基于上下文信息的自适应场景分类算法
2018-10-29史静,朱虹
史 静,朱 虹
(西安理工大学自动化与信息工程学院,陕西西安710048)
近些年来,随着互联网的发展,网络上每天都涌现出大量的图像和视频资料,我们可以充分利用网络资源丰富我们的生活,但随之而来的问题就是,如何更好地分类、管理这些资源。
目前,由于网络的归类整理方式和能力有限,加之大量图像的文字标注有误差,使得利用文字注释进行图像分类整理方法不再具有优势。由此,依据图像内容进行分类的算法逐渐发展起来,并成为机器视觉领域中一个重要的研究内容[1-3],其应用领域涉及到基于内容的图像检索[4]、目标检测[2]、视频摘要[5]、视频内容分析[6],特别是机器人服务[7],例如机器人路径规划和机器人管家等等。
早期的图像分类,主要通过描述图像底层特征[8]信息来表征图像的视觉感知属性,进行场景分类,之后映射到高层语义进行分类。文献[9]将图像表示为一个尺度不变的响应映射,通过提取的底层特征进行聚类,构成“视觉词袋”来表征图像的语义信息[10-11],最终反映图像的类别信息。
然而,由于场景中的事物数量和种类繁多,同类场景之间类内变化较为丰富,以及不同类场景之间差异较小,造成了使用功能的差异,这些影响降低了其分类的准确度。
见图1,图1(a)为同一类的两幅不同图像,然而,类内的出现目标、聚集区域以及姿态和外形都有着相当大的差异。图1(b)~(d)中的三幅图像分别属于三个不同的类,但却在视觉上非常相似。因此,对于一个高性能的分类系统来说,应该能够处理具有细微视觉差异的图像类别。

图1 类内差异及类间相似图像对比Fig.1 Images comparison of intra-class differences and extra-class similarity
针对上述问题,本文提出了一种新的基于上下文信息的自适应场景分类算法,通过对图像的上下文信息进行优先检测,弥补了将图像中的事物割裂开来并硬分割组合的缺点。同时,利用提取的上下文信息对图像的多尺度多方向特征进行优化,进一步有效地提高了分类算法的效率和精度。
1 算法描述
本文算法中为了充分利用图像在不同尺度方向下的频域特征,首先对图像进行Gabor变换[10],之后,分别提取各尺度方向下Gabor变换图像的显著性区域。接着,对不同尺度方向下的Gabor变换图像提取细节纹理特征,并利用同尺度方向下显著性检测的结果,对这些特征进行加权融合,并得到加权后纹理特征的累计直方图。最后,送入到SVM中进行训练。由于部分数据集中的图像大小不一,所以,在训练和测试之前需要将图像尺寸归一化。
1.1 Gabor变换
Gabor变换是Gabor等提出的一种时间-频率分析方法。其对信号的处理近似于人眼,能够很好地提取目标物的局部空间和频域信息,特别是对于图像的边缘信息,具有良好的方向和尺度选择特性,且对于光照信息不敏感。鉴于以上原因,本文根据Gabor变换特殊性质,在其变换域的的不同尺度和方向上提取主要关联特征,在这里我们进行5个尺度和8个方向的Gabor变换,即一幅图像共得到40个变换结果图。见图2,由于变换结果图较多,仅显示Gabor变换的部分结果图。

