益的消费者知道该新产品是值得再次消费的,其选择再次消费的意愿将提高。而初始体验没有获取正收益的消费者会更新自己对于新产品的信念,更可能认为该新产品和自己不匹配,因此再次消费的意愿将降低。我们假设该垄断厂商不能观测到每个消费者的体验结果因而无法实行价格歧视,为了继续吸引第一次体验未得到正收益的消费者,厂商将进一步压低价格(因为体验失败的消费者的体验意愿降低)。此时第一次体验成功的消费者将从该低价格中获取较高的收益。这种动态定价模式将持续一段时间,即垄断者的定价将不断降低。随着越来越多的消费者体验成功,对于厂商而言,不断降低价格的好处越来越少,而其代价越来越高(越来越多体验成功的消费者享受低的体验价格),我们证明存在一个临界点,使得垄断者选择放弃掉体验失败的消费者,转而对所有体验成功的消费者收取一个高的垄断价格。
如上所述,垄断厂商的均衡动态定价是从一个低价格开始,并在此之后的一段时间内不断降低该价格,当达到一个临界点之后,突然提高价格,该高价格只有体验成功的消费者才会支付,一直体验不成功的消费者将被逐出市场。这就是垄断厂商的最优动态定价模式。如果从社会福利最大化的角度考虑,则存在社会最优效率的定价模式。两者相比较,我们发现垄断厂商会过早地停止低价格,从而转向一个高价格而放弃掉体验失败的消费者,这会造成社会福利的损失。因而从政府规制的角度看,为了达到社会最优,应该对垄断厂商起初的低价格进行补贴,以延长低价格吸引消费者的时间从而提高社会福利。当垄断者提高价格后,政府可以对垄断高价进行征税,既可以纠正垄断造成的无谓损失,同时又可以支付前期的补贴,精心设计的税制和补贴在某种程度上可以达到总预算平衡。
本文理论上的贡献在于弥补了文献中对于消费者数量是连续统时,垄断者对新产品的动态均衡定价过程的研究。我们发现当消费者数量是连续统时,均衡的停止低价格的临界值取决于消费者对新产品是否适合自己的先验概率。这与当消费者数量是有限个时的结论(比如Bergemann and Välimäki, 1996, 2000;Weng, 2015a)迥然不同,那里均衡的停止低价格的临界值不取决于消费者对新产品是否和自己匹配的先验概率。我们在解出了均衡的动态定价之后,还对停止低价格时信念的临界值作了比较静态分析,其中需要特别指出的是,消费者对新产品与自己匹配的先验概率越高,垄断者收取的价格越高,但同时该先验概率越高,垄断者实行低价格的信念临界值越高,从而相较于社会最优解来说,所损失的效率就越大。因此,消费者认为新产品符合自己需求的概率越大,由于垄断者过早地结束低价格所带来的社会效率损失就越大。
本文除了在理论上解决了消费者数量是连续统情况下垄断者对新产品的均衡定价问题,同时也能帮助我们更深入地理解当今经济中越来越多的新产品的定价行为,并对由此造成的潜在社会损失作出分析,从而为政府规制垄断厂商新产品的动态定价提出政策建议。随着经济中创新和创业的不断发展,会源源不断地涌现出新的产品和服务形式(比如最近兴起的共享单车),这些新产品和新服务必定在最开始的时候拥有相当大的垄断势力,在人们享受初始很低的体验价格时,人们也要预计到在不远的将来垄断者将会实行的垄断高价。本文的分析有助于理解决定这种低体验价格的因素,并给出了低价格的动态演化方程,以及低价格运行的时间,并证明了这种动态均衡定价所蕴含的社会损失以及政府规制改善垄断均衡定价的空间。
本文的结构如下,第1部分梳理相关理论的文献,第2部分是模型设定和求解,第3部分是对均衡的分析,包括对均衡临界信念值的比较静态分析,最后一部分是结论。
1 文献综述
