面向微服务系统的运行时部署优化
2018-10-24徐琛杰赵文耘
徐琛杰 周 翔 彭 鑫 赵文耘
(复旦大学软件学院 上海 201203)(上海市数据科学重点实验室(复旦大学) 上海 201203)
0 引 言
近年来,越来越多的公司如谷歌、亚马逊[1]等开始采用微服务架构。文献[2]将微服务定义为可独立开发、部署、测试和伸缩的应用程序。基于微服务架构的应用系统(下文简称“微服务系统”)相较于单体应用有易于开发、部署、维护和伸缩等优点[3]。
微服务系统在线运行时,不同微服务拥有的实例数量不一,而微服务占有的资源量与实例数量呈正相关关系。微服务实例越多,该微服务占有的资源就越多,反之亦然[4]。进而当请求数量较多时,若某个微服务实例数量过少,其占有的资源也会较少。这将导致该微服务出现平均响应时间急剧变长的现象,严重影响用户的使用。同时,微服务系统线上运行时,其负载一直动态变化,导致特定的部署方案无法有效降低系统的整体响应时间。特别是在集群资源固定且有限的场景下,需要根据负载的变化动态地调节各个微服务的实例数量,从而降低微服务系统的整体响应时间。
Kubernetes[5]、Marathon[6]等当下流行的微服务管理工具提供了微服务的自动伸缩[7]功能。这些工具根据预先设定的条件为所有资源过少的微服务添加实例、为所有资源过多的微服务减少实例,从而调节微服务占有的资源量。但这些工具均假定在云计算环境下运行,当集群资源不足时,可以动态地向集群中添加新服务器。在集群资源固定且有限的场景下,当集群资源不足时,因无法添加新服务器,这些工具将无法如期调节微服务实例数量。此外,这些工具需要人工为每个微服务配置伸缩方案,配置工作相对繁重。
针对以上问题,本文提出了一个基于MAPE(Monitor、Analyze、Plan、Execute)环路[8]的自适应部署优化方法。在集群资源固定且有限的场景下,每轮MAPE循环时,通过分析微服务调用链及各个微服务实例的资源使用情况,根据调用链上缺少资源的微服务数量,挑选出数量最多的一条调用链。当集群资源充足时,为挑选出的调用链上缺少资源的微服务各添加一个实例。当集群资源不足时,先为所有存在空闲实例的微服务各减少一个实例,再根据减少实例后集群资源空闲情况,为挑选出的调用链上部分或全部缺少资源的微服务各添加一个实例。最终达到降低微服务系统整体响应时间的效果。在开源系统Spring Cloud Sleuth和Zipkin的基础上,本文实现了一个面向微服务系统的运行时可视化监控工具,基于该工具实现了一个面向微服务系统的运行时部署优化工具,并通过实验验证了部署优化方法的有效性。Train_ticket[9]是一个开源的、基于微服务架构的火车票订票系统,拥有超过40个微服务,本文基于该系统举例说明相关方法和技术,同时进行实验验证。
1 相关工作
谷歌开发的Dapper[10]是一个面向分布式系统的追踪工具,通过向通信模块、流程控制模块和线程库等被绝大多数应用所使用的模块中插入探针,使Dapper能在收集追踪信息时保持对应用层透明。Spring Cloud Sleuth是Spring Cloud提供的一个分布式追踪解决方案。Zipkin是一个基于Dapper开发的分布式追踪系统,可以用来收集Spring Cloud Sleuth指导分布式系统产生的运行时数据并可视化。
文献[11]实现了一组监控和管理微服务系统的静态页面,对单个微服务的平均响应时间、吞吐量等进行了可视化。本文不仅实现了单个微服务的平均响应时间、吞吐量等的可视化,还实现了微服务调用链及线上部署情况的可视化,并结合收集到的数据进行了可视化展示。