图2 Gabor变换示意图Fig.2 Gabor transformation images
1.2 显著性检测
由人眼的视觉感知特性可知,人们对场景的认知通常是依据场景中的某些事物,比如如卧室中的床、教室中的桌椅等,而对于场景的判别问题,目标物的检测就尤为重要。
早期的显著性检测算法主要集中在对目标物轮廓信息的描述,并没有对目标物存在的区域显著性进行判别,且只注重目标物本身的提取,没有关注目标物之间的相互关联,因此存在局限性,况且简单的目标物检测及组合,并不能准确表征图像场景所反映的内容。
鉴于以上原因,根据Goferman[12]的思想,所提取的显著性区域,不但与周围邻近区域具有明显差异,而且与图像整体也具有明显的差异,充分考虑了图像中上下文之间的语义关系。通常情况下,图像块之间的颜色差异越大,距离越近,则显著性越强。在提取场景图像显著性区域的基础上,注重显著目标之间的上下文关系。
图3为部分图像及其进行显著性检测后的结果。通过图3可以看出,结果图像能够充分地反映场景中的事物,并对周围环境进行了一定程度地描述。

图3 部分图像及其进行显著性检测后的结果Fig.3 Partial images and the results from sensitive information detected
1.3 特征提取
本文利用经典的LBP(Local Binary Pattern,局部二值模式)算法[13],它是由Ojala等人提出的,能够很好地描述图像的细节特征,对于图像中的旋转和灰度变化有着较强的鲁棒性。计算公式如下:
(1)

(2)
式中:gc代表模板中的中心像素值,gn代表模板中与中心像素相邻的像素值,N为模板中像素点的个数,s(x)为纹理元。
见图4,由3×3模板所覆盖的区域,将区域中的周围像素与中心像素进行比较,所得的结果表示成8位二进制码,将这8为二进制码转为十进制,即为该模板中心像素的LBP值。通过该算法,将图像中的所有像素点映射到0~255的范围内。

图4 LBP特征提取示意图Fig.4 LBP feature extraction images
图5为对图2的Gabor变换结果提取LBP特征后的部分结果。从结果图中可以看出,LBP特征可以从不同尺度方向Gabor变换中提取更多的细节纹理特征,且表示更加清晰。
1.4 特征融合
将每幅训练图像Gabor变换得到的40幅变换图像,进行显著性检测,同时提取LBP特征,在同一尺度方向下利用显著性检测图对LBP特征提取图进行加权,权值通过Sigmoid函数[14]映射得到。Sigmoid函数为S型函数,也称为S型生长曲线,有着单增以及反函数单增等性质,常被用作神经网络的阈值函数,将变量映射到0~1之间。计算公式如下:
(3)
式中:w为显著度值,αw为Sigmoid函数映射后的权值。下式为利用Sigmoid函数映射结果对LBP特征进行加权的公式:
LBPweight=αw·LBPnew
(4)
其中,LBPweight为加权后的LBP特征。

图5 Gabor变换提取LBP特征部分结果Fig.5 The partial results of Gabor transform extracts LBP feature
对所有加权后的LBP图像求取累计直方图,生成256维特征向量,将所有尺度方向下的特征向量进行串联,即每幅图像转为256×40=10 240维特征向量。如此高维的特征向量,无论对于纹理的提取、表达都是不利的,数据量过大,导致直方图过于稀疏,而且还会影响后期事物纹理的识别、分类及信息的存取,大大降低了算法的效率。因此,需要对加权后的LBP特征向量进行降维,使其在数据量减少的情况下,能够很好地保留原始数据的特征信息,本文利用Ojala提出的均匀模式LBP(Uniform Pattern LBP)进行降维。
经过统计,均匀模式LBP在整个的LBP特征中占85%~90%,而其他模式只占很少的一部分,因此,对于3×3的邻域,将LBP特征值分为59类,58个均匀模式为一类,其它所有值为第59类,直方图从原来的256维变成59维。最后,将每幅训练图像融合后的59×40=2 360维特征作为训练特征,送入到SVM中进行训练。
2 实验结果分析
在3个公共标准图像集上评价本文算法,分别为8类自然场景图像集[15]、8类运动场景图像集[16]及15类场景图像集[15,17-18]。为准确评价本文算法与同类文献的实验结果,应用同样的训练和测试数据比例。
1) 8类自然场景图像集(OT):该数据集共包含8类2 688幅大小均为256×256的自然场景图像。见图6(a),有海滩、高楼等。每个类别利用200幅训练,其余用来测试。

