基于Spark优化的协同过滤推荐算法研究
2018-10-31张嘉新赵建平蒋振刚
张嘉新,赵建平,蒋振刚
(长春理工大学 计算机科学技术学院,长春 130022)
随着信息技术和互联网的发展,人们逐渐从信息匮乏的时代走入了信息过载的时代。在这个时代,无论是信息消费者还是信息生产者都遇到了很大的挑战,作为信息消费者,如何从大量信息中找到自己感兴趣的信息是一件非常困难的事情,作为信息生产者,如何让自己生产的信息脱颖而出,受到广大用户的关注,也是一件非常困难的事情。推荐系统就是解决这一矛盾的重要工具。推荐系统的任务就是联系用户和信息,一方面帮助用户发现对自己有价值的信息,另一方面让信息能够展现在对它感兴趣的用户面前,从而实现信息消费者和信息产生者的双赢。推荐算法能够将可能受喜好的资讯或实物(例如:电影、电视节目、音乐、书籍、新闻、图片、网页)推荐给使用者。推荐算法中,协同过滤算法是目前使用最多的一种算法。“协同过滤”最初的应用是于 1992 年由Goldberg、Nicols、Oki及Terry提出[1],应用于Xerox公司在Paloma Alto研究中心资讯过载的问题,最初的推荐系统Tapestry只是处理公司内部邮件,数据量较少。随着互联网的飞速发展,一些电商一天的数据量超过50TB,其中有4亿条产品信息和2亿多名用户的活动信息,这无疑给推荐算法与大数据处理带来了挑战,基于模型ALS(Alternating Least Squares)协同过滤算法提供了良好的降维方法,而最新一代的大数据处理引擎Spark非常适合处理ALS的复杂迭代计算,以逐渐取代Hadoop大数据计算平台[2-6]。Spark虽然计算速度快,但在数据量过大时,其效率很难达到满意程度,本文基于Spark底层运行机制与ALS算法特点对Spark作业进行资源优化与Shuffle优化,通过合理分配资源与合并Shuffle过程产生的文件,达到降低内存存储压力与减少磁盘I/O的目的,从减少了推荐时间提升了推荐效率。
1 ALS推荐算法
基于隐语义模型[7]的推荐算法所研究的核心问题就是如何将数据抽象出的高维矩阵进行矩阵分解的问题,它本质上是对用户与商品的关系矩阵进行降维。本文针对基于ALS模型的推荐算法进行优化研究。
