融合评分-评价一致性和多维时间序列的虚假评论识别方法
2018-10-26房有丽
房有丽,王 红,3
1(山东师范大学 信息科学与工程学院,济南250358 )2(山东省分布式计算软件新技术重点实验室,济南250014)3(山东师范大学 生命科学研究院,济南250014)
1 引 言
网上购物迎合了当今快速的生活节奏,给人们生活带来便捷.但是,虚假评论的存在,为营造公平公正的网络购物环境带来了巨大挑战.网上购物使得用户无法亲身感受到商品质地和性能,所以,在线评论成为顾客了解商店与商品的重要渠道,他们通常先参考商品的评论与评分,再决定是否购买.好的评论可以提升产品的信誉,引导更多的顾客购买;相反,差的评论会影响信誉,降低销售量.因此,由于利益的驱动,商家开始雇佣水军冒充普通顾客伪造评论.一方面对自己的商品进行好评,另一方面对于竞争者恶意诋毁.因此,如何有效发现这些虚假评论成为亟待解决的问题.
先前的工作大多分别利用评分或评论来检测虚假评论,如1-2分代表差评,3分代表中评,4-5分代表好评,这些方法存在不足:第一,分别利用评分或评论检测虚假评论,而没有考虑二者的一致性问题,只利用评分或评论不能准确检测出虚假评论,因为评论与评分有时会不一致,评分不能完全代表评论者的真实情感.其中本文提到的一致性是指评论文本的情感极性与其评分都是一致积极或者消极,呈现正相关,如表1所示,A、B表示不一致,C表示一致;第二,忽略了虚假评论在不同的时间的不同表现.一般来说,在一段时间内评论数量激增及评分突然上升或下降,就可能存在不真实的评论.针对上述问题,本文提出了基于评分-评价一致性和多维时间序列的虚假评论识别方法.

表1 评论-评分一致性对比表Table 1 Comment-rating Consistency comparison
本文的主要贡献包括:
1)提出了判断评论与其评分差异性的方案,综合利用评分和评论检测虚假评论.给出分析感情极性并判断与其评分的一致性算法.
2)研究虚假评论在时间维的表现,提出了针对评论与评分的多模态时间统计检测方法,检测一段时间内评论与评分突变的相关性,而不是传统的静态评论集合检测方法.
2 相关工作
近年来,研究者们在垃圾网页[1]与垃圾邮件[2]的识别研究上做了大量工作,获得了较好效果.近来,虚假评论的检测成为一个研究热点.Jindal等[3]发现了虚假评论广泛的存在于商品中,但是这些评论本质上与垃圾网页和垃圾邮件不同,他们利用商品的评论数据、融合评论文本内容和商品的特征因素进行建模来区分复制观点和非复制观点,检测出是复制观点时则判为虚假评论.
Xie等[4]发现了单一评论是虚假评论的重要组成部分.正常的评论比较稳定、相关低.相比之下,虚假的评论相关性高且突发性,表达情感极性强.因此提出时间模式,构建基于多维聚合的时间序列统计以此挖掘虚假评论的相关性.
OTT等[5]利用众包平台实现了第一个虚假评论的“黄金”数据集,其中包含真实评论跟虚假评论.在基于计算机语言学的基础上,把虚假评论的检测问题转化为文本分类问题.Li等[6]通过网络获取大量产品的评论,然后手动标注语料库,利用协同算法来检测虚假评论.
任亚峰等[7]提出基于语言结构和情感极性的虚假评论识别方法,并利用自然语言处理技术分析正面和负面情感极性对评论的影响.然后利用遗传算法,通过复制、交叉和变异实现种群的进化,从而提高准确率.Li等[8]利用语义和情感检测,并给出了构建每个特征的模型和算法,实验表明,提出的模型,算法和特征在检测任务中比基于内容,评论者信息和行为的传统方法有效.
