使用程序分析和特征识别方法过滤网页广告
2018-10-26何欣程查春柳
何欣程,查春柳,2,许 蕾,2
1 (南京大学 计算机科学与技术系,南京 210023)2 (南京大学 计算机软件新技术国家重点实验室,南京 210023)
1 引 言
在互联网时代,用户可以免费访问各种网站并浏览网页上各种各样的信息.网页开发者免费提供网页信息给用户,并通过互联网广告来获得收益,用于网站的维护与更新,由此形成了一个良性的互联网生态系统.然而,恶意广告的出现给用户造成极大的困扰.这些恶意广告跟踪并窃取用户的浏览信息[1,2],造成隐私泄漏等威胁,严重影响用户的访问安全.因此,很多用户选择在浏览器上安装广告拦截器,用于屏蔽广告,阻止恶意广告的跟踪和信息窃取[3].
AdBlock Plus1是目前最具代表性的广告拦截器,它通过对网页代码与过滤列表easyList2进行正则表达式的匹配,从而识别并拦截广告.这种方法能识别出大多数的广告,效率较高,因而深受用户欢迎.但这种方法也有一些缺点:
1)当网络中出现新的广告时,AdBlock Plus不能及时对广告进行屏蔽,因为新出现广告的URL地址尚未出现在过滤列表中,而AdBlock Plus需要人工不间断地维护更新过滤列表.
2)除了对广告JavaScript文件的匹配与拦截,AdBlock Plus还通过HTML元素的匹配来确定某个页面元素是否是广告,这可能会导致过滤广告后的页面出现大块空白、排版错乱等问题.
为了解决现有广告过滤器的不足,减少人工维护列表所带来的开销并提高过滤精度,本文提出了一种结合静态分析和特征识别的方法,来识别并屏蔽广告.具体过程包括:首先,在搜集的数据集上,统计过滤列表并进行特征的提取,然后将提取到的特征放入分类器进行训练,从而得到广告分类模型,最后实现一个Chrome浏览器插件TriFilter,用于准确识别并屏蔽广告.通过对546个网页进行实验,本文提出的方法能达到较好的精度(69.9%)和查准率(74%).
本文第二节介绍相关工作,包括广告过滤器、反广告过滤器和JS程序分析的研究现状;第三节展示了论文的主要方法,包括对JS文件进行代码解析、确定过滤列表和广告特征、分类器的训练以及浏览器插件的实现;第四节主要介绍本文的实验部分,提出2个研究问题来考察TriFilter的有效性,并得到相应实验结果;第五节对全文进行总结与展望.
2 相关工作
2.1 广告过滤器
现有的广告过滤器包括Adblock Plus、Adguard3、ADSafe4、保护伞广告过滤器、广告拦截大师5等.这些过滤器能够过滤一些已知的广告,但也存在一些问题,比如并未能真正实现准确有效的代码识别并完全过滤广告,或者错误地把普通网页代码理解为广告代码而进行删除或屏蔽.例如,AdBlock Plus通过一个过滤列表来进行正则表达式的匹配(类似黑名单),过滤列表中包括URL、元素ID以及一些域名等已经确认是广告的列表.但是对于一些新出现的广告,则需要人工进行添加名单,否则不能识别出这类广告,这类方法需要长期人工维护过滤列表,代价很大.
Orr C.R.[4]等人提出基于静态分析方法来确定网页中的广告特征,从而区分广告和正常的内容.这些特征是通过对JS程序进行静态分析得到的.在此基础上,再使用SVM进行分类,以识别广告JS文件.但是这种方法在确定特征的时候没有进行实证研究,所选取的特征并不一定全部适用于现有的网页情况;另外这篇论文并没有通过插件实现可用的广告过滤器.
另外也有研究通过程序分析和机器学习结合的方法[5,6]来对相关的JS文件进行识别,判断是否是广告文件,但在方法的精度和效率上还需要改善.
2.2 反广告过滤器
如果越来越多的用户使用广告过滤器,会导致Web生态系统的失衡,造成巨大的影响.因此出现了一些方法用来阻拦AdBlocker的使用,例如,方法Antiblock6通过JavaScript来检测用户当前环境是否存在广告屏蔽工具,如果存在这类工具,则要求用户关闭AdBlocker或者对该网站内容进行付费观看,但是这种方法会降低用户的使用体验,因此Weihang Wang[7]等人提出了WebRanz工具,通过使用内容和URL随
机化方法来规避广告过滤器.通过使用WebRanz,网页发布者可以改变网页元素的ID内容,包括HTML、CSS和JavaScript等,使得广告过滤器不能按照过滤列表来识别广告.WebRanz重写了原生JavaScript API,使得动态生成的DOM对象也能被随机化,并且在不改变页面功能和显示效果的前提下使得广告过滤器失效.