ALS,译为交替最小二乘法。将User-Item-Rating(用户-商品-评分)的数据集建立一个User×Item(用户-商品)的m×n矩阵,由于不是每个用户都对每个商品进行过评分,所以这个m×n的矩阵往往是稀疏的,因此ALS的核心就是将用户对商品的评分矩阵分解为2个低秩矩阵,分别是用户对商品隐含特征的偏好矩阵,和商品所包含的隐含特征矩阵,在矩阵分解的过程中,缺失的评分项得到了补充,基于这些补充的评分就可以给用户进行商品推荐了。
对于矩阵R(m×n),ALS旨在找到两个低秩矩阵X(m×k)和矩阵Y(k×n),来近似的逼近R(m*n),即
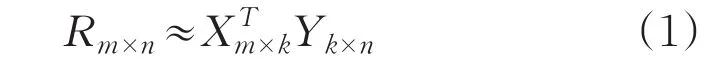
其中,R(m×n)代表用户对商品的品分矩阵,X(m×k)代表用户对隐含特征的偏好矩阵,Y(k×n)表示商品所包含隐含特征的矩阵,其中k<<min(m,n),为了使得矩阵X和Y的乘积尽可能地逼近R,采用最小化平方误差损失函数:

其中,rui表示第u个用户对第i个物品的评分,xu表示用户u的偏好隐含特征向量,yi表示商品i的隐含特征向量,xTuyi为用户u对物品评分的近似,为了防止过拟合,加入正则化项:
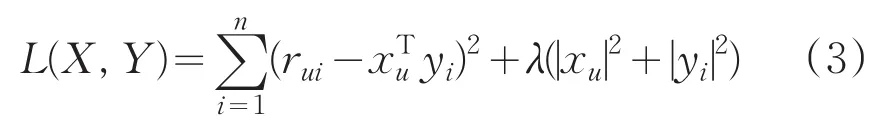
xu和yi耦合在一起,并不好求解,故引用ALS,先固定Y,将损失函数L(X,Y)对xu求偏导,即:
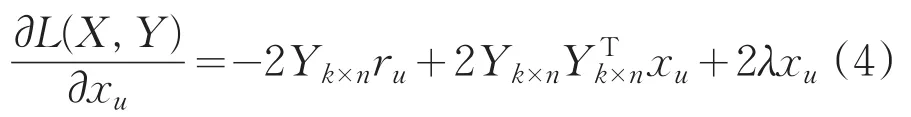
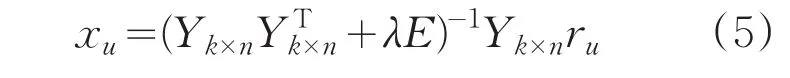
同理固定X,由对称性得:
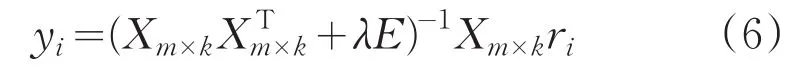
反复进行以上两步的计算,引入均方根误差RMSE作为迭代终止的条件参数。
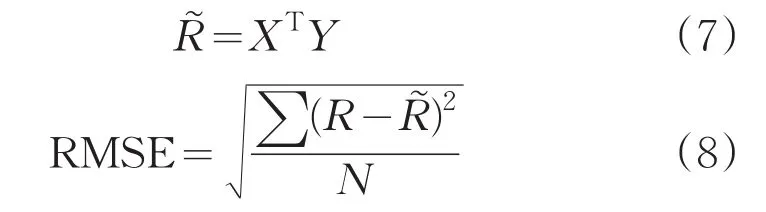
当均方根误差RMSE的值变化很小,小于一个预设值时,就可以认为结果已经收敛,停止迭代,也可以预设迭代次数,当达到预设迭代次数时,迭代停止。
2 Spark优化
2.1 单点故障优化
如图1所示,由于Spark集群是主从式分布结构,即在集群中只有一个Master节点负责整个集群中Worker节点的资源调度和分配,一旦Master节点出现异常就会导致整个集群无法工作,本文用Zookeeper技术来解决单点故障问题。

图1 Spark主从结构图
Zookeeper[12]是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。由Zookeeper维护的Spark集群与HDFS集群可以达到高可用的状态(High Availability)。
