一种基于支持向量机的安卓恶意软件新型检测方法
2018-10-24张超钦胡光武王振龙刘新宇
张超钦 胡光武 王振龙 刘新宇
1(国家数字交换系统工程技术研究中心 河南 郑州 450002)2(郑州轻工业学院计算机与通信工程学院 河南 郑州 450002)3(深圳信息职业技术学院计算机学院 广东 深圳 518172)4(清华大学深圳研究生院 广东 深圳 518055)5(深圳市金洲精工科技股份有限公司 广东 深圳 518055)
0 引 言
近年来,基于安卓操作系统(Android)的智能终端设备得到了极大普及,并成为大部分智能手机的操作系统。但由于Android平台的开放性,恶意软件的制造者可以轻易地开发出大量的恶意软件,给用户带来了很大的危害[1]。随着Android智能手机的用户数量不断增加及越来越多的Android应用(App)不断推出,检测和防范Android恶意软件的重要性日益突出[2]。
Android恶意软件的检测方法可以分为两大类:静态检测和动态检测。静态检测不需要实际运行程序,只需将程序源文件(APK)进行解压和反编译,然后提取相应的特征信息(如Permission、API等)、或者分析特征码,就可以识别恶意App。因此静态检测过程比较简单,检测速度较快,但缺点是只能检测现有已知恶意程序[8]。而动态检测是指在程序运行过程中跟踪程序的运行状态,通过分析程序的实际运行行为来检测恶意程序。包括跟踪内存进程运行状态、网络状态、文件操作、CPU使用情况、用户隐私数据的访问、系统调用等。因此,动态检测过程较为复杂,需要运行程序才能判断是否是恶意App,其效率较静态检测稍差,但可以检测未知的恶意软件。基于机器学习的动态检测方法的成功取决于:(1) 收集信息的有用性和充分性;(2) 机器学习方法是否使用得当[3]。
系统调用是应用程序与操作系统进行交互最底层的接口,系统调用序列是对一个应用程序所有行为的最根本的描述,包含了程序行为的所有信息,因此通过分析程序的系统调用序列来识别恶意App可以取得比较好的检测效果[4]。机器学习算法在恶意软件的检测方面应用非常广泛,比如:朴素贝叶斯[3]、遗传算法[5]、决策树[6]、支持向量机(SVM)[7]、随机森林[8]等。与其他方法相比,支持向量机可以在样本比较少、特征维数比较高的情况下仍然拥有很好的泛化能力,而且可以避免“维度灾难”[9]。
考虑到以上系统调用序列和支持向量机的特性,本文提出Android平台基于系统调用序列的SVM检测恶意软件的方法。不同于现有的SVM方法[3,6-8,10-11]直接分析调用序列,本文采用了马尔可夫链(Markov Chain)提取系统调用序列的特征,即把一个系统调用当作一个Markov链状态,而一个应用程序在一段时间内调用的系统调用序列可以当作一个离散时间Markov链[12]。紧接着,我们利用序列里相邻系统调用对出现的频率计算对应状态的转移概率,并在转移概率矩阵的支持下,将其转化成特征向量。另一方面,我们利用已有标签(已判定为恶意或正常的App)的特征向量训练SVM,使得训练后的SVM可接受未知App的特征向量,计算该App所属类别标签(正常或恶意),从而判断出该App的性质,实现判定未知App是否属于恶意软件的目的。通过在1 189个正常软件和1 227个恶意软件上进行的实验结果表明,本文所提方法显著优于现有的其他SVM检测方法。