新体验品的动态定价问题是产业经济学中重要前沿研究领域之一。该种商品与普通产品的不同之处在于买家需要通过自己的不断体验才能确知产品的价值,而体验的结果又是不确定的,导致卖家需要随着买家的体验结果动态调整价格。文献中对新体验品的动态定价问题研究起始于Bergemann and Välimäki对寡头市场中体验品动态定价的一系列研究(Bergemann and Välimäki, 1996, 2000)。这类模型一般假设虽然消费者不确切知道新体验品带来的效用,但期望效用满足共同价值(common value)假设,也即所有消费者的期望效用是相同的。消费者在共同价值假设下可以进行社会学习(social learning),也就是从其他人的体验中获取新体验品的信息。研究发现,学习速度快的企业相比于学习速度慢的企业能获得额外的竞争性优势,因此最后的均衡没有实现社会最优效率,而且相比于社会最优,均衡时消费者会更多地体验学习速度快的产品(Eeckhout and Weng, 2015)。
本文与上述模型假设最大的不同之处在于摒弃共同价值假设,每个消费者从商品中获得的价值都是不同的,因而消费者只能通过个体学习来获取新体验品的信息。在相关文献中,Bergemann and Välimäki (2006)以及Weng (2015a)都研究了个体学习下最优的垄断者动态定价问题。Bergemann and Välimäki (2006)研究的也是一个连续统消费者问题,但消费者的学习过程被大大简化:消费者体验之后要么完全认知到体验品的价值,要么还是一无所知。最后作者发现在不同参数条件下,可能会出现niche market,即最后均衡价格会转向一个高价格;或者会出现mass market,即最后均衡价格会一直下降。本文采用了文献中常用的指数学习模型(exponential bandit),并发现最后的动态定价均衡总是Bergemann and Välimäki (2006)中的niche market。但我们更关注分析在这样的市场中,均衡价格何时会转向一个高价格,以及对社会福利的影响。
Weng (2015a)考虑的则是在指数学习模型下有限多个消费者时的最优动态定价问题。传统理论认为社会学习时的动态决策是无效的,而个体学习时的动态决策是有效的。因为在社会学习的情形下,消费者有搭便车的动机,他们总是希望别人付出成本去体验新产品,而自己可以坐享其成。Weng (2015a)的理论贡献在于发现,如果加入卖家的动态策略定价的话,上面的结果正好反转。在社会学习的情形下,卖家的定价可以攫取所有的经济租,从而使得消费者没有动机搭便车。在个体学习的情形下,消费者之间存在一种新的搭便车行为:买家可以通过短期背离获取更有利的信念,因而获得正的经济租。因此,个体学习时的动态定价反而变为无效的。本文把Weng (2015a)一文的分析扩展到连续统消费者的情形,对均衡价格的推导沿用了Weng (2015a)一文中“一次性背离”的思想,这里发现均衡结果依然是无效的,但两文中的模型存在如下三点显著差异:首先,Weng (2015a)的分析主要是基于两个消费者的情形,随着消费者人数上升均衡的刻画会变得非常复杂,而本文利用连续统消费者的设定很好地解决了有限消费者模型难以推广到更多消费者情形的问题。其次,本文利用连续统消费者情形下的精确大数定律(Sun, 2006),只需假设厂商能观测到过去各个时间点购买了体验产品的消费者总测度。与文献中(比如Bergemann and Välimäki, 1996, 2000;Weng, 2015a)通常假设所有的历史信息都是公开可观测的相比,本文的假设条件更弱,也更加自然。最后,也是最重要的,Weng (2015a)一文中的均衡临界信念取决于已有多少消费者获得了好的体验,但与初始信念无关;而本文中的均衡临界信念与已有多少消费者获得了好的体验无关,但与初始信念有关。因此,本文关注的焦点问题是初始信念是如何影响均衡临界信念的,而这个问题无法在Weng (2015a)一文中探讨。
