基于FP-growth算法的学生成绩分析系统的研究
2018-10-31韩睿鹏雷立宏丁岩
韩睿鹏,雷立宏,丁岩
(长春理工大学 计算机科学与技术学院,长春 130022)
随着高等教育的迅速发展,大多数高校教育信息化的应用,教务数字化信息数量飞速增长,给高校管理机构和教师的教学方法的改进带了不少新课题[1]。教育行业的大数据处理已经成为我们国家高校基础性和前沿性的技术需求,对学生的成绩数据进行深度的处理和分析就是一个亟待解决的课题,大数据基础上的数据分析可以有效处理这一课题[2]。当前,大部分高校都具有学生成绩数据的海量存储,隐含在这些海量成绩数据后面是很重要的知识信息,学生成绩的大数据分析能够挖掘并利用隐藏的价值。
1 数据挖掘技术及关联规则概述
1.1 数据挖掘技术概述
在互联网+时代,大数据的开放、挖掘和应用已经成为信息领域的发展趋势。数据挖掘是在没有确定目标下去发现潜在应用价值,数据挖掘与普通的数据处理不一样,它把数据处理从简单增添、删除、查询,提高到一个更高级的挖掘知识,智能决策阶段[3,4]。数据挖掘的步骤如下图1所示。数据挖掘任务实现的技术较多,从应用领域和科学研究方面考虑,数据挖掘的技术分为以下6种:关联、预测、聚类、分类、回归、诊断。
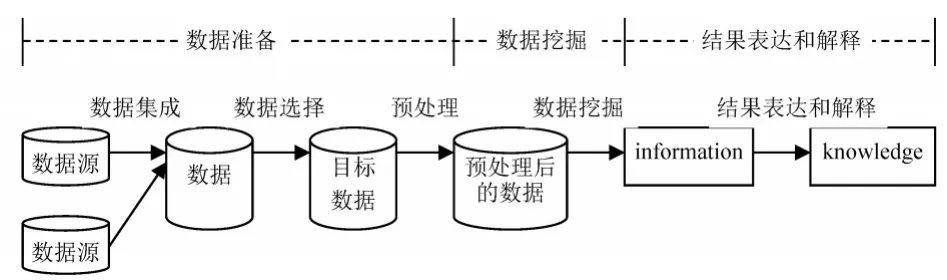
图1 数据挖掘步骤
1.2 关联规则概述
关联规则分析方法是挖掘数据特征之间的彼此联系,挖掘的目标是分析出数据之间隐藏的关系网[5]。关联规则分析在许多领域获得了良好的效果,例如商业、医疗保健、邮递、金融证券等。关联规则的基本概念如下:
定义1:关联规则
关联规则可表示为X⇒Y的公式,X,Y分别是项目集的真子集,X∩Y=Ø。X叫做X⇒Y的前提,Y叫做X⇒Y的结果。
定义2:关联规则的支持度(Support)
关联规则的支持度是交易集中同时包括X和Y的交易数与所有交易数之比,记为support(X⇒Y),即support(X⇒Y)=support(X∪Y)=P(XY)
支持度表明了同时包含X和Y的项集在事物数据库中同时出现的概率。
定义3:关联规则的置信度(Confidence)
关联规则的置信度是事物数据库中同时包含X和Y的事物数与所有包含X的事物数之比,记为confidence(X⇒Y),即:

定义4:最小支持度与最小置信度
最小支持度(min_sup)和最小可信度(min_conf)都是用户自己定义的一个界限值。X⇒Y的支持度≥min_sup并且X⇒Y的可信度≥min_conf,此时认为X⇒Y是有趣的。最小支持度描述项目集统计上最低重要水平,最小置信度描述了项目集统计上必需的最低可信性。
2 频繁增长模式FP-Growth算法
2.1 FP-Growth算法定义
FP-Growth算法是一种关联规则分析方法,创造性地提出使用更适宜的数型结构,没有候选项目集,提高了算法的速度。FP-Growth算法主要分两步:一、建立FP树;二、从FP树中挖掘频繁模式[6]。该算法主要有以下两大优点:一、不产生候选集;二、只需要2次搜索数据库,效率很高。
该算法的具体描述如下:
第一步:FP-树构造算法流程图2所示。

图2 FP-树构造算法流程图
第二步:挖掘FP-tree的频繁模式,算法流程图如下图3所示。

图3 挖掘FP-tree的频繁项集算法流程图
2.2 FP-growth算法实例演示
为了说明算法的实现过程,假设原始项目集如图4所示。
步骤1:构建FP-树:
搜索事物数据库,结果为频繁集1-项目集F,如图5所示。