本文主要贡献如下:(1) 总结了现有的使用SVM检测Android恶意软件的方法;(2) 首次提出基于系统调用序列的SVM检测方法;(3) 利用Markov链提取系统调用序列的特征,更好地刻画了App的动态行为;(4) 使用动态检测方法检测未知的恶意软件,并具有较高的准确率。
1 背景知识
1.1 离散时间Markov链
定义1一个随机过程{ξn,n≥1}具有状态空间S={s1,s2,…,sn},如果对所有的n≥1,j∈S和sm∈S(1≤m≤n),有:
Pr(ξn+1=j|ξn=sn,ξn-1=sn-1,…,ξ1=s1)=
Pr(ξn+1=j|ξn=sn)
(1)
则称该过程为离散时间Markov链DTMC(Discrete-Time Markov Chain)。
定义2一个离散时间Markov链{ξn,n≥1},如果它对所有的i∈S和j∈S,条件概率Pr(ξn+1=j|ξn=i)与n无关,则称这个DTMC{ξn,n≥1}是时间齐次的。
对于时间齐次的DTMC{ξn,n≥1},一步状态转移概率记作pij=Pr(ξn+1=j|ξn=i),由一步状态转移概率pij构成的矩阵P=[pij]称作(一步)状态转移概率矩阵。ti=Pr(ξ1=i)称作状态i的初始出现概率。行向量T=(ti)i∈S称作初始概率分布,它由状态的初始出现概率构成[12]。
定理1初始概率分布T和状态转移概率矩阵P可以完全刻画时间齐次的DTMC{ξn,n≥1},即:
Pr(ξ1=s1,…,ξn-1=sn-1,ξn=sn)=
ts1ps1,s2…psn-1,sn
(2)
1.2 系统调用
操作系统的主要功能是硬件资源管理,为应用程序开发人员提供良好的环境,使应用程序具有更好的兼容性。为了达到这个目的,系统内核提供一系列具备预定功能的多内核函数,通过一组称为系统调用的接口呈现给用户。系统调用把应用程序的请求传给内核,并调用相应的内核函数完成所需的处理,最终将处理结果返回给应用程序。和其他操作系统一样,Android操作系统的架构也采用了分层的形式,从上层到底层分别是应用层、应用程序架构层、系统运行库层和Linux内核层。本文所定义的系统调用是指在系统运行库和Linux内核之间的接口。本文使用的Android版本是4.0.4,一共有196个不同的系统调用。