在建模思路上,本文采用的是文献中常用的指数学习模型。该模型自从被Keller等 (2005)提出之后,被广泛应用于刻画动态学习和创新过程(Bergemann and Hege, 2005; Bonatti and Hörner, 2011; Manso, 2011; Hörner and Samuelson, 2013; Weng, 2015b; Guo, 2016; Halac et al., 2016, 2017; 龚六堂等,2016)。但上述提到的模型都只考虑了有限数量的参与人,而本文把指数学习模型扩展到连续统消费者的情形,启发未来的研究同样可以考虑类似的扩展。
2 模型设定
考虑一个连续时间模型,t∈[0,+∞),贴现率为r>0。垄断厂商在市场上出售一个全新的风险产品,消费者的数量是个连续统,记为i∈[0,1]。假设垄断厂商和所有的消费者都是风险中性。该风险产品的生产成本标准化为零。[注]零成本假设是为了简化分析采取的标准化处理。假设生产成本c>0与假设生产成本为零而无风险产品的流量回报为s′=s+c是等价的。在每个时间点上,每个消费者可以选择从垄断厂商那里购买一个单位的风险产品或者从外部购买一个单位的无风险产品。
如果消费者购买无风险产品,她将得到一个确定的流量回报s>0。[注]同时,也可以假设流量回报是随机变量,服从一个已知的分布,期望为s>0。而风险产品带来的回报是一个随机的一次性的总额收益(lump-sum payoff)ξ>0。该回报ξ取决于风险产品和特定消费者i∈[0,1]之间的匹配质量: 匹配(κi=1)或者不匹配(κi=0)。任意两组消费者和风险产品之间的匹配质量是相互独立的。每个消费者i匹配质量的先验概率ρ0=Pr(κi=1)都相同。根据Sun (2006)的精确大数定律,ρ0可以近似地表示为匹配的消费者占全体消费者的比例。[注]Duffie and Sun (2012)提供了一个关于连续统参与者的模型的严格分析。
消费者通过个体学习的方式,即用自己的亲身体验来判断该新产品是否适合自己,也即是否满足κi=1。本文采用文献中常用的指数学习模型(exponential bandit):如果消费者最初购买了风险产品,随机的一次性总额收益ξ在消费者之间服从独立的泊松分布。该分布对于消费者i的到达率为λκi,其中参数λ>0。如果产品与消费者匹配,消费者有可能获得一次性收益;否则无法获得一次性收益。当消费者从风险产品获取一次性收益后,对自己与产品匹配的事后信念立即更新为1。令g=λξ,并且假设g>s,即如果消费者获得了一次性收益,那么风险产品将占优于无风险产品。所有的参与者(垄断厂商和消费者)在初始时都无法观察到产品的特征和匹配质量,但参数λ、ξ和ρ0是已知的。假设每个消费者的历史行为和结果都只有自己知道,而不能被其他参与者观测到。这样,厂商在每个时点上就只能观测到购买了风险产品的消费者总测度。与文献中(比如Bergemann and Välimäki, 1996, 2000;Weng, 2015a)通常假设所有的历史信息都是公开可观测的相比,本文的假设条件更弱,也更加自然。
