基于云平台Hadoop的中医数据挖掘系统设计与实现
2018-10-24石艳敏史春晖朱习军
王 倩 石艳敏 史春晖 朱习军
(青岛科技大学信息科学技术学院 山东 青岛 266061)
0 引 言
近年来云计算创新发展、大数据战略、物联网健康发展、“互联网+”行动、人工智能规划等一系列重大决策部署,开启了我国信息化发展新征程。为顺应信息化发展的历史潮流、突破中医药大数据量存储与计算的瓶颈问题,以推进中医药继承创新为主题的中医药大数据应用平台系统的建立迫在眉睫[1]。基于此,本文提出了一个基于云计算平台Hadoop的中医数据挖掘系统,充分发挥云、大、物、移、智在中医药中的作用,采用并行优化的FP-growth算法对中药、症状和证型数据进行关联关系的挖掘,发现其证型与症状间,用药间的关系,从而达到辅助医疗诊断的效果。
1 系统结构与功能
1.1 系统架构设计
该系统选择C/S结构模式,以Hadoop集群作为系统的服务器端,客户端界面使用Java Swing设计,同时借助Webservice技术实现客户端与服务器间的交互。系统总体架构如图1所示。
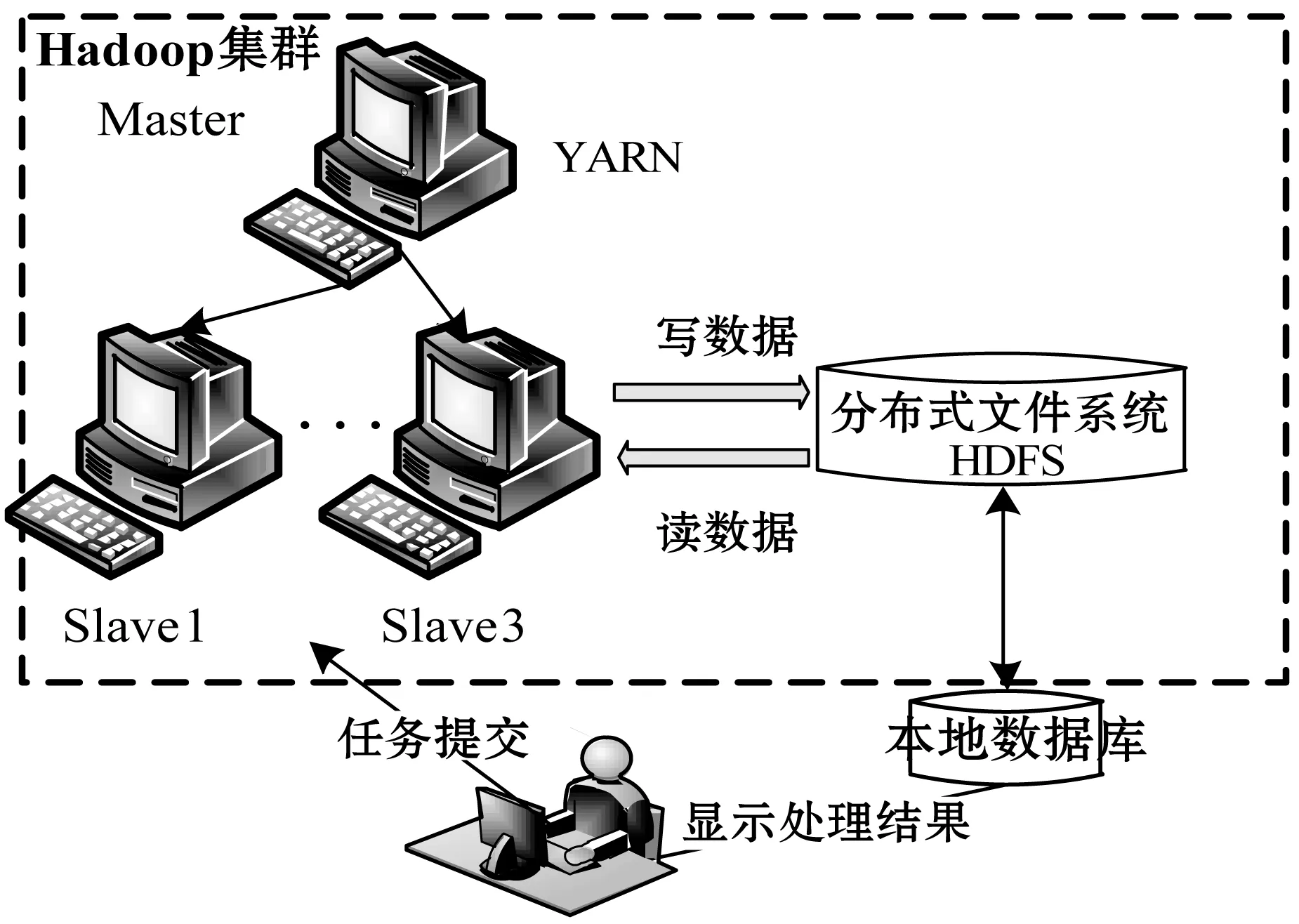
图1 系统总架构
1.2 系统功能设计
系统主要包括数据管理和数据挖掘两个大模块。具体功能描述如下:
1) 数据管理模块 分布式文件存储系统HDFS其分区块存储数据的思想可以有效地提高容错能力及写入性能:将每个区块分为128 MB对数据顺序存储,记录其偏移量,因此即使存储过程某个节点发生故障,在其恢复后数据也能根据其偏移量及区块数继续存储,保证整个系统正常运作防止数据的丢失。