利用数据冗余性的高速缓存压缩校验技术
2018-10-26张伟功
田 芳,王 晶,张伟功
1(首都师范大学 信息工程学院,北京 100048)2(北京成像技术高精尖创新中心,北京 100048)3(首都师范大学 电子系统可靠性技术北京市重点实验室,北京 100048)
1 引 言
空间环境中存在大量的高能带电粒子,高速缓存作为占据芯片面积50%以上的关键部件,极易发生单粒子翻转故障,导致存储数据发生多位的错误.与此同时,"功耗墙"问题使整个计算机行业面临巨大的能源危机.降低电压是减少能耗最有效的手段之一,然而电压的降低却导致故障率的指数级增加,当供电电压下降到正常电压的50%时能效性可以提高10倍,但1位错误率从1/108增加到10%,远高于系统可容忍的0.1%,且会引发0.01~0.001%的3位和4位故障[1].
电路级容错是较为简单且广泛使用的方案,然而底层电路的全加固会导致面积和能耗开销成倍增加.体系结构级方案,如容错校验码ECC,能够根据系统可靠性的需求,结合应用程序的特性,更加灵活的实现性能与功耗的权衡,广泛应用在高速缓存中.然而ECC的容错开销会随着故障的复杂度和保护的信息位位数增加而线性增长.对于经典的BCH码,对63位数据实现纠4检5的保护时,所需校验位为码长的38.1%;而当纠错能力增加到10位时,校验位将增加到71.4%,此外能耗、面积等开销也会随着纠错算法的复杂度增加同比上升.针对校验算法的高开销问题,本文提出一种基于数据冗余特征的高速缓存的压缩校验方案.本文主要贡献如下:
1) 针对在民用智能设备、航天、国防等领域中广泛应用的经典BCH纠错算法的空间开销和时间开销进行分析,量化了信息位、容错能力与开销之间的关系.
2) 提出基于数据存储特征的压缩校验算法,针对全零型、重复性和数据的相似性等不同的冗余模式选择压缩算法,提升单一压缩算法的数据压缩率.
3) 设计了支持多标签的高速缓存结构,和基于数据模式校验的高速缓存访问流程,动态权衡容错高速缓存空间开销与压缩算法时间开销,提高了存储空间利用率.
2 相关工作
目前国内外主流的处理器高速缓存大多采用纠一检二的海明码或EDAC码,算法简单、开销低,但是纠错能力有限.为了在容错能力和开销之间实现权衡,学术界提出大量的编码算法,表1总结了典型的Cache校验算法.