Kubernetes可以将单个微服务部署为一个Pod,通过自动伸缩Pod的方式,实现微服务的自动伸缩。但Kubernetes的自动伸缩功能要求微服务系统运行在云计算环境下,从而可以动态地向集群中添加新服务器。Kubernetes会为所有资源利用率超过预先设定值的微服务启动新实例,但如果运行的实例总数量过大,集群中的资源将不能启动全部新实例,Kubernetes就会添加新服务器到集群中,但是这种做法不适合集群资源固定且有限的场景。此外,Kubernetes还需人工为每个微服务单独配置伸缩方案,如微服务实例数量的上下限、期望的CPU平均利用率等限制条件,配置过程相对繁琐。文献[12]将微服务调用链定义为请求到达微服务系统后,微服务之间的相互调用所形成的有向无环图。本文提出的基于MAPE环路的自适应部署优化方法是在集群资源固定且有限的场景下,根据调用链来调节各个微服务的实例数量从而缩短微服务系统整体的平均响应时间,不需要人工为每个微服务配置伸缩方案,降低了配置的复杂度。
文献[13]提出了一个基于MAPE环路的自动伸缩方法,但该方法仅关注了CPU资源利用率,且每轮调节只调节一个节点,这导致在请求数量快速变化的场景下其调节速度较慢。本文提出的部署优化方法除关注CPU资源利用率外,还关注内存的使用情况,且每轮调节会根据调用链选择出一组微服务进行调节。当请求数量快速变化时,本文提出的部署优化方法能快速调节微服务实例数量。
2 背景知识
微服务系统属于分布式系统,因此可将基于Dapper开发的面向分布式系统的开源工具Spring Cloud Sleuth和Zipkin,用于研究微服务系统的行为。其中Spring Cloud Sleuth负责指导微服务产生trace信息,Zipkin负责收集trace信息并展示。
用户对微服务系统的一次请求通常需要大量的微服务调用进行处理。Dapper将针对一个特定请求的全部后台调用定义为一个trace,将微服务实例间的一次远程过程调用定义为一个span。Dapper为每个trace分配一个唯一的ID,称为trace id,从而区分开了来自前台的不同请求;Dapper为每个span分配一个唯一的ID,称为span id,从而区分开了不同微服务实例之间的相互调用。除最外层span,每个span均有一个span作为自己的父亲,并将父亲span的span id作为parent id记录在span中。图1展示了一个简单的微服务系统请求处理流程(图中,六边形节点代表了微服务系统中的不同微服务实例) ,rpc1对应的span1,是rpc3对应的span3的父亲,也是rpc4对应的span4的父亲;而微服务实例C没有再调用其他微服务实例,因此rpc2对应的span2没有孩子。通过span之间的父子关系,同一trace下的众多span构成了一颗树,记录了微服务系统不同实例之间的调用关系。

图1 微服务系统请求处理路径图
Span除记录trace id、span id和parent id外,还记录了span的name(通常为被调用的接口)、远程过程调用的时间节点、被调用方的接口、IP等众多信息,为研究微服务系统的行为奠定了基础。
3 可视化监控
为实现本文提出的基于MAPE环路的自适应部署优化方法,本文在开源系统Spring Cloud Sleuth和Zipkin的基础上,实现了一个面向微服务系统的运行时可视化监控工具。该工具从微服务可用性、微服务调用链及部署情况三个维度监控微服务系统的运行状态,并将结果可视化。
通过分析trace信息可以得到微服务可用性信息,微服务可用性信息包括每秒钟请求数量QPS(Query Per Second)、平均响应时间、最短响应时间、最长响应时间和错误率(请求错误数量与请求总数量的比值)等信息。微服务系统的大量微服务在短时间内可产生庞大的trace数据。例如,将Train_ticket部署在1台服务器上,每个微服务拥有1个实例,以每秒50个请求的速度发送查票请求,持续一小时可以收集32.6 GB的trace数据,数据量巨大。当用户查询微服务可用性信息时,如果直接从数据库中取得数据进行统计,由于数据量巨大,往往需要很长的时间分析数据。为了提升系统性能,本文采用MapReduce编程模型[14]对trace数据进行预处理。