在实际应用中,出于安全保密或者存储的需要,网页中的JavaScript代码和HTML代码有时会被混淆或压缩:原先具有明确语义的代码变成一些肉眼难以识别和理解的字符串,但仍然可用一些专门的函数来解析,不影响输出结果.另一方面,混淆技术[8,9]在现实中收集到的恶意脚本样本中被大量采用,以逃避检测.因此,一些网页开发者在插入广告时将广告对应的ID以及URL做代码混淆,这样使得传统的广告过滤器也无法识别出广告.
2.3 JS程序分析
JavaScript具有语法灵活性和高度动态性,易于使用,但代码的可维护性不够好.由于HTML元素和JavaScript代码之间通过浏览器相互作用,进一步加剧了客户端JavaScript代码的维护问题.
目前,JS的程序分析分为静态分析和动态分析两种.通过对JS程序进行分析可以得到JS程序的相关信息并了解JS程序的功能.
在静态分析方面,现有技术[10]大都需要对程序进行代码解析、控制流图和数据流图构建等工作,类似JS-WALA7这样的分析框架(SAFE8,TAJS9等)提供了传统的静态分析器,但可扩展性不好,而且现有的 JavaScript的动态特性(比如JavaScript的原型链特性以及闭包特性等)使得静态的程序流分析难以实施,无法获得精确的分析结果;除此以外,大多数的JavaScript应用依赖于大的和复杂的库和框架,与JavaScript原生代码交织在一起,更增加了分析的难度[11].因此,长期以来,分析JavaScript程序被认为是一个巨大的挑战.
在动态分析方面,目前常用的分析工具有Jalangi[12],支持影子执行(shadow execution) 机制,在程序动态执行过程中替换原本程序语句执行的语义,并在执行过程中通过更新影子值(shadow value) 来对原程序进行动态分析.通过该工具可以实现JS动态分析,如论文[13-15]都是在Jalangi框架上对JS代码进行动态插桩分析并得到相应的运行时信息.
3 网页广告识别、过滤方法
3.1 方法概览
本文给出一种基于程序分析与特征识别相结合的方法过滤网页广告,本文实现的广告过滤插件的框架如图1所示.
为了实现相应的插件,我们首先对捕获到的网页的JS文件进行代码解析、生成AST树,然后遍历AST树并提取出JS
文件的特征向量(3.2节);其次通过实证分析,确定哪些特征能作为区分广告代码与普通代码的依据,并确定了一些常用的广告JS文件,得到一个JS文件过滤表(3.3节);通过训练好的分类器模型对得到的特征向量进行分类(3.4节),判断文件是否是广告JS文件,进而完成广告过滤插件的实现(3.5节).

图1 TriFilter结构图Fig.1 Structure of TriFilter
3.2 解析JS代码
抽象语法树(AST树)是指源代码语法所对应的树状结构.可以通过构建语法树将源代码中的语句映射到树上的每一个节点.通过遍历,可以操纵语法树并精确获得程序代码中的某个节点.
我们通过现有的语法解析器Esprima10将JavaScript代码解析成一个用JSON文件表示的树状结构并保存下来,文件中的结构就是解析后的AST.通过遍历抽象语法树提取特征,将提取到的特征拼接成特征向量,这样就可以得到每个JavaScript文件对应的特征向量.
3.3 确定过滤列表和广告特征
为了确定区别广告代码和其它JS代码的特征,我们首先进行了实证分析,在现有论文基础上对提取的一些特征进行研究,分析哪些特征能对广告文件和非广告文件的区分起到更好的效果;然后给出具体的特征表示.
3.3.1 实证分析
论文[4]将广告代码特征分为7大类,分别是混淆代码(Code obfuscation)、动态代码和URL生成(Dynamic code and URL generation)、代码结构(Code Structure)、函数调用分布(Function call distribution)、事件处理(Event handling)、脚本源(Script origin)、关键词的存在(Presence of keywords)以及一些不属于这些类别的特征,如ad字样.在此基础上,本文进行实证分析,以确定广告特征.