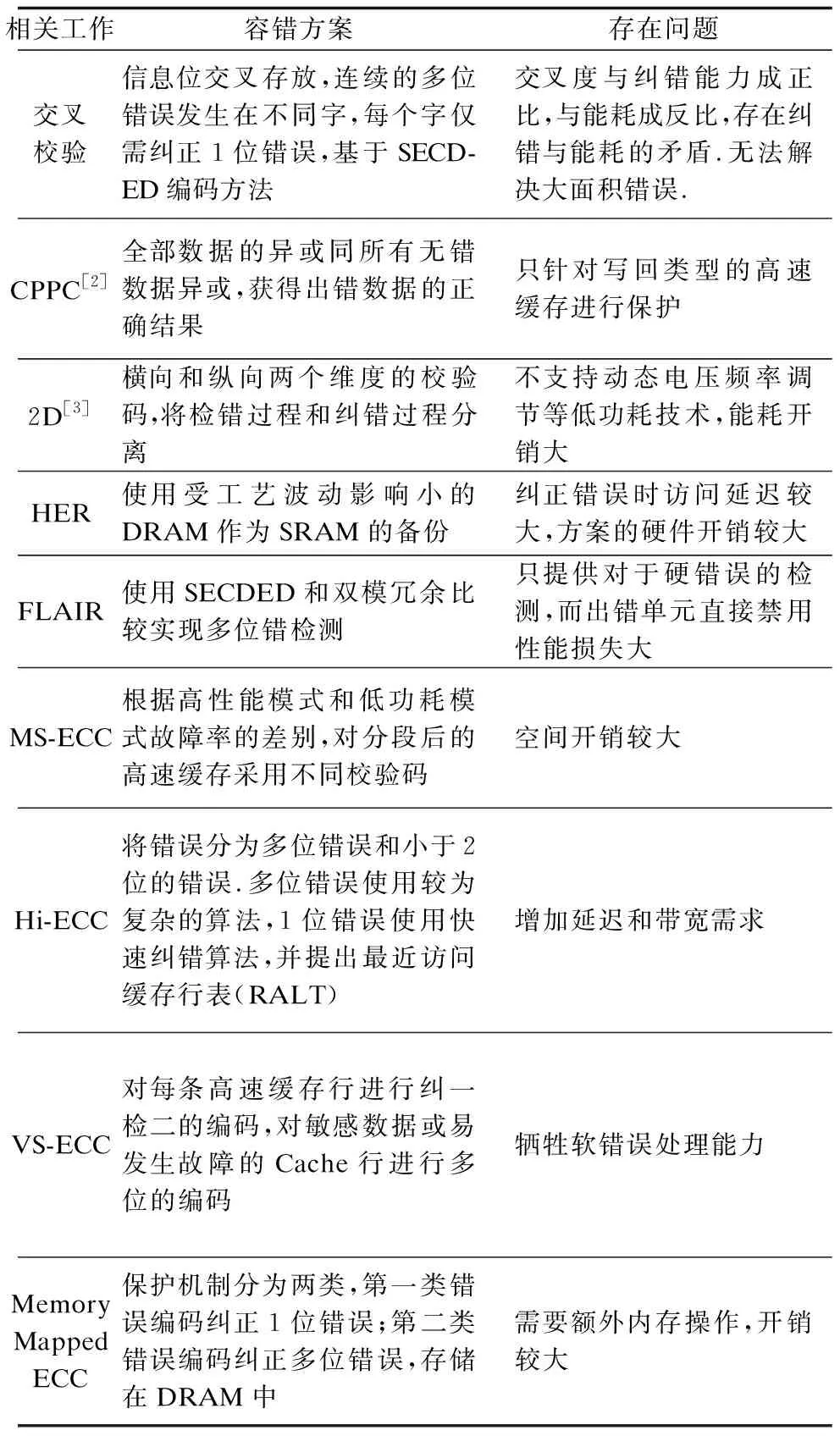
表1 典型Cache校验算法分析Table 1 Analysis of the typical algorithm of Cache
基于空间的交叉校验、CPPC和2D算法只能处理特定模式的错误,基于备份的HER和FLAIR方法空间开销成倍增加.Intel提出的MS-ECC方案根据高性能模式和低功耗模式故障率的差别,对分段后的高速缓存采用不同校验码,高性能模式采用纠一检二检验算法,低功耗模式采用正交拉丁方编码.译码时,将数据行与对应的ECC行放在译码器中,判断是否有错误位.相比于以往方案MS-ECC能够降低容错开销,但仍需消耗约50%的缓存空间[4].Hi-ECC方案是将错误分为多位错误和小于2位的错误.多位错误使用较为复杂,延迟较长的算法,1位错误使用快速纠错算法,方案将已读取的数据所在的高速缓存行的地址存储在最近访问缓存行表(RALT)中,每次读取数据时,先从RALT中遍历是否有该数据的地址,如果有,直接将数据发送到CPU中,不需要再次检错.如果读取到不同缓存行的数据,则将此行的地址存储在RALT中.这种方式减少了读取数据的检错次数,减低了能耗.然而,Hi-ECC在更新ECC位时所需要的读写修改操作代价大,导致读操作的延迟和带宽需求增加[5].可变长度纠错码(VS-ECC)方案是对每一条高速缓存行进行纠一检二的编码,对敏感数据或易发生故障的Cache行则进行多位的编码.此方案提出3种模式,分别是固定可变长度纠错码,关闭可变长度纠错码,可变长度纠错码.固定可变长度纠错码是对确定的几行进行校验;关闭可变长度纠错码,是指当某一高速缓存行产生的错误个数大于2时,关闭此行,避免错误;可变长度纠错码,具有较高的精确率,需要先判断高速缓存行产生的错误个数,之后选择对应的纠检码.然而VS-ECC是对硬故障采用校验码纠正,牺牲了软错误的处理能力[6].Doe et.al提出的方案是将复杂编码存储在DRAM中.此方案将保护机制分为两类,第一类错误编码是低延迟,低功耗编码,它可以纠正1位错误;第二类错误编码容错能力较高,可以纠正多位错误,但是开销较大,性能平均下降1.3%,访问末级缓存次数平均增加了36%,延迟几乎增加了6%,而且需要额外的内存操作,第二类错误读、写操作分别增加整体DRAM通信的0.1%和1.4%[7].