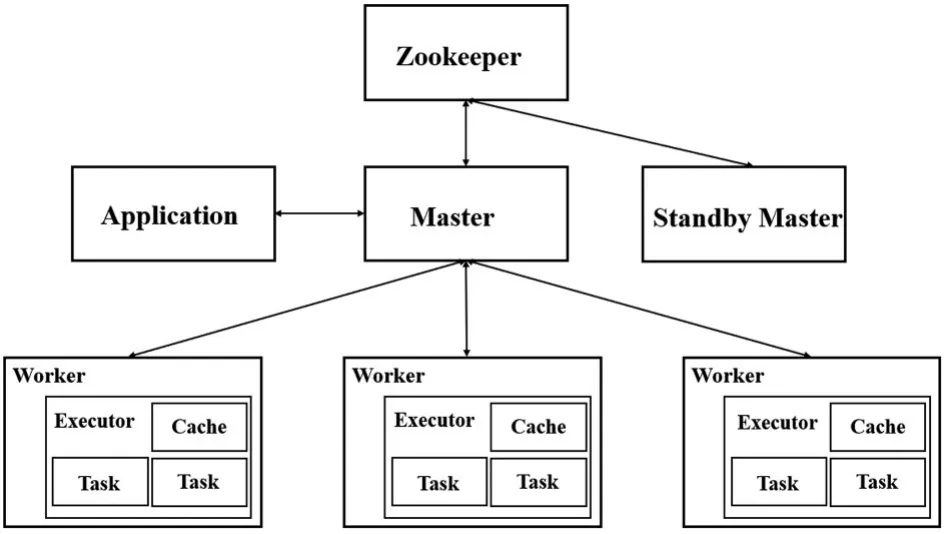
图2 Spark HA(High Availability)集群
图2所示,在HA集群中,可设置多个Standby状态的Master节点,当Master节点发生异常时,Standby Master会切换为Master状态,处于Standby状态的Master在接收到org.apache.spark.deploy.master.ZooKeeperLeaderElectionAgent发送的ElectedLeader消息后,就开始通过ZK中保存的Application,Driver和Worker的元数据信息进行故障恢复。
2.2 Spark Shuffle分析与优化
由于ALS算法多次迭代的特点,Spark作业的性能主要消耗在了Shuffle阶段,同时该环节还包含了大量的磁盘I/O、序列化、网络传输等操作,因此要让ALS推荐算法的性能提高,就要对Shuffle过程进行优化。Shuffle,译为“洗牌”,在MapReduce过程中需要各节点的同一类数据汇集到某一节点进行计算[11],把这些分布在不同节点的数据按照一定的规则聚集到一起的过程称为Shuffle。
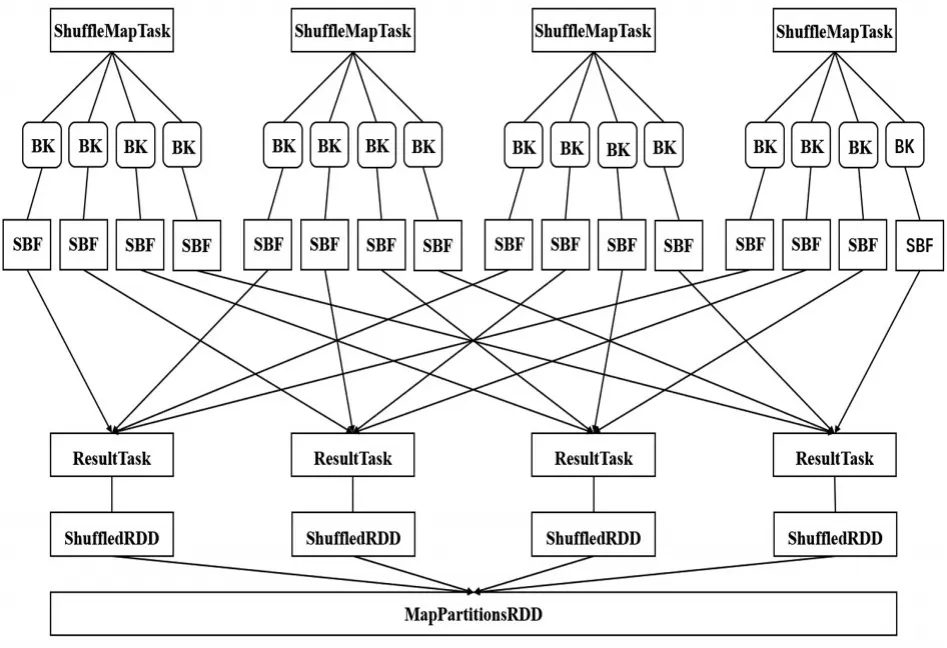
图3 无文件合并Shuffle流程
如图3所示,该图为Spark集群中的某个节点的架构图,此节点上运行了4个ShuffleMapTask,节点的CPU Core个数为2。每个ShuffleMapTask都会为每个ResultTask创建一份BK(Bucket)缓存,以及对应的SBF(ShuffleBlockFile)文件磁盘文件(下文统称Bucket与ShuffleBlockFile为输出文件),ShuffleMapTask的输出会作为MapStatus发送到DAGScheduler的MapOutTrackerMaster中,MapStatus包含了每个ResultTask要拉取数据的大小,每个ResultTask会用BlockStoreShuffleFetcher去MapOutputTrackerMaster获取自己要拉取的数据信息,然后通过BlockManager将数据拉取过来。