系统调用是应用程序与操作系统进行交互的最底层的接口,程序对硬件资源的请求最后都要通过调用系统调用来执行(包括API调用的执行)。较其他特征,系统调用序列更能刻画一个应用程序行为,所以本方法拟通过程序的系统调用序列提取特征来进行恶意程序的检测。同时,系统调用频率只能描述事件出现的次数,并不能刻画事件之间的关联性。而离散时间Markov 链可以很好地挖掘出相邻事件的关联关系,因此本文将利用Markov 链来提取系统调用序列中的关联特征。
1.3 支持向量机
下面以二分类问题为例介绍线性支持向量机SVM的原理。
给定样本训练集(xi,di),i=1,2,…,N,xi∈Rn,di∈{±1},SVM的原理是试图寻找一个超平面(w·x)+b=0,x,w∈Rn,b∈R,使该超平面满足分类要求,即寻找权值向量w和偏置b的最优值,使满足公式:
di(wTxi+b)≥1-ξii=1,2,…,N
(3)
式中:松驰变量ξi≥0,i=1,2,…,N。
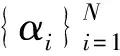
α=(α1,α2,…,αN)T
(4)
F(x)= sgn{(w0·x)+b0}=
(5)
对于线性不可分的输入数据,支持向量机可以通过核方法利用以上原理,建立线性的特征空间像的最优分类面。此时的最优分类函数为:
(6)
式中:K(xi,x)是核函数。
2 SVM在恶意软件检测中的应用
SVM是一种建立在统计学习理论基础之上的、应用最广泛的机器学习算法。与传统的分类方法相比,SVM在训练样本比较少,特征维数比较高的情况下仍然能够显示出很强的分类能力[9]。所以它广泛应用于人脸识别、文本分类和人工智能等领域。现有使用SVM检测Android恶意软件的方法主要分为两步,即提取特征和利用SVM进行分类。不同文献方法之间的主要区别体现在提取了不同的特征。现有方法提取特征一般为:Permission、API调用以及内存使用情况、CPU使用信息、进程信息和电池信息等。
文献[7]提出了基于Permission的检测恶意程序的方法。先把程序的APK文件进行解压和反编译,提取出每个程序的Permission作为原始特征,然后通过主成分分析方法(PCA)降维得到新特征,作为SVM的输入进行训练和测试。单纯的Permission不能提供足够的信息证明一个程序是否恶意,该方法只能达到最高90.08%的准确率。与此类似,文献[6]也先进行解压和反编译,提取出Permission和API调用,然后分别使用三种特征提取算法(Chi-Square、Relief和Information Gain)进行特征提取,最后利用SVM进行分类。文献[11]的前面处理方式与文献[6-7]一样,提取的特征包括细粒度化的Permission(Requested Permissions、Used Permissions)、细粒度化的API(Restricted API calls、Suspicious API calls)以及程序组件和网络地址(IP、URL、主机名)等。