图5 频繁集1-项目集F
设定min_sup=2,对F重新排列,如图6所示。
创建根节点和频繁项目表如图7所示。

图7 根节点和频繁项目表
加入第一个事物(I2,I1,I5)如图8所示。
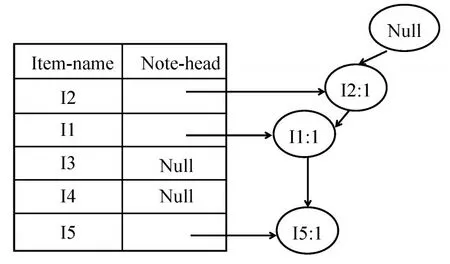
图8 加入第一个事物的FP-树
依次加入其它事物,一棵完整的FP-树构建,如图9所示。
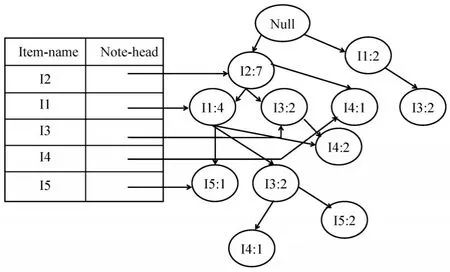
图9 完整的FP-树
步骤2:根据FP-树挖掘频繁项集:
1)首先从I5开始,导出条件模式基:<(I2,I1,I3:1)、(I2,I1:1)>,并构造条件FP-树如图10所示。

图10 I5条件FP-树
得到 I5的频繁项集:{I1,I5:3}、{I2,I5:2}、{I1,I3,I5:2}、{I2,I1,I5:2}。
同理,依次考虑,I1,I3,I4,得到的频繁项集如下。
I1的频繁项集:{I2,I1:4}。
I3的频繁项集:{I1,I3:4}、{I2,I3:4}、{I2,I1,I3:2}。
i4的频繁项集:{I2,I4:3}、{I1,I4:2}。
上面实例演示了FP-Growth算法的详细实现过程,可以看出,按照FP-Growth算法查找频项集,更直观,更高速。
3 基于FP-Growth算法的课程成绩分析
3.1 数据准备及预处理
数据几乎都是不完善的,大部分原始业务数据具有不完全,自相矛盾或数据噪声等的一系列问题。数据预处理可以对原始数据进行纠正、筛选、合并、去除不合理的数据,从而提高数据质量,为下一步的数据分析做好准备。因为数据质量的差异,挖掘类型的不同,原始数据预处理运用的技术也会相应变化。一般情况下,数据预处理包括数据清洗、数据集成、数据规约和数据变换等步骤,如图11所示。
用于成绩分析的样本数据来源于长春理工大学教务管理系统中2012-2016级计算机科学技术专业7个班4个年级必修课成绩数据。教师输入数字化成绩时,偶尔也会出现失误,学生也会由于某种原因缺考或中途退学,去掉成绩缺失和数据错误的记录后,共有1200条成绩记录。成绩单包括学号、姓名、学院、系、计算机导论、面向对象程序设计、数据结构与算法、数字逻辑、计算机网络、计算科学与数值方法等多个属性。首先将姓名、学院、系这几个属性删掉,其余的全部用于挖掘分析成绩的属性。
在数据分析前经常需要对连续型的数据进行转换,数据离散化是创建数据挖掘算法最常使用的方法,而数据挖掘结果的可靠性是与数据离散化方法的选取息息相关的。数据离散化是把连续型数据划分成若干区间,然后分别用不同符号来代替不同个区间。使用的是“自动调整宽度”的离散化方法。此方法的特点是充分照顾到不同数据特性,数值区间划分的比例能够调控,具有较强的灵活性[7]。
在针对学习成绩的分析中,将分数制的成绩数据离散化为等级制。由此把百分的成绩分为优秀、良好、中等、及格、不及格5个等级,下表1表示各等级在各门课程中所占百分比[8]。

