点云无损压缩并行算法研究
2018-10-26刘振亮孙煜东
刘振亮,孙煜东,闫 华
(太原理工大学 信息化管理与建设中心,太原 030024)
1 引 言
近年来,随着激光雷达(LiDAR,Light Detection And Ranging)扫描技术的不断进步,扫描精度逐渐提高,扫描获得的数据以指数级增长,如果直接进行数据传输或存储,不仅成本高、实施难度大,而且很难实现,需要进行数据压缩等预处理再进行传输.
常见的点云压缩算法一般分为两类:第一类是基于几何学压缩.首先对点云数据预处理,获得网格模型,再对其进行压缩.典型算法有三角网格剖分法[1]、顶点聚类算法[2]、边折叠法、小波分解法等.该类方法需要在网络拓扑的基础上根据采样点对网格进行重构,进一步简化.简化效果好,但是需要构造和维护庞大的拓扑信息,计算量大,效率较低.第二类是基于点云数据本身的压缩,直接对点云数据进行处理,典型算法有比例压缩法、基于八叉树的压缩算法[3]、基于特征点的压缩算法[4]和基于预测模式的压缩算法[5].这类方法直接对点云数据进行简化,操作简单,尤其是以LASzip[6]、LASCompression[7]等为代表的预测模式算法应用最为广泛.本文选取LASzip无损压缩作为研究对象.
然而,单纯依靠压缩算法远远不能实现数据实时处理的目标.随着多核并行技术的不断发展,仅仅依赖单核对数据进行压缩,并不能很好的解决压缩速度慢的问题,并行处理技术是提高LASzip压缩算法压缩、解压缩速度的有效方法,目前高性能计算有两大趋势,并行计算集群和CPU处理器与GPU显卡的异构混合计算.在GPU加速方面[8],利用GPU计算能力,将训练数据传到GPU端进行计算提高训练速度.卢敏等人[9]以地形因子计算为例,分析并测试了基于共享内存模型的CPU多核并行模式与基于流处理器模型的GPU众核并行模式的计算性能,在此基础上实现了负载均衡的设备间任务划分,进行CPU与GPU异构混合的并行技术改良研究.另一方面,多核CPU加速也是一个较热的并行研究领域,宋刚等人[10]提出一种基于共享存储的并行压缩策略.通过Beowulf集群测试,并行化的gzip程序取得了极大的性能提升,压缩速度显著提升.
本文对传统的LASzip压缩算法进行介绍,分析其耗时部分,结合该算法特点,比较不同核数和不同数据量分块单元的串并行算法执行时间及压缩比,通过OpenMP技术优化LASzip压缩算法压缩、解压缩过程,实现了多核CPU并行加速.并将该算法在台式机四核机器上进行实验.实验发现,OMP-LASzip并行压缩算法通过损失少量压缩比,换取数据压缩、解压缩速度的大幅提高,充分发挥了多核处理器的性能,在实时性传输和节省存储空间上有很大的应用空间.
2 背景知识
2.1 LAS格式
LAS文本格式从2003年发布至今,经过数次修订,目前已更新到LAS1.4版1.

表1 LAS1.4版本格式结构Table 1 Structure and format of the LAS1.4
2.2 LASzip算法
LASzip算法是一种针对特定点云格式las开发的无损压缩算法,采用预测模式进行编码,仅保存预测错误的数据项.LASzip对点数据记录区按组成项目分块压缩,每一项都有独立的版本号和压缩模型,方便后续las数据类型的扩展,压缩方案也各不相同.LASzip算法以50,000个点为单位编码,由于压缩后每块大小不同,压缩器在文件末尾存储一个块列表明确每个数据块的起始字节.当开始一个新块时,LASzip压缩器存储第一个点作为原始字节,然后初始化熵编码器,并将该点作为预测模式的初始值.接下来的点一项项由下面的压缩模式顺序压缩.LASzip串行压缩算法执行步骤描述如下:
Step1.对于las文件中的公共头文件区和变长记录区(包括扩展变长记录区)的内容并不进行压缩,仅拷贝到压缩后的输出文件laz中.并将点类型的值增加128,以防las读取器直接读取laz文件.