由于以上这些方法没有运行程序,因此都属于静态分析。它们只是从源代码中提取特征,这样提取的程序信息不够充分,不足以判断一个程序是否恶意。如通过Java反射机制可以改变或隐藏API的名字,从而逃避API特征的提取。动态分析方法则可以实时跟踪和监控应用程序的运行行为,根据程序的运行状态提取特征信息进行识别。与静态分析相比,这种方法能够获取更多的信息[3]。
文献[13-14]构建了一个检测系统,通过监控应用程序的网络、电话、短信息、CPU以及电池、进程、内存的信息,并从这些信息中挑出32个特征,然后利用Linear-SVM来检测恶意软件。文献[14]的整个检测系统分为两部分:mobile agent和analysis server。其中mobile agent负责监控和记录应用程序的运行状态,而analysis server主要负责对获得的运行信息进行分析。虽然以上文献监控了应用程序的相关运行信息,但是这些信息并不全面,因此无法完全刻画程序的行为,并引起一定的误判,致使检测效果不是很理想。例如:在手机上运行游戏程序时,CPU的使用率和内存的使用率突然变高,就可能导致误判。文献[3]使用APIMonitor和APE_BOX分别记录应用程序的API调用和活动(activity),统计特定的25个API和13种活动单独出现的次数,以及由这些组成的2-gram和3-gram的出现次数,接着拼接成一个56 354维的向量并进行归一化,最后输入到LIBSVM中进行检测。但该方法仅依靠API调用和活动的频率识别。
3 基于Markov链的恶意软件检测方法
如图1所示,除样本准备阶段外本文提出的安卓恶意软件检测方法主要有三个步骤:预处理、特征提取和分类阶段。
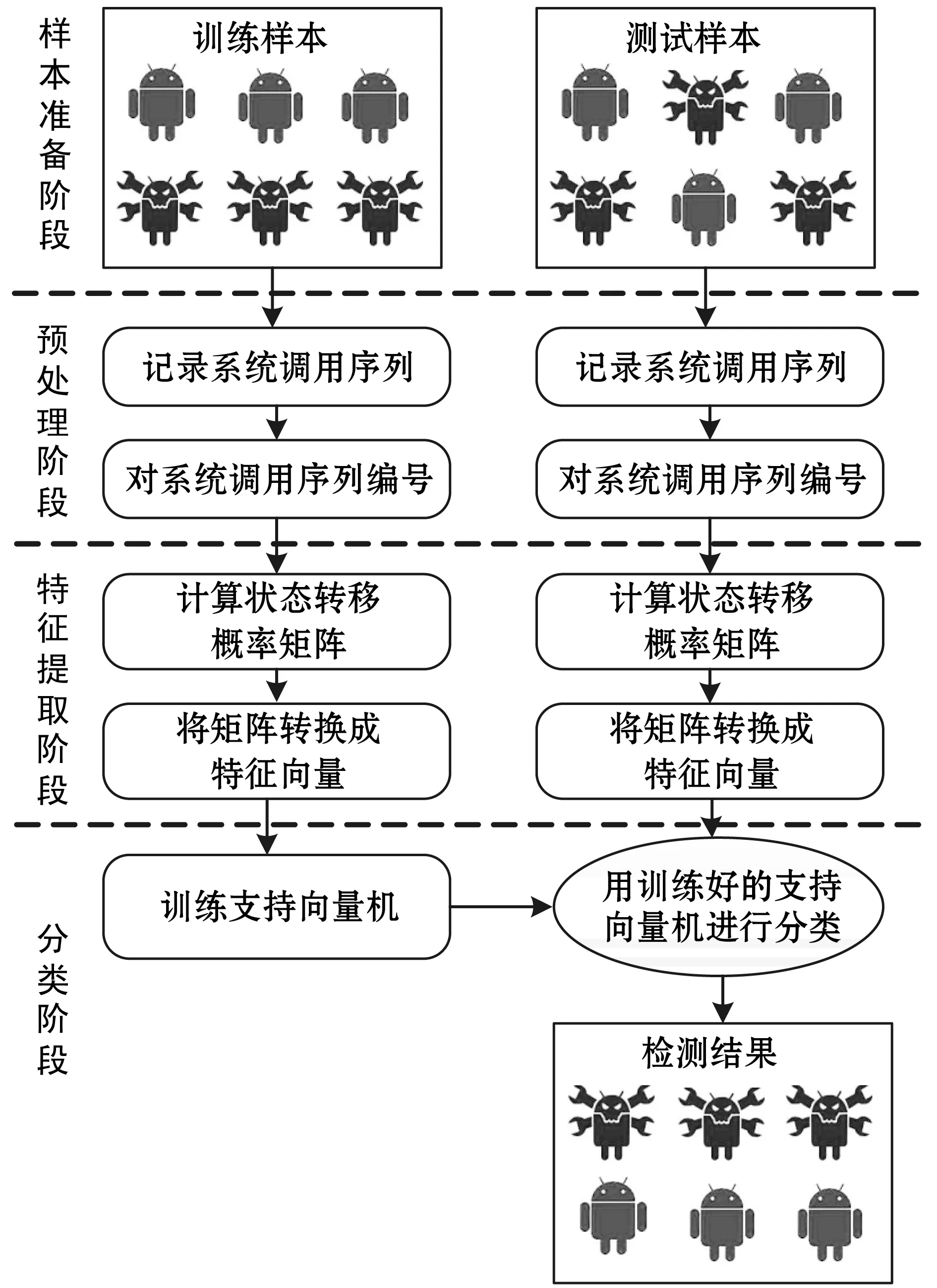
图1 安卓恶意App检测方法步骤
其中预处理包括系统调用序列的获取、编号,并得到一个系统调用数列;特征提取包括计算状态转移概率矩阵和将矩阵转换成特征向量;分类部分包括对SVM的训练和利用SVM进行检测。SVM的训练过程是一个典型的有监督学习的过程,它可以对线性可分和线性不可分的样本集进行分类。对于线性不可分的情况,SVM通过使用非线性映射算法(核方法)将低维输入空间线性不可分的样本转化为高维特征空间的线性可分样本,然后在高维空间采用线性算法进行分析。
3.1 预处理阶段
预处理阶段包括记录系统调用序列和编号两部分。我们通过strace、monkey命令来记录一个应用程序发起的系统调用。strace 命令可以跟踪到一个进程产生的系统调用,包括参数、返回值、执行消耗的时间。monkey是Android中的一个命令行工具,它能够向系统发送伪随机的用户事件流(如按键输入、触摸屏输入、手势输入等)。在这里,我们通过monkey工具来模拟用户的使用行为。
在用strace跟踪程序的系统调用的输出文件中,会出现极少数的乱码,我们通过去噪把这些乱码删除。然后把系统调用的时间、参数等都过滤掉,经过简化,我们得到了只包含系统调用名称的按时间顺序排列的系统调用序列。为了方便后继处理,我们用1,2,…,196,这196个数对Android4.0.4中的196个系统调用进行编号。经过这些操作后,系统调用序列转化成了系统调用数列。
