一种概率模型的Docker镜像删减策略
2018-10-26邓玉辉
周 毅,邓玉辉,2
1(暨南大学 信息学院计算机科学系,广州 510632)2(中国科学院计算技术研究所 计算机体系结构国家重点实验室,北京 100190)
1http://jaso-nwilde-r.com/blog/2014/08/19/squashing-docker-images/
1 引 言
Docker容器技术是一种类似OpenVZ[6],Zap[7]和LXC[5]的操作系统级虚拟化技术,用户可以创建和管理容器,高效快捷得使用多个虚拟环境.因而每一个工作负载都可以运行在独立的虚拟环境中,并且容器之间也可以获得较好的工作效率和隔离度.容器技术以共享内核资源的方式区别于传统虚拟机,实现轻量级的应用隔离[3].
现如今,随着云计算和大数据规模的日益扩大,工业界对产品持续集成和高效发布的需求与日俱增[8],学术界也有很多对镜像存储和拉取的研究[12].由于镜像包含了所有运行时依赖,从而导致镜像的体积往往很大,在本地存储和导出迁移的过程中会产生较大的磁盘和网络I/O开销,增大了部署运维成本,同时也限制了镜像的迁移和扩展[2].镜像应该只包含一种服务所需要的依赖环境,因此,对于过于庞大和冗余的镜像包的删减工作就显得尤为重要[9].
本文提出了一种基于概率模型的Docker镜像删减策略,可以实现在本地镜像存储时,通过增大基础镜像的复用率来减小本地存储开销;并且对于要导出的镜像,则是收集原镜像运行时访问到的文件,同时建立导出概率模型,对达到导出阈值的目录下文件全部导出,从而在减少镜像大小的同时兼顾了镜像功能的完备性.
2 背景知识
2.1 镜像的写时复制(CoW)机制
为了使容器最大程度复用镜像层数据,减少磁盘占用空间和磁盘I/O开销,Docker采用如图1所示的堆栈式的镜像存储模型和写时复制(CoW)机制.CoW机制的核心在于,当读取已存在于下层的数据时,上层将不产生任何增量部分,仅当需要修改下层已存在的文件时,上层将会将该文件复制一份,然后再进行修改,而下层的原有文件则不会被更改,但从上层的视角来看,该文件已被修改.同样的,当上层需要删除下层中已存在的文件时,只需要添加一种占位符形式的特殊文件——whiteout,虽然从上层视角看确实删除了,但实际上该文件依然存在于下层中,并且实际占用的磁盘空间不会减少.

图1 镜像的写时复制(CoW)机制Fig.1 Copy on write mechanism of image
Docker容器的组织结构都采用了CoW机制,镜像层作为只读层,提供基础数据共享,容器层则用于存储当前镜像的修改部分,CoW的这种不改变下层数据的特性也决定了镜像的大小只会增长不会减小.因此,想要减小镜像的大小,仅仅直接在上层容器里删除相关内容是无法作用于下层镜像层的.而如果直接对镜像层进行处理,可能会影响到其他依赖该镜像的容器,经过修改的镜像也无法保证原有功能的完备性.
我们的工作即针对Docker镜像的这种特性,在本地存储和导出镜像时进行优化,使得镜像在本地存储时占用更少的存储空间,对于导出的镜像则有较小的体积和较完备功能.
2.2 镜像删减算法
在现有工作中,大多数都是根据镜像层CoW特性,采用静态分析算法1寻找镜像中的whiteout文件,然后删除镜像层中相对应的文件1;或者从dockerfile的编写上进行规范,使得生产的镜像更小更安全[10],其缺点在于无法对已制成的镜像进行处理.
而算法1的缺点在于只能对特定的aufs文件驱动的镜像进行处理,而对于其他文件驱动,比如device-mapper,btrfs等,这些文件驱动的镜像存储位置和镜像读写方式和aufs有很大区别[11],无法直接通过路径访问,因此也无法进行镜像删减.另外,对于不包含whiteout的镜像文件,即镜像层中没有需要删除的内容,那么算法1就几乎不能有所删减.
