基于堆叠降噪自编码机的广告博文识别方法
2018-10-26赵晓乐冯旭鹏刘利军黄青松
赵晓乐,栾 杰,冯旭鹏,刘利军,黄青松,3
1(昆明理工大学 信息工程与自动化学院,昆明650500)2(昆明理工大学 教育技术与网络中心,昆明 650500)3(云南省计算机技术应用重点实验室,昆明650500)
1 引 言
在互联网快速发展的今天,社交网络在人们生活中占据了很重要的位置.其中新浪微博作为基于社交关系进行信息传播的媒体平台之一,以其发信息布门槛低,文本长度短,实时分享性以及互动性等特点吸引了大量的用户注册和使用[1].尽管微博拥有诸多优点,但是也存在着一个严重的问题,即由于微博本身的特性,它允许任何人在不透露自己真实身份的前提下,就可以表达自己的意见,这种匿名性鼓励了有某种意图的人会有针对性的发表言论[2].通常这类博文被称作噪音博文,其中的广告博文就是这类言论的代表,其特点是带有营利性,由专业人士编写,内容分散,形式多种多样,很难通过统计筛选的方法将其去除.随着微博中的广告数量日渐增多,产生了大量的低质量或无用信息,直接导致了博文质量的下降.微博中广告的存在使得人们阅读微博时不仅浪费了大量的时间,同时也增加了挖掘博文中有用信息的难度.因此对微博博文中的广告进行识别,去除广告噪音博文,对于改善博文质量,挖掘博文中用的价值等信息都有重要意义.
微博充满了各种各样的博文,广告博文属于噪音博文的一种.目前国内外对于噪音博文的定义形式与处理方法多种多样,Castillo[3]认为不可信的博文(Twtter)即谣言是噪音博文,需要设计方法进行去除.对于不可信的噪音博文,高明霞[4]通过构建基于信息融合的识别框架来识别该类噪音博文.Li[5]等基于机器学习算法提出两种半监督的方法应用于大量未标记数据来识别垃圾邮件.董雨辰[6]对新浪微博上的水军发布的炒作博文进行过滤,通过分析炒作微博的特性,提出基于SVM的炒作博文识别方法.Zhang[7]发现许多的商家为了扩大商品的知名度在Twtter上发布许多带有URL链接的广告博文,Zhang对这些博文中涉及的推广活动进行分析,提出一个基于URL推广目的相似度的推广活动博文识别框架.
对于有专业人士编写的有目的性的广告博文,其内容广泛多变,难以通过统计筛选将其过滤.目前国内外关于广告博文的去除主要有以下几种方法.王琳[8]将广告微博和字符微博定义为噪音博文,并通过对广告博文进行分析,确定广告博文拥有的特性,将各个特性值相加并设定阈值来过滤广告博文.Anita[9]在经过实验验证之后发现使用随机森林分类的方法识别广告博文效果最好.姚子瑜[10]在Zhang和Anita的基础上将广告博文和有奖营销博文放在一起作为噪音博文,通过朴素贝叶斯和最大期望算法构建一种半监督的噪音博文识别模型,实验证明所提的模型要优于朴素贝叶斯和支持向量机模型.高俊波等[11]使用文本数据作为特征,采用监督学习的方式构建SVM分类模型进行广告博文的识别;然而这种方式在建立模型未考虑博主社会关系方面的特征.因此,郭跇秀等[12]从博主角度出发定义特征,在原有的特征基础上引入博主“主题”特征,实验证明在引入博主“主题”特征之后广告博文识别模型准确率有所提高.但上述方法在构建模型时都没有对特征进行选择,使用的特征或多或少存在着冗余的问题.张宇翔等[13]参考特征工程中现有的特征选择方法(主要为机器学习方法)构建自己的特征选择方法,并将选择后的特征用于构建微博反垃圾模型,实验表明相比于方法的选择,特征选择对模型的识别效果更为重要.
对此,本文从另一个角度出发,使用堆叠降噪自编码机进行特征选择,提出一种基于SDA的广告博文识别模型.一方面通过SDA对特征进行降维处理,将原有特征编码成另一种更低维度的特征表征,解决特征冗余的问题,提高了模型的识别率,另一方面使用深度学习技术对特征进行选择减轻了特征选择的工作量,降低了应用的难度.
2 相关工作
2.1 word2vec
首先通过训练将微博文本中的每个词表征为K维实数值向量,通过计算词与词之间的距离来计算他们之间的语义相似度.然后根据词频用Huffman编码,使得所有词频相似的词隐藏层激活的内容基本一致,出现频率越高的词语,他们激活的隐藏层数目越少,这样有效的降低了计算的复杂度[14].其采用的模型有CBOW和Skip-Gram两种.
CBOW模型的基本原理是通过已知当前词的上下文Context(w)对当前词w(t)进行预测,其条件概率函数如下:
(1)
Skip-Gram模型的与CBOW模型相反,Skip-Gram模型的基本原理是通过已知当前词w(t)对当前词的上下文Context(w)进行预测.其条件概率函数如下:

(2)
(3)
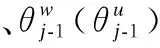
2.2 堆叠降噪自编码机
想要了解堆叠降噪自编码机的原理首先理解其中的基本单元自编码机的原理,自编码机最早是由Hinton等人[15-17]提出,是一种无监督的学习算法,主要由两个部分组成,编码和解码.在整个过程中尝试学习一个函数y使得输出最大程度上复现输入x,实现自编码机学习出x→h→y的能力并且在几乎不损失信息量的情况下将原始数据表达成另一种形式.基于这一原理便可以实现使用自编码机对特征进行压缩,将高维特征转化为更低维度的特征表征,以此达到特征选择的目的.
降噪自编码机是自编码机的变种,由Vincent等人[18]于2010年提出,他认为能将原始数据进行编码并通过解码将其恢复的自编码机并不一定是最好的,能够将有噪音的原始数据编码并通过解码将其恢复为真正的原始数据的自编码机才是最好的.降噪自编码机的结构如图1.

图1 降噪自编码机结构图Fig.1 Noise reduction autoencoders structure

堆叠降噪自编码机(SDA)是在降噪自编码机上的一种改进,这种改进的目的是为了通过深层网络学习出原始数据的多种表达,每一层都以上一层的输出作为输入,借此找出最适合分类任务的表征.堆叠顾名思义其使用的编码机不止一个,其结构如图2.

图2 堆叠降噪自编码机结构图
Fig.2 Stack noise reduction autoencoders structure
其中DAE1表示的是降噪自编码机单元,当我们完成自编码机的训练之后,其输出z就没有存在的必要了,因为对我们来说最重要的是隐藏层的数据,因此上图中降噪自编码机单元的输出为h.堆叠降噪自编码机的训练是逐层训练的,也就是说前一个单元训练完成之后将输出传递给下一个单元,下一单元接受数据后才能开始训练,最终完成整个网络的训练.
2.3 最大熵分类
最大熵是在给定约束条件下,对未知情况不做任何假设.这样得到的概率分布越均匀,概率模型的熵越大,预测的风险就越小[19].在本文中,将微博文本特征向量放入最大熵分类中,得到该特征向量的博文识别模型.最大熵分类模型公式如下:
(4)
(5)
其中y为分类结果,x为评论特征,Zw(x)称为规范化因子,wi是特征的权重,f(x,y)是特征函数.
3 SDA博文去噪模型
3.1 基于SDA博文去噪模型
博文去噪的对象是无内容的博文、无评论的博文、广告博文.模型的总体框架如图3所示,模型的输入是采集到的微博文本数据,输出是微博文本的分类结果.

图3 SDA广告博文识别模型框架Fig.3 SDA advertisements post recognition model framework
在上述过程中,由于特征选择方式的不同,广告博文的去除方式也不同,分为如下三种方式:
1)基于微博文本特征向量的广告博文识别模型:首先使用word2vec对微博文本进行处理,将其转化为文本向量,再对文本向量使用SDA进行特征选择,获得基于微博文本的特征向量(FV1),将FV1放入最大熵分类中得到基于FV1的广告博文识别模型M1.
2)基于人工定义特征向量的广告博文识别模型:对噪音博文进行分析定义特征,然后对定义的特征进行抽取获得人工定义的特征,将人工定义的特征作为SDA的输入,进行特征选择,得到基于人工定义的特征向量(FV2).将FV2放入最大熵分类中得到基于FV2的广告博文识别模型M2.
3)基于组合特征向量的广告博文识别模型:将FV1和FV2放在一起进行组合得到组合特征向量(FV3),将FV3放入最大熵分类中得到基于FV3的广告博文识别模型M3.
依据分类结果筛选出最好的分类模型,依据此分类模型识别广告博文.
3.2 基于微博文本的特征向量
文本特征一直都是广告博文识别中特征工程的一个重要组成部分,先前研究对其处理的方式主要是通过对文本数据中出现的词进行编号,对每个词计算其TFIDF值作为该特征的权重,依此来构建文本特征向量.然而由于新浪微博将文本的字数限制从原来的140字调整到了2000字,使得文本的特征词也相应的得到扩大,而且其中存在着大量的同义词,上下文依赖严重,因此难免会出现特征词冗余的问题.
对此论文首先使用word2vec对文本进行处理,借助word2vec在语义信息表征上的优越性[20]把文本中的每个词转化为向量表示称之为词向量,再将获得的词向量进行组合,得到文本向量.公式如下:
(6)
其中v(blog)i表示文本向量第j下标所对应的值,n为词向量的维度,m为文本包含的词数,word2vecij表示第i个词的词向量下标j所对应的位置.
此外对博文进行分析,可发现微博上的博文主要有两种类型,一种是原创博文,另一种是博主转发的博文.由于转发的博文比原创博文多了一项转发理由,而转发理由也包含了大量文本信息,为了表征所有种类博文的文本信息,本文将文本特征向量分为两部分,前一部分用以表征转发的博文的文本信息,后一部分用于表征转发理由这一文本信息,对于原创博文而言,其文本特征向量的前一部分表征博文的文本信息,由于其没有转发理由这一文本信息,故将其特征向量的后一部分做置0处理.这样就得到所有种类博文的文本特征向量,再使用SDA对获取的文本特征向量进行特征选择,得到FV1.
3.3 人工定义的特征向量
人工对问题分析定义特征是特征工程的常用方法,先前关于广告博文的研究中,特征的定义已经十分完善,本文在特征定义上引用上述研究定义的特征并依据自身对微博文本的分析补充一些特征.特征的详情如表1所示.