在每个时间点t上,垄断厂商首先基于以往的历史宣布一个现价,然后每个消费者根据以往的历史和该宣布的价格来决定购买何种产品。假设垄断厂商既不能实行价格歧视,也不能承诺一个定价规则。
2.1 信念更新
如果消费者从风险产品中获取了一次性总额收益,那么她立即就会知道她与风险产品是匹配的。没有获取到一次性收益表明很可能是完全不匹配的。用ρi t来表示消费者i关于匹配质量的事后信念。给定先验概率ρ0,可以根据贝叶斯法则得到后验概率ρi t。Keller等(2005)与Weng(2015a)证明,如果没有获得一次性收益,ρi t将遵循如下微分方程:
(1)
在接下来的分析中,我们把获得一次性收益的消费者叫做“体验成功”消费者,没有获得回报的消费者称为“体验失败”消费者。
2.2 策略和均衡
令Ni t表示消费者i在时间t之前获得的一次性总额收益的总次数。令Pt表示垄断厂商在时间t收取的价格,mt表示在时间t选择购买风险品的消费者数量测度。如果消费者i在时间t购买风险产品,记为ai t=1;如果消费者i在时间t购买无风险产品,记为ai t=0。在我们的模型中,每个消费者i观测到的历史记为:
hi t≜(aiτ,Niτ,Pτ)0≤τ 垄断厂商观测到的历史为:hs t≜(mτ,Pτ)0≤τ 在时间t,垄断者的定价策略是从历史hs t到价格Pt的一个映射,而每个消费者的购买决策是从她的历史hi t和价格Pt到ai t的一个映射。和Weng(2015a)一样,我们假设在没有一次性收益时的购买决策ai t与定价决策Pt都是关于时间的右连续函数,Weng(2015a)对该假设有详细说明。在本文中,我们集中讨论对称均衡的情况,即在每个时间点,拥有相同后验概率的消费者会做出相同的购买决策。考虑在任何合理的均衡中,垄断者起初向所有消费者(包括体验成功和体验失败的消费者)出售产品,而最终只能向体验成功的消费者出售。对于这样一个动态博弈过程,我们考虑马尔科夫完美均衡(markov perfect equilibrium),即均衡定价策略只由最近的状态变量决定。这里的状态变量是后验概率ρ,研究的重点是刻画均衡定价策略P(ρ)的涵义和特征。 (2) 在每个时间点t,垄断者需要选择是同时向体验成功和体验失败的消费者都出售产品还是只向体验成功的消费者出售。如果垄断者总是只向体验成功的消费者出售,他可以收取价格g-s来攫取体验成功消费者的所有消费者剩余,此时接受这个价格的体验成功消费者的测度为γt。因此,垄断者的收益(标准化后的期望贴现利润之和)是: (3) (4) rJ(ρ)=rP(ρ)-λρ(1-ρ)J′(ρ) (5) 同样地,体验成功消费者的收益(标准化的期望贴现效用总和)满足: (6) 从而可以推导出如下方程: rV(ρ)=r(g-P(ρ))-λρ(1-ρ)V′(ρ) (7) 最后,体验失败消费者的收益可以表示为: rU(ρ)=r(gρ-P(ρ))+λρ(V(ρ)-U(ρ))-λρ(1-ρ)U′(ρ) (8) 与式(7)相比较,式(8)增加一项λρ(V(ρ)-U(ρ)),该项表示匹配时一次性收益以速率λ出现,此时后续收益跳到V(ρ)。要求解上述微分方程,需要P(ρ)的显性表达式,我们将在下部分进行求解。 垄断厂商实质上面临的是一个双臂赌博机(two-armed bandit)问题: 是选择对所有消费者出售产品还是只对体验成功的消费者出售。当信念比较高时垄断者会向所有消费者出售产品,直至达到某个时间转而只对体验成功者出售。当垄断者向所有消费者都出售产品时,下面的引理给出了均衡价格P(ρ)。 引理1如果垄断者向所有消费者都出售产品,均衡价格P(ρ)将会是gρ-s。 证明: 见附录。 