另一种方法则完全区别于算法1中采用的静态分析思路,使用了算法2的动态分析方法:程序从待修改的镜像中,运行起一个容器,并在该容器中植入一个探针,用于实时捕捉在容器中执行的进程和访问到的文件.等到该容器运行结束,探针会汇总在容器运行过程中所访问到的相关依赖文件,并将这些文件导出,重新生成一个新镜像,从而达到减少镜像文件数量的目的.我们采用如图2所示的UML活动图来描述算法2.

Algorlthm 1:Delete Whiteouts Data:FileName,ImageDir,DeletedFile1 for FileName in ImageDir do// If start with whiteout2 if startWith(FileName,“.wh.”)==0 then // Remove deleted files3 removeAll(FileName); // Remove the whiteout itself4 DeletedFile=truncate(FileName,“.wh.”);5 removeAll(DeletedFile);
算法2可以最大程度减小镜像的大小,并且不会像算法1受限于特定文件驱动.但缺点在于,算法2只依赖于容器运行中实际访问到的文件,如果在运行过程中没有较全面覆盖到所需的文件,则存在过度删减的可能.
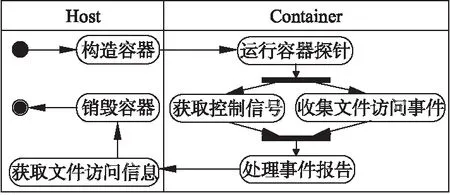
图2 算法2:获取容器内访问文件活动图Fig.2 Algorithm 2:UML activity diagram of getting container access files
针对上述问题,我们通过共享基础镜像减少本地镜像存储开销;同时基于算法2的动态分析加以概率模型,对导出镜像所需文件进行预测,使得在减少镜像大小的同时兼顾镜像功能的完备性.
3 基于动态分析和概率模型的删减策略
为了实现Docker镜像删减策略,本文设计了一种本地存储和导出镜像优化工具——docker-jimp,它可以有效地降低镜像在本地存储时所占用的磁盘空间,同时也大大减小了导出的镜像的大小,便于镜像的导出和迁移.
3.1 docker-jimp整体结构
对于Docker镜像的数据删减包含本地存储的镜像和导出的镜像.本地存储时,通过增大镜像之间基础镜像层的复用率,让更多的上层镜像复用同一个基础镜像,从而减小镜像在本地的总体存储开销;在导出镜像时,主要通过获取文件访问信息,使生成的删减镜像包含镜像功能所依赖的文件,并使用概率模型预测导出镜像所需文件,构建出新镜像.其整体结构如图3.
3.2 删减评估模型
镜像删减的关键在于对镜像行为的分析和基础镜像的选取,其决定了生成镜像的可靠性和最终生成的镜像大小.过多的删减可能会导致镜像功能不稳定,而仅仅是删除镜像中已标记为删除的文件又不能达到删减镜像的目的.为了达到最佳的删减效果,需要建立在不同删减模式下的评估模型.在本文中,我们主要对以下两种情况的模型分别进行分析.
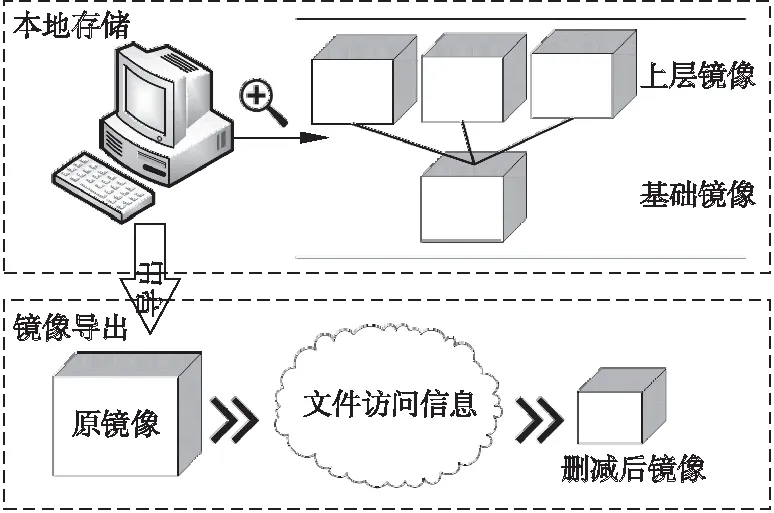
图3 docker-jimp整体结构图Fig.3 Integral structure diagram of docker-jimp
1)本地存储模式
Docker镜像在设计时采用了分层结构,其目的就在于希望可以充分利用本地存储的镜像层之间的共享关系,从而减少存储开销.我们对本地存储已有的镜像进行分析得知,镜像在本地存储时,镜像都包括基础镜像层及实现自身镜像功能的其他层.基于上述事实,对于存储在本地的镜像,我们尽量加大其对基础镜像的复用率,从而降低全局镜像存储的总开销.