图6 各数据集部分图像Fig.6 Partial images of each datasets
2) 8类运动场景图像集(SE):该数据集共包含8类1 579幅运动场景图像。其中包括赛艇、滑板滑雪、攀岩等,见图6(b)。每个类别利用70幅训练,60幅用来测试。
3) 15类场景图像集(LS):该图像集总共4 485幅图像,分为15类,包括室外以及室内场景,见图6(c)。每类利用100幅图像训练,其余用来测试。
在测试过程中,将测试图像通过上述步骤得到2 360维特征向量,送入到已训练好的SVM分类器中测试。
为了比较添加了显著性算法与未添加该算法对本文实验结果的影响,本文按照同样的实验数据划分比例,对有无显著性算法的实验结果进行比较测试。表1为5次测试结果的平均值。
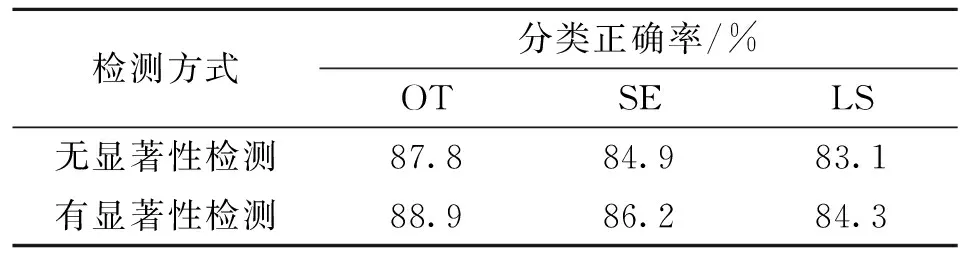
表1 有无显著性检测算法的分类准确率比较Tab.1 The classification accuracy with and without containing saliency detection algorithm
通过表1可以看出,在三个图像集中,OT数据集的分类效果最好,一方面由于分类的数目较少,室外场景中目标物之间的上下文关系较为单一,变化较少,另一方面同类场景中目标物的纹理结构较为类似,因此分类难度较小,而SE和LS数据集场景中目标物相对比较复杂,特别是LS数据集中还包括一些室内场景,因此分类准确率较低。
增加了显著性算法后,分类准确率相比较没有显著性算法的结果有了略微的提升,说明该算法具有一定的有效性,特别是对于SE数据集,提升的幅度相对较大,主要是由于该数据集为运动场景数据集,显著性区域较为明显且集中,而另外两个数据集所包含的场景显著性检测所捕获的上下文关系不够明显,显著区域较为分散,因此,利用该算法所提升的性能有限。
将本文提出的算法在3个公共图像集上与同类算法的分类正确率进行比较,结果见表2。

表2 分类正确率的比较测试实验结果Tab.2 Comparison test results of scene classification accuracy
从表2中可以看出,本文算法较对比文献算法整体占优,文献[7]利用核稀疏表达(KSR),其为图像在高维空间中的稀疏编码技术去分类场景和人脸。文献[13]提出了多尺度完备局部二值模式(MS-CLBP)描述子,在多个分辨率下表征占主要地位的纹理特征。文献[19]利用扩展谱回归和词袋特征对图像进行分类。本文的方法不需要建立复杂的主题模型,只需提取图像的多尺度方向纹理特征,并利用显著性区域检测对特征进行增强。
3 结 语
本文提出了一种有效的场景图像分类方法,通过提取图像的显著性区域和多尺度多方向上的细节纹理特征,并利用显著性检测算法对特征进行加权融合。之后,根据均匀模式对加权后的LBP特征向量进行降维。最后,训练SVM分类器,并进行分类判别。该方法不仅充分考虑了人眼对视觉信号的敏感程度,而且弥补了单尺度单方向特征对于整体图像描述不足的缺陷。