每个Result-Task拉取过来的数据会组成一个内部RDD,即ShuffleRDD,如果内存不够,则写入磁盘,随后每个ResultTask针对数据进行聚合,生成MapPartitionsRDD。假设有100个MapTask,100个ResultTask,那么本地磁盘要产生10000个文件,由此可以看出Spark的Shuffle过程会消耗大量的磁盘I/O(输入输出)资源,严重影响推荐性能。
通过优化ConsolidateFiles,即map端输出文件合并机制,可以解决map端输出文件过多的问题,如图4所示。
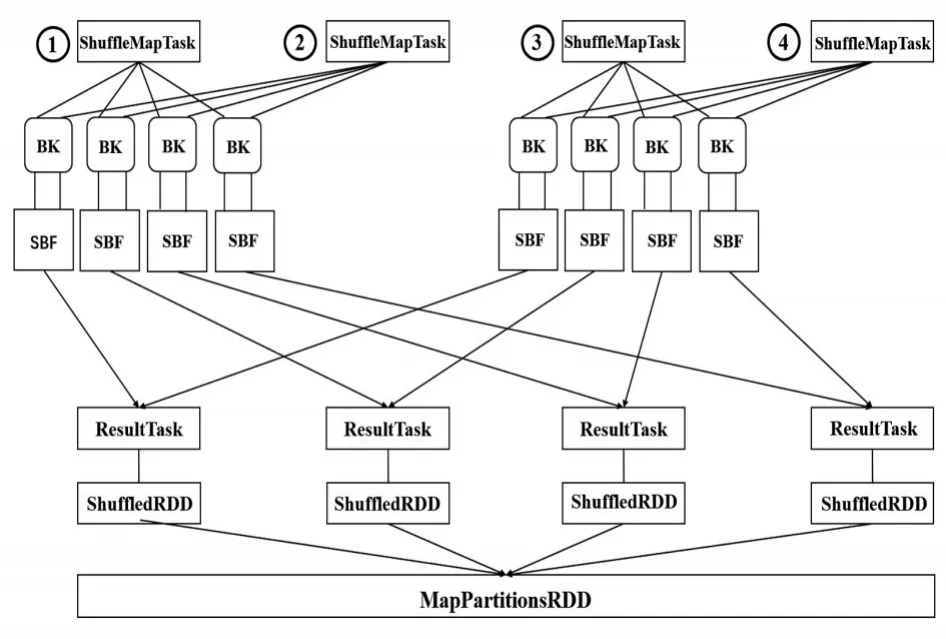
图4 文件合并Shuffle流程
在并行运行了ShuffleMapTask、后,每个ShuffleMapTask都创建了4个BK缓存,以及对应的SBF磁盘文件,ShuffleMapTask、执行完成后,Shuffle-MapTask、在并行运行时不会重新创建新的输出文件,而是复用之前的ShuffleMapTask、创建的输出文件,并将数据写入ShuffleMapTask、的输出文件中,ResultTask在拉取数据时,只是拉取少量数据,每个输出文件中可能包含了多个ShuffleMapTask给自己的输出文件,这样输出文件数量就减少了一倍。在实际应用中假设有100个节点,每个节点一个Executor,每个Executor分配 2个CPU Core,分别有1000个ShuffleMapTask和ResultTask,将会产生100万个输出文件,磁盘对I/O的压力非常大。在优化ConsolidateFiles后,每个Executor执行10个ShuffleMapTask,那么每个节点输出文件的数量是2000个,100个节点输出文件的总数减少至20万个,磁盘I/O压力减小了5倍。
3 实验及结果分析
3.1 实验环境
本文中所搭建的Spark大数据集群为高可用集群,即在集群服务器架构中,当主服务器故障时,备份服务器能够自动接管主服务器的工作,并及时切换过去,以实现对用户的不间断服务,本文所使用的存储系统是Hadoop中的HDFS(分布式文件系统),具体版本如表1所示。
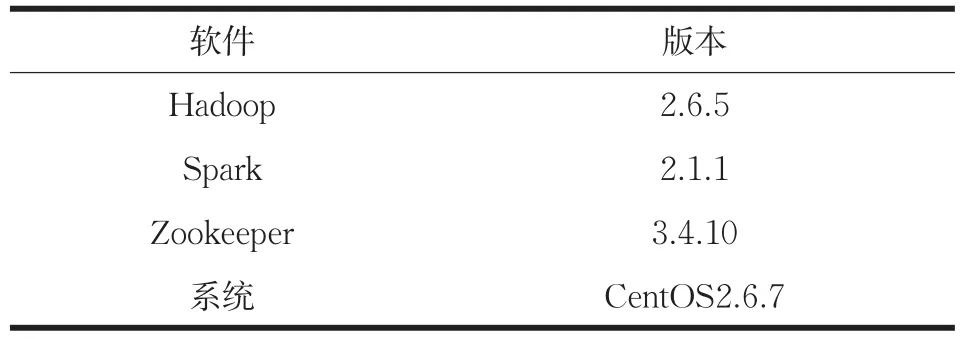
表1 集群配置
Spark大数据集群的优势就是可以不用专业的、价格高昂的服务器,而用普通的个人电脑即可,本文实验中所用的计算机配置如表2所示。

表2 节点配置