(1)
其中,S表示共享基础镜像层的大小,L表示该层所共享次数.η值越大表明基础镜像层的复用率越高,对全局存储开销的提升效果越显著.因此,可以根据η值,选取本地共享的基础镜像.
2)导出镜像模式
对于导出镜像,我们希望其在满足功能的同时大小尽可能小.理论上,我们可以直接保留容器运行中访问到的文件,但在实际中,仅仅通过保留部分时间运行的文件将很难覆盖到所有需要的文件.比如,对于gcc镜像,在运行过程中几乎不可能访问过所有头文件,但对于导出的gcc镜像,提供较为完整的头文件库无疑是确保功能相对完备的保证.
为了使得导出镜像占用空间较小,同时能更完整包含实现其功能的依赖文件,因此,既需要导出在容器运行过程中访问到的文件,又要对其他未访问文件的导出可能性进行预测.本文中我们以目录为单位,预测目录y:a、只导出容器运行中访问到的文件;b、导出目录下所有文件.进一步的,我们定义:
目录y={子目录集Z,依赖文件集X,其他未访问文件},事件Y={目录y被全部导出},则目录y中文件全部导出的概率为P(Y),其取值与目录y中包含的依赖文件数量以子目录的全部导出概率相关,而子目录的全部导出概率则需要迭代至叶子目录求得,图4展示了目录y的导出模式.这种模型建立依据源于在一般目录结构设计里,每个目录里的文件是实现某种功能的集合,当一个目录内有较多文件被导出,那很有可能表明,这个目录里的文件是实现某功能的核心,因此这个目录下的所有文件也应该需要被导出.

图4 目录y导出模式示意图Fig.4 Export schema of directory y
为了实现导出模型,我们定义导出镜像所需要的所有依赖文件集合为Φ,其容量为n,目录y中包含的依赖文件集合X={x1,x2,…,xl}、子目录集Z={z1,z2,…,zM}.
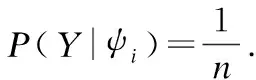
同样,定义目录y中所包含的子目录zj(j∈[1,m])被全部导出的事件为φj={子目录zj全部导出},那么子目录zj的全部导出概率则为P(φj),其值大小由子目录递归计算得出,而zj对目录y导出的条件概率P(Y|φj)则体现为zj对目录y的影响因子α,即P(Y|φj)=α.对于文件系统中的任何一个目录,都包括0到多个文件和子目录.因此,对于任何一个目录y,其全部导出概率P(Y)可描述为目录下所有依赖文件及子目录的全概率,即:
(2)

(3)
其中l为目录y下包含的依赖文件数,m为子目录数,我们给定一个阈值ε(0ε1),若P(Y)>ε,则将目录y下的所有文件全部导出.
3.3 实现手段
为了达到预计的目的:动态收集容器的运行使用依赖情况,完成3.2中的两种模型.需要实现的内容如下:
1)访问文件信息收集
为了动态捕捉镜像在运行时所访问的文件,我们采用Fanotify文件系统通知机制[4]对镜像内文件访问事件进行收集.结合每个镜像的功能,使用该镜像运行若干个用例,对所有用例访问到的文件取并集,从而得到镜像访问文件集合.
具体实现是通过4个并发进程及线程之间的相互通 信完成,分别为User、Sensor、Monitor和Collector.User是向探针发出开始或结束指令的进程,通常是运行在主机中,与Sensor通过unix socket进行通信;Sensor即在容器中进行文件访问信息捕获的探针进程,主要作用是负责接收Monitor捕获而来的报告(report),并把这些报告上报给User进程;Monitor线程是负责汇总从Collector线程收集到的事件(even),并整理成报告提交给Sensor.