Step2.点云数据分块编码.
Step3.POINT10数据项压缩
1)压缩器编码6位掩码用以指定强度、返回值、分类值、扫描角等级、用户信息、点资源ID等属性值与之前处理过的点属性相比是否改变;
2)压缩器对预测错误(点属性发生改变)的值进行编码.
Step4.GPSTIME10数据项压缩
将双精度浮点数GPSTIME10视为有符号64比特整型数,存储当前数据之前连续四个压缩完成的GPSTIME10值取delta平均值.
Step5.RGB12数据项压缩
1)las点云数据用16位无符号整型数记录R,G,B通道.用256乘以8位颜色值,此时较低的8位为0;
2)LASzip对每个颜色通道的高位和低位分别压缩:首先熵编码6位指定哪些字节已经作为符号转变.对于所有字节都发生变化的,与前一个压缩完成的数据项差分取模256进行熵编码.
Step6.WAVEPACKET13数据项压缩
LASzip简单的熵编码波形描述符索引,如果该数据点没有波形信息和索引,则记为一个字节的无符号数0,否则表示可变长记录区已经记录波形信息.
Step7.BYTE数据项压缩
一个las文件可能存在“额外的字节”,这是因为las头文件定义的字节数大于各自的点类型字节数.此时对每一个BYTE数据项进行上下文熵编码作为前一项BYTE数据项模256的差分.
2.3 OpenMP介绍
随着多核处理器性能不断提升,为了提高多核处理器利用率,决定引入OpenMP并行设计技术,设计人员只需研究系统瓶颈,重构算法即可提升算法性能.OpenMP是高效的多核编程处理方案,以线程为基础,通过编译指导语句实现并行,在CPU核数扩展性、方便性和可移植性上都有很大的优势.使得串行应用程序在多核共享存储系统上,并行加速效率获得大幅提升.
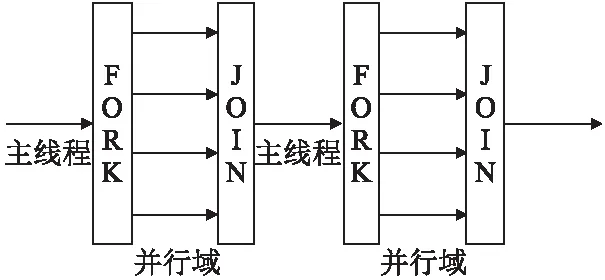
图1 Fork-Join执行模式流程图Fig.1 Executive flow of Fork-Join
OpenMP技术根据fork-join模式,对可并行的部分利用OpenMP子句和命令创建多个子线程实现并行.在并行域阶段,主线程和子线程同时工作;并行结束后,子线程随之结束或挂起,程序返回主线程继续执行,并行算法中fork-join流程如图1所示.
3 基于OpenMP的点云压缩算法OMP-LASzip多核并行设计及实现
3.1 多核并行压缩模型
基于OpenMP的多核并行技术为点云数据的并行压缩处理提供了很好的平台,为了改变原始串行算法,使其更好发挥作用,根据多核环境并行特性,借助Intel软件工具VTune[12]对算法性能进行分析,建立基于OpenMP技术和LASzip算法的多核并行设计模型OMP-LASzip.VTune是Intel一个比较强大的性能分析软件,主要包括三个小工具:
1)Performance Analyzer:性能分析,找到软件性能比较热的部分,即性能瓶颈的关键点,帮助收集数据发现问题.
2)Intel Threading Checker:用于查找线程错误,检测资源竞争、线程死锁等问题.程序在并行化后,可以通过Threading Checker检测是否存在多线程相关的错误.