在一个单期的静态模型中,价格P(ρ)等于gρ-s的结果非常符合直觉:该价格意味着体验失败的消费者即期在购买和不购买之间无差异。但在动态模型中,消费者购买风险产品实际上是在购买一个期权:未来在获取了一次性收益时会继续购买,而如果迟迟未获取的话,会停止购买。因此当P(ρ)等于gρ-s时,由式(8)可知:尽管体验失败者在即期无差异,均衡收益U(ρ)却会严格大于s,因为有可能获得一个一次性收益从而获取一个高值的V(ρ)。也就是说,即便垄断者将价格P(ρ)定在略高于gρ-s的水平,体验失败者从购买风险产品中获取的收益依然要大于s,但为什么垄断者不再索取更高的价格呢? (9) 有趣的是,为了防止消费者的背离,垄断者索取的均衡价格恰恰使得体验失败的消费者即期在购买和不购买之间无差异。为了理解该结果的直觉,我们可以考虑一个离散时间模型。如果垄断者在t期向所有消费者都出售产品,“一次性偏离原理”意味着其均衡价格应当使得体验失败的消费者在下述两个选择之间无差异:①t期购买风险产品以及从t+1期起维持均衡策略;②t期不购买风险产品以及从t+1期起维持均衡策略。上述两个选择从t+1期起给消费者带来的期望收益是完全一样的。首先,在连续统消费者模型中,单个消费者购买或不购买风险产品完全不影响未来价格;其次,t期不购买的消费者比t期体验失败的消费者更乐观,因此如果t期体验失败的消费者在均衡时愿意继续购买风险产品,t期不购买的消费者的均衡策略也一定是继续购买;最后,因为在贝叶斯法则之下信念更新满足鞅(martingale)性质,消费者在t期是否购买风险产品也不影响未来购买风险产品的期望消费收益。因此t期的均衡价格只需使得体验失败的消费者即期在购买和不购买之间无差异。 垄断者求解其双臂赌博机问题的关键是比较只对体验成功者出售所获得收益和向所有消费者出售产品所获得收益。如式(3)所表明的,垄断者只对体验成功者出售将获得收益S(ρ)=γ(ρ)(g-s)。式(5)和引理1意味着垄断者向所有消费者出售产品获取收益J(ρ)满足:rJ(ρ)=r(gρ-s)-λρ(1-ρ)J′(ρ)。 最优停止文献(例如Dixit,1994;Peskir and Shiryaev,2006)中的经典结论表明,如果垄断者在后验信念x下最优的选择是停止向体验失败者出售产品,那么停止的临界值x应该满足值函数的匹配和平滑条件: J(x)=S(x),J′(x)=S′(x) 因此,我们得到如下定理: 定理1对任意ρ0满足ρ0[rg+λ(g-s)]>rs,存在一个对称的均衡,当ρ>x*时垄断者制定价格gρ-s。当ρ趋向于x*时价格为g-s。均衡的临界值x*<ρ0是下述方程的唯一解: rgx2-[2rg+λ(1-ρ0)(g-s)]x+rs+rρ0(g-s)=0 (10) 证明: 见附录。 这里条件ρ0[rg+λ(g-s)]>rs有一个直观的经济学解释。设想一个消费者在极短的时间内以零价格购买了风险产品,那么期望流量收益是ρ0[rg+λ(g-s)],其中λρ0(g-s)表示将来有可能获取一次性收益的期望收益。如果消费者选择无风险产品,那么流量收益就是rs。条件ρ0[rg+λ(g-s)]>rs说明选择风险产品会带来租金,因此垄断者可以从出售风险产品中获取正期望利润。 图1 价格路径示意图 基于定理1我们可以画出典型的价格路径(见图1),垄断者起初会保持递减的价格来促使体验失败消费者尝试购买,但最终会转向一个很高的价格只向体验成功的消费者出售产品。这里需要注意,在产品尝试阶段均衡价格可能是负的:垄断者短期内可能损失一些钱来吸引体验失败者进行再次体验。 定理2对任意的ρ0满足ρ0[rg+λ(g-s)]>rs时,一定有x*>xe。 