基于PLSR的土壤有机碳预测模型中建模组与验证组最优数量关系
2018-10-26丁建军
丁建军,章 盛,孙 超,米 铁
(江汉大学 a.物理与信息工程学院;b.化学与环境工程学院,湖北 武汉 430056)
0 引言
土壤有机碳(soil organic carbon,SOC)是土壤质量评价和土地可持续利用管理中必须考虑的重要指标[1]。多元线性回归模型能有效地对土壤属性进行分析与预测,自WOLD等[2]于1983年提出了偏最小二乘回归(PLSR),有效解决了多个环境因子相互间的多重线性问题[3],国内外专家学者便开始使用多元线性回归方法对土壤进行研究。UDELHOVEN等[4]对未经处理的原始土壤样本进行PLSR模型预测R2=0.60,精度较差。刘焕军等[5]建立多元逐步回归预测模型预测东北黑土土壤有机碳含量R2=0.936。刘雪梅[6]对江西红壤样本的有机碳含量进行PLSR模型预测R2=0.81。
本文通过使用PLSR算法构建土壤有机碳含量快速预测模型。由于在建立PLSR模型时发现以上文献中均未详细讨论如何使用PLSR构建最优的土壤有机碳预测模型,本文详细论证建模过程中建模组样本数与验证组样本数的数量关系,分析得出基于PLSR的土壤有机碳预测模型最优条件。
1 材料与方法
1.1 材料
实验所用土壤样本采集于湖北省武汉市蔡甸区的典型南方水稻田,每块稻田随机采集5组样本,共采集样本105组。将采集的每个样本逐一标号,剔除杂质并置于干燥通风处风干,研磨并过孔径为0.25 mm的土壤筛过筛后,对各组样本采用重铬酸钾容量法[7]逐一测定其有机碳含量的标准理化值。
1.2 方法
1.2.1 数据预处理 为减少实验过程中外界环境如噪声、样本的背景信息和杂散光等因素的影响,本研究对每组土壤样本光谱数据分别进行了S-G平滑、一阶微分、标准正态变量变换等若干种数据预处理方法。S-G平滑加一阶微分预处理后的光谱曲线能清晰地表现出波长-反射率曲线在440~1 000 nm波段上各点处的明显差异(图1),具有明显的区分度和显著性,故本研究使用S-G平滑加一阶微分混合预处理方法。

图1 S-G平滑加一阶微分预处理Fig.1 Pretreatment by S-G smoothing and with first order differential
1.2.2 PLSR建模与评价指标 由于土壤的近红外光谱中每个波长点可能重叠了多种成分信息,导致该谱区产生光谱复杂、谱峰重叠等各种不利因素,难以进行直接分析,故在近红外定量分析中需通过化学计量学方法[8],如主成分回归(PCR)、偏最小二乘回归(PLSR)、支持向量机(SVM)、人工神经网络(ANN)等建立光谱属性与被测参数之间的相关关系模型。其中,PLSR是一种基于多因变量与多自变量之间相关关系的回归建模方法,偏最小二乘回归分析能较为有效地解决传统多元回归难以解决的问题[9]。PLSR算法在建模过程中对近红外光谱矩阵X进行分解,剔除某些影响建模的非相关信息的同时也对浓度矩阵Y进行相应的变换处理,并在处理光谱矩阵X的过程中考虑了浓度矩阵Y对其的二次作用。
对于所建立的校正模型必须通过对验证集样本的测试以判别所建模型的质量是否达标,模型预测效果的优劣一般通过统计参数进行评估,如建模均方根标准差(RMSEC)、预测均方根标准差(RMSEP)、决定系数(R2)等。若R2数值越大,RMSEC与RMSEP数值越小,则预测效果越好[9]。

其中yi,act为第i个样品的实测值,yi,pre为建模集中第i个样品的预测值,y′i,pre为验证集中第i个样品的预测值,n为建模集的样品数,m为验证集的样品数。

在建立PLSR模型前,需判断所选主成分因子的数量。其采取的方法为逐步等量增加所选因子的数量,即因子数每变化一次,校正集对模型便进行一次检验。当检验的结果使RMSEC最小且R2最大时,其结果即为合理取值[10]。本研究中的主成分因子数为2。
2 结果与分析
2.1 模型建立与分析
结合上述模型质量评价指标的数学公式定义可知,若建模集样本的数量过少则会导致PLSR模型的预测能力不足;若验证集样本的数量过少则会导致PLSR模型的精度不高。由于建模集样本与验证集样本的数量之和为一定值,故需合理确定实验样本的建模集与验证集的数量关系。
基于上述原因,本研究通过调整建模集与验证集的数量关系,将土壤样本分为3组,逐一进行建模分析。1号组中建模集与验证集的数量关系为1∶1,即建模集样本数为52、验证集样本数为53;2号组中建模集与验证集的数量关系为1∶3,即建模集样本数为26、验证集样本数为79;3号组中建模集与验证集的数量关系为3∶1,即建模集样本数为79、验证集样本数为26。
当建模集与验证集的数量关系为1∶1,即建模集样本数为52、验证集样本数为53时,所有样本点较为均匀地分布在标准分界线两侧(图2),表明通过模型预测数值与标准理化试验实测数值较为吻合。