MapReduce是一种用于处理大规模数据集的编程模型,该模型首先对数据进行映射(Map),然后对映射后的数据进行归约(Reduce),最终获得需要的结果。本文通过定时任务,每分钟统计一次微服务可用性信息。统计微服务可用性信息时先将span映射为统计微服务可用性的avaCount,再将具有相同微服务名称、微服务实例IP地址和接口名称的avaCount归约,最终将归约后得到的avaCount转换为微服务可用性信息(即中间结果)。avaCount中包含如下信息:微服务名称、微服务实例IP地址、接口名称、函数名称、查询数量、总响应时间、错误数量、最短响应时间和最长响应时间。将预处理获得的中间结果存储在数据库中。当用户查询微服务可用性信息时,只需分析数据库中的中间结果即可获得微服务可用性信息。
映射过程如图2所示。将span与avaCount中边框类型相同的项目进行映射。将span的名称映射为avaCount中的接口名称。将span的持续时间分别映射为avaCount的最短响应时间、最长响应时间、总响应时间。Span的类型有CLIENT、SERVER、PRODUCER、CONSUMER四种。其中CLIENT对应同步或异步调用中的调用方,SERVER对应同步或者异步调用中的被调用方;PRODUCER对应消息队列中的生产方,CONSUMER对应消息队列中的消费方。当span的类型为SERVER或者CONSUMER时,span的localEndpoint中记录了被调用微服务的信息,serviceName为微服务名称,Ipv4为微服务实例IP地址,将以上两项分别映射为avaCount中的微服务名称和微服务实例IP地址。Span中的tags记录了一些额外信息。如图2中mvc.controller.method为微服务被调用的函数名称,将其映射为avaCount中的函数名称。当被调用的微服务响应出现错误时,tags中将包含error,此时avaCount中的错误数量应置为1。因1个span对应1个请求,avaCount中的查询数量应置为1。
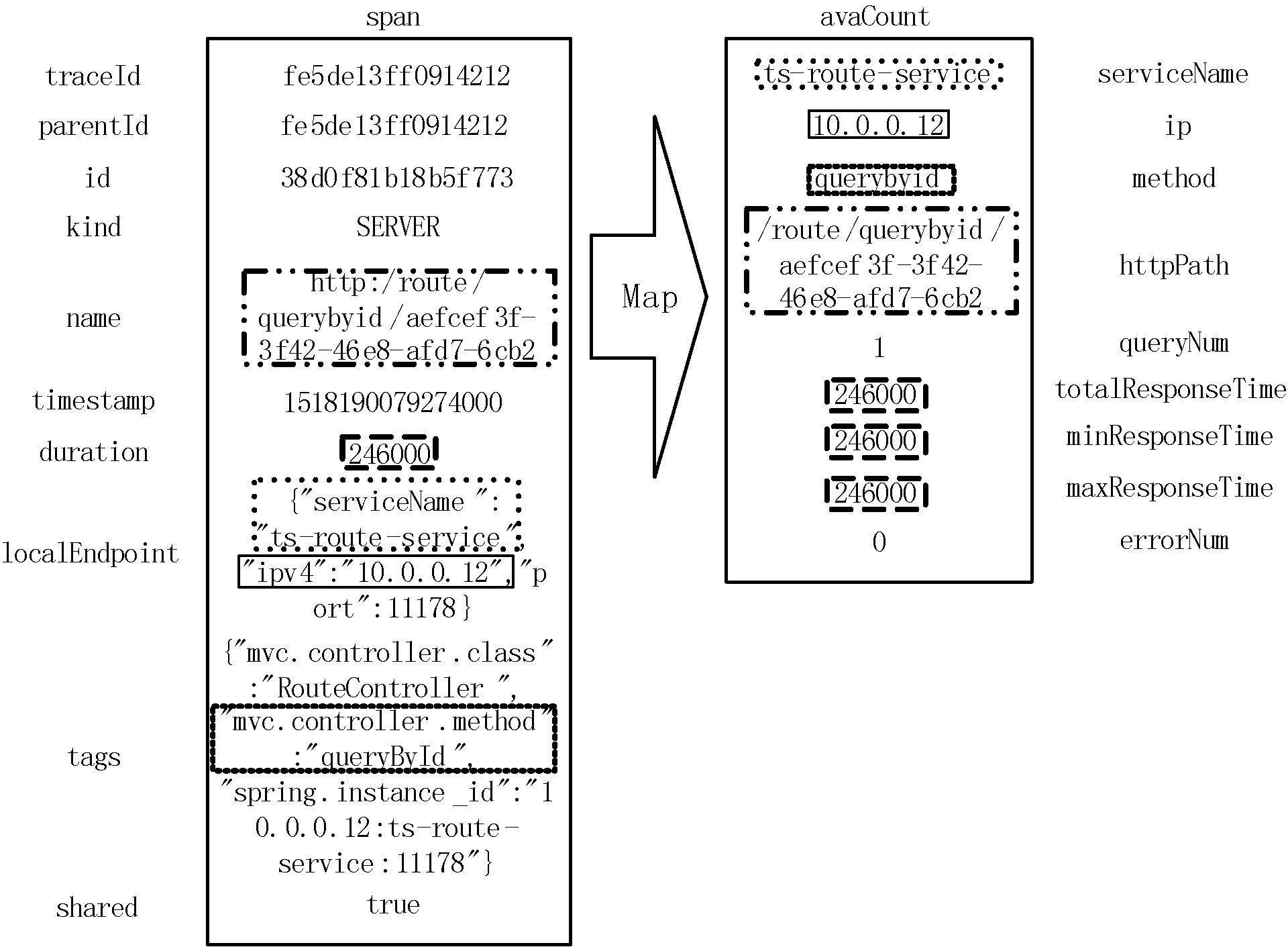
图2 span映射为avaCount示意图
归约过程如图3所示。avaCount1和avaCount2的微服务名称均为ts-route-service、微服务实例IP地址均为10.0.0.12、函数名称均为querybyid,因此可以将avaCount1和avaCount2归约为reduced avaCount。接口名称中可能包含参数,因此取httpPath1和httpPath2的相同部分作为归约后的httpPath。查询数量、总响应时间和错误数量均采用相加的方式归约。最小响应时间取minResponseTime1和minResponseTime2中较小者。最大响应时间取maxResponseTime1和maxResposneTime2中较大者。
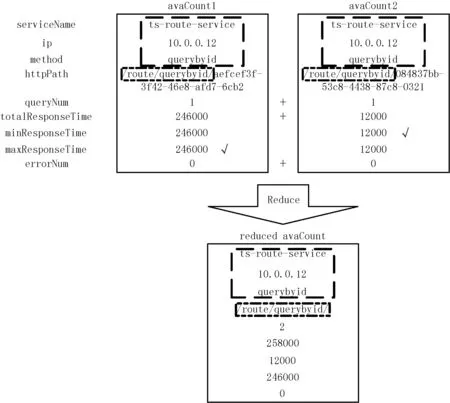
图3 avaCount归约示意图
图4给出了一个基于Train_ticket收集的微服务可用性信息表格,表格共八列,从左到右依次为:微服务名称、微服务实例ID(通常为IP地址)、调用接口名称、查询时间内的QPS、查询时间内的平均响应时间、查询时间内最短响应时间、查询时间内最长响应时间、查询时间内的错误率。表格中第1~6行分别为微服务实例10.0.0.39的6个不同接口的可用性信息,该实例属于微服务ts-order-service。
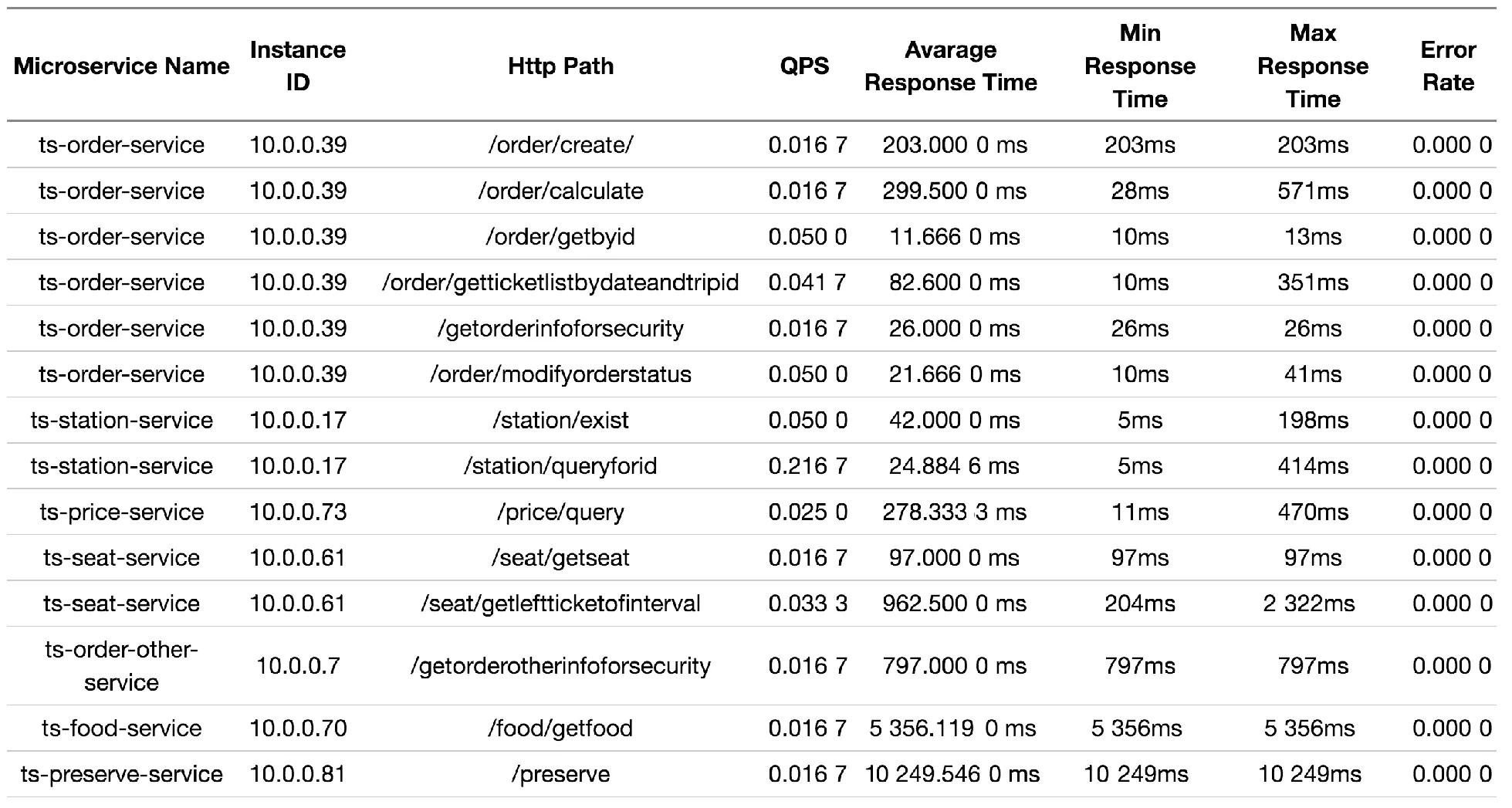
图4 微服务可用性
图5给出了一个Train_ticket中查票微服务的QPS随时间动态变化图。横轴为时间,纵轴为对应时间一分钟内的平均QPS。图6给出了一个Train_ticket中查票微服务的平均响应时间随时间变化图。横轴为时间,纵轴为对应时间一分钟内的平均响应时间。
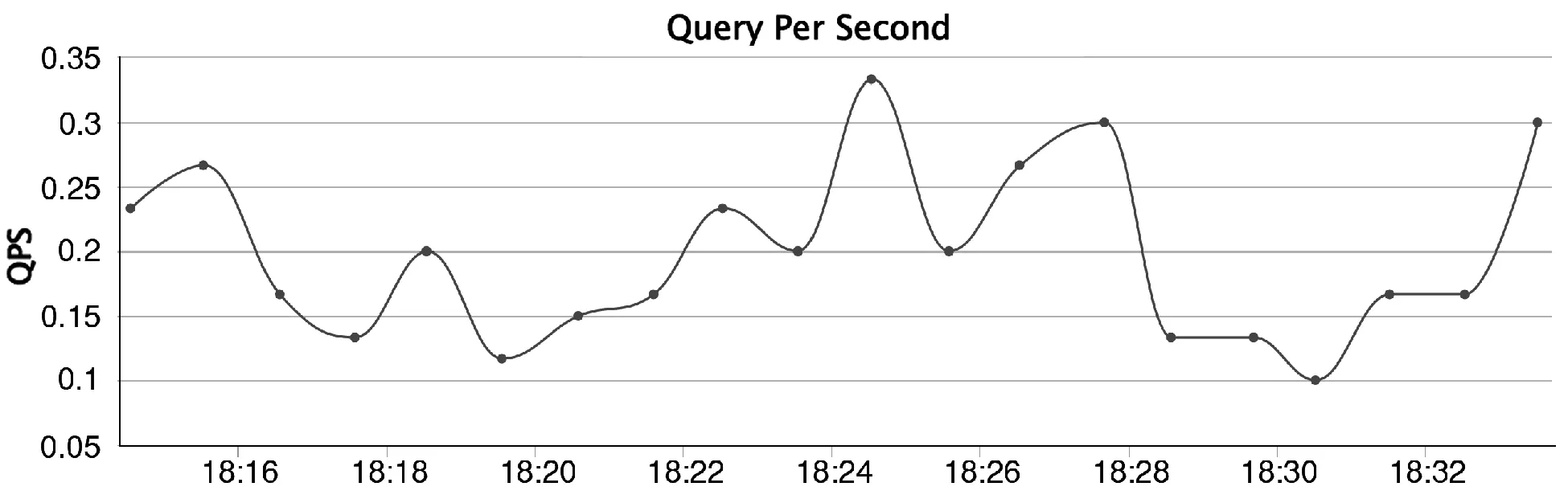
图5 QPS随时间动态变化图

图6 平均响应时间随时间动态变化图