Peng等[9]为了解决情感对商品的影响度,提出了基于自然语言处理技术对于情感的评分,并通过观察建立规则来判别虚假评论,实验表明,他们所提出的方法在分析情感的精确度上取得了良好的效果.
Chang等[10]利用重要的属性词,具体的量词和名词动词比例来构建虚假模型,结果说明更加独特的词汇和具体的量词和名词包含在内,假冒的可能性就越小.Li[11]等通过集体无标记的学习来识别虚假的评论.
通过总结前人的工作发现,研究者分别从评分和评论两个方面进行研究.一方面从商品评分着手,通过聚类算法进行分组,识别出虚假的评论;另一方面是基于自然语言分析文本.本文提出融合情感分析、评分与评论一致性、以及时间序列的动态多维模型来检测虚假评论.
3 方法与模型
本文的目标是利用情感技术及多维时间序列更加准确的检测虚假评论,为了实现这个目标,有3个问题需要解决.第一,如何判断评论文本的情感极性与其评分的一致性,第二,如何利用时间序列模型检测在一段时间内评论数量与评分突变的相关性,进行虚假评论识别;第三,如何通过机器学习模型发现虚假评论的影响因素,并揭示这些因素与识别虚假评论的关系.
3.1 评论文本情感极性分析
评论文本的情感倾向分析是通过挖掘和分析评论文本中的立场、观点情绪等主观信息,分析得出评论者的正面或者负面情感倾向.Dewang等[12]提出了一套新的词汇和句法特征集,并应用监督算法对假评论数据集(黄金标准)进行分类.邸鹏等[13]提出对转折句式文本分析算法,主要针对长文本的情感分析,所以考虑上下文的转折关系是有效的.但是他们直接对短文本分析效果并不佳,因为无法考虑上下文信息.本文提出了不同的计算方法:分别利用情感强度、特征权重对虚假评论的影响,提出了感情极性与其评分的一致性算法,如算法1所示.为了方便计算,符号表示如表2所示.
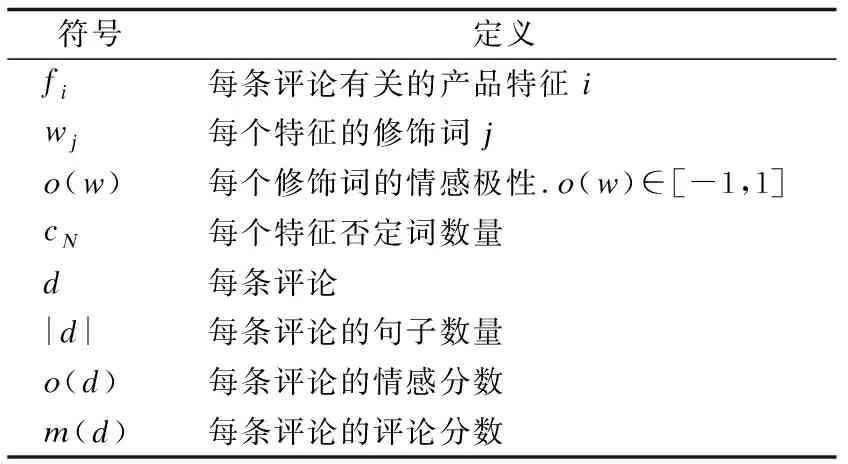
表2 符号定义表Table 2 Symbol definition
定义f(d)代表语义情感分数和评分之间的差异度,如公式(1)所示,若m(d)与o(d)的乘积大于0,则表明它们之间没有太大的差异;若是二者乘积小于0,则说明它们的差异过大是虚假评论.
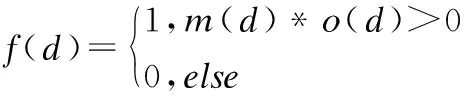
(1)
1)情感强度.情感强度是指情感词通过距离对特征的影响度.当特征与情感词距离较近时,情感强度加强,反之亦然.定义s(f)代表所有特征词汇情感度,用dis(wi,f)表示两者的距离,计算情感词对特征的影响度如公式(2)所示.