表1 特征详情表Table1 Feature details
特征定义之后需要对数据进行处理,将特征从其中抽取出来.由于定义的特征数过多,对于能直接量化的特征不做赘述,对不能直接量化的特征描述如下:
1)昵称复杂度
昵称复杂度主要表征的是微博用户昵称的复杂程度,微博用户昵称允许输入字母、数字、汉字、特殊字符这四种字符,论文对这四种字符设立权重并计算四种字符在昵称中所出现的次数,将四种字符的权重与出现次数相乘并求和作为用户的昵称复杂度.
(7)
其中NC表示昵称复杂度,i表示字符编号,wi表示i字符的权重,ti表示i型字符在用户昵称中出现的次数.
2)博文情感
博文情感使用博文的情感倾向来表示正面:1,负面:0.通过工具包构建情感分析模型,将模型分析出来的值作为博文的情感特征值.
将抽取的特征进行融合得到初步的特征向量,对初步的特征向量使用SDA进行特征选择得到FV2.
3.4 组合特征向量
组合特征向量的构建在前两种特征向量构建的基础上进行,前两种特征构建方法是现阶段研究中较为常用的特征向量构建方法,其方法各有优点但也各有缺点,对此我们将前两种方法构建的特征向量进行组合,构建组合特征向量.具体组合方式是通过构建一个能同时容纳两种特征向量的高维向量作为FV3.
4 实 验
4.1 实验设计
为了验证本文所提方法的有效性,实验分为四个部分进行,第一部分为特征抽取实验,用以验证论文中所提的特征抽取方法的有效性(针对不能直接量化的特征).第二部分为SDA特征选择实验,将引入SDA之后的模型与未引入SDA的模型的识别效果作对比,验证使用SDA进行特征选择的有效性.第三部分为对比选择实验,分两个阶段进行,首先将FV1和FV2进行组合实验获得基于FV3的识别模型.第二阶段,将基于FV3的识别模型与之前的基于FV1的识别模型和基于FV2的识别模型作对比,选出识别效果最好的模型用于广告类噪音博文的去除.第四部分为分类对比实验,将最大熵分类与其他分类方法作对比,验证选择最大熵分类的有效性.
4.2 实验数据
由于在广告博文识别方面尚未有标准的数据集,因此本文使用爬虫获取的数据进行实验.实验数据主要分为两个部分(DA,DB),DA是通过对COAE2013中倾向性分析评测数据文本进行预处理获得的数据,DB是对爬虫获取的微博数据进行预处理(主要为第一步的去除无法获取博主信息的博文,第二步的两轮人工标注,标注广告博文)之后得到的,包括微博,和博主信息.同时为了获得高维的最大熵特征函数向量,提高最大熵分类的效果.论文使用不平衡的样本数据训练模型,使用权重调整的方式解决样本不平衡带来分类问题.数据详情如表2所示.
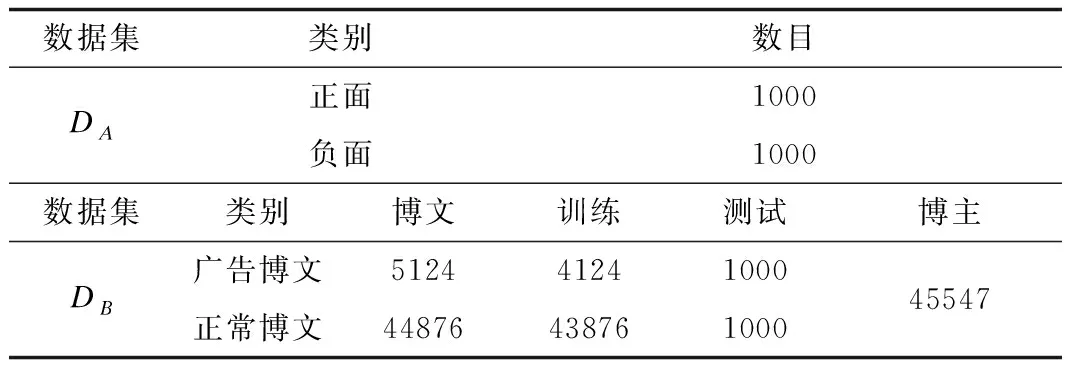
表2 数据详情
4.3 特征抽取实验
对于不能直接量化的特征进行抽取实验,验证本文抽取方法的有效性.昵称复杂度的抽取实验如表3所示.