由于应用程序数据局部性,高速缓存中的数据存在大量的冗余信息,比如大量的数组通常初始化为全0,多媒体等应用中某个区域的像素值数据值完全相同,或当连续地址访问时地址之间的数值差别很小而基址较大,或者是针对计数器等情况分配的存储空间远大于实际数值占用空间[13,14].这些冗余数据为压缩带来了可能,通过压缩能够消除高速缓存中冗余信息缩短信息位,从而降低容错开销.典型的Cache压缩算法包括:ZCA压缩算法针对的存储数据值大多为0,或NULL[8],对其他数据特征无法进行高效压缩;FVC压缩算法[9]可将存储的大量重复数据进行压缩[10],以此减少源数据所占的空间,但无法对小范围浮动值等冗余信息进行有效压缩; FPC压缩算法[11]试图把几种可压缩的模式进行压缩,比如4位符号扩展,一个字节符号扩展等[12],但延迟开销较大;B△I压缩算法[13]压缩数据值差别较小的缓存行,对全0值和重复值冗余模式的开销较大.
针对上述问题,本文提出一种基于数据存储特征的纠检错策略.该方案通过分析数据特征,动态选择压缩算法,采用纠错算法对高速缓存进行容错.
3 研究动机
针对现有容错方案的高开销问题,本文从校验算法的时间开销,空间开销两个方面分析,同时分析了程序数据的冗余度,为低开销的压缩校验奠定了基础.
3.1 校验算法开销分析
目前常用的EDAC码有海明码、奇偶校验码、BCH码、循环冗余校验码等.随着电压的降低、晶体管尺寸的减少,多位错误发生的概率增加,校验码产生的复杂度与开销越来越大.因此,对经典的BCH码进行开销分析.BCH码是Bose、Chaudhurl和Hocquenghem于1959年发现的一种循环码[14],是一类纠错效果不错的线性分组码.由于BCH纠错算法可对任意纠错强度进行配置,也可纠正多位随机错误,尤其在短和中等码长下,性能很接近于理论值,并且构造方便,编码简单,BCH算法成为当前NAND flash主控制器中主流的纠错算法[15].但是,BCH纠错算法时间开销与空间开销很大.
BCH纠错算法的空间开销和延迟开销都由源数据信息位的长度决定,校验位数目是由信息位的长度k和纠错能力t共同决定;算法的时间复杂度则随着编码的长度的增加而增加.
BCH码的时间复杂度通常可以表示为信息位的函数,纠错时间如公式(1),其中n为码长,由图1码长和时间的曲线可知,随着编码长度的增加,时间复杂度同比增加.
T=n×log2n
(1)
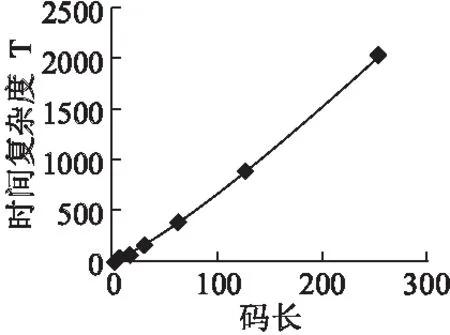
图1 时间复杂度Fig.1 Time complexity
空间开销方面,对任何正整数m和t,一定存在一个二进制BCH码,它以α,α3,…,α2t-1为根,其码长n(n=2m-1)或是2m-1的因子,能纠正t个随机错误,校验位数目至多为m*t个,n和m之间的关系如公式2,(n:码长,k:信息位,m:有限域的次数 GF(2m))[16].