图5是文件访问信息收集的数据流图,整个系统有三条数据流:stop流,由User发出,在整个探针信息收集完成后,停止探针工作,Sensor收到stop信号后,会将其传送给Monitor,由Monitor执行清理工作(cleanup);report流,由Monitor发出,在Monitor中执行事件处理函数(ProcessEven),将从Collector收集到的原始访问信息转化为report,传回给Sensor,进而由Sensor发送给User;even流,由Collector发出,是Collector在容器运行过程中执行事件捕获函数(GetEven),实时收集文件访问原始信息.
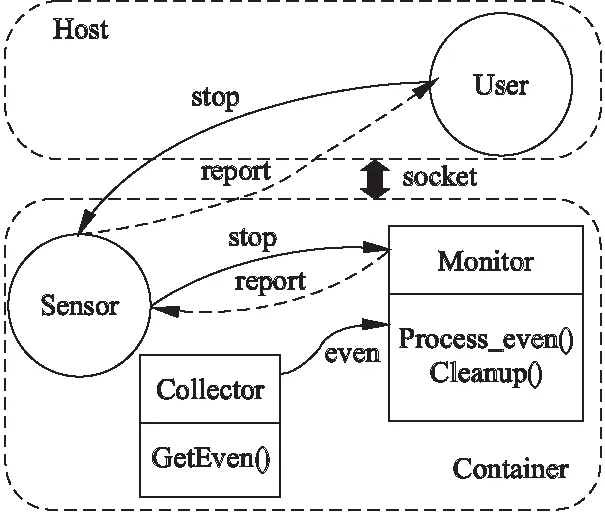
图5 文件访问信息收集数据流图Fig.5 Data flow diagram of access information
2)删减模型实现
删减模型的实现分为本地存储模式和导出模式,我们分别进行讨论:
本地存储模式:根据公式(1)的模型,本地存储模式的任务核心在于获取本地每个镜像的存储空间大小,以及基础镜像层的大小.在实现上,由于与Docker的守护进程进行通信的方式是利用Socket通信,通过向守护进程发送Get请求来获取到某一镜像的配置信息,从而得到镜像每一层的大小.
之后对新加入的镜像进行分析,取得其中所包含的文件,剔除所有与共享基础镜像重复的部分.最后,使用选定的共享基础镜像和剔除后的剩余部分重新生成一个新的镜像.从而该镜像的基础镜像部分不会额外占用本地的磁盘空间,达到减少本地存储开销的目的.
导出镜像模式:实现导出镜像模型的核心在于对生成镜像的文件访问信息进行收集和分析,由公式(3)可知,我们主要关注的是目录y下包含的依赖文件数,通过找出每个目录下文件和子目录的数量,并从叶子目录开始计算,向上迭代直至根目录,然后代入公式(3)中计算目录y的导出概率.进而可以得到文件系统中每个目录对应的导出概率,对于超过阈值ε的目录,就直接导出目录中的全部文件.
4 实验评估和分析
为了进一步验证本文提出的删减策略的有效性,对本地存储模式和镜像导出模式分别进行了验证.对于本地存储模式,实验主要对镜像集在进行基础镜像替换后每类镜像的变化情况以及占用的实际存储空间的变化情况进行了统计;对于导出镜像模式,我们以gcc镜像为例,在该镜像中编译多种代码,统计出每个目录的导出概率,并得出在不同的导出阈值ε下,需要导出的文件数量和对应导出镜像的大小.
4.1 实验环境及说明
本文实验采用Inter Core i7-6700的 CPU,4GB DDR3 RAM,和7200RPM 500GB SATA硬盘,并操作系统为CentOS7.3,Linux内核版本是3.10.0,Docker版本是1.12.0对应的API版本为1.27,采用的编译语言Golang版本为1.7.5,实验具体环境具体参数如表1所示.