其特点很好地解决了中医大量病案数据的存储及安全问题,因此该模块主要通过HDFS实现对中医病案数据的存储管理和数据与本地之间的上传下载。另一方面,MapReduce在执行任务需要将Jar包写入到HDFS中,在读取待处理数据和存储结果时也需要到HDFS读取和写入。
2) 数据挖掘模块 由于中医数据较为复杂,因此在进行数据挖掘之前首先需要对病案数据进行预处理,主要包括:(1) 对原始数据进行规范整理获得症状、证型、用药三种数据类型;(2) 中医药数据及对证型症状的描述均为中文表示,其复杂性不适合作为数据挖掘中的输入,因此需要对中文数据进行数值化处理,完成中文到数字的转换;(3) 最后将处理好的数据存储在HDFS上以便MapReduce任务读取进行挖掘[1-2]。
挖掘类型包括:对用药数据关系的单独分析,从而获得药物组合规律;对症状与证型进行挖掘分析其关联性;将症状、证型和用药数据组合进行挖掘获取其关联性。
2 算法设计与实现
2.1 并行化设计的FP-growth算法
由于关联规则经典算法Apriori算法需要多次遍历数据集来构造候选集、筛选候选集而获取频繁项集。当处理大数据量时将会造成系统的 IO 负载过高。另外若支持度阈值较小,那么通过自连接产生候选项集的计算量将非常庞大又耗时;若支持度阈值过高,虽能提升计算效率但挖据获得的有效信息又会变少。
针对Apriori算法计算时产生大量候选项集的问题,Han等提出了FP-growth算法[3],它采用前缀树的形式来表示数据,在计算过程中只需要扫面两次数据库,然后递归地生成条件FP-tree来挖掘频繁项。这有效地解决了传统Apriori算法需要多次扫描数据库的问题。然而在处理大数据量时,FP-growth算法也有一些弊端:大数据量导致其生成的FP-tree有可能非常大,以至于无法放入内存;另外大数据量也会导致挖掘到的频繁项数量非常巨大。