n=2m-1
(2)
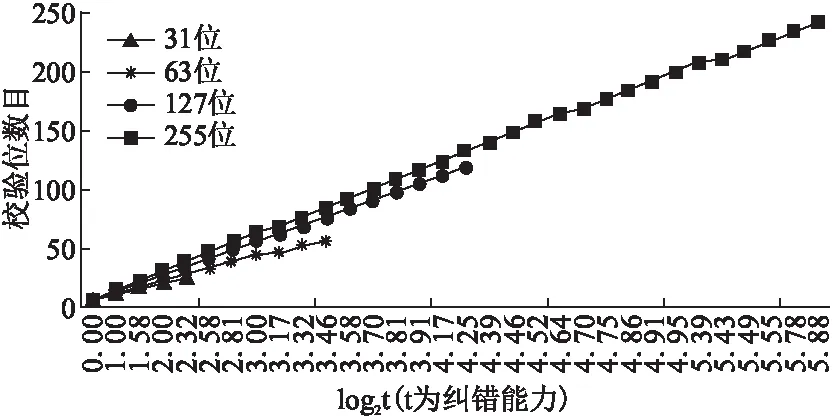
图2 BCH算法不同纠错能力和信息位下的空间开销Fig.2 Different error correcting capability and the space overhead bits of BCH algorithm
图2为BCH算法不同纠错能力和信息位下的空间开销,通过图可知,不同纠错能力,所需要的检验码不同,进而带来的空间开销也不尽相同.例如,当源数据为1MB,码长为63位时,纠错能力为1,校验位数需1572864位,总位数为9961472位,校验位占总位数的15.8%;纠错能力为4,校验位数需6291456位,总位数为14680064位,校验位占总位数的42.9%.
3.2 应用程序数据冗余模式分析
应用程序的数据存在大量的冗余,通过对典型应用的数据分析发现,如图3所示的三种冗余数据模式在应用程序出现最为频繁[12].在应用程序中,0值出现的概率非常大,比如,系统初始化时,局部变量声明会赋值为0或初始化为空指针或false布尔值,因此高速缓存行中会存储大量的0;图像或视频处理程序中,临近像素通常具有相同或相似的颜色,也会使高速缓存存储大量相同的数值;而数组地址数值之间差异小,因此会出现高速缓存中相邻数据之间值相似,偏差较小的情况.
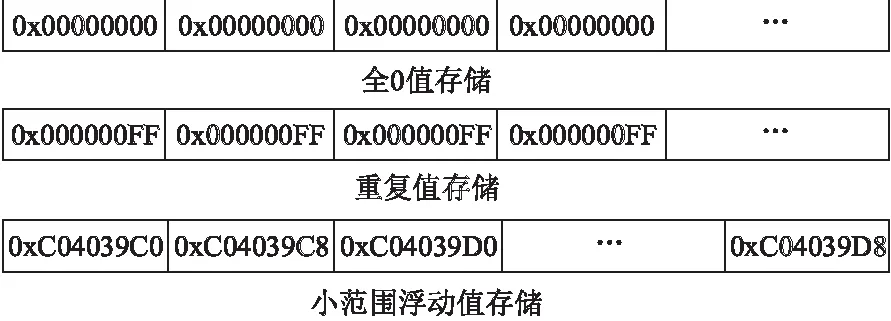
图3 应用程序数据冗余模式Fig.3 Data redundancy model of the application
以64B高速缓存行为例,通过对以上三种冗余模式采用不同压缩算法进行压缩,得到图4的压缩结果,其中全0值压缩后所占空间为原有的1.56%;重复值压缩后占原存储空间的6.25%到12.5%;而由于基值和增值字节数不同,小范围浮动值冗余模式占原有字节数的25%~62.5%.由此可见压缩算法可以有效降低拥有显著冗余模式的源数据信息位长度,能够达到减少校验位长度的从而提高系统的性能的目的.

图4 不同压缩算法信息位位数Fig.4 Bits of information in different compression algorithms
4 容错高速缓存的压缩校验技术设计
通过对BCH纠错算法的分析可知,常见的线性分组码时间和空间的开销都由源数据信息位的长度决定[18].而由于数据局部性和相似性特征,高速缓存中的数据存在着一定冗余信息.因此,本文提出一种基于数据存储特征的纠检错策略:分析数据的存储特征,选择相应的压缩算法.既消除源数据信息位的冗余信息,减少源数据的信息位,又保证数据的正确性,达到减少空间开销和延迟时间,提高容错高速缓存性能的目的.
4.1 压缩算法的选择
现有压缩算法只针对具有某一种数据特征的存储块进行设计,因此,单一压缩算法针对在不同应用程序中其所能达到的压缩率是不同的.在运行基准测试过程中,发现全0值,重复值,小范围浮动值这三类数据特征出现概率较大.为了达到较高压缩率,本文对这三类冗余模式进行压缩,由于高速缓存是简单、快速、有效的存储器件,因此,本文采用的压缩算法均为简单的向量加减操作.