本文基于Zipkin实现了微服务调用链的可视化。微服务调用链可视化展示了微服务间的调用关系,线条粗细表示了微服务间调用次数的多少,线条上标注的数字表示了各微服务调用其余微服务的可能性。图7给出了一个基于Train_ticket收集的微服务调用链的可视化界面,每个节点代表一个微服务,节点上的字母代表微服务的名称。例如:节点ts-travel-service代表微服务ts-travel-service,节点ts-ticketinfo-service代表微服务ts-ticketinfo-service。节点间的有向线段表示微服务间的远程调用关系,位于有向线段起点的微服务调用位于有向线段终点的微服务。有向线段的粗细表示调用次数的多少,越粗调用次数越多。线段上标注了“数字1:数字2”,其中“数字1”代表查询时间内远程调用的次数,“数字2”代表有向线段起点的微服务调用线段终点的微服务的概率。如ts-travel-service调用ts-ticketinfo-service共12次,ts-travel-service有0.400 0的概率调用ts-ticketinfo-service,且通过线段的粗细可以看出:ts-travel-service调用ts-ticketinfo-service和ts-route-service的次数较多、调用ts-seat-service和ts-train-service的次数较少。

图7 微服务调用链可视化
本文实现的可视化监控工具通过调用外部系统接口获取微服务系统线上部署情况。Kubernetes和Docker Swarm等微服务管理工具通常提供了获取微服务实例部署情况的接口。为使开发和运维人员能更直观地了解微服务系统的线上部署情况,可视化监控工具通过3D图形来表示微服务系统的在线部署情况。图8给出了一个基于Train_ticket收集的部署情况的可视化界面,图中每个小球代表一个微服务实例,颜色相同的小球属于同一个微服务。单击小球可看到对应微服务的名称,如图中的ts-food-map-service。可以明显看到小球聚集成两堆,聚集在一起的小球表示对应微服务实例部署在同一台服务器上,横坐标server2和server1则代表着对应服务器的名称。
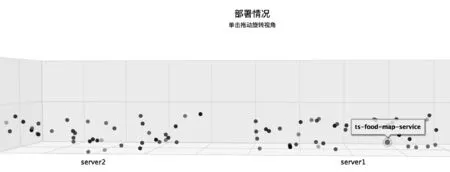
图8 微服务系统线上部署可视化
4 基于MAPE环路的自适应部署优化
本文提出的基于MAPE环路的自适应部署优化方法,由监控模块、分析模块、规划模块和执行模块四部分组成。监控模块负责监控微服务系统中各个微服务的运行情况及服务器的资源使用情况;分析模块根据监控模块收集到的信息,分析各个微服务实例是否过载或空闲;规划模块根据微服务调用链、微服务实例资源使用情况、集群资源使用情况等信息,从分析模块找出的过载和空闲的微服务实例中挑选出需要进行动态伸缩的一组微服务,并生成最终的自动伸缩方案;执行模块根据规划模块生成的自动伸缩方案,通过调用外部系统接口实现动态伸缩微服务。
基于所实现的面向微服务系统的运行时可视化监控工具,本文实现了一个运行时部署优化工具。本文将微服务部署在Docker容器中,并由Docker Swarm管理微服务集群。Docker Swarm提供了spread、binpack、random三种容器放置策略[15]。Spread策略将容器尽可能平均地置于集群中的服务器上;binpack策略将容器尽可能地置于已放置了容器的服务器上,以便将空余服务器用于放置未来较大的容器;random策略随机选择服务器放置容器上。本文采用spread策略,使容器尽可能平均地分布在服务器上。
4.1 监 控
监控模块主要监控以下三项信息:trace信息、服务器上CPU的平均利用率和内存的平均使用情况、各个微服务实例使用服务器CPU百分比。
本文实现的部署优化工具中,监控模块通过可视化监控工具收集对应时间内的trace信息;通过定时采样的方式,收集对应时间内服务器上CPU平均利用率和内存平均使用情况;通过Docker Swarm提供的Docker Stats指令[16],以定时采样的方式收集对应时间内各个微服务实例使用服务器CPU百分比。
