一种基于比较的专利文献检索方法
2018-10-23周文强
周文强 徐 建 张 宏
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
专利文献是维护公司利益的重要智力资源。与一般的Web文档不同,专利文献通常有固定的格式要求,长度较大,并且包含大量的专业词汇[13]。专利文献的这些特征使得人工进行专利分析是十分耗时耗力的。因此,近年来出现了专利检索这一新的研究领域,目的就在于协助专利分析师检索、处理并分析专利文献[1,4,11]。在实际应用中,专利检索任务需要根据具体的检索目的进行具体分析。其中,基于比较的专利文献检索的目的是通过专利文献的比较,检测出专利文献之间的可替代性或新申请专利的可专利性。得出的摘要有助于专利分析人员快速了解两篇专利之间的关联性,从而降低专利检索任务的成本。
为了使专利文献内容更容易理解,Shinmori等[5]通过自然语言处理的方法降低结构的复杂度。虽然这种方法都在一定程度上提高了专利文献的可读性,但是在专利文献之间的比较上,还需要耗费大量人力。另一类提高搜索结果准确性的方法是使用摘要表示原始的专利文献。Trappey等[7]提出一种基于聚类的方法将本体论的概念和空间向量模型的概念相结合。这种方法可以提取出专利的主要信息点,但是它们无法得出专利之间的差异性。
一般的专利检索任务通常需要测量出两个专利文献之间存在多少的相似性(或差异性)[2~3]。如果能够提供两个专利文献之间的比较性摘要,那么这一过程将会得到有效的化简。因此将专利文献的比较问题看作是摘要提取问题。普通文档摘要提取的目的是找出文章中的主要内容,但是大多数的摘要提取方法无法提供文章之间比较的信息。比较性摘要方法(comparative summarization)的提出[9]为解决专利文献间的比较问题提供了一种新的思路。一些用于专利的比较性摘要方法可以提供两个专利的摘要[12],但是无法直观地看出两个专利之间的联系,并且得出的比较结果无法根据用户的不同需求进行调整。为此,提出一种改进性的方法。这种方法首先从每个专利文献中提取出可以进行判别的项,然后通过基于图论的方法将这些项在同一个图中进行连接。并且通过用户自定义的停用词,快速地得出用户想要的结果。总而言之,该方法有以下三个特点:
1)将比较专利文献的问题转化为比较性摘要的问题;
2)使用基于图的方法提取出专利之间的相同点与不同点;
3)加入用户自定义停用词,使得提取出的信息更满足用户需求。
2 问题提出与解决方法
2.1 问题描述
假设有两个待比较的专利 p1和 p2。每个专利文档都有若干语句组成,即。两个文档的比较问题本质上是一个比较性摘要生成问题,分别选择一个有相同长度L的语句子集s1⊂p1,s2⊂p2。s1和s2可以分别代表 p1和 p2的主要内容,也可以将s1和s2分别划分成几个部分,每个部分都代表着一个特定的方面。出于分析的目的,摘要应该具有很高的质量,提取出的摘要需要在尽可能少的冗余信息下包含尽可能全面的专利特征。
通常情况下,比较可以确定对象间的相似性与差异性。因此,生成比较性摘要需要文档中有代表性的信息,并且包含尽可能多的比较性依据。特别地,给定两个文档,比较性摘要问题是通过提取每个文档中差异性最大的语句为每个文档生成一个简短的摘要。这一问题与普通的文档摘要问题有相似之处:它们都需要通过提取文档中的语句生成内容摘要。但是不同的是,普通文档摘要的目标是包括文档集中的绝大部分信息,而比较性摘要的重点在于寻找文档间的差异性。
2.2 比较性摘要方法
为了解决已知解决方案的局限性,提出一种改进性的方法。这种方法的构建流程如下:
1)选取可区别的特征:给定两个专利,分别将它们作为一个类,并且进行特征提取,选择出有差异的项(如,名词)。
2)构造特征图:通过原始专利文档中的特征共性信息构造无向特征图,并且在图中标记出有差异的特征。
3)提取代表树:基于差异性的特征,在特征图上提取出两个专利的共同信息。使用树形结构表示这些差异性与共性。
4)生成比较性摘要:通过得出的特征树中有连接的点挑选出两个专利文档中的语句,并通过用户自定义的停用词进行进一步筛选。最终得出的摘要包括了专利间的差异性与共性。
下面对上述流程进行详细解释:
1)选取可区别的特征