3)Intel Threading Profiler:线程性能检测工具,多线程化可能存在负载不平衡,同步开销过大等线程相关的性能问题.
该工具可以帮助监测任一线程任何时刻的运行状态.
具体建立并行压缩模型步骤如下:
Step1.使用Intel软件工具VTune性能分析LASzip串行算法,发现热点代码;
Step2.分析串行算法耗时部分及热点代码的并行化可行性;
Step3.并行建模,实现并行LASzip算法;
Step4.使用Intel Threading Checker 和 Intel Threading Profiler对OMP-LASzip多核并行设计模型进行调试,优化代码;
Step5.检测算法执行性能,包括是否达到负载平衡,加速比、多核利用率、线程运行效率等情况;
Step6.使用Intel Threading Checker进一步检查算法性能和潜在漏洞;
Step7.若存在漏洞,则返回Step 3优化算法.
在算法并行过程中,首先要找到程序耗时部分,因为这部分代码一旦能够实现并行处理,将大幅度提高算法执行效率.当然,除了热点代码,执行时间较长或执行频率较高的算法实现并行也对提高系统运行效率、提高加速比起到促进作用.
3.2 OMP-LASzip算法基本原理
由2.2节LASzip串行算法步骤可知串行算法基本流程.大场景点云数据在压缩过程中按数据项不同分块压缩,压缩方式也各不相同.为了引入OpenMP技术,现从算法实现流程进行分析.考虑到压缩过程中连续数据之间虽然有一定程度的相关性,但是由于数据分块压缩时以50,000个数据点为一个单元,且压缩过程中不涉及数据竞争问题,因此可以直接并行化.通过将数据分为n组,同时分配样本数据给n个线程,每组数据使用一个线程来实现LASzip算法的并行压缩.采用OpenMP相关语句和命令来给并行压缩的数据分配多个线程.
本文利用OpenMP多核并行技术对LASzip算法进行并行化研究.分析LASzip串行程序中耗时部分,同时分析耗时部分的可并行性,通过OpenMP添加并行语句对原有串行程序进行并行化,提出基于OpenMP的点云无损并行压缩算法OMP-LASzip.
3.3 OMP-LASzip算法实现
LASzip算法只对点数据记录区进行压缩,对公共头文件区、变长记录区和扩展变长记录区并不进行压缩,仅拷贝到输出文件中,因此计划LASzip算法执行分两部分进行:

图2 OMP-LASzip算法流程图Fig.2 Flow of OMP-LASzip algorithm
1)读入点云文件.仅保留点数据记录区内容,将不需要压缩的其他数据项直接写入输出文件;
2)压缩点云数据.为了减少压缩算法运行时间,提高点云数据处理效率,需要对压缩过程实现OpenMP并行化.串行传播的过程是点云数据分块后顺序压缩的过程,使用并行语句后,数据分组并行压缩提高压缩效率.调用lasmerge函数对数据以n个点为单位进行分块,分配给多个线程并行压缩.