表1 课程成绩离散化数据比例
依照表1中对各门课程成绩的百分率分段,将每个学生的成绩转换成A,B,C,D,E五个等级。
3.2 代码转换表制定
把参加挖掘的每门课程名称转换为编码,计算机导论的编码为1,面向对象程序设计的编码为2,数据结构与算法的编码为3,以此类推[9,10]。
同样把成绩等级转换为编码,优秀为A,良好为B,中等为C,合格为D,不合格为E,则成绩数据转换后的代码表如表2所示。
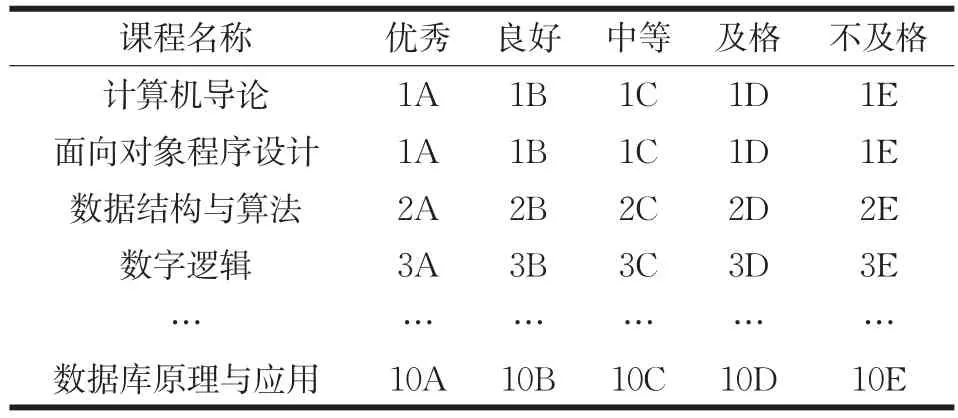
表2 代码转换表
3.3 学生成绩表的转换
学生成绩数据库如下表3,表中每一行是一个学生的成绩信息,例如:第一行是学号S1的各门课成绩,计算机导论、面向对象的程序设计、数据结构与算法、高等数学等分别是91、86、83、92、…。

表3 学生成绩数据库
依据FP-growth算法的要求,下面将学生成绩数据库(表3)转换为对应的事务数据库,使用区间映射方法,将学生表中对应的每一个的成绩值由数值型映射成某个枚举值,转换结果如表4所示。

表4 事物数据库
3.4 挖掘结果
为了数据挖掘的信息可信程度较高,设置min_sup=0.3,min_conf=0.6,执行 FP-growth关联分析算法,分析哪些课程之间具有较强的关联性,挖掘出前期课程对后期课程成绩的影响。挖掘出来的部分结果如表5所示,可以看出,满足最小支持度0.3的包含3门课的项集如下:
{数字逻辑(良好),面向对象程序设计(优秀),计算机网络(优秀)}
{电工电子技术(优秀),数据结构(中等),计算机网络(良好)}
{数据结构(良好),数字逻辑(良好),计算机网络(良好)}
说明计算机网络取得优秀成绩和数字逻辑的优良程度且面向对象程序设计优秀具有很大的关系。
设置目标课程T为“计算机网络”,目标规则为关联后件包含“计算机网络”的关联规则。得到的关联规则如表5所示。

表5 部分挖掘结果示例
表5的规则表明如果数字逻辑成绩优秀,则计算机网络成绩也为优秀的概率为90.1%,说明数字逻辑成绩好的学生在学习计算机网络课程时会有一定优势,原因在于数字逻辑作为计算机专业的基础学科,为学生奠定了逻辑运算及硬件基础,可为学习计算机网络打好基础。计算机导论成绩优秀,则计算机网络成绩也为优秀的概率为85.9%,说明计算机导论成绩突出对学习计算机网络也有很大优势,计算机导论讲述了有关计算机的基础知识,基本理念,给予计算机网络的学习很深厚的专业理论功底。同理,挖掘出的其他规则可以得到其他前期课程对计算机网络成绩的影响。
根据以上列出的具有较强关联性的课程和推导出的关联规则,教务管理人员可以预先了解学生学习有关课程的情况,有选择性地制定教学计划。例如,若计划开设《计算机网络》这门课程,则可使用《数字逻辑》这门课程学习成绩对《计算机网络》课程预先测评,对班级每个学生的学习状况进行评估,根据不同的评估结果,分别对待,个别指导,继而激发全班学生的学习潜力。学生们亦可根据挖掘出来规则,提高对某些课程的关注和努力。比如想要《计算机网络》课程取得好的成绩,从表5规则可看到,如果其先期课程《数字逻辑》成绩良好及《面向对象程序设计》成绩优秀,学好《计算机网络》课程的可能性就很高,从为学习做好先期准备,提升学习效果。
4 结束语
关联规则分析是数据挖掘中最简单、最实用、最重要一种知识模式,实验证明,通过FP-growth频繁增长模式算法能够有效地对课程成绩数据进行挖掘分析,得到理想的挖掘结果。挖掘出来的关联规则在某种程度上显示了课程之间时间安排顺序的重要性,前期课程对后续课程教学效果的影响力。此外,教师可以根据前期课程的学习情况,有目标、有针对性地对不同学生关注和辅导。学生也可参照规则,对学习的科目进行评估和预测,以便在今后的学习中采取有效的措施,最终达到较好的教学效果。课程成绩数据分析的有效成果为将数据挖掘技术逐步推广开来,应用在教育领域的各个方面,具有重要的现实意义。