为了确定有用的特征,我们在216个网页上对论文[4]中的特征进行统计,由于统计后大部分特征在广告和非广告的JS文件中都大量出现,我们删除了那些在广告文件中从未出现过或极少出现的特征,其中包括混淆代码.对于一个特征是否加入广告或非广告特征,我们根据这一特征在广告文件中出现的次数是否大于在非广告文件中出现次数的1.5倍进行判断.
3.3.2 特征表示
通过实证研究,我们确定了4个类别总计21个特征来表示广告特征向量.这四个类别分别是代码结构、函数调用分布、事件处理以及其它(包含ad字样).每个类别中包含的特
征如表1所示.
3.4 训练分类器
本文采用对数几率回归算法以及十折交叉验证来实现一个二分类分类器.十折交叉验证将数据集分成十份,轮流将其中的1份作为测试集,9份作为训练数据,10次的结果的正确率(或差错率)的平均值作为对算法精度的估计.每一次的训练算法采用的是对数几率回归,也即Logistic Regression(LR).
LR可以看作泛化的线性模型,其训练的主要工作是对于我们提取出的特征向量赋权值.一个网页的某个特征向量在决定该网页是否为广告时所起的作用越大,其所占的比重越高.当一个LR模型训练出来后,对于新来的网页,我们依旧提取其特征向量,并使用我们训练出来的各向量权重beta进行计算,从而判别出分类结果.

表1 特征分类及表示Table1 Classification and representation of features
由此可见:在对数几率回归中,我们主要通过训练过程不断调整权重向量参数beta.对于给定的数据集,对率回归模型最大化“对数似然”(log-likelihood):
(1)
我们使用牛顿法或梯度下降法求解beta参数,通过调整学习率、训练轮数等参数,对模型进行微调,通过加大训练集、调整特征向量,对精度做进一步提升.
当权重向量beta参数求解出来后,对于一个待检测的新网页,我们使用3.3节中方法提取出该网页JS文件的特征向量后,使用算法1判断该网页是否广告相关.
Algorithm1. AdDetection
Input:BETA:Weight coefficient vector
PATH:Path of JavaScript files
Output:”ad” or ”other”.The result of the judgment
1:/*Stage 1-Build the AST of input file */
2:jsScript←fs.readFileSync(PATH,"utf-8")
3:ast←esprima.parse(jsScript)
4:/*Stage 2-Extract the eigenvector*/
5:recordTables←BFS(ast)
6:individualOut←compositeResult(recordTables)
7:individualNum←countResult(individualOut)
8:/*Stage 3-Calculate the result of the judgment*/
9:result←0
10:foreachb∈BETA,eachx∈individualNumdo
11: result←result-b·x
12:endfor
13:result←1/(Math.exp(result)+1)
14:ifresult>=0.5 then
15:returnad
16:else
17:returnother
上述算法中,第2~3行读取待检测网页的JS文件,构建该文件的AST;第5~7行使用BFS方法遍历AST,提取表1中的特征向量,存入individualOut中,统计每个特征向量出现次数,存入individualNum中;第9~17行,使用训练好的LR模型判断该JS文件是否ad相关,输出结果.
3.5 TriFilter三次过滤的实现
本文计划实现的广告过滤器是一个Chrome浏览器扩展插件,其实现过程包括三次过滤,故将其命名为TriFilter.
首先我们需要确定一个小规模的JS文件过滤表(主要包括百度、谷歌等常见推广广告的JS文件名与URL地址)和白名单表(已经确认的不需要拦截的JS文件及URL,主要包括已审查过的非广告类及位于白名单的列表),通过在线加载的方式,在遍历HTML页面时,对与列表匹配的JS文件进行过滤,也即不加载匹配到的JS文件;
然后对加载后的JS文件内容进行分析,将加载得到的JS文件进行静态分析,得到对应的AST树,然后提取特征并通过训练好的分类器模型对JS文件分类,判断是否是广告JS文件,若是广告JS文件,则实行“block”操作,让浏览器不加载该JS文件;
另外,在得到分类器判断结果后,Tri-blocker会自动将判断的结果更新到第一步的文件过滤表和白名单;
最后,对得到的html文件再进行一次遍历审查,对需要屏蔽的元素实行“display:none”操作.