针对以上问题,本文对Fp-growth算法在中医药数据的处理上从两方面来进行优化:
1) 将待处理数据切分成多个数据片段分别存储到Hadoop集群的多个节点中,以此来保证整个集群的读写性能。然后通过MapReduce任务并行的处理节点上每个job中的数据[4]。即通过划分数据库来突破空间复杂度的瓶颈。
2) 对于构造的项头表中一些频度相同的频繁项,若在排列时顺序不同将会构造出不同的fp-tree,从而有可能会导致构造出的fp-tree过大,因此在构建fp-tree时可以通过对项的顺序动态调整来寻找最优化的fp-tree,以此节省存储空间[5],提升计算效率。
图2为FP-growth算法进行MapReduce优化的流程图。
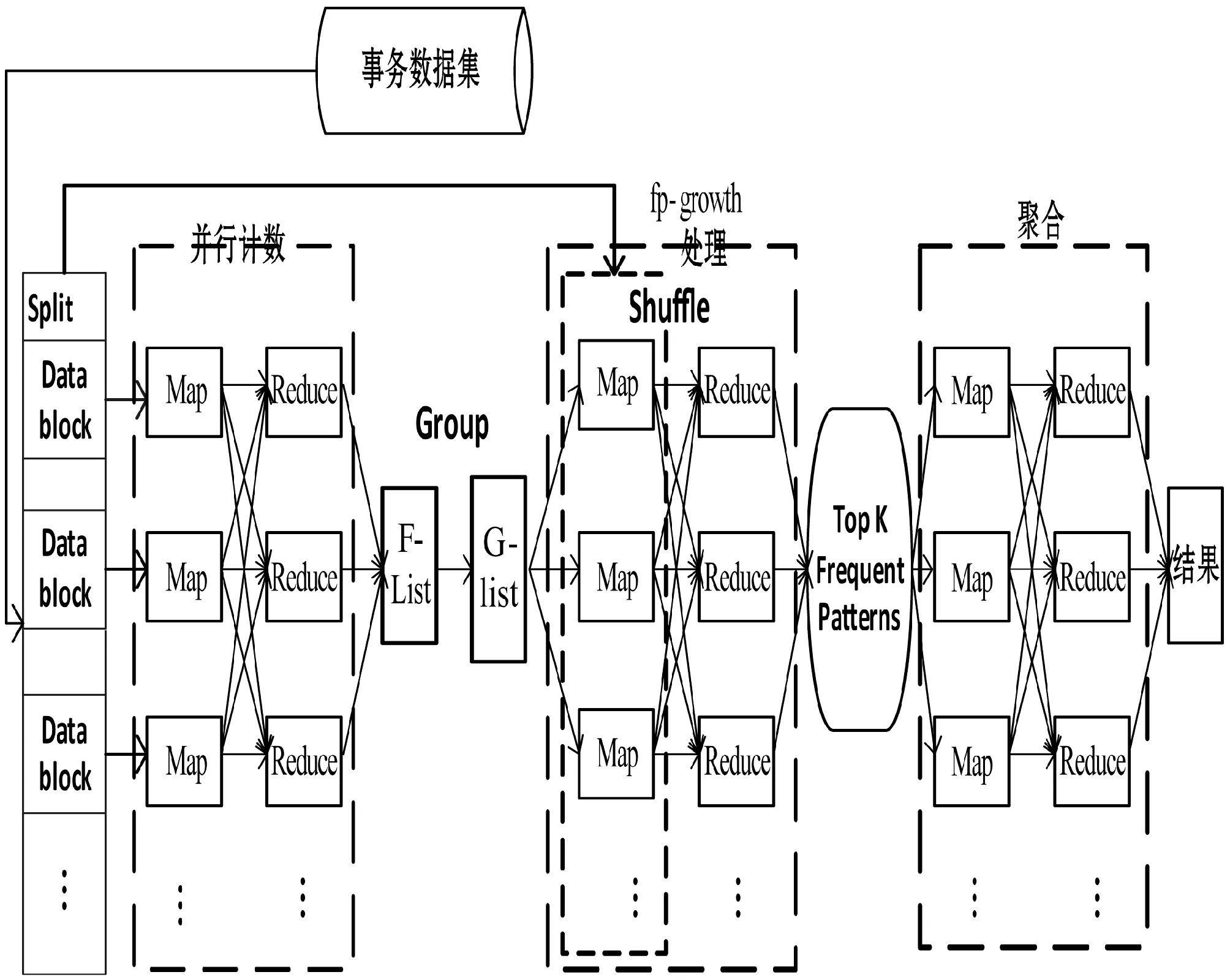
图2 FP-growth算法并行化实现流程图
算法实现总体分为五个阶段:
1) 数据分片:将大量数据划分在多个Datanode节点以区块方式存储。
2) 并行计算获取F-list(项头表):通过Map()与Reduce()任务计算支持度存入F-List,其中每个Mapper对应一个区块。
3) 对F-list分组:每组赋予一个唯一的组ID得到G-List。