3.2 特征提取阶段
提取特征的过程包括两步,即计算状态转移概率矩阵和将矩阵转换成特征向量。每个应用程序的系统调用序列当作一个离散时间Markov链,其中一个系统调用对应一个状态,Android4.0.4共有196个系统调用,所以状态转移概率矩阵的维数是196×196。设经过预处理后的系统调用数列为s1,s2,…,sr,r为其长度,N为系统调用总个数(在我们的方法中N=196),计算状态转移矩阵P的伪代码如下:
1P=(pij)N×N:=0;C=(cij)N×N:=0;k:=1;
2i:=sk,j:=sk+1;cij:=cij+1;
3k:=k+1;
4 IF (k≤r-1) Goto STEP 2;
6 For (1≤i,j≤N)pij:=cij/di;
假设一个系统只有6个不同的系统调用1、2、3、4、5、6,经过预处理后的系统调用序列假定为:2,1,6,4,1,3,5,4,6,3,2,5,1,4,5,3,4,2,1,4,6,2,5,3,6,4从系统调用i转移到系统调用j的个数记为cij,从系统调用i转移到任意系统调用的个数记为di,根据以上的系统调用序列有c11=0,c12=0,c13=1,c14=2,c15=0,c16=1,d1=4,……进而我们可以求出所有cij和di:
若系统调用i转移到系统调用j的概率记为pij,根据概率论中的大数定理,我们可以定义:
(7)
最后,我们可以求得状态转移概率矩阵:
因为支持向量机的输入为向量,所以在得到状态转移概率矩阵后,需要将矩阵转换成(特征)向量,才能作为支持向量机的输入。具体的转换方法是将矩阵的每一行按行号从小到大把每行元素首尾相接连在一起构成一个(特征)向量。如以上的矩阵转化后的特征向量是(0,0,1/4,1/2,0,1/4,1/2,0,0,0,1/2,0,0,1/4,0,1/4,1/4,1/4,1/5,1/5,0,0,1/5,2/5,1/4,0,1/2,1/4,0,0,0,1/4,1/4,1/2,0,0)。在我们的方法中,转移概率矩阵的维数为196×196,所以转换后的特征向量维数为38 416。
3.3 分类阶段
本文的分类过程包括支持向量机的训练过程和检测过程两部分。在我们的样本集中有1 227个恶意软件和1 189个正常软件,取其中614个恶意软件和595个正常软件作为训练样本,剩下的613个恶意软件和594个正常软件作为测试样本。每个软件的系统调用序列经过预处理4.1和提取特征4.2的处理后得到了一个38 416维的特征向量。记恶意软件得到的特征向量为xi∈R38 416,i=1,2,…,1 227;正常软件得到的特征向量为yi∈R38 416,i=1,2,…,1 189。SVM的训练过程是一个有监督的学习过程,其输入为特征向量和其对应的标签。具体在我们的方法中,SVM的训练数据为38 417维的向量,即(xi,+1),i=1,2,…,614,和(yi,-1),i=1,2,…,595。其中“+1”是恶意软件的标签,“-1”是正常软件的标签。通过以上带有标签的数据的训练,SVM求得最优权值向量w0,最优偏置b0和最优分类函数F(x),这样就获得了分类的知识,可以为无标签数据计算标签。