每个专利文档通常有自己独特的地方。例如,技术型专利通常在他们的发明中使用不同的技术。因此需要在文档中提取出能代表这一文档特性的项,通常以名词为主。将每个专利文档作为一个类,每个名词或名词短语作为一个特征。这就将问题转化为特征选取问题。
形式上,假设从两个专利中选取t个特征变量,定义为{xi|xi∈F},其中F是完整的特征索引集,|F|=t。类变量C={c1,c2}(即,两篇专利c1,c2)。特征选取问题就是选取一个特征的子集,S⊂F,然后准确的预测出目标的类变量C。进行特征选取的方法有很多,例如,基于信息理论的方法(如信息增益、互信息),以及统计的方法(如x2统计)。此次使用x2统计的方法,这种方法以及在文本挖掘领域得到成功的应用,方法如下:
在统计学中,x2统计量经常用来检测两个事件的独立性。在特征选择中,两个事件分别指词项的出现与类别的出现,计算公式如下:

其中,et=1表示包含特征t,否则et=0;ec=1表示在类变量c1中,否则ec=0;N表示出现频率;

其中|{v1|v1∈A}|以及|{v2|v2∈A}|分别表示v1和v2在文档A中出现的频率。|{(v1,v2)|v1∈A,v2∈A}|表示在A中v1和v2出现在相同语句中的次数。ωA(v1,v2)本质上描述了v1和v2在A中共现的概率。给定两个文档A和B,若v1和v2在A与B中的平均链接指数都超过一个规定的阈值,就连接v1和v2。
3)提取特征树
从特征选取中获取的可区分特征可以表示专利文档之间的区别。但是,这些特征之间可能会存在一定差距,也就是说,它们可能无法在特征图上很好地连接。为了得到一个结构流畅的比较性摘要,需要发现可区别特征之间的关系,这可以通过连接可区分的顶点与两专利文档共有的顶点达到。同时,生成的摘要应该尽可能的密集、详尽,即,通过最少量的特征表示出主要的共性/差异。
通过制定最小Steiner树解决问题。给定图G(2)中的特征图)以及顶点S的子集,G的Steiner树类似于最小生成树。定义为用尽可能少的边包含整个S的G的子树。
定义:给定图G=(V,E),顶点集S⊂V以及任意顶点v0∈S。最小Steiner树(MST)的问题是找出G中以v0为根并且包含S的最小子树。
MST问题是一个NP-hard问题。使用递归的方法生成Steiner树T解决这一问题。这里需要用到级别参数i≥1。当i=1时,算法找出k个离根v0最近的终点,并且用最短路径将它们与v0相连。通过查询x2分布表,就可以得知特征t与专利c之间是否独立。若不独立,则认为t是c的一个可区别特征。
2)构造特征图
步骤1)中提取的可区别特征主要用于描述专利之间的不同之处。因为两个专利文档的比较性摘要应包含不同点和相同点,所以使用基于图的方法更加准确地得出这些相同点。
构造无向图G代表两个专利文档,G=(V,E)。G中包含一组顶点(即,特征)V,每个顶点代表专利文档中的一个名词/名词短语。两顶点只有在它们共同出现在同一语句中才进行连接。特别地,定义在单一文档A中两个顶点v1和v2的连接指数如下:因为特征图中的每一个顶点都可以连接到其他任一顶点,所以在V中随机地选择出v0。当i>1时,算法反复寻找顶点v,v与第i次输入的根相邻。K′是更新树的最小成本,这里的成本通过边的数量进行计算。在获得了预期的路径之后,更新相应的Steiner树、目标大小k以及终点集S。
4)生成比较性摘要
步骤3)中的Steiner树为生成两个专利文档间的比较性摘要提供了基础。选取出可以完全覆盖Steiner树中特征的原始文档语句最小集。每个语句可以代表特征图的一个子图(Steiner树也可视为一个子图)。因此,需要选取覆盖Steiner树的子图的最小集。定义两个图的联合Ga=(Va,Ea)以及Gb=(Vb,Eb),Ga∪Gb=(Va∪Vb,Ea∪Eb)。生成比较性摘要的问题可以看作找出子图中联合覆盖了Steiner树的最小子集。
定义:给定图G=(V,E),一组子图S,以及G的Steiner树T,子图覆盖问题(SGCP)是找出最小子图集C⊂S的问题。其中联合U=(VU,EU)覆盖T中所有顶点和边。
SGCP问题与集合覆盖问题(SCP)紧密相关。SCP是一个NP-hard问题。集合覆盖问题的贪婪算法选取集合有一个规则:选取在每一次迭代中包含最多已发现元素的集合。这个算法可以得出H(s)的近似比例,其中s是被覆盖集的大小,H(m)是第m次谐波级数:
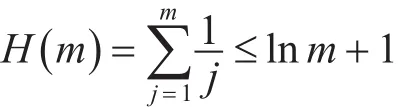
在得到了比较性摘要之后,可以通过用户自定义的停用词,对结果进行进一步的筛选与化简。
3 实验设计与分析
本次实验所选的专利文档数据集来自润桐RainPat专利检索网站(http://www.rainpat.com/),以计算机软件程序的装载或启动类的中文专利为主,发表时间从2012年到2016年,共约3000篇。下面分别使用两种评价方法进行测评。
3.1 Edmundson测评
Edmundson评价方法比较简单,可以客观评估,就是通过比较机械文摘(自动文摘系统得到的文摘)与目标文摘的句子重合率的高低来对系统摘要进行评价。随机以1000对专利作为训练集,500对专利作为测试集,得出的平均Edmundson值为76.39%,可以看出这一方法可以较好地总结出专利的摘要。
3.2 ROUGE 测评方法[14~15]
ROUGE测评方法目前已经广泛地应用于文档摘要质量的评估。给定一个系统生成的摘要以及参考的标准摘要集,ROUGE方法通过单元重复计算的方法评估摘要的质量。
3.2.1 与现有方法进行比较
五种不同方法下的ROUGE值如表1和图1所示。其中,Minimal Dominate Set方法(MDSM)[10]从每个专利中选取最具有代表性的语句。Discrimi⁃native Sentence Selection方法(DSSM)[8]选取每个专利中最具有差异性的语句表现不同专利的特点。Comparative Summarization via Linear Programming方法(CSLPM)[6]将不同主题的概念对作为专利之间差异性的依据,将相关概念作为专利之间相似性的依据。PatentCom方法通过专利之间的比较生成专利的摘要。这些ROUGE值取超过300对的专利文档ROUGE平均值。从中可以得出:1)基于比较的方法与PatentCom方法在各ROUGE值上的表现接近,优于其他三种方法;2)DSSM方法在四种方法中表现较差,这表明只考虑到专利间的差异性对于生成专利特征是不够的。这是因为差异性可能不是专利特征中最重要或者最具有比较性的因素;3)MDSM方法在ROUGE-1值上表现较好而其他ROUGE值上远不如CSLPM方法,这是因为MDSM方法会选取出每个专利的重点句,所以最终的摘要会包含专利中的常用词。这样会与基于单一字节的参考总结有明显的重叠,这与ROUGH-2、ROUGH-W、ROUGE-SU的测量目的相悖,所以导致了MDSM方法在这三种ROUGE值上偏低。
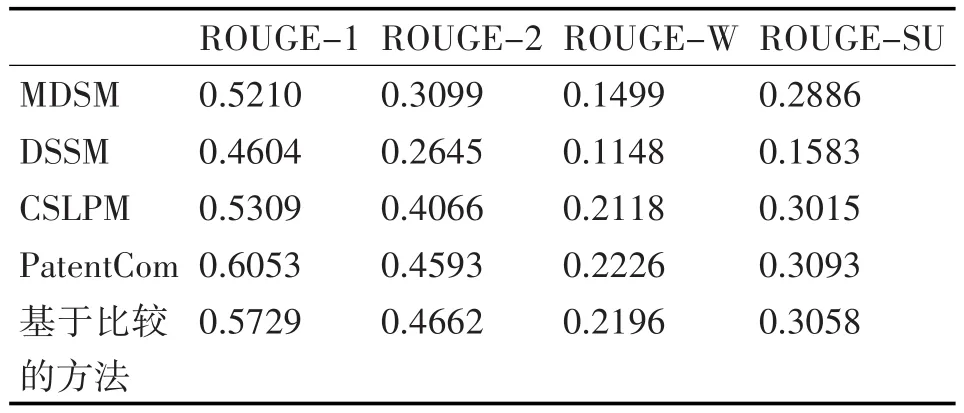
表1 不同方法下的ROUGE值比较
图1 不同方法下的ROUGE值折线图
3.2.2 对专利的不同部分进行比较
标准的专利一般包括发明摘要、方案说明、声明等部分。其中的一些部分具体描述了专利发明的方案细节,而有一些部分概括了专利的整体情况。为了评估每一部分在提供比较信息方面的重要性,需要生成不同部分的比较性摘要。本次实验中,对发明摘要(S)、方案说明(E)、声明(C)以及整体专利(A)四个部分进行比较,结果如表2和图2所示。从表中可以看出,声明和方案说明部分一起进行实验时,平均的各项ROUGE值都较高。这是由于声明部分是整个专利的核心部分,而方案说明部分包含了专利发明的绝大部分具体细节,这就为生成一个高质量的比较性摘要提供了更大的可能性。

表2 不同部分的ROUGE值比较
图2 不同部分的ROUGE值折线图
4 结语
本文主要研究了对比专利文档的相关问题,以此检测专利之间的可替代性或者新申请专利的可专利性。将此次需要解决的问题视为一个提取比较性摘要的问题,并且设计了一种自动提取给定专利文献之间比较性摘要的新方法。得出的摘要有助于专利分析人员快速地了解两篇专利之间的关联性,从而降低专利检索任务的成本。实验部分通过约3000篇计算机软件程序的装载或启动类中文专利证明了文中提出的新方法的有效性。在今后的研究中计划在选取特征时,为专利的各部分分配不同的权重,希望以此进一步提高方法的准确率。