4.2 分 析
分析模块通过分析监控模块收集到的各个微服务实例使用服务器CPU百分比,判断各个微服务实例的运行状态,进而判断各个微服务是否获得了足够的资源。
将各个微服务实例使用服务器CPU百分比超过上限的次数称为upper、低于下限的次数称为lower。若某个微服务实例的upper高于阈值,则认为该微服务实例过载;若某个微服务实例的lower高于阈值,则认为该微服务实例空闲。若某个微服务的全部实例过载,则认为该微服务处于资源过少的状态;若某个微服务的部分或者全部实例空闲,则认为该微服务处于资源过多的状态。
在判断微服务运行状态时,本文只通过微服务实例使用服务器CPU百分比来判断,而没有考虑请求数量。因为请求数量会直接表现在CPU利用率上,通过观察CPU利用率便可知请求数量的多少。如果CPU利用率过高,说明该微服务实例正在处理数量较多的请求;如果CPU利用率过低,则说明该微服务实例正在处理数量较少的请求。
4.3 规 划
本文根据调用链和微服务实例资源使用情况,每次挑选一条调用链上需要添加实例的微服务及全部微服务中资源利用率过低需要减少实例的微服务进行动态伸缩。在挑选需要减少实例的微服务时,本文采取的方法类似于Kubernetes,将该轮MAPE循环中资源利用率过低的微服务全部减少一个实例,而不是从一条调用链上挑选。因为通过实验发现,在集群资源固定且有限的场景下,能更快地减少实例就意味着能更快地为需要资源的微服务空出启动新实例所需的资源。
通过分析监控模块收集到的trace信息,可以获得对应的调用链信息。用户对微服务系统的一次请求,通常需要大量的微服务调用来进行处理。例如,网站amazon.com构建每个页面平均需要调用100~150个微服务[17]。被请求直接调用的最外层接口,我们称之为调用链的名称。调用链中包括了调用链的名称及所有被调用微服务的名称组成的列表。
获得了调用链信息后,就可以根据调用链信息和分析模块获得的微服务实例资源使用率超过上限的次数,判断该为哪条调用链上缺少资源的微服务添加实例;根据调用链信息和微服务实例资源使用率低于下限的次数,判断该为哪些微服务减少实例。算法1给出了基于调用链的微服务选取算法。
算法1基于调用链的微服务选取算法
01:输入:监控模块采样次数n,微服务实例超过资源使用率上限的次数microserviceId2Upper,微服务实例资源使用率低于下限的次数microserviceId2Lower,微服务实例id列表microserviceIdList
02:输出:需要添加实例的微服务列表increaseList,需要减少实例的微服务列表decreaseList
03:threshold ← n/2,微服务实例资源使用率超过上限次数大于threshold即为过载,微服务的全部实例均过载则该微服务过载
04:overloadList初始化,过载微服务组成的列表
05:increaseList初始化
06:decreaseList初始化
07:for id in microserviceId2Upper.keySet()
08: if microserviceId2Upper.get(id) > threshold then
09: name ← toServiceName(id)
10: find ← false
11: for id2 in microserviceId2Upper.keySet()
12: if !id2.equals(id) &&
name.equals(toServiceName(id2)) &&
microserviceId2Upper.get(id2) < threshold then
13: find ← true
14: end if
15: end for
16: if !find then
17: overloadList.add(toServiceName(id))