表1 实验环境参数
Table 1 Parameters of experiment environment

环 境描 述CPUInter Core i7-6700Memory3797628 kBOSCentOS7.3Kernel3.10.0-514.16.1.e17DockerAPI Version 1.27GolangVersion 1.7.5
4.2 数据集分析
本文的数据集采用文献[1]中的实验镜像集,其中包括共10个数据库镜像,13个操作系统镜像,17个编程语言类镜像,4个web框架镜像,6个web服务镜像和7个其他工具镜像,共57个,均从docker hub上拉取.图6是每个镜像大小占总镜像的百分比,从图中可以看出,操作系统类镜像所占比例相对其他都要少,这是因为其他镜像往往都是以某个操作系统镜像为基础搭建的.而比重最大的则是编程语言类镜像,这是因为其中包含大量的依赖文件,其中最大的gcc:7.1.0镜像,则达到了1.64G.
我们对镜像集中的镜像进行分析,主要统计了镜像每层的占用空间大小.结果发现每个镜像各层的大小差异很大,而基础镜像层的大小往往位于最大的三层中,平均每个镜像中最大的层可占镜像总大小的67%.从图7中可以看出,一个镜像中的数据基本都集中在最大三层中,尤其是操作系统类镜像,几乎所有数据都只存在一层中.因此,通过共享同一个基础镜像层,增加本地中基础镜像层的复用率,可以达到多个镜像共用同一个基础镜像层的效果,从而减少镜像整体在本地占用的磁盘空间大小.

图6 实验镜像集Fig.6 Set of experimental images
4.3 实验结果分析
4.3.1 不同基础镜像替换后各个类型镜像的影响
在本地存储模式下,通过增大镜像之间共享的镜像层的复用率,让更多的上层镜像复用同一个基础镜像,从而减小镜像在本地的总体存储开销.我们选取镜像集中43个功能镜像分别用crux:3.1(341.68M)、debian:jessie(123.5-1M)、fedora:2(230.86M)和alpine:3.5(3.98M)进行基础镜像替换.图8是在基础镜像替换后,每一类镜像的平均虚拟空间占用情况,从中可以看出,新镜像的虚拟占用空间都比原来镜像变大一些,而debian:jessie和alpine:3.5的增长程度较低.这是由于原本镜像多采用debian:jessie基础镜像,而使用更大的crux:3.1、fedora:25基础镜像,无疑会增加单个镜像的虚拟空间占用,但实际上基础镜像是共享的,所以本地只会存储一份基础镜像.而使用alpine:3.5这种很小的基础镜像进行替换,单个镜像变化不会明显.
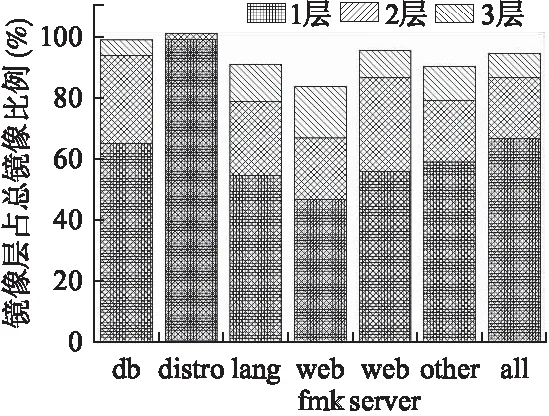
图7 镜像各层所占比例关系Fig.7 Proportion of image layers
由公式(1)计算得ηcrux=40.0%,ηfedora=30.8%,ηdebian=25%,ηalpine=1%.理论上应选取η最大的crux基础镜像.在实际实验中,替换前本地存储实际占用空间大小为21.2G,用crux替换后占用空间大小为20.4G,fedora替换后大小为22.8G,用debian替换后大小为19.5G,而用alpine替换后大小为24G.可以看到,使用fedora和alpine替换后,镜像的实际占用空间反而更大了,这是由于我们虽然共享了基础镜像,但忽略了其他层的共享,导致了一部分数据的冗余存储,而效果最好的是用debian进行替换,空间节约了8%,这是由于原有镜像的基础镜像有较多是使用debian基础镜像,对于这些镜像,我们完全保留了原有的共享关系,同时把其他镜像也进行了debian基础镜像替换,所以可以使得空间的节约最明显.