检测过程是对未知的恶意软件进行检测,SVM的输入不需要标签,所以只是38 416维的特征向量。训练好的SVM通过式(6)中的最优分类函数F(x)为每个输入特征向量计算出一个新的标签(1或-1)。具体在我们的方法中,对于每个测试样本,训练好后的SVM的输入数据为其系统调用转移概率矩阵转化的特征向量xi(i=615,…,1 227),或yi(i=596,…,1 189);SVM的输出数据为SVM通过式(6)计算出的该向量对应的标签,如果标签为“+1”,则该软件被判为恶意,否则该软件被判为正常。我们统计xi(i=615,…,1 227)作为SVM的输入时,SVM输出的标签为“+1”的样本总个数为TP(True Positive),输出的标签为“-1”的样本总个数为FN(False Negative);yi(i=596,…,1 189)作为SVM的输入时,SVM输出标签为“+1”的样本总个数为FP(False Positive),输出标签为“-1”的样本总个数为TN(True Negative)。这些数量可用于评估我们的方法。
4 实验结果和分析
4.1 数据集和评判指标
本文的实验数据集中的正常软件来自于Android市场的官方网站。我们通过修改Chrome浏览器的插件,从中一共批量下载了1 189个App当作正常软件。实验数据集中的恶意软件来自文献[15],一共有1 227个恶意App,其中包括49个病毒家族。我们在MATLAB R2013b 中采用5个不同的核函数进行训练和测试。
评判一个检测系统好坏的常用指标有TPR(True Positive Rate)、FPR(False Positive Rate)、Precision和F-Score。记TP为恶意软件被判定为恶意软件的个数,FN为恶意软件被判定为正常软件的个数,TN为正常软件被判定为正常软件的个数,FP为正常软件被判定为恶意软件的个数,则TPR定义为:
(8)
FPR定义为:
(9)
Precision定义为:
(10)
F-Score定义为:
(11)
TPR相等时,FPR越小,检测效果越好;反之FPR相等时,TPR越大,检测效果越好。Precision越大说明检测系统的准确度越高。F-Score是Precision和TPR的加权调和平均,是评判一个检测系统综合好坏的最重要的指标。
4.2 实验结果