18: end if
19: end if
20:end for
21:callChainOverload ← 挑选出包含缺少资源的微服务数量最多的一条调用链
22: for microservice in callChainOverload
23: if overloadList.contains(microservice)
24: increaseList.add(microservice)
25: end if
26:end for
27:for id in microserviceId2Lower.keySet()
28: if microserviceId2Lower.get(id) > threshold then
29: name ← toServiceName(id)
30: find ← false
31: for id2 in microserviceId2Lower.keySet()
32: if !id2.equals(id) &&
name.equals(toServiceName(id2)) then
33: find ← true
34: end if
35: end for
36: if find then
37: decreaseList.add(name)
38: end if
39:end if
40:end for
算法1第3行,计算threshold。第4~6行负责初始化。第7~20行,针对每个微服务的实例判断所属微服务是否过载。第8行,判断该实例是否过载。第9行,获取该实例对应的微服务名称。第10~18行,查找是否存在属于同一微服务的未过载的不同实例。若存在,说明这个实例过载是负载不均衡导致的,不应该通过加实例的方式解决该实例过载的问题;若不存在,说明该微服务全部实例过载,则此微服务应该增加实例,将其添加到过载微服务列表overloadList中。第21行,针对调用链缓存中的每条调用链,分别计算该调用链上需要添加实例的微服务数量,选择数量最多的一条调用链。第22~26行,将该调用链上需要添加实例的微服务添加到increaseList中。第27~40行,针对每个微服务实例判断是否应该将对应的微服务加入decreaseList中。第28行,判断该微服务实例是否空闲。第29行,根据微服务实例id获得微服务名称。30~35行,判断是否存在属于同一微服务的不同实例,若存在find为true,不存在find为false。第36~38行,将实例数量大于1的微服务加入decreaseList中。
获得了需要增加实例的微服务列表和需要减少实例的微服务列表后,根据集群资源使用情况,综合判断生成最终的部署调节方案。算法2给出了部署调节方案生成算法。
算法2部署调节方案生成算法
01:输入:集群资源利用情况serverResources,服务器CPU利用上限cpu_threshold,服务器内存利用上限memory_threshold、需要添加实例的微服务列表increaseList、需要减少实例的微服务列表decreaseList
02:输出:最终的部署调节方案changes
03:enough ← false
04:for serverResource in serverResources
05: if serverResource.CPU < cpu_threshold &&
serverResource.memeory < memory_threshold then
06: enough ← true
07:end if
08:end for
09:if enough then
10: if increaseList !=null then
11: changes.add(increaseList)
12: end if
13:else
14: if decreaseList !=null then
15: changes.add(decreaseList)