4) 并行化FP-growth:Mapper首先读取G-List中生成的groupid,然后将第一步生成的每一个数据片作为Map()的value值。扫描value中的每一个项,若项Vn在G-List中所对应的groupid是第一次出现,则输出V0~Vn的项,否则不输出数据。将所有groupid相同的数据放到同一个Reduce中,由Redeuce()递归构造fp-tree挖掘频繁模式。
5) 结果整合:Mapper对上一步中每个不同groupid的Reduce节点上的频繁模式进行处理,由Reduce()汇总Map()的输出获得最终的结果。
由图2可见,这五个阶段共使用三个MapReduce的Job来完成。
2.2 FP-growth算法应用实现
1) 中医药数据关联规则挖掘 根据上述FP-growth算法的并行化设计方案,将某医院中医呼吸科临床数据分类整理与规范化,然后对数据统计编号完成数值化便于机器处理[6-7]。
中文数据的数值化处理主要是将三种数据类型依次按顺序编号,编号之间以逗号作为分隔符,主要由Java编程中的Map()函数完成。数值化处理后的数据每如I={ 131,72,252,162,154,233,126,138,96,91,88,101,92,195,16,140,161,111,212,240,2}所示,该数据表示的是表1所示的一条事务项数据内容。

表1 算法的一条事务项数据内容
挖掘过程主要分为两步:
(1) 将处理好的数据上传至HDFS作为输入数据。
(2) 将实现挖掘的Java代码打包后通过命令行来设置数据的输入及输出路径支持度等参数,然后提交至集群执行MapReduce任务。