(2)
在公式(2)中,o(wj)表示情感极性的词汇,当是积极性词汇时,情感极性用+1表示;当是消极性词汇时,情感极性用-1表示.cN表示每个特征否定词的数量,如果没有否定词,cN等于0;若有奇数个否定字,极性情绪为-1,否则为+1.
2)特征影响度.特征影响度是指利用不同特征判断虚假评论的准确度.在评论里有很多特征对判断虚假评论都有影响,但影响程度不同.权重较大的特征判断虚假评论精确度会更高;相反,权重较小的特征甚至影响虚假评论的判别.定义o(d)代表每条评论的情感分数,如公式(3)所示.
(3)
Algorithm1.Review Analysis
1.INPUT:Review Text:
2.OUTPUT:Review Orientation
3.rt←{Review Text};
4.While(rt.read())
5. For all j∈rt.Length DO
6. IF(rt.wordi∈NegDictionary) THEN
7. IF(num/2!=1)THEN
8.o(wj)←o(wj)
9. ELSEo(wj)←-o(wj)
10.END FOR;
∥emotional intensity calculation
∥emotional score calculation
∥evaluation and score consistency judgment
13. FORfielement ind
14. IFm(d)*o(d)>0
15.f(d)=1∥the two are consistent
16. ELSE 0∥the two are inconsistent
17. END FOR
18.END WHILE;
19.RETURNf(d)
3.2 基于多维时间序列异常检测
商家雇佣水军冒充普通顾客伪造评论,会造成一段时间内评论数量激增及评分突然上升或下降.最早提出利用时间序列检测虚假评论的是文献[14],但是存在着不足,他们仅基于评分建立评价指标,不够准确,因此,本文提出利用多维时间序列关于评论及评分异常模式检测方法.
3.2.1 时间序列结构
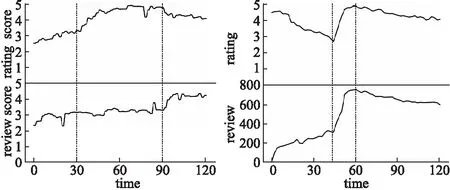
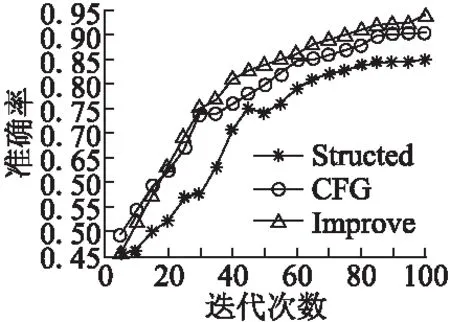
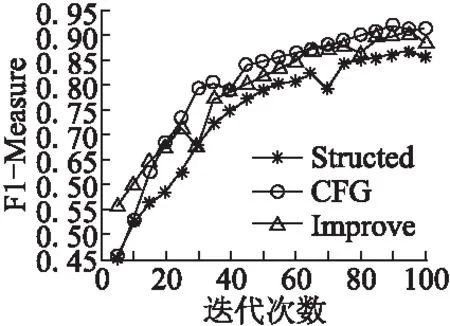
检测方法是基于时间序列,包括评论数量、平均评分.每个商店都有一系列按照发布时间升序排序的评论数量及评分.其中,R(s)={r1,…,rns} 和TS(s)={ts1,…,tsns}分别表示评论与其对应的时间,ns是商店的评论数量,tsi是评论ri的评论时间,tsi≤tsj当1≤i (4) f1(In)=|{rj:tsj∈In}| (5) (6) 检测虚假评论的思想如下:给定两个时间序列的商店,我们在两个序列中找出评分及评论数量相关的异常段.具体步骤如下所示. 第1步.首先,在每个维度上,我们采用贝叶斯变化点检测算法[15],使用时间序列拟合曲线. 第2步.将简单的模板匹配算法应用于拟合曲线以检测突发模式.令C={c1,c2}表示时间序列二维的拟合曲线,并使用类似函数的模板来表示值的突然v={v1,…,v5},如果拟合曲线上的段c={c1,c2,…,cn}∈C与模板函数匹配,从而发现曲线上的异常段. 第3步.滑动窗口在时间序列的所有维度中找出对应于联合突发的时间序列段.