图5为不同压缩方式存储,针对于全0值和重复值这两种冗余模式,本文只需存储一个数值,其中重复值的字节数可能不同,基于数据的对齐存储特性可分为4字节和8字节重复值存储.而对小范围浮动值冗余模式,需要判断基值和差值.由于基值越多,算法越复杂,延迟时间开销越大,压缩率越低,基于性能和开销的折中考虑,方案选用2个基值,一个基值为0值,另一个基值根据具体的高速缓存行进行选取,通过基值与高速缓存行中的数据并行执行向量减操作,得到相应的差值,这样,较大程度地减少源数据的信息位长度,如图6.由于应用程序的数据存在多样性,因而支持多种数据长度,基值可支持2字节、4字节和8字节,而增量值分别为1字节、2字节和4字节,共6种情况.
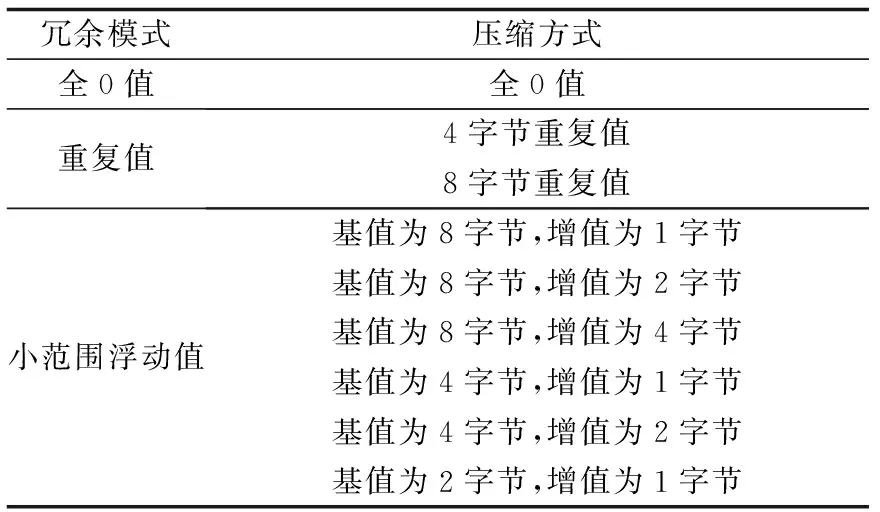
表2 压缩方式Table 2 Compression mode
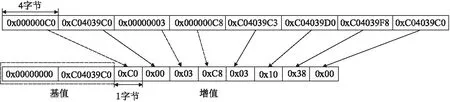
图6 基值为4字节,增值为1字节压缩方式Fig.6 Cache line compressed with B+Δ
表2给出了支持的压缩方式,其中重复值冗余模式根据重复值所占字节数的不同,分为2种;小范围浮动值根据所选基值和对应增值所占字节数的不同,分为6种.
4.2 支持压缩的容错Cache结构设计
与传统未压缩高速缓存相比,压缩高速缓存可以在相同数据容量下存储更多的高速缓存行信息.为了有效利用压缩节省的缓存空间,提出支持多个标记的Cache结构[17],通过额外的标记位获得更多缓存行.由于压缩算法的基值选择为2个,因此Cache的标记位增加一倍.每一标记位均包含额外1位记录是否压缩以及额外3位记录压缩大小,数据数组分成八字节段,根据压缩方式不同,缓存行压缩为1-8个段.图7为标记位存储与数据位存储,以4路组相联为例,每一标记位存储起始段,比如tag1存储S1段.

图7 标记位设计Fig.7 Tag design
在Cache的相联度方面,组相联映射比直接映射、全相联映射命中率高,超标量体系结构微处理器中高速缓存通常使用组相联映射,因此,本文采用组相联模式.然而,组相联模式中的每一路对应着相同的映射关系,造成一定程度上的数据冲突.而高关联度高速缓存在不同路使用不同映射函数,在一定程度上降低数据冲突发生概率[19].因此,本文同时采用高关联度高速缓存进行对比.