3.6 插件TriFilter的算法优化
使用简单的LR分类器,我们的插件TriFilter能够识别广告网站和非广告网站(具体实验评估结果详见第4节),但仍然存在精确率不足,尤其是召回率较低的问题.出现这样的问题,主要是由于以下两点:
1)广告代码特征提取较为困难.一段含有广告的源代码,往往与普通代码结构十分相似,有可能被误认为非广告代码.只有通过大量的数据收集,才能正确总结出代码特征,并将之运用到训练器中,不断调整参数、训练结果.为此,我们需要进一步扩大训练集从而进行优化.
2)我们采取的对数逻辑回归模型是适用于二分类的训练模型,但在实践中面对现实网页源代码错综复杂、看似毫无规律的特征数据时,有可能精度方面有所限制.为此,我们拟采用集成学习的方法进行解决.
集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务,这些个体学习器可以是同一种学习器,也可以是不同种学习器.集成学习通过将多个学习器进行结合,常会获得比单一学习器显著卓越的泛化性能.我们拟采用AdaBoost族算法,基于最简单的“加性模式”进行求解.
(2)
其工作机制主要为:先从初始训练集训练出基学习器LR,再根据基学习器的表现对训练样本分布进行调整,使先前学习器做错的训练样本在后续收到更多关注,然后基于调整后的样本分布训练下一个基学习器.
其中,我们令每个弱分类器的组成是 [阈值 偏置 特征列],使用基学习器的[errorRate TPRate FPRate]评价其表现,规定训练停止的条件为:达到预设定训练轮数或基学习器错误率小于某个数.
使用集成学习器,能够进一步提高我们工具的广告识别精度,其实验评估结果(LRBoost)详见第4节.
4 实验评估
本实验在Windows系统下进行,采用JavaScript语言实现Chrome插件,IDE采用JetBrains WebStorm 10.0.1,数据集来源为互联网各大网站网页源码.
为了验证本文提出的方法的有效性,我们提出下面两个研究问题:
RQ1:和论文[4]相比较,我们得到的新特征列表是否有效?与简单使用LR的方法相比,我们提出的集成学习改进策略是否有效?
RQ2:本文提出的方法是否能够有效识别广告?对于研究问题1,本文分别对论文[4]的方法和本文的两种方法进行实验,通过对数据集(包含546个网站,其中JS文件有214个,非JS文件有332个)进行训练,对两者的实验结果进行比较,具体结果见表2.其中,
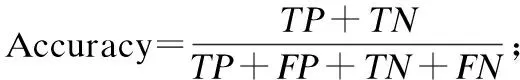
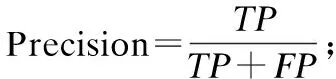

TP(True Positive),TN(True Negative),FP(False Positive),FN(False Negative)分别表示被识别为广告的广告、被识别为非广告的非广告、被识别为非广告的广告、被识别为广告的非广告.

表2 论文[4]、TriFilter、LRBoost方法的比较结果Table 2 Comparison results of three methods
由表2可知,与论文[4]中方法相比,我们的方法具有更高的精度(提升18%)、查准率(提升18%)和查全率(提升120%),特别体现在查全率的提升上,说明我们方法所选取的特征更能有效区分出广告与非广告.
另外,我们比较了简单分类器和集成学习的实验结果,发现LRBoost方法在精度上有1.7%的提升,在查准率上有20%的提升,但在查全率上略有下降(9.6%).一般情况下,查全率和查准率会互相牵制,原因在于:当查准率较高时,通常广告网页的比例会比较高,但难免会漏掉一些广告网页,导致查全率较低;但当查全率较高时,通常广告相关的网页比较多,但不可避免地有非广告网页被误判为广告相关,导致查准率较低.因此,应该结合要处理的问题决定查准率和查全率的权衡.在过滤网站广告的实例中,我们认为:误将普通网页判定为广告网页的严重程度高于漏报广告网页的严重程度,因此,我们更倾向于查准率的提高.
对于研究问题2,我们随机选取了20个非训练集中的网站进行实验,使用TriFilter对这些网站上的广告进行识别,并计算正确识别的广告个数以及误报的个数(基准通过人工审查来确定),然后计算精度、查准率和查全率.实验结果如表3所示,我们使用TriFilter识别这20个网站上的广告及非广告文件.其中第一列表示网站的名称,第二列、第三列分别表示网站中的广告文件数和非广告文件数(由人工审查确定),TP表示识别出的广告文件数,TN表示识别出的非广告文件数,FP表示未识别出的广告文件数,FN表示未识别出的非广告文件数.