可以通过c滑动窗口来获得所有段,落入窗口中的所有段定义为b={ci1,…,cin},并求在两个序列v、b之间进行匹配.其中两个序列之间的匹配是根据一个序列中的点与另一个序列匹配,通过两个点之间的“匹配”,两个点的绝对值之的差小阈值ε,L(i,j)记录子序列之间的匹配数量匹配公式如(7) (7) 3.2.2 异常检测算法 前文进行了多维时间序列相关异常模式检测构建,如算法2所示. Algorithm2.Correlated Abnormal Patterns Detection in Multidimensional Time Series 1.Input:Multidimensional-curvesC, 2.window sizeΔt,time spanI. 3.Output:Periods when correlatea nomalies appear, 4.Detected time of spam activities 5.Initialize time setS0={I},scaleη=0 6.n=length ofC,w=time frame length 7.S=φ//set of periods tor return 8.forb=1→n-w+1 do 9.S=S∪{[b,b+w-1]} if 10. |{x∈Li:i=1,2,x∈[b,b+w-1]}==2| 11.End for 12.WhileΔtnot small enough do η=η+1,St=φ. 13. ForI∈Sη-1 do Fit a curveF(I,Δt) 14.Sη=Sη∪C 15. End for 16.End while 17.ReturnSη 特征选择是从原有的特征集中选出贡献率较大的特征子集.任亚峰等人使用遗传算法对特征进行选择,但是该算法存在缺点:有许多参数,如交叉率和变异率,并且这些参数的选择严重影响解的品质,而目前这些参数的选择大部分是依靠经验,因此本文提出借助于信息增益进行选择,最后利用似然比检验使用的逻辑回归模型是否有效. 3.3.1 变量选取标准-信息增益 信息增益(IG,Information Gain)是非常有效的特征选择方法.在信息增益中,重要性的衡量标准就是看特征可以为分类系统带来多少信息,带来的信息越多,该特征越重要.其计算虚假评论如公式(8)、公式(9)所示. (8) G(t)=entropy(D)-entropy(c|t) (9) 3.3.2 评论文本特征选择 影响虚假评论的特征有很多,本文提出最可能影响的11个特征如下所示,并用信息增益计算影响度较大的特征. F1:文本复制.评论者为了尽快完成评论,经常复制一些雷同的文本以不同身份评论,从而达到虚假攻击. F2:情感度.情感度是指评论者对评论的情感极性度.虚假评论者比较片面,而正常用户相对客观. F3:文本长度.虚假评论者相比正常评论者相对较长. F4:用户信誉.用户发表的评论被其他用户采纳的数量越多,则信誉越高越真实. F5:追评时间.正常客户一般再使用一段时间后进行追评,而虚假评论者几乎跟初评同时完成. F6:专业术语.正常用户在进行评论时比较白化,而虚假评论者使用词汇较专业. F7:否定词.正常用户在评论部分性能或许使用否定词,而虚假评论者几乎不用. F8:一致性.文本评论的情感极性与给出评分的相似度,相似性越低越可能是虚假评论,是检测虚假评论重要特征. F9:相关度.