图8 组相联映射Fig.8 Set-associative Cache
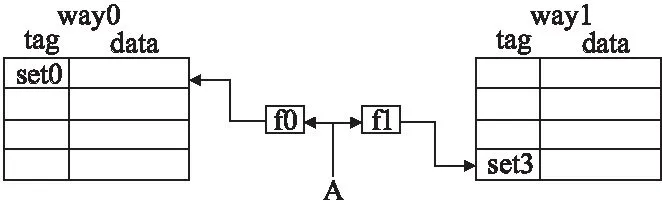
图9 高相联度映射Fig.9 Skewed-associative Cache
以2路组相联为例,图8为组相联模式,当数据块A0,A1,A2同时需要存储在高速缓存中,由于组相连模式所有路使用同一函数映射,数据块均存储在组2中,此时,则需替换一路数据,造成数据冲突.而高关联度进行存储,由于不同路采用不同的哈希函数,在不同路中对应的组号则不同,假设路0中组0已存有数据,而数据块A在路0中映射到组0,发生数据冲突.如果数据A映射到路1,由于映射关系不同,所对应的组号不同,数据冲突发生概率较小,如图9.
4.3 支持压缩的容错Cache访问流程设计
图10为容错高速缓存压缩技术的结构设计.由于校验算法的空间开销和时间开销由源数据信息位的长度决定,而在运行基准测试时发现:全0值、重复值、小范围浮动值这三种冗余模式出现频率较大.压缩这三种冗余信息位,源数据信息位数将会显著降低,进而减少校验位数,降低空间开销和时间开销.
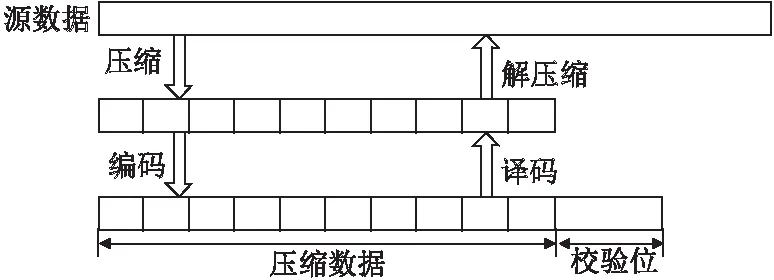
图10 结构设计Fig.10 Architectural design
图11为9种压缩方式和未压缩总位数(信息位与校验位之和).以源数据的信息位长度为64B,BCH码可以纠正4位错误为例,检验位位数为48B.通过分析缓存行中存储的数据特征,选择对应压缩算法,比如高速缓存行数据的冗余模式是基值为8字节,增值为1字节的小范围浮动值,首先判断冗余模式,其次选择基值,由于基值为8字节,因此,缓存行中数据以8字节为单位,与基值进行向量减操作,并对对应的增值进行存储,所得到的压缩数据为16B,是未压缩数据的25%,最后通过对压缩数据进行BCH码编码进行容错,校验位为12B,总位数为由112B降低为28B.

图11 不同压缩方式总位数Fig.11 Total bits of different compression modes
图12为基于数据模式校验的高速缓存控制流程.
1) 为CPU一般访问流程:CPU读取数据时,先从L1 Cache中获取数据,如果不命中,则从L2 Cache中获取数据,如果L2 Cache没命中,则从内存中获取数据.本文提出的基于数据模式校验的高速缓存控制流程;
2)为L2 Cache从内存中读取数据:首先判断数据特征,对不同数据特征采用不用压缩算法,消除冗余信息,减少源数据信息位位数;其次,对压缩后的数据进行校验算法的编码阶段,保证数据的正确性;最后将数据传送到L2 Cache中.
3)为L2 Cache往L1 Cache中写数据:首先进行纠检错译码阶段,保证数据的正确性,其次对压缩的数据进行对应解压缩操作,恢复源数据;最后将源数据传送到L1 Cache中.
4)为L1 Cache往L2 Cache写数据,具体过程与(2)类似.
5)为L2 Cache往内存写数据,具体过程与(3)类似.