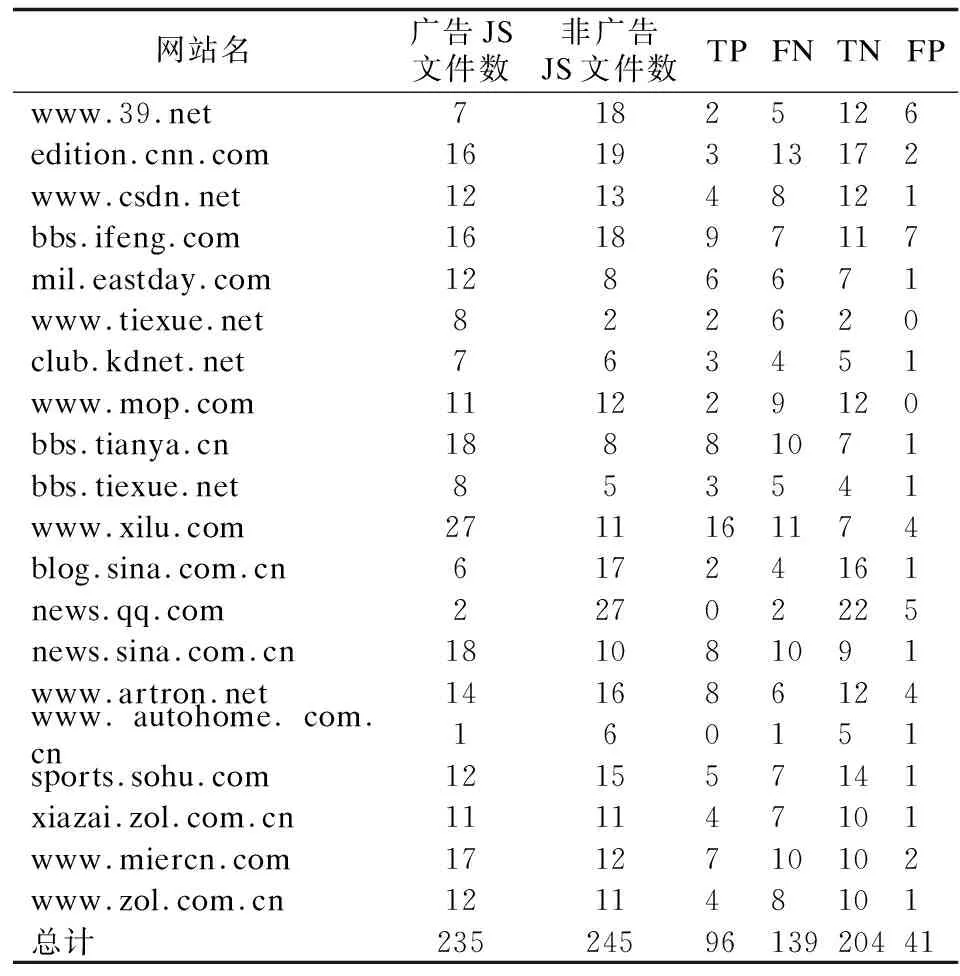
表3 TriFilter的广告识别结果Table 3 Results of TriFilter
从实验结果来看,对于这20个非训练集数据,我们的插件TriFilter能达到62.5%的精度、70.1%的查准率和40.9%的查全率.在该数据集上的精度和查全率和分类器的准确率相比略有降低,但是查准率有明显的提高,因此我们的分类器对于未曾训练的广告的识别具有较好的效果,这说明我们选取的特征可以较为准确地识别出web广告.
5 总结与展望
本文通过静态分析的方法对JS代码提取特征,并结合机器学习的方法进行训练学习,通过训练得到一个可用于识别广告的分类器模型;然后根据Chrome浏览器插件的规则实现了广告过滤器TriFilter.区别于现有广告过滤器需要维护庞大的黑名单列表,我们的TriFilter能自动识别页面广告代码并在最终展示时过滤掉页面上的广告.
实验结果说明了我们方法的有效性,但还需要进一步提高精度、查准率和查全率,尤其是查全率,我们可以考虑对广告代码的特征提取步骤进行优化,可以通过进一步扩大实验数据和增加特征来完善.