2) 挖掘结果分析 并行化算法运行结束后,首先获得第一次构建FP-Tree树产生的后缀模式的条件模式基,如图3所示,输出结果为key-value形式。然后对结果进行关联规则计算,输出结果形如[233,140,16]=>2:supp=0.250,conf=0.729,其中supp代表支持度,表示[233,140,16]与2同时出现的概率为0.250;conf代表置信度,表示[233,140,16]出现的情况下2出现的概率为0.729。而数字16、2、233、140则是对中文中医数据的编码。因此为了更直观清晰地分析出数据之间的关联规则,需要将挖掘结果转换为中文表示,同样主要由Java编程中的Map()函数实现。将部分挖掘结果汇总如表2所示,该表包含了证型与症状、药物与症状、药物与药物之间的规律。

图3 部分后缀模式的条件模式基
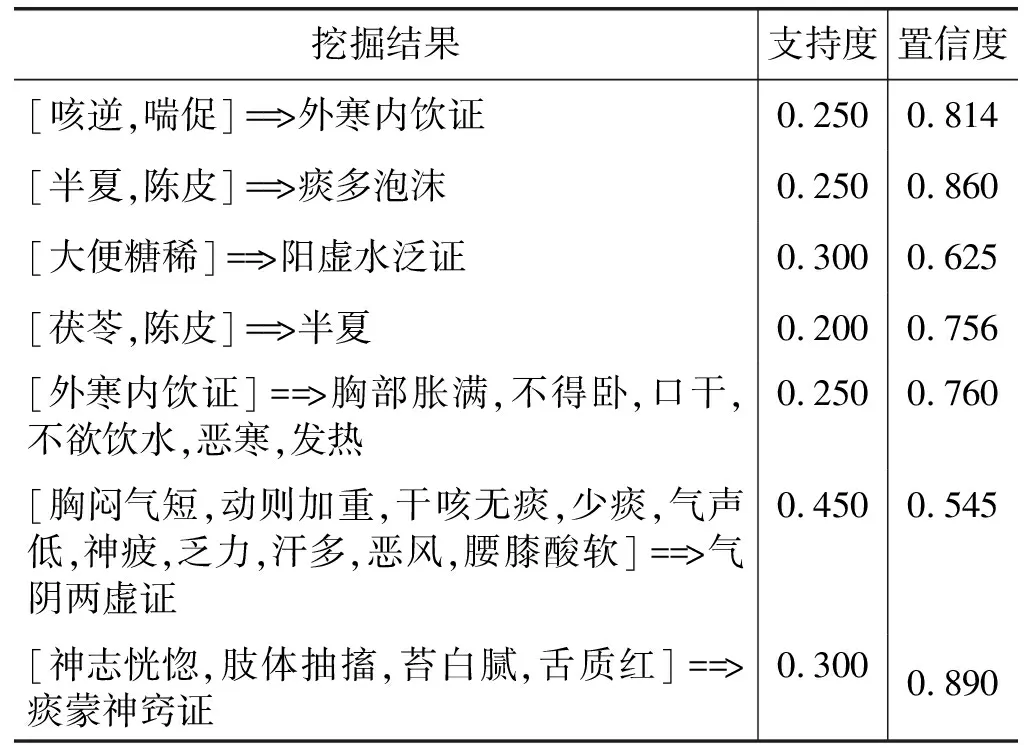
表2 部分挖掘结果示例
通过分析表2发现:
1) 半夏,陈皮,茯苓该组药物同时出现的频率很高,经查阅相关资料得知,半夏主治燥湿化痰,降逆止呕,痰多咳喘,痰饮眩悸,风痰眩晕等症状;陈皮主要用于脘腹胀满,食少吐泻,咳嗽痰多;茯苓则用于脾虚食少,痰饮眩悸,惊悸失眠等症状。分析发现半夏,陈皮和茯苓均用于痰多咳嗽症状且有化痰的功效,这也与表2中挖掘出的:[半夏,陈皮]==>痰多泡沫这项结果相符合。证明本次实验挖掘得到的中医用药与症状之间的关系符合实际与实践。
2) 发现了一些证型中的核心症状表现,如表2中的气阴两虚证:此证型同时与胸闷气短,动则加重,干咳无痰,少痰,气声低,神疲,乏力,汗多,恶风,腰膝酸软等症状频繁出现,其支持度较高;反之,若当患者出现如上几个症状,可以考虑患者有可能患气阴两虚证。