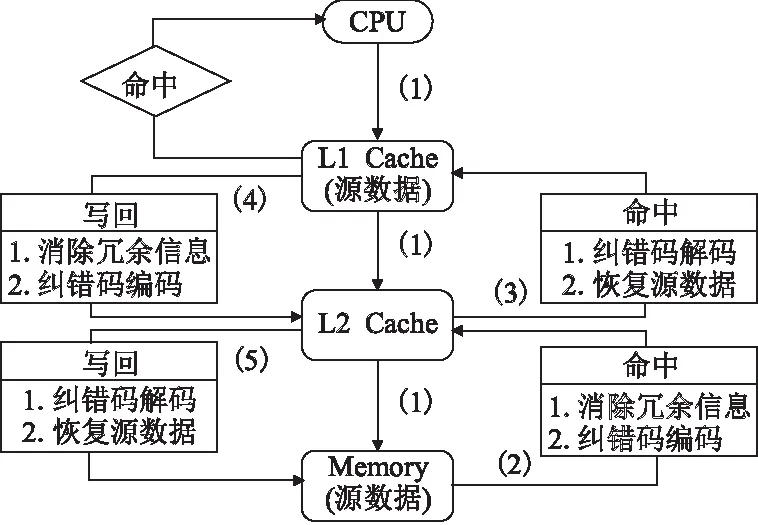
图12 支持压缩的容错Cache访问流程Fig.12 Access process in fault tolerant Cache supporting compression
5 实 验
在Zsim[20]模拟环境中运行SPEC CPU2006基准测试程序对本文方案进行评估,体系结构参数具体如表3所示.

表3 体系结构参数Table 3 Architecture parameter
图13和图14分别是高速缓存为1M和2M情况下的压缩率.压缩率定义为压缩后数据量和压缩前数量量的比值,如
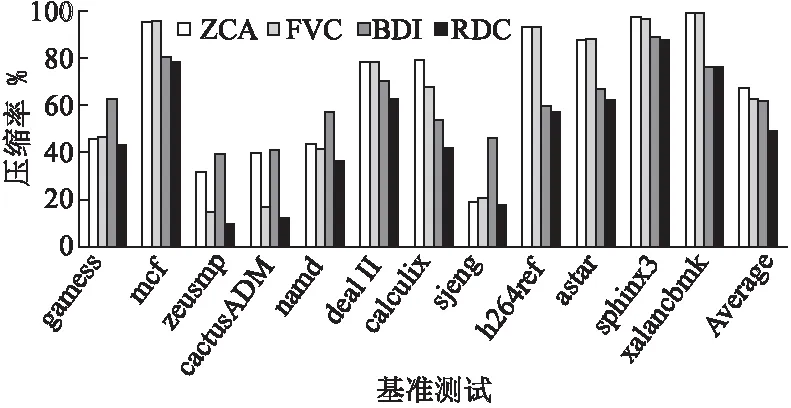
图13 1M压缩率Fig.13 Compression ratio for 1MB Cache
公式(3),值越低压缩效果越好.实验结果显示:采用不同方案,高速缓存中的总位数都有不同程度的减少,在1M时,本文提出的方案(RDC)压缩率为48.8%,ZCA压缩算法压缩率为67.5%,FVC压缩算法压缩率为63.2%,BDI压缩算法压缩率为61.8%.在2M时,本文提出的方案(RDC)压缩率为44.7%,ZCA压缩算法压缩率为63.2%,FVC压缩算法压缩率为59.0%,BDI压缩算法压缩率为59.2%.本方案在消除源数据信息位的冗余信息后,经过BCH码编码产生的校验位位数也相应降低,容错高速缓存存储的总位数明显的降低 .

(3)

图14 2M压缩率Fig.14 Compression ratio for 2MB Cache
图15和图16为高速缓存分别为1M单核和2M多核时不同压缩算法的命中率,本文的方案相较于ZCA分别将命中率提高了1.47%和1.53%,相比于FVC分别将命中率提高了7.94%和8.31%,相比于BDI压缩算法分别将命中率提高了7.93%和8.36%.