表1给出了我们的方法在不同核函数下的实验结果。其中linear是线性核函数,quadratic是二次的核函数,polynomial是3次的多项式核函数,RBF是宽度为1的高斯径向基函数,MLP是权重为1偏置为-1的多层感知器核函数。由表1可知,新方法利用线性SVM取得最好的检测准确度:TPR为0.956 0,FPR为0.010 1,Precision为0.989 9,F-Score为0.972 6。其中613个恶意软件的测试样本中只有27个被误判为正常软件,594个正常软件的测试样本中只有6个被误判为恶意软件。

表1 本方案利用不同核函数对恶意软件的判定结果
4.3 比较与分析
现有文献[3,6-8,10-11]分别提出了6种不同的使用SVM检测恶意软件的方法。表2列出了本文方法(线性核)与以上6种方法的检测结果的比较。从表中可以看出本文方法在Precision和F-Score值明显优于其他SVM检测方法。
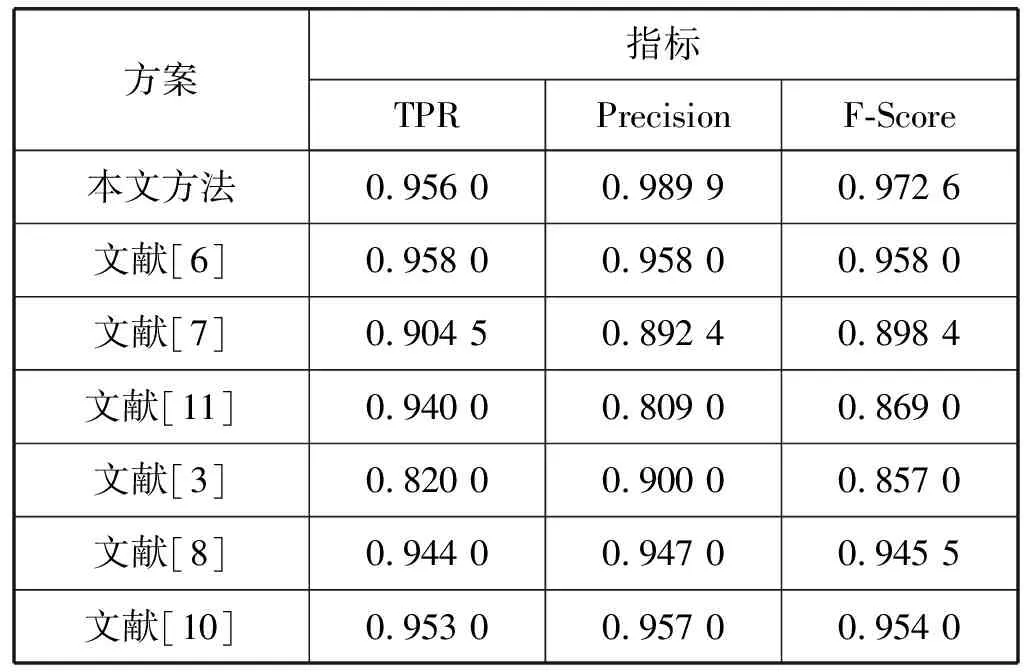
表2 本方案与其他方法的比较
文献[6-7,11]是静态分析的Android恶意软件检测方法。文献[6]只考虑了应用程序的Permission特征,单纯的Permission提供的信息非常有限。文献[7,11]从Permission和API调用两个方面提取特征。这些方法都是从静态的源代码中提取特征,这样提取的程序信息不够充分,不能描述程序的实际动态行为,所以它们的检测结果比较差。
文献[3,8,10]使用的是动态分析的检测方法。文献[8,10]从应用程序运行时的电话、短信息、网络、CPU、电池以及进程、内存的信息中提取特征。由于这些相关运行信息并不够全面,不能完全刻画程序的所有行为,所以会引起一定误判,检测效果不是很理想。文献[3]依靠API调用和活动的频率来判别恶意程序。API调用是应用程序接口,底层都是通过调用系统的系统调用来执行的。系统调用相对于API调用更能细粒度地刻画程序行为,而且频率仅能体现事件次数,不能体现事件的内部联系。Markov链描述了事件的前后联系,所以利用Markov链提取系统调用特征的方法比文献[3]方法的检测结果好。
图2直观地反映了表2的结果,从该图我们看可以出,本文提出的方案要优于静态检测方案6及动态检测方案10,同时也明显优于其他方案。
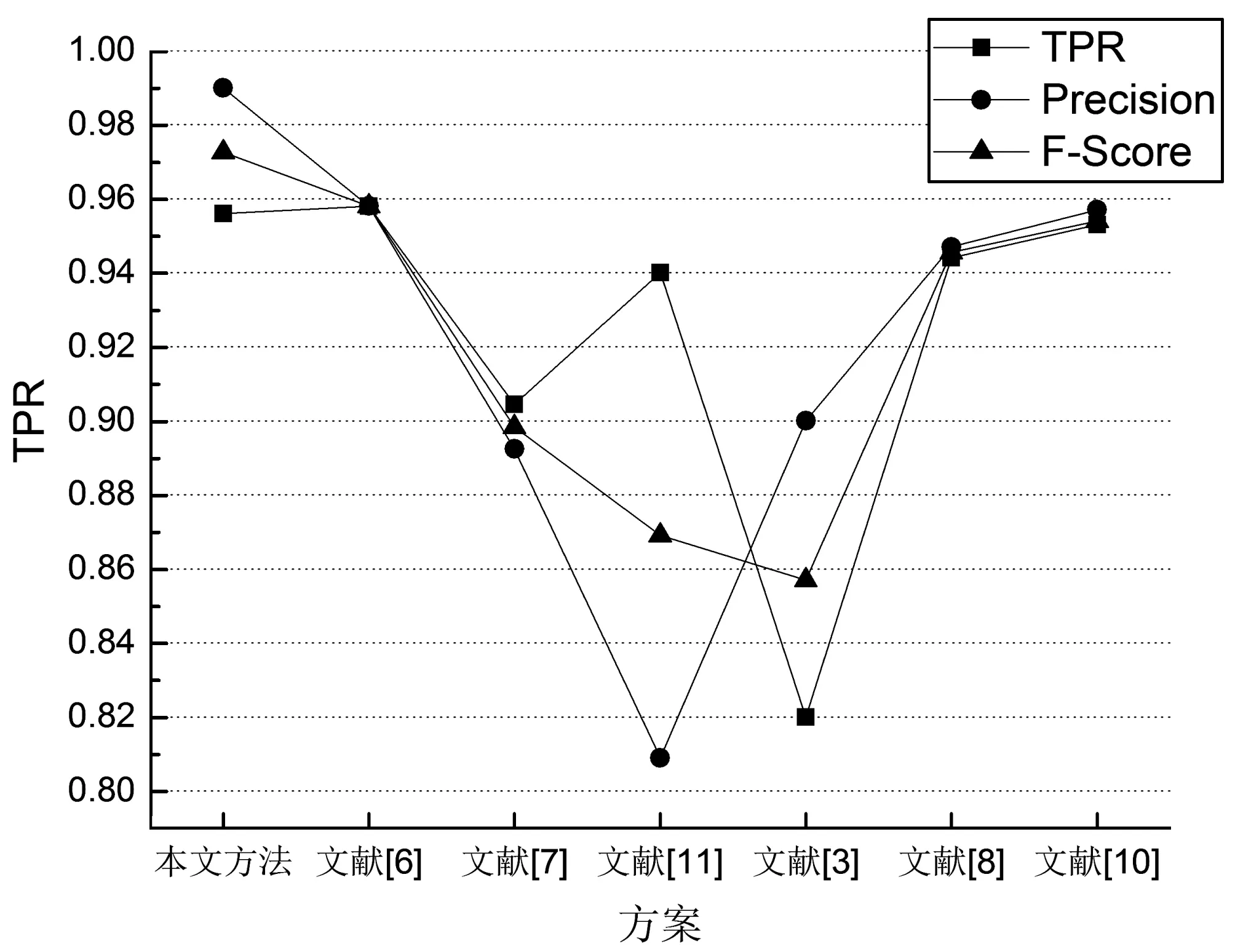
图2 本方案与其他方案对比
5 结 语
本文提出了一种基于SVM分类器的Android恶意软件检测新型方法。该方法为系统调用序列建立了Markov模型,把Markov链的状态转移概率矩阵作为SVM的输入来判别恶意软件。实验表明本方法的检测效果优于现有的其他基于SVM的检测方法。一方面是由于系统调用是一个应用程序具体行为的最根本的体现,另一方面是由于离散时间Markov链可以挖掘出隐藏在系统调用系列里的事件之间的联系。但是本文中还有一些工作可以进一步的研究。建立Markov模型,计算状态转移概率矩阵只是从系统调用序列中提取信息的一种方法,是否存在更好的数学模型来提取特征值得我们将进一步研究和探讨。