3) 表2中最后一项痰蒙神窍证与其症状间关系的置信度高达百分之八十九,表示神志恍惚,肢体抽搐,苔白腻,舌质红这些症状出现的情况下,患者所患的病症为痰蒙神窍证的概率达89%。而查阅相关资料发现痰蒙神窍证的主要症状为神志恍惚,抽搐,苔白腻或黄腻,舌质暗红,脉细。证明挖掘结果有效可靠有效,符合实际情况。
3 系统环境搭建及实现
3.1 Hadoop体系结构
Hadoop被公认是一套行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力。它主要解决了三大问题:通过HDFS实现海量数据的存储、MapReduce实现海量数据的计算与分析、YARN实现资源的管理调度。
数据量越来越多,在一个操作系统管辖的范围存放不了,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件系统HDFS。其中NameNode是整个文件系统的管理节点,它维护着整个文件系统的文件目录树,同时接收用户的操作请求。而Data-Node则提供真实文件数据的存储服务。
MapReduce是一种分布式计算模型,主要用于解决海量数据的计算问题。MR由两个阶段组成:Map和Reduce,每个Map处理一个块的内容,当所有Map都处理完之后再通过Reducer进行合并。用户只需要实现map()和reduce()两个函数,即可实现分布式计算。MapReduce运行在YARN之上,Yarn中的ResourceManagger用来管理资源的分配调度,NodeManager负责具体任务。
3.2 集群规划说明