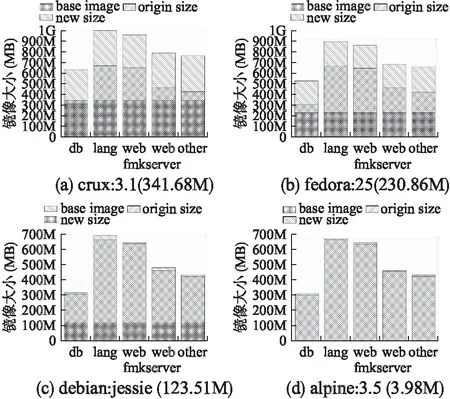
图8 基础镜像层共享关系Fig.8 Shared relation of base image
可见η值可以在一定程度上反映基础镜像的复用率,作为基础镜像的选取标准,但也应该考虑原本的层共享关系,减少本地存储时的数据冗余,这也是我们未来工作需要完善的地方.
4.3.2 概率模型中不同阈值选取对导出镜像的影响
对于镜像导出模式,我们选取了gcc:7.1.0镜像作为实验对象,其大小为1.64G.在实验中,我们编译了nginx-1.12.2、openssl-1.0.2m和 redis-4.0.6,并对运行过程中实际访问到的文件数目进行统计,对于取不同的阈值ε,结合公式(3),得出对应目录的导出概率.图9是镜像导出模型的目录结构拓扑图(部分结构未画出).其中files为当前目录中实际访问到(包括重复访问)的文件访问次数,dirs为当前目录中被访问到的子目录数,P(export)为导出概率.从图中可以看出,当阈值ε取到0%-5%时,可以全部导出/usr/include,/usr/lib/x86_64-linux-gnu等与gcc镜像编译功能密切相关的目录里的所有文件,从而保证导出镜像有较好的完备性.
为了验证选取不同阈值时,对导出文件数目的影响,我们选取了不同的阈值,并统计在在不同阈值下需要导出的文件数量.从图10(a)可以看出,每次运行访问到的文件数目基本不变,而当选取较小的阈值,其导出的文件数目越多,最高可增加133%.随着阈值的提高,导出文件数目呈阶跃式下降,这是由于对于导出概率大于阈值的目录会完全导出其中文件,而小于阈值的目录则按需导出,导致导出文件数量的跳跃式变化.同时,当阈值ε大于25%后,由于所有目录的导出概率均小于阈值,不会预测导出文件,因而导出文件数目和访问文件数目一致.

图9 各目录访问次数及导出概率Fig.9 Number of directory visits and export probability
从图10(b)中可以看出,gcc镜像原来的大小为1.64G,随着阈值的增大,导出镜像的大小随之减少.在没有使用概率模型,即当阈值ε选取到25%以上时,此时仅仅导出了在运行过程中实际访问到的文件,导出镜像大小为64.5M,较原有镜像减少了96%,这已经很难保证镜像功能的完整性了,而当阈值选取在1%时,导出镜像为498.12M,减少了69.5%,此时可以保留更多依赖文件.
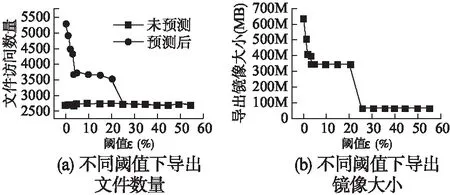
图10 不同阈值下导出文件数目及导出镜像大小Fig.10 Number of exported files and size of images under different threshold values
5 结 论
本文提出了一种基于概率模型的Docker镜像删减方法,
结合镜像本身的分层机制,加大本地镜像的基础镜像层复用率,从而减少在本地存储时的存储开销.同时,在导出镜像时,使用概率模型按需构建新镜像,一方面减少了导出镜像的大小,另一方面提高了导出镜像的完备性.在本文中所采用的镜像动态分析方法和概率模型,对镜像行为分析、镜像安全检测及镜像逆向工程也有一定参考价值.
从实验结果上看,在本地存储的镜像,最多可以使空间开销节约8%.导出的镜像同其未使用概率模型的方案相比,减小了61%,同时增大了镜像在导出后功能的完备性.