如表3所示,节点glance02、glance03为Master节点,即在程序运行中,一旦其中一个Active状态的Master节点出现故障,另一个Standby状态的Master节点会以秒级的速度切换为Active状态,使程序继续运行。
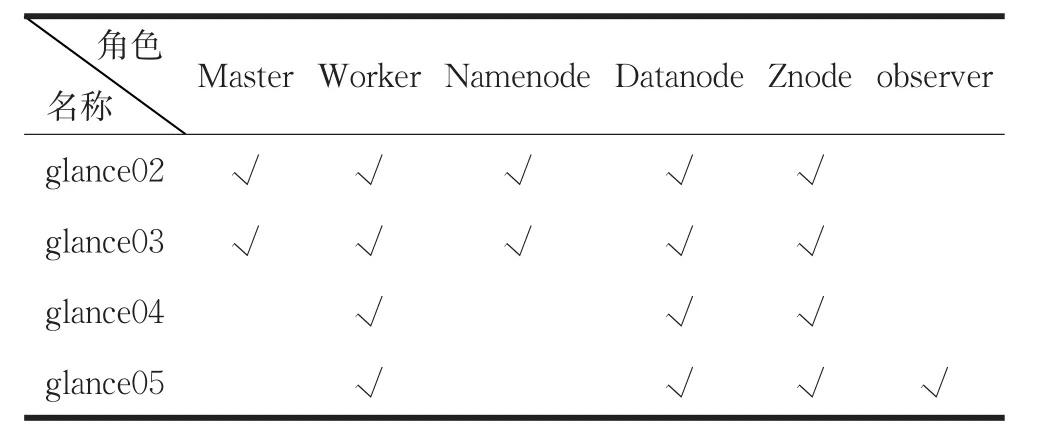
表3 节点角色
3.2 实验数据
本文所使用的数据集为MovieLens数据集,它是由明尼苏达大学的GroupLens研究组组织收集的,数据集中包括用户数据,电影数据与电影的评分数据,主要用于推荐系统的研究,数据集包含几种级别数量级的数据,本文使用的数据大小为:电影数据10618条,电影评分数据为1000万条。
3.3 实验设计
解决针对新用户的冷启动问题:在数据集中选出最受欢迎的50部电影,在这50部电影中随机选取10部电影,让新用户打分,根据用户打分情况,生成用户的特征向量,并使用ALS协同过滤推荐算法向用户推荐50部电影。
通过三组实验分别是无优化,资源优化与Shuffle优化,观察四项指标(RMSE:均方根误差,Iteration:迭代次数,Rank:矩阵维度,Assessment:推荐基准线)与运行时间的关系。

图5 不同优化方式的时间-参数对比图
其中,图5(a)是三组实验中RMSE的变化值与运行时间的关系;图5(b)是三组实验的最佳迭代次数与运行时间的关系;图5(c)是三组实验的最佳矩阵维度与运行时间的关系,图5(d)中Assessment是高出推荐基准评估线的百分比,由这三组实验可以看出,在RMSE与Assessment的值基本不变的情况下,通过资源配置的改进推荐时间由21分钟缩短至14分钟,提升效率为33.3%,通过Shuffle的map端文件合并的优化,推荐时间由14分钟缩短至9.5分钟提升的总效率为54.8%。
4 结论
针对于应用行性强的推荐算法,性能的提高不能仅仅需要考虑推荐算法本身,在数据量急剧增加今天,大数据处理技术的提高与优化也是不可或缺的,本文提出的Shuffle过程中map端的文件输出合并优化是实际生产中容易忽视而又重要的问题,通过实验证明,本文提供的改进算法是可行、有效的。
Spark是基于内存计算的快速的大数据计算引擎,要想使推荐效率进一步提高,在Spark的优化上还有很多值得研究的地方,接下来可以从分布式数据的网络传输,ShuffleMapTask的执行并行度及实际项目重构RDD架构等方面进行更深一步的研究。