系统基于Linux环境,通过6台PC机组成6个节点搭建Hadoop 2.7.2 集群作为服务器。集群部署规划如表3所示:考虑到NameNode和ResourceManager要占用大量资源,因此将二者分别配置在两个节点中,从而减轻资源使用的压力。将DataNode和Node-Manager分别配置在三个节点中,由于NodeManager有多个,因此它通过心跳机制与ResourceManager保持联系同时主动领取MapReduce任务,以此减轻Resource-Manager作为管理者的压力。另外考虑到集群的负载均衡与HA问题,采用QJM解决方案使得主备NameNode之间通过一组JournalNode同步元数据信息,共配置三个JournalNode。同时将分布式协调服务Zookeeper配置到集群中用于DFSZKFailoverController的故障转移,当Active NameNode产生故障时会自动切换Standby NameNode为Active状态,保证了整个集群的正常运作[8]。表3中QuorumPeerMain为Zookeeper的进程。
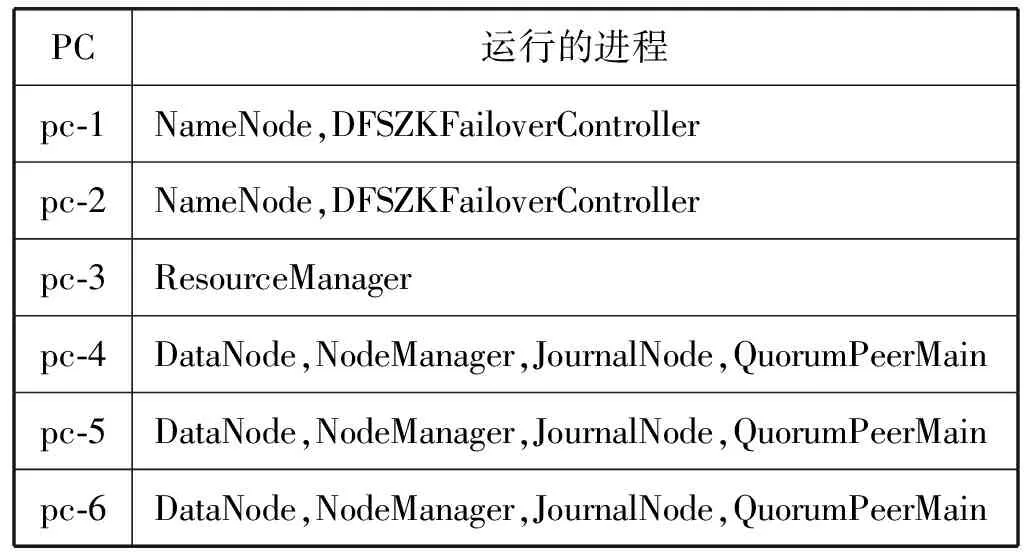
表3 集群规划部署表
3.3 系统实现
系统通过Webservice技术实现集群连接,文件上传/下载,Job任务提交等,最终完成服务器之间的交互。
向集群提交MapReduce任务时,后台远程调用Webservice提交任务,将请求任务加工成soap包后提交至YARN,各节点任务结束后将结果汇总存储到HDFS上。这时可以在系统界面对结果进行、下载,或者将结果加载展示在系统界面[9]。