采用一个读线程,一个写线程,多个压缩线同时工作.其中读线程负责读数据,循环检测缓冲区,将空缓冲区填满;写线程负责写数据,将压缩完的数据按照读的顺序写到输出文件.为了保证读写顺序一致,即压缩文件按顺序写入输出文件,引入读写顺序队列机制.当读线程检测到一个缓冲区为空,就从原文件中读一块数据加入到缓冲区中,同时将该缓冲区的序号加入到读写顺序队列中,这样,写线程就必须按着读写顺序队列里面存储的缓冲区序号写输出文件,由于缓冲区和输出队列一一对应,这个序号也就是输出队列的序号,写线程就可以从这个序号对应的输出队列中取得数据,写入输出文件,从而保证写文件时保持原文件的顺序.同时保证每个文件(除了最后一个)数据量近似相等,多核运行时负载均衡.下图为对点数据记录区OMP-LASzip算法数据压缩部分详细流程图(见图3):

图3 OMP-LASzip算法数据压缩部分详细流程图Fig.3 Flow of partial details of OMP-LASzip algorithm
解压过程原理相同,调用lasmerge函数对带解压文件以n个点为单位分块,运用OpenMP技术,对数据块并行解压缩,以下是并行顺序压缩的伪代码:
#pragma omp parallel for
//OpenMP的for循环并行语句
for(i=0;i<(totalnum/n);i++)
//totalnum为点云总数,n为每块点云包含的数量,i为点云块数
{
OMP-LASzipPOINT( ) ;//POINT10数据项压缩
OMP-LASzipGPSTIME();//GPSTIME10数据项压缩
OMP-LASzipRGB ( ) ;//RGB12数据项压缩
OMP-LASzipWAVEPACKET( ) ;//WAVEPACKET13数据项压缩
OMP-LASzipBYTE( ) ;//BYTE数据项压缩
}
在并行设计模型和OMP-LASzip算法实现之后,考虑到如果串行编程存在错误,势必会影响到并行算法的实现,因此还需要对结果进行调试与优化,以保证计算性能达到最优效果.采用多线程并行完成工作虽然可以提高系统运行效率,但是也提高了程序设计错误的风险.因此,在算法并行化完成后,对处理结果进行进一步的调试与优化十分必要.
4 实验结果与分析
本文的实验数据来源文献2,选取5个数据量大于2G的点云数据集,数据分别按5,000,000、7,500,000、10,000,000、12,500,000、15,000,000个点为单位分块压缩.实验平台为台式机Intel(R) Core i7-4770四核八线程处理器,主频3.50GHz.开发环境是在Windows 7 Professional X64位系统上安装Microsoft Visual Studio 2013,OpenMP直接在Microsoft Visual Studio 2013中配置.由于算法引入读写线程,则并行压缩线程数最多为6.为保证LASzip算法在串行设计时的正确性,确保并行实现的顺利进行,实验计划先对OMP-LASzip算法串行程序进行测试,并将实验数据在并行环境中进行实验,表2为OMP-LASzip算法压缩结果性能比较,定义压缩比:
(1)
其中s′为压缩后文件大小,s为原始文件大小.统计10次取平均值得到并行多核LASzip压缩算法相对串行算法的压缩比误差:
e=|kn-k|
(2)
其中,kn表示以n个点为单位的点云数据压缩比,k表示原始点云文件压缩比.

表2 OMP-LASzip算法压缩结果性能比较Table 2 Comparison of the compress result of OMP-LASzip
实验发现,数据分块后压缩较原串行压缩,压缩比有所下降,这是因为数据分块后每个数据块的起始数据无法使用预测模式进行编码, 因此造成压缩比降低, 但从结果可知误差维持在1%以内, 验证了并行算法的可行性.实际上,并行压缩就是在损失少量压缩比的前提下换取压缩速度的提高.以CA_042_NE_PtCl.las实验结果为例,以下为多线程点云数据并行分块压缩的时间.