图2 1号组分布图Fig.2 Distribution map of group 1
当预测集与验证集的数量关系为1∶3,即预测集样本数为26、验证集样本数为79时,所有样本点均分布在标准分界线下侧(图3),表明此时的模型预测值普遍低于标准理化试验实测值。
当预测集与验证集的数量关系为3∶1,即预测集样本数为79、验证集样本数为26时,绝大多数样本点基本分布于标准分界线上侧(图4),仅有极个别样本点落于标准分界线上,表明此时的模型预测值普遍高于标准理化试验实测值。
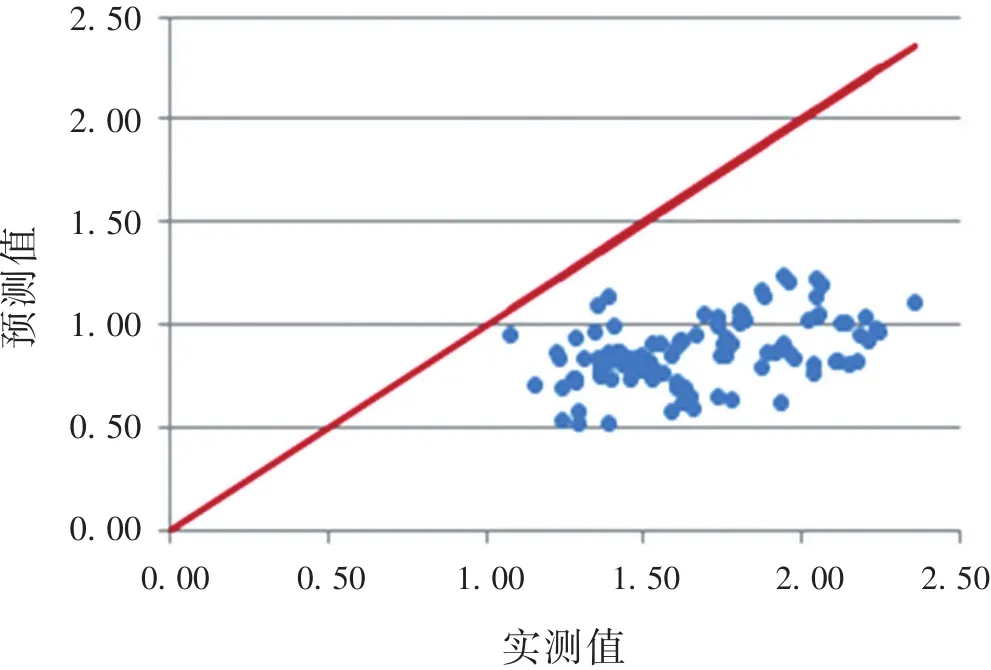
图3 2号组分布图Fig.3 Distribution map of group 2
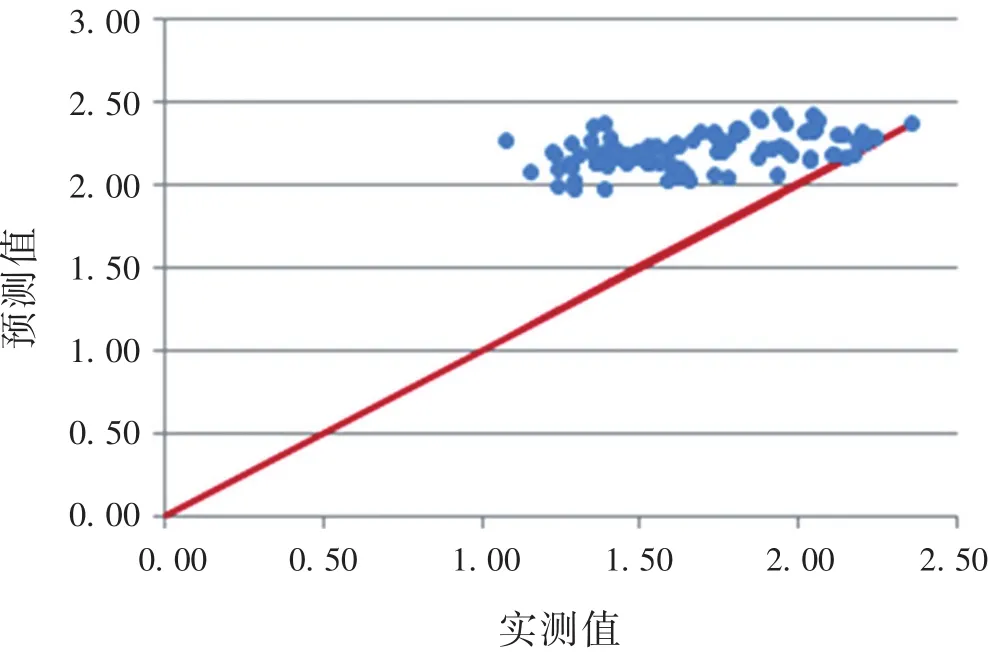
图4 3号组分布图Fig.4 Distribution map of group 3
2.2 模型质量评价比较
从表1中得知,基于建模集与验证集的数量关系为1∶1时所建立PLSR模型的1号组,RMSEC=0.25,数值远低于其他两组;=0.98,数值远高于其他两组,各项性能参数指标计算结果均明显优于其他两组。

表1 3组PLSR模型的评价参数比较Tab.1 Comparisons of evaluation parameters of three groups of PLSR models
3 结语
本研究通过可见-近红外光谱技术获取土壤的可见-近红外光谱作为实验对象,对光谱敏感波段范围内的反射率与有机碳含量进行了相关性分析,使用S-G平滑加一阶微分混合预处理方法对原始光谱进行预处理,通过调整模型建模集与验证集的数量关系,建立了3组偏最小二乘回归(PLSR)模型。最后通过各项评价指标对3组模型进行比较,最终得出将建模组样本数与验证组样本数的数量关系设定为1∶1时,是基于PLSR建立土壤有机碳含量预测模型的最优条件。