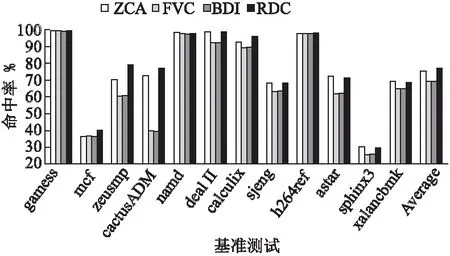
图15 1M单核不同压缩算法命中率Fig.15 Hit rate of single-core different compression algorithm for 1MB L2 Cache
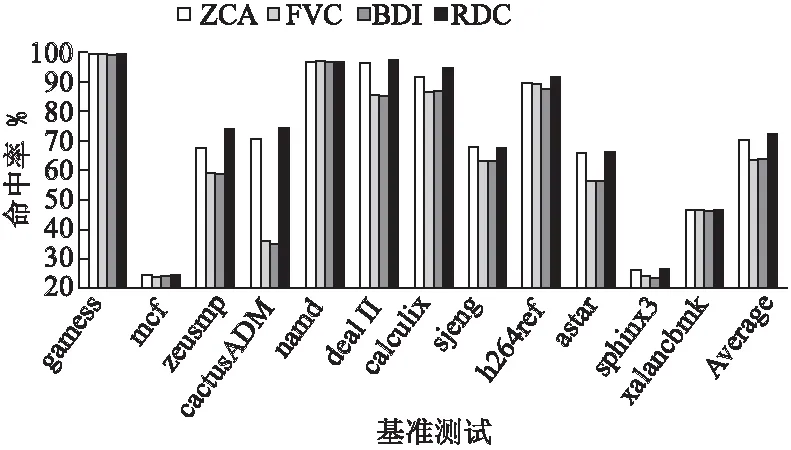
图16 2M多核不同压缩算法命中率Fig.16 Hit rate of multi-core different compression algorithm for 2MB L2 Cache
图17和图18是高速缓存分别为1M单核、2M多核时,系统的性能,采用归一化IPC表示.结果显示,RDC均不同程度地提升IPC值,1M单核相比ZCA压缩算法提升7.9%,FVC压缩算法6.6%,提升BDI压缩算法10.1%,2M多核分别提升19.4%,6.9%,14.5%.
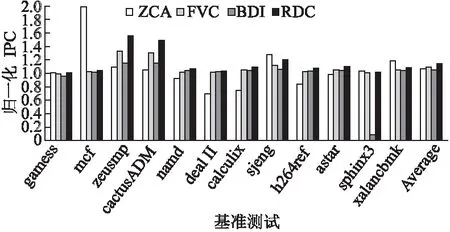
图17 1M单核IPCFig.17 IPC of single-core for 1MB L2 Cache
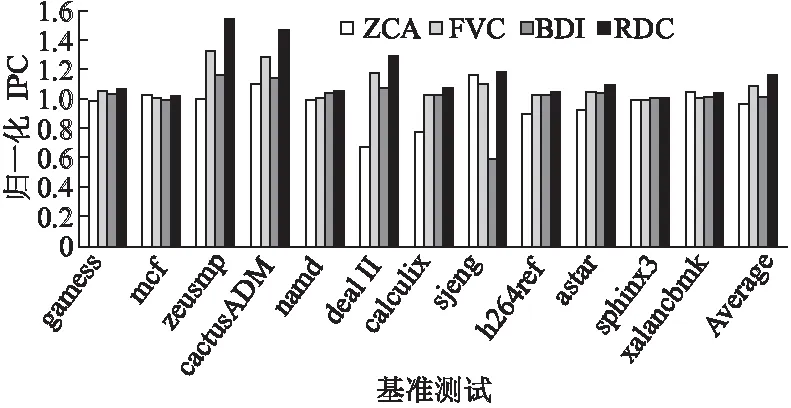
图18 2M多核IPCFig.18 IPC of multi-core for 2MB L2 Cache
图19分析了高速缓存分别为1M、2M时,不同数据特征出现的概率.通过图可知在2M时,满足冗余数据特征的概率较大,2M冗余数据特征出现的概率平均为79.4%,1M冗余数据特征出现的概率平均为75.1%.
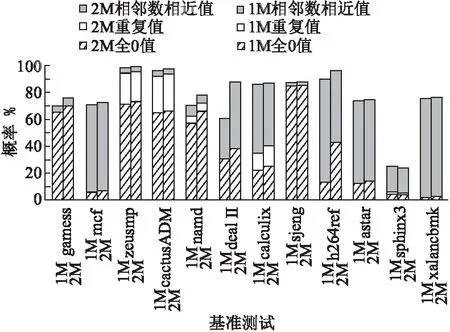
图19 不同数据特征出现的概率Fig.19 Probability of the appearance of different data features
6 结 论
高速缓存的容错设计在空间等苛刻计算环境中具有重要意义,现有系统多采用校验算法,但随着错误复杂度的增加,时间与空间开销等比增加.为此本文提出一种基于数据模式的高速缓存压缩校验方案,分析数据冗余特征,设计了根据数据冗余模式的动态压缩算法选择方式,并对压缩数据进行校验,模拟环境中的评测显示本文方法将高速缓存的占用率平均降低了53.2%,单核IPC平均提升15.1%,多核IPC平均提升16.7%,命中率平均提升了5.92%.既保证了系统的可靠性,又降低了容错开销,提高了系统性能.