16: if increaseList !=null then
17: if increaseList.size() > decreaseList.size() then
18: list ← 从 increaseList中随机选择m个微服务,其中m=decreaseList.size()
19: changes.add(list)
20: end if
21: else
22: changes.add(increaseList)
23: end if
24:end if
25:end if
算法2第3行负责初始化。第4行,针对每台服务器的资源使用情况进行判断。第5行,如服务器CPU和内存的使用率分别低于cpu_threshold和memory_threshold,则认为该服务器资源充足。只要存在一台服务器资源充足,即认为整个集群资源充足。第9~12行,若集群资源充足,则仅仅为需要添加实例的微服务各添加一个实例。原因在于,在集群资源固定且有空余时,不需要通过减少空闲微服务实例的方式来降低资源消耗。此外,这种做法还可以应对请求突增的情况。第13~25行,对应集群资源不足的情况。第14~24行,对应decreaseList不为空的情况,即存在微服务可以减少实例。第15行,将这些微服务加入changes中,为这些微服务各减少一个实例。第16行,若increaseList不为空,即存在微服务可以增加实例。第17~20行,若increaseList中微服务个数大于decreaseList中微服务个数,则从increaseList中随机选择m个微服务加入changes中,为这些微服务各添加一个实例,其中m为decreaseList中微服务的个数。因此时集群资源不足,当减少m个实例后,粗略认为可以增加m个实例到集群中。第21~23行,若increaseList中微服务个数小于等于decreaseList中微服务个数,则将increaseList中微服务全部加入changes中,为这些微服务各添加一个实例。但如果集群资源不足,且没有微服务可以减少实例时,不添加也不减少任何实例。
4.4 执 行
执行模块根据规划模块生成的自动伸缩方案,通过调用外部系统提供的接口来增加或减少某些微服务的实例数量,从而实现动态地伸缩微服务。Kubernetes、Docker Swarm等当下流行的微服务管理工具均提供了动态调节微服务实例数量的功能。本文实现的部署优化工具中,执行模块通过远程调用Docker Swarm提供的伸缩微服务的Docker update指令[18]来添加或删除微服务实例。
5 实 验
为了验证本文所提出的基于MAPE环路的自适应部署优化工具的有效性,本文进行了仿真实验。本文使用Train_ticket作为微服务系统,将其和本文开发的部署优化工具共同部署,从而进行仿真实验。
5.1 实验设置
服务器为四台虚拟机(操作系统Centos 7、8 * Intel Xeon E5649@2.53 GHz CPU、24 GB内存、50 GB硬盘、10 M/s带宽)。微服务系统和部署优化工具部署在两台服务器上,另外两台服务器部署压力测试工具Jmeter。微服务系统部署在Docker Swarm集群中,每个微服务部署两个实例,每个实例部署在一个Docker容器中,且一个Docker容器中只部署一个实例。
使用Jmeter模拟400个用户的并发访问,请求分别为登录和查票。如表1所示,登录对应调用链包含3个微服务,查票对应调用链包含10个微服务,且两条调用链包含的微服务没有交集。请求到达速度如图9所示,持续时间为35分钟。
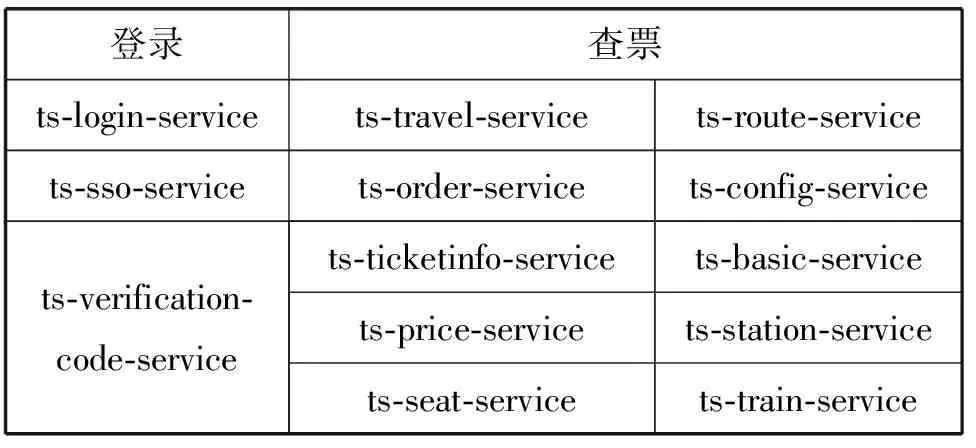
表1 登录和查票对应调用链包含微服务列表
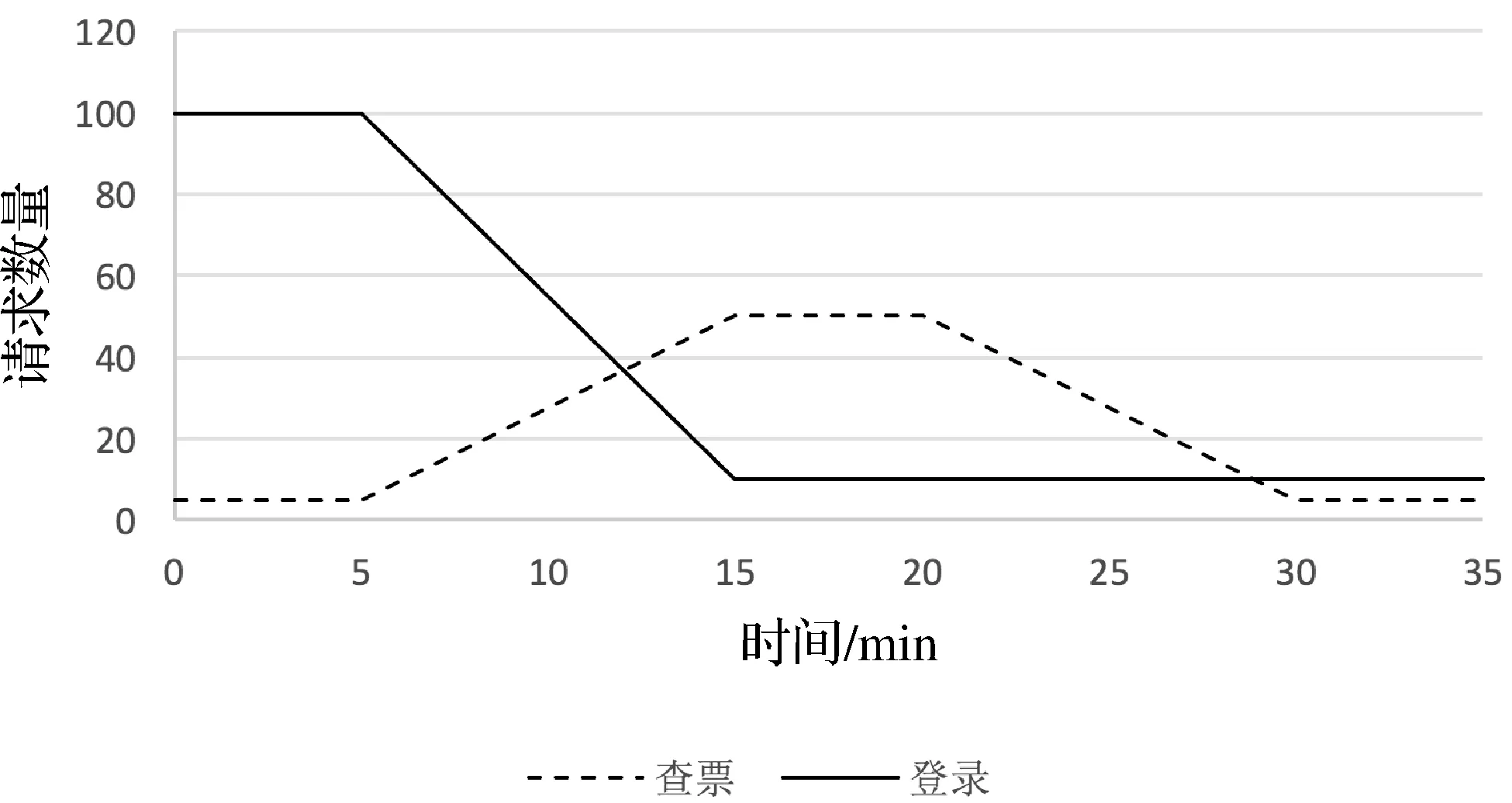
图9 请求到达速度图
5.2 实验结果与分析