证明: 见附录。 上述定理表明垄断者这种先低价再高价的动态定价均衡并不是社会最优的。通过比较,我们发现垄断厂商过早地停止低价格,从而转向一个高价格而放弃掉体验失败的消费者,这会造成社会福利的无谓损失。造成这个结果的原因也跟Weng(2015a)中均衡无效率的原因是类似的:体验成功的消费者愿意为风险产品支付更高的价格,而厂商又无法进行价格歧视,这种诱惑导致厂商愿意更早放弃掉体验失败的消费者。与本文不同的是,Weng (2015a)要求厂商能完全观测到消费者的过往体验历史以判断是否需要转向高价格。而本文模型中,即便厂商无法观测到消费者过往体验历史,在连续统消费者的情形下仍然可以应用大数定理推算出体验成功的消费者测度。 基于方程(10),我们可以推出几个比较静态的分析结果。下面的定理描述了均衡临界值x*与模型中有关参数的关系。 定理3均衡临界值x*受先验概率ρ0、到达速率λ、风险产品的期望价值g、无风险产品的价值s以及贴现率r的影响。具体而言,x*是ρ0、s、r的增函数,是λ、g的减函数。 证明: 见附录。 对于λ,g,s和r的比较静态结果的分析应该比较容易理解,因为它们的符号与xe对λ、g、s和r的比较静态结果相同,并且其经济学直觉也类似。当λ变高或者r变低时,购买风险品变得相对便宜,因此垄断者会更多地鼓励消费者体验。当g变高或者s变低时,体验购买风险品的收益提高或者成本降低,从而垄断者也更加鼓励体验。 图2 均衡临界信念x*与初始信念ρ0关系示意图 接下来,我们研究体验性购买时间的长度如何受ρ0的影响。注意到垄断者从先验概率ρ0开始进行体验性销售一直到后验概率达到x*。因此,体验性购买时间的长度满足: 从而得到: (11) 定理3表明x*是ρ0的增函数,从而t*可能是ρ0的非单调函数。不过,下边的定理证明t*是ρ0的增函数,见图3所示。 图3 均衡临体验性购买时间长度t*与初始信念ρ0关系示意图 定理4均衡的体验性购买时间长度t*是ρ0的增函数。 证明: 见附录。 虽然上述定理证明均衡的体验性购买时间长度是初始信念的增函数,但是该结果并不意味着初始信念上升会使均衡变得更加有效。因为初始信念上升同时也意味着社会最优的体验性购买时间长度也应该上升。特别地,我们可以用κ表示均衡的体验性购买时间长度与社会最优的体验性购买时间长度之间的距离:κ=te-t*,te可以类似于(11)式得到: 本文理论上的贡献在于弥补了文献中关于垄断者对新体验产品的动态定价研究的不足。我们考虑了当消费者数量是连续统时,垄断厂商的定价如何随着消费者对新产品信念的变化而变化。当体验失败的消费者对新产品是否匹配的后验概率越来越低时,垄断者为了向这些体验失败者出售产品,必须不断降低价格来诱导这些人消费。随着低体验价格时间的延长,垄断者实行低价格的代价越来越大,直到消费者对产品匹配的后验概率达到临界值后,垄断者转向垄断性的高价格,此时体验失败者完全被垄断者排除在市场之外,只对体验成功的消费者出售产品。本文的结论与消费者数量有限时的结论有所不同,在本文中消费者对新产品匹配的初始信念越高,垄断者停止低价格的信念临界值越高。而当消费者数量为有限时,垄断者停止低价格的临界值与消费者的初始信念无关。 我们对信念的临界值作了比较静态分析。值得注意的是,消费者对新产品匹配程度的先验概率越高,垄断者获取的利润越大。但同时,该先验概率越高,垄断者就会在越高的后验概率临界值处停止低价格,这会带来更大的社会损失。 本文不仅在理论上有新的贡献,而且对于现实经济政策的分析也能提供重要指导。