表3 昵称复杂度抽取实验Table 3 Nickname complexity extraction experiment
表3展示的是使用本文方法抽取复杂度的部分实例,可以看出复杂度的给定基本符合客观事实.

表4 情感特征抽取实验Table 4 Emotional feature extraction experiment
从表4中实验结果可以看出情感分析的准确率在86%以上,召回率在84%以上,达到了实验要求的标准.
4.4 SDA特征选择实验
为了验证使用SDA进行特征选择之后对模型产生的效果,对比SDA引入前后模型识别率的变化.首先展示未引入SDA的模型识别效果(一方面由于本文识别的是广告博文,另一方面为了更好的对比实验结果,后续实验结果将仅展示广告博文类的P、R、F),实验结果如表5所示.

表5 未引入SDA的实验结果Table 5 No experimental results were introduced for SDA
从模型的F值上看,两个模型之间相差不大,仅有1.24%的差距.从准确率上看,基于特征FV2所构建的模型准确率只有49.37%,表明该模型存在许多误判的情况,而基于特征FV1所构建的模型其准确率为100%,明显高于前者.从召回率来看,基于特征FV2所构建的模型要略有优势.总的来说仅从表5的实验结果难以判断两个模型哪个效果更好.因此对两个模型分别引入SDA进行特征选择,观察模型的识别效果.引入SDA之后模型的实验结果如表6所示.

表6 引入SDA的实验结果Table 6 No experimental results were introduced for SDA
对比表5和表6的实验结果可以看出在引入SDA之后对于基于不同特征向量的模型,其识别效果均有不同程度的提升.此外从F值上看,对于FV1来说,当特征维度降至50维的时候模型的识别效果最好,对于FV2来说,当特征维度降至15维的时候模型的识别效果最好,因此后续实验中文本特征向量选择经过SDA处理后的50维向量,而人工定义的特征向量则选择经过SDA处理后的15维特征向量.
4.5 对比选择实验
根据本文4.3节所述将识别效果最好的人工定义的特征向量(经过SDA处理后的15维特征向量)和文本特征向量(经过SDA处理后的50维特征向量)组合构建一个65维的特征向量作为组合特征向量FV3,将组合特征向量放入最大熵分类中获得基于组合特征向量的广告识别模型M3,将M3与之前识别效果最好的M1进行比,选取出广告博文识别效果最好的模型.实验结果如表7所示.

表7 对比实验表Table 7 Comparison of experimental tables
从表7可以看出基于文本特征向量的模型M1的识别效果最好,虽然其识别的准确率较低,但是其召回率较高能识别出微博中绝大部分的广告博文,因此选取M1用于广告类噪音博文的去除.
4.6 分类对比实验
对比实验中由于有些分类方法在实现时难以对模型进行权重调整,因此将分类对比实验分为两步来做.对不可以进行权重调整的方法使用重采样的方式来解决数据不平衡问题.同样与之对比的最大熵也使用相同的数据进行实验,重采样的特征选择和权重调整的特征选择使用的方法一致.实验得出当模型的特征向量为FV1维度为150维时,模型在重采样数据集上效果最好.对比实验结果如表8所示.
从F值上可以看出无论是权重调整还是重采样,与其他分类方法相比,最大熵分类方法在广告博文识别问题上的效果都是要优于其他分类方法的.因此选择最大熵作为解决本问题的分类方法是有效可行的.

表8 分类对比实验Table 8 Classification comparison experiment
5 结 语
本文重点介绍了针对博文去噪问题所提出的基于SDA的广告博文识别方法,提出了三种不同的识别模型,依据实验结果选出其中对广告博文识别效果最好的模型,将其与前面介绍的统计筛选放在一起作为噪音博文去噪的方法.实验结果表明该方法能够有效识别绝大多数的广告博文,且效果优于其他模型.
不足之处:由于广告博文的形式越来多变复杂(如文字很少,广告以图片的形式展示),使得实验数据标注出现的误差变大,导致模型识别误差较大,因此下一步工作将考虑使用半监督学习的方式来调整训练数据集.