相关度是指评论内容与商品属性的关联程度,有些虚假评论者为了快速评论便复制一些与商品不相关的内容. F10:图片.普通用户一般很少上传照片,但是虚假评论者通常上传照片提高商品信誉. F11:转折词.虚假评论者的情感极性高度一致,很少使用转折词.但普通用户或许会对部分性能表示不满. 其中sw(re)表示评论中情感词集合,tw(re)表示评论中所有词语集合,l(r),f(r)分别为始末评论时间.特征F2,F5,F6计算如公式(10)-公式(12)所示. (10) (11) (12) 虚假评论的影响因素有很多,但是哪些因素对检测虚假评论更加明显,这其实就是回归问题.自变量X是影响因素,由于自变量是离散的,无法直接用线性回归方法解决,因此最佳的解决方法是Logistic回归模型.Logistic分析原理就是利用一组数据拟合一个Logistic回归模型,然后借助于这个模型揭示总体中若干自变量与一个因变量取某个值的概率之间的关系.概率P与自变量的关系如公式(13)、公式(14)所示. Y′=θ0+θ1X1+θ2X2+…+θmXm (13) (14) 在上述公式中自变量为X1…Xn,θ0常数项,θ1…θn等为偏回归系数,P表示在n个自变量共同作用下发生的概率.因变量Y是二分类的值,所以取值为 现在把研究Y与X关系转换成分析当Y取某个值时的概率P与X的关系.当Y是0时为虚假评论,X为虚假评论的影响因素.这样研究虚假评论的攻击率P与X的关系就简单了很多. 本文的数据集主要来自Xie等[16]12402条评论,其中包含6492条真实评论,5910条虚假评论.其中在一段时间内突然激增,如表3所示. 表3 数据分析表Table 3 Data analysis table 为了选取对逻辑回归模型影响较显著的自变量,我们利用前文给出的公式(8)(9)计算每个自变量的信息增益,其结果如表4所示. 表4 候选特征及其信息增益值表Table 4 Candidate features and information gains 为了检验模型中所有自变量整体是否与所有研究事件的信息增益存在线性关系,本文用似然比检验.其原理是通过分析模型中变量变化对似然比的影响,依次判断增加或者删除某个变量是否对因变量有显著影响,如公式(15)所示. G=-2(ln(Lp)-ln(Lk)) (15) 在公式(15)中:ln(Lp)表示不包含检验变量时模型的对数似然值,ln(Lk)表示包含.当样本量较大时,G近似服从自由度为待检验因素个数的χ2分布.当G大于临界值时,接受H1,拒绝无效假设,表示该影响因素对Logistic模型有意义.本文计算7个特征的似然比,在p值等于0.05条件下,计算结果如表5所示. 表5 似然比测试表Table 5 Likelihood ratio text 本文首先借助于情感分析利用情感强度、特征权重对虚假文本评论的影响计算出每条评论的近似分数,然后再与评论者给出与其相对应的评分进行比较,结果如图1所示,实验结果发现在所有给出的评论中前30天是趋向于正相关的,评分与评价基本一致,在(2010.5.15-2010.7.15)逐渐趋向于负相关,两者不再一致,说明该时间段内出现大量虚假评论,原因是商店为了提高效率,大量水军复制与内容不符的评论文本,导致与实际评分出现误差,但整体评分趋向于上升趋势,因为商家雇佣的好评水军数量大于恶意的诋毁者.通过实验说明评分与评价一致性表现出了不错的性能. 