登录和查票的平均响应时间随时间变化图像如图10所示。前2分钟登录和查票的平均响应时间均较长,这与订票系统Train_ticket本身相关。在使用Train_ticket过程中发现,系统初启动时明显慢于启动一段时间之后。查看部署优化工具的日志发现,第4分钟由于集群资源不足,触发了扩缩容操作,共有31个微服务缩容、4个微服务扩容。登录相关的3个微服务保持不变,查票相关的4个微服务执行了扩容操作、5个微服务执行了缩容操作、1个微服务保持不变,使得查票的平均响应时间在第4~7分钟变短。
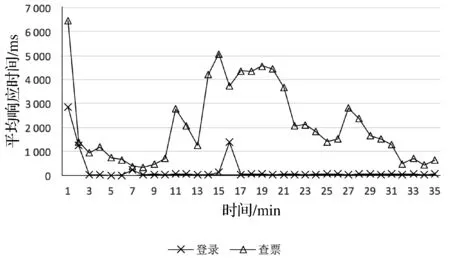
图10 平均响应时间变化图
从第5分钟开始,查票请求数量逐步增加,登录请求数量逐步减少。第7分钟处,查票相关的2个微服务执行了扩容操作,使查票平均响应时间在第7~8分钟略微降低。
第8~15分钟,查票平均响应时间随着请求数量递增,在整体上呈变长的趋势。但在第11分钟处,查票相关的7个微服务执行了扩容操作,使得平均响应时间明显缩短。
第16分钟处,集群资源不足导致同时触发了缩容和扩容操作。登录相关的3个微服务缩容,查票相关的微服务中5个需要添加实例。但由于此时集群资源不足,且需要执行扩容操作的微服务数量多于执行缩容操作的微服务数量。因此从需要扩容的5个微服务中随机挑选了3个进行扩容,分别为ts-seat-service、ts-route-service和ts-station-service。扩容操作在带来查票平均响应时间缩短的同时,缩容操作也使得登录平均响应时间在短时间内急剧变长。随后登录平均响应时间降至正常水平,这与登录的请求数量减少有关。登录相关的3个微服务初始部署时各有2个实例,可正常响应100 req/s(request/s,每秒钟请求数量)的请求到达速度而不触发扩容操作。16分钟后,虽然登录相关的3个微服务实例数量均变成了1个,但登录的请求到达速度已变为10 req/s。
查票的请求到达速度在15~20分钟一直维持在50 req/s。从21分钟开始,查票的请求到达速度开始下降。而在21分钟时,恰好因为20分钟时较高请求到达速度执行了扩容操作,使得第21和22分钟平均响应时间在扩容和请求数量变少的双重作用下显著缩短。
第27分钟处,查票相关的6个微服务触发了缩容操作,导致平均响应时间短暂变长,而后又随请求数量的降低而缩短。
综合以上分析,本文提出的基于MAPE环路的自适应部署优化工具,在集群资源固定且有限的场景下,能有效地调节微服务的实例数量、降低系统整体响应时间。但同时也发现了一些问题,第15~20分钟,查票请求到达速度维持在50 req/s,此时为相应微服务执行扩容操作,虽能够降低平均响应时间,但仍然无法将平均响应时间缩短至第5~9分钟的水平。经分析Train_ticket发现,存在单个微服务的多个实例使用同一数据库服务的情况,如ts-station-service 的四个实例均使用ts-station-mongo。这使得系统的瓶颈转移至数据库处,此时再为ts-station-service增加实例,不能有效降低平均响应时间。另外,从第10~13分钟可以看出,本文提出的基于MAPE环路的自适应部署优化方法有一定滞后性,平均响应时间随请求数量增长一小段时间后,才会触发自适应调节操作。
6 结 语
本文提出一个基于MAPE环路的自适应部署优化方法,在开源系统Spring Cloud Sleuth和Zipkin的基础上,实现了面向微服务系统的运行时监控和部署优化工具,并通过实验验证了部署优化方法的有效性。在集群资源固定且有限的场景下,部署优化方法能有效调节微服务实例数量、降低系统整体响应时间。
本文提出的基于MAPE环路的自适应部署优化方法还存在一些不足。不同微服务实例对服务器资源需求不同,当集群资源不足时需要先减少一些实例再启动相同数量的实例,但这是建立在不同微服务实例需要资源相当的基础上的。在一定程度上,为微服务添加实例可降低平均响应时间,但当实例数量到达一定程度时,系统的性能瓶颈可能转移到数据库等部分,此时继续添加实例无法有效降低平均响应时间。通过实验发现,自适应调节仍有一定的滞后性。