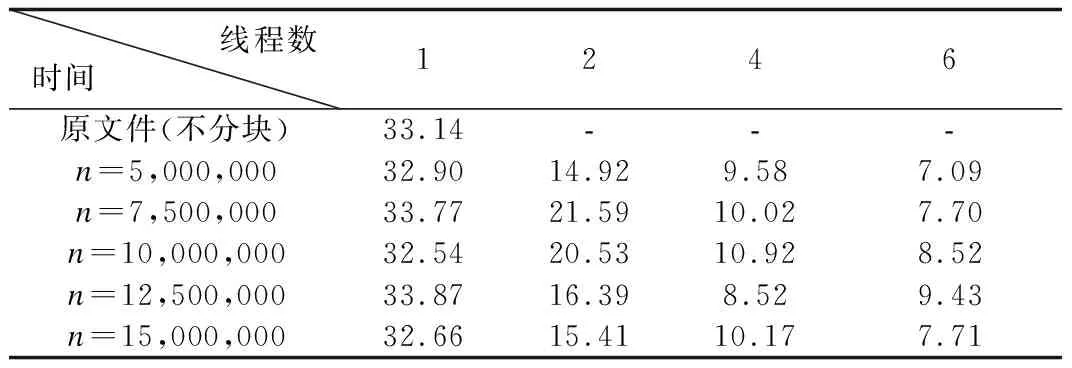
表3 多线程下点云数据并行分块压缩时间(单位:s)Table 3 Time of the compression of OMP-LASzip in multi-thread
图4 多线程点云数据并行分块压缩时间示意图Fig.4 Diagram of compress time in multi-thread of point cloud data
加速比是衡量并行程序的指标,即用最优执行时间除以并行执行时间所得到的比值,加速比可以描述程序并行后获得的性能收益,公式如下:
(3)
其中,s(p)为加速比,t1为最优串行算法执行时间,ti为线程数为i时的并行算法执行时间.从表4可知当n=5,000,000时,线程数为2时,理想加速比为2,但实验发现此时加速比达到2.21,出现了“超线性加速比现象”.理论上讲,当在p个处理器上运行的并行程序,其理想的运行速度应为串行程序运行速度的p倍,但是由于通信延迟,负载不均衡等原因,很难达到理想加速比.然而实验显示,线程数为2时,加速比达到2.21,超过理想加速比2,这是因为并行程序完成了较少的工作,即一般情况下,并行执行时所要访问的数据都驻留在每个处理器的cache中,而顺序执行时必须访问存储器系统中运行较慢的部分,因此由于并行程序所完成的工作量比串行程序的少,从而出现了超线性加速比现象.
从表4可以看出,当分块点数量恒定时,加速比与线程数呈正相关.实验发现,当线程数为6时与线程数为4相比加速比提高并不理想,这是由于系统硬件条件的限制,即使所有线程都分配到任务,系统CPU接近100%,压缩程序的执行效率并不会有很大提升,因为线程的增加必然会提高系统开销,影响程序性能.
同时实验可以看到当线程数恒定时, 随着单位块内点云数量的增加, 加速比并没有相应增加,而是出现了小幅波动甚至下降的结果,这是因为随着单位点云数量增多,数据量增
大,点云块数量减少,容易造成负载不均衡反而降低算法运行效率.由表4可以看出,当单位点云数量n=5,000,000时随着线程数增加,加速比随之升高,与其他单位点云数量相比性能提升最优.同时,当线程数为4时(考虑到读写线程,实际运

表4 多线程加速比实验结果Table 4 Data chart of different thread of speed-up ratio
行线程数为6),加速比达到3以上,最高达到3.98,优化效果显著;当线程数增加到6时,加速比较线程数为4时略有提高,此时8线程全部运行,CPU利用率过高,不利于系统正常运行,因此决定采用1个读线程,1个写线程,4个压缩线程共同操作,保证各压缩线程负载平衡,达到最优运行效果.
5 结 论
在对大量旅游景点数据进行三维重建过程中,对采集到的点云数据进行实时处理、压缩、传输,对于提高建模效率、保证数据真实性、完整性具有重要意义.本文针对LASzip算法,分析其耗时部分,引入OpenMP技术,实现点云数据分块并行压缩OMP-LASzip算法,提高点云数据处理效率.实验结果表明,与原串行算法相比,并行算法在损失少量压缩率的情况下,压缩速度显著提升,保持负载均衡,同时随着核数增加,加速比也在增加.实验结果显示,当单位点云数量n=5,000,000,压缩线程为4时运行效果最佳,验证了该算法的可行性、有效性和可扩展性,解决了现有点云压缩方法处理效率低、实时性差的问题.