图1 评论-评分一致性对比图Fig.1 Comment-rating consistency comparison图2 评论和评分的时间序图Fig.2 Reviews and scoring time 同时,我们预先故意选取数据了(2010.5.15-2010.7.15)确定包含大量水军的评论,基于多维时间序列从审查数据中检测到更多的突发细节的时间段.我们设置窗口大小为15天,发现评分与评论数量在(20→30)急剧增加的可疑活动,如图2所示,这与事先选取的实际评论情况相吻合,此结果揭示多维时间序列论识别方法是检测虚假评论的重要性能. 本文利用情感极性、多维时间序列,并通过逻辑回归模型检测虚假评论,并采用十折交叉验证,通过与邵珠峰[17]提出的基于情感特征和用户关系的方法(图3中Structed标记)与Feng[18]提出的基于句法结构的检测算法(图3中CFG标记)对比验证本文方法的有效性.本文采用最为通用3个评判指标来判断虚假检测的优劣:准确率、召回率、F1值.从图3中可以看出融合评分-评价一致性和多维时间序列的虚假评论识别方法取得了较好的结果. 图3 准确率比较图Fig.3 Comparison of accuracy 邵珠峰等人分析虚假评论者和真实评论者在情感极性上存在着差异,通过评论者的情感差异构建特征模型,并结合用户之间的关系构造多边图模型,最后计算出用户评分来识别虚假评论.该方法准确率有所提高,主要因为考虑情感极性差异,融合了评论文本较为重要的8个特征和其权重.但也存在着缺点,通过人工标记数据存在着一定偏差,只考虑初末时间.F1指数对比与召回率对比如图4、图5所示. 图4 F1指数比较图Fig.4 F1_Measure comparison Feng等人提出的于句法结构的检测算法分析了浅层次句法模式的缺点,主要研究深层次的句法模式.他们在先前研究者的工作基础上加入特殊句法模式构建语义树并提取语义特征,此方法的准确率达到91.2%.该方法优越于邵珠峰的主要原因是,对于不同规则的书写模式可以利用语义树挖掘深层的句法关系,构建专门的语义树,但邵珠峰提出的方法受到限制. 本文相比较邵珠峰和Feng的准确率有所提高,但F1值比Feng的稍差一点.本文,首先,借助自然语言处理通过情感技术分析评论的情感极性并判断与其评分的一致性;其次,建立时间序列进行评论识别;最后,通过抽取7个特征并使用逻辑回归进行虚假检测.但我们发现准去率提高的同时F1值有所下降,可能原因在于在加入特征后一些评论不存在否定词. 随着电子商务的蓬勃发展,研究者们对虚假评论检测作出了不懈的努力.基于情感极性和多维时间序列,首先根据在线商品评论的特点,提出通过分析评论的情感极性,判断与其评分的一致性算法;其次,考虑时间对评分及评论数量的影响,构建基于多维时间序列的虚假评论识别方法;最后,通过抽取不同特征,建立逻辑回归模型,进行不真实的或虚假的评论检测,通过对比试验证实了本文算法取得了较好的效果.但该方法还需有待改进,第一,冷启动问题,没有动态的考虑评论情况,在没有评论或者仅仅少数评论的前提下该怎样获取评论信息;第二,评论文本中还隐藏其他重要特征可以提高精度.未来工作主要集中在这两方面.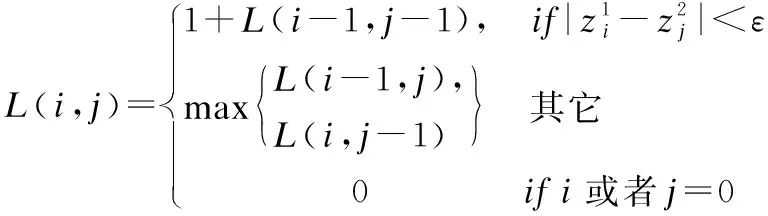
3.3 虚假评论特征选择
3.4 逻辑回归模型

4 实验分析
4.1 数据集
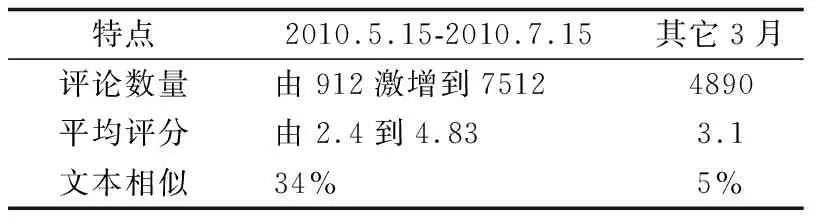
4.2 自变量计算-信息增益

4.3 方法与模型检测


4.4 实验分析
5 结束语