在当前经济进一步市场化,政府大力鼓励创新和创业的背景下,新产品和新服务不断涌现,本文的研究对新产品的垄断动态定价给出了理论分析和相应的政策建议。我们的研究表明,政府对垄断厂商的规制不仅限于对传统意义上垄断性的高价格的限制,对其新产品实行低价格吸引客户的时间也可以进行规制来提高社会效率,对垄断厂商实行的体验性低价格应该进行鼓励或者补贴以延长该价格的时间,让更多的消费者有机会体验新产品以提高消费者对新产品的认同来提高社会效率。随着移动互联网的深入发展,越来越多的公司基于移动互联网进行创新和创业。滴滴打车、共享单车等创新服务模式深刻地改变了原有的商业版图,初创公司在起步时大量引入投资以支持低廉的用户体验价格,在很短的时间内大量地吸引消费者进行尝试,迅速占领市场;低价格一段时间后,提高价格来获取更高的利润回报初期投资者。这对厂商而言无可厚非,但过早地结束低价格会带来社会损失。政府在这种新产品的低价格期间可以进行补贴来延长体验期,等厂商转向高价格后,可以反过来对企业征税。这种产业政策的机制设计可以从社会福利最大化的角度给予企业正确的激励来向社会最优的配置结果靠拢。 附录 引理1的证明: 证明: 垄断者面临的问题是选择对所有消费者出售产品还是只对体验成功的消费者出售。假定垄断者选择以Pt的价格向所有消费者出售产品直至时刻T,并且假定一个信念为ρ的体验失败消费者一直购买风险产品直至时刻T,那么该消费者得到的期望收益为: U(ρ)= 为了向所有的消费者出售产品,垄断者所制定的价格P(ρ)必须阻止“一次性偏离”。通过偏离均衡策略而选择h时长的无风险产品,一个信念为ρ的体验失败消费者可以获取收益: 上式成立的一个重要前提是偏离者比非偏离者更加乐观。所以给定非偏离者愿意一直购买风险产品直至时刻T,偏离者也愿意采取相同的行动。在连续统消费者模型中,单个消费者购买或不购买风险产品完全不影响未来价格。也即上述两式中Pt和T完全相同。同时在贝叶斯法则之下,信念更新满足鞅性质:因此垄断者的定价必须满足也即当垄断者向所有的消费者出售产品时,该不等式对于任何ρ和充分小的h都成立,因而可得: 在均衡时,垄断者希望选择尽可能高的价格以最大化其利润。因此均衡价格满足P(ρ)=ρg-s。 证毕。 定理1的证明: 证明: 把边界条件代入值函数得到: rγ(x)(g-s)=r(gx-s)-λx(1-x)γ′(x)(g-s) 令f(x)=rgx2-[2rg+λ(1-ρ0)(g-s)]x+rs+rρ0(g-s) f(0)=rs+rρ0(g-s)>0 因此,当且仅当f(ρ0)<0时,f(x)=0有一个根x<ρ0,这等价于 ρ0[rg+λ(g-s)]>rs 证毕。 定理2的证明: 证明: 关键是证明f(xe)>0,其中 f(x)=rgx2-[2rg+λ(1-ρ0)(g-s)]x+rs+rρ0(g-s) 简化后可以得到f(xe)>0等价于-rgxe(1-xe)+λρ0(g-s)xe+rρ0(g-s)>0。 成立。 显然,rρ0(g-s)-rxe(g-s)>0 由假设ρ0[rg+λ(g-s)]>rs我们可以得到xe<ρ0,并且 因此,我们一定有f(xe)>0,从而x*>xe。 证毕。 定理3的证明: 证明: 令f=rgx2-[2rg+λ(1-ρ0)(g-s)]x+rs+rρ0(g-s) 对此进行全微分可以得到: 证毕。 定理4的证明: 因此上述方程变为:3 均衡分析





3.1 均衡价格


3.2 均衡下何时停止向体验失败消费者出售

3.3 与效率临界值的比较

3.4 比较静态分析
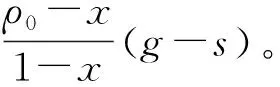




4 结论