系统在进行挖掘时,需要设置的参数包括:待处理的数据源,关联规则算法,支持度与置信度,HDFS的结果存放路径。如图4所示,设置好相关参数后选择要执行的算法jar包提交任务,点击执行后系统立即执行挖掘。如章节一中系统集群配置模块中所述,挖掘过程中可在集群监控中查看任务进度与状态,以便于及时发现问题,保证挖掘任务的顺利进行。
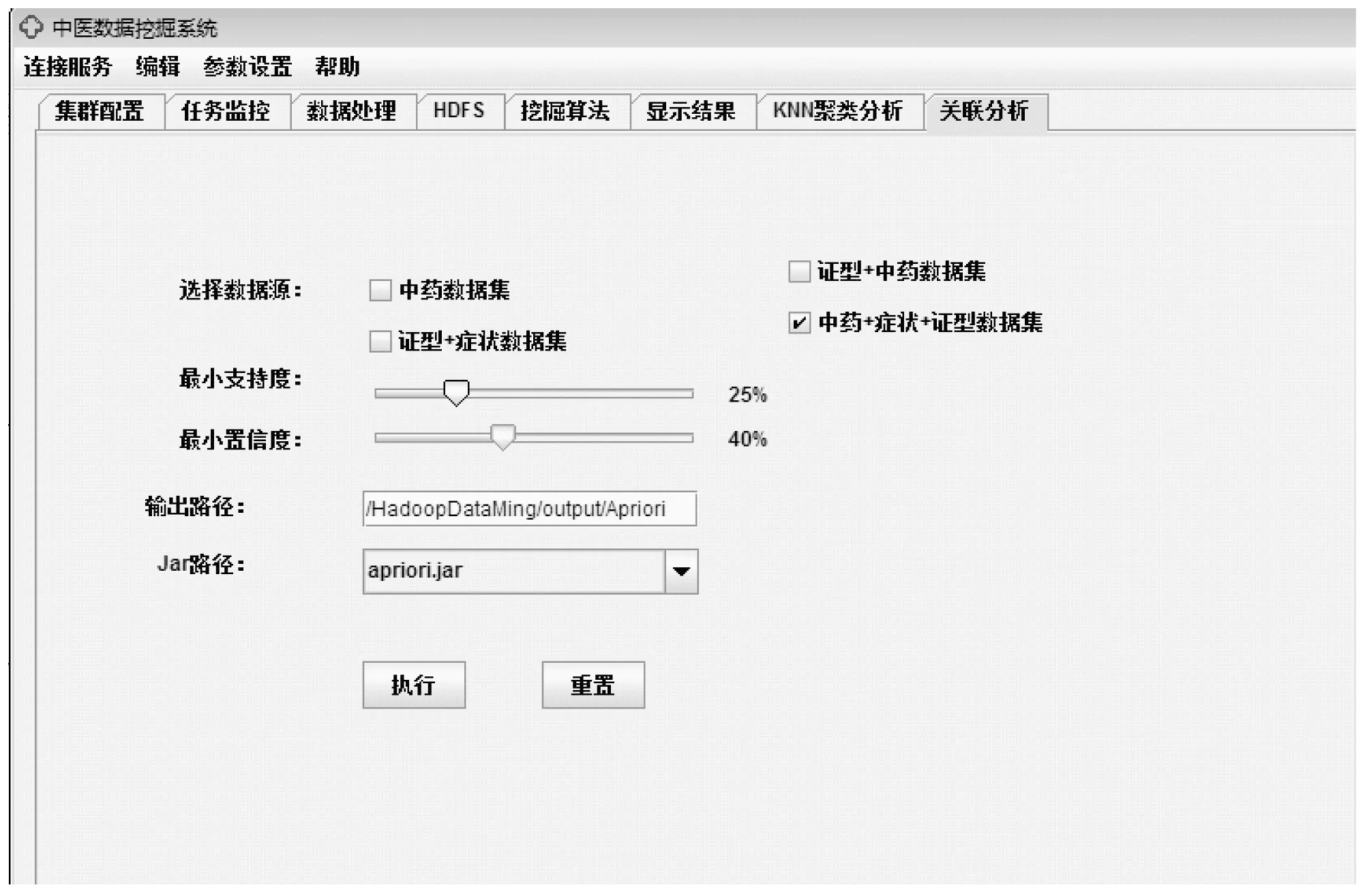
图4 关联模式的挖掘
如图5所示,若监控任务显示挖掘任务运行成功,选择结果显示中的加载结果文件,选择数据转换将结果转换成中文,或将结果导出再进行分析。
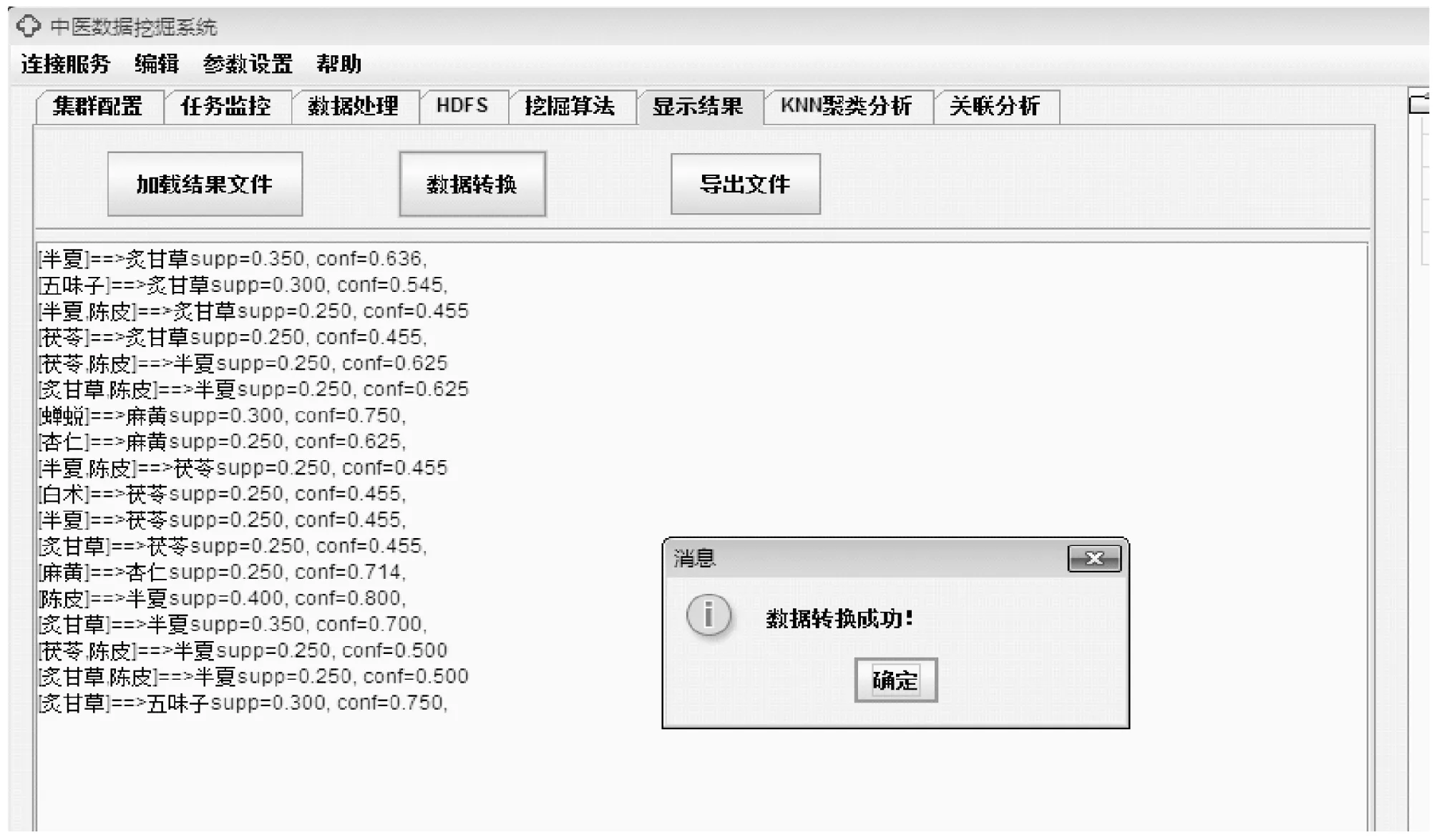
图5 挖掘结果展示
4 结 语
本文在Hadoop平台上设计实现了一个集中医药数据管理和数据挖掘功能于一体的中医数据挖掘系统,并对系统所提供的功能进行了比较详细的分析与设计。相比于中医数据挖掘的已有研究,本文具有以下创新点:1) 为避免Apriori算法产生大量候选集导致的大计算量问题,对FP-growth算法并行化设计:将数据存储在多个节点中并行计算,提高存储与计算效率;2) 系统在具备传统中医数据挖掘系统的基本功能的前提下,通过引入Hadoop体系结构,实现了对中医大数据量更完善、更安全的存储和更高效、更准确地挖掘计算,从而完成了一个比传统专家系统计算效率更高的中医数据挖掘系统。结果证明在Hadoop平台上将FP-growth算法并行化并应用于中医大数据量的进行挖掘具有一定的可行性,其效率更高、结果更准确。这为中医药健康大数据的应用奠定了基础,也推动了互联网与中医药健康服务深度融合发展。
