基于langid模型的多语言微博识别研究
2018-10-18郭倩倩
郭倩倩
(新疆大学信息科学与工程学院,乌鲁木齐 830046)
语言识别;langid模型;微博
0 引言
计算机技术日益成熟,互联网的浪潮席卷着地球每一寸土地。越来越多的文化、教育等活动延伸到不同的民族、不同的国家。学者们走出国门参加国际学术会议,不仅是对个人工作的认可,也加速了各国学术技术之间的交流;跨国企业先后在全球范围内寻求最具优势的合作伙伴:越来越多的国内人为了感受异域风情从而选择境外旅游。这些活动使人与人之间的交往更密切,以及促进了科技文化等的共同进步。然而语言之间的难以沟通障碍阻碍着时代的发展。Freeno⁃de Network的创始人Rober Levin曾说过:The last barri⁃er for global E-Commerce is the language barrier[1]。如今处在全球化的时代,这句话完全可以扩展到商业以外的各个领域。但值得庆幸的是,计算机技术的迅猛发展,使借助计算机进行自动语言识别的研究一直未离开研究者们的视线[2]。
自动语言识别是许多应用程序中关键的一步,但对每个应用程序建立一个定制的解决方案,是非常昂贵的,特别是针对应用领域,人类注释标记语料库从而获得培训语料。因此,我们需要的是这样的一种通用的、可用的、现成的语言识别技术的工具。在本文中,我们提出了使用langid模型。langid是一个现有的语言识别工具,被视为有监督的机器学习任务,并极大地受到文本分类研究的影响[3]。同时,langid.py是一个全监督的、基于多项式的朴素贝叶斯分类器。它用共包括97种语言的多场景(domain)的语料对模型进行了训练,场景包括五类:政府文件、软件文档、新闻电讯、在线百科和网络爬虫[4]。
但针对本文的多语言微博进行识别分离研究,现有识别工具langid模型并不能直接使用。首先,现有识别工具langid模型语料库大多是针对比较正式的、长文本数据,并不直接适用于本文的多语言短文本微博数据。为了解决以上问题,本文需要构建适合本文研究的语料库,并通过反复实验,训练出适合本文多语言短文本微博数据识别分离的模型。
1 多语言识别微博语料库的构建
将微博爬虫与模拟登录、网络爬虫和Web内容解析相结合,爬取微博信息。根据微博的特点,新浪需要分析微博登录协议,通过模拟程序登录到微博浏览器获取用户登录信息,获取种子集,根据采集的URL使用URL调度器进行排序,并按照一定的策略对网页收集器分配URL。网页收集器使用GET方法通过HTTP协议收集数据[5]。最后,通过页面分析提取所获取的数据。详细流程图如图1所示。
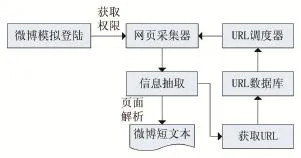
图1 基于微博爬虫的信息采集流程图
本文是手动筛选出多语言微博,并将其作为种子词,采用自编爬虫程序爬取更多的微博数据,爬取的微博数据包含:微博正文、点赞数、转发数、评论数、时间、来源和地点,如下表1所示:
爬取博文步骤具体如下:

表1 保存样例
(1)模拟登录,首先获取客户端的 cookie,利用cookie进行模拟登录,用于用户验证。
(2)页面抓取,利用Python中requests库的get函数,把相应用户ID的网页下载到本地。
(3)页面解析,利用Python中的Beautiful库提供的函数,对下载到本地的网页进行网页元素处理,主要是利用find_all()方法。
(4)在步骤(3)的结果上,利用 Beautiful的find_all('span',class_='ctt')方法,把含有标题的文本取出来。
(5)利用正则表达式和find_all('a',href=re.compile('^http://*'))过滤含有超链接的标签,把点赞数、转发数,评论数取出来。
(6)同理,利用Beautiful的find_all('span',class_='ct')把发表微博的日期和消息来源取出来。
(7)爬取内容的保存,把爬取到的标题、点赞数、转发数、评论数、日期和消息来源作为一条完整的数据,写入到txt文本中保存下来。
(8)接下来,依次爬取该用户的所有微博页面的数据,并把这些数据写入到txt文本中。
(9)依次对所有的用户ID进行爬取(即对每个用户ID执行步骤(2)-步骤(8)的操作),并把取得的数据保存到txt文本中。

图2 爬取微博步骤
2 基于langid的短文本多语言识别研究
许多应用程序都能够从自动语言识别任务上受益。如果人类自动标注语种语料库来建立一个自动语言识别处理程序从而应用到这些应用领域,那么代价是非常昂贵的。因此,我们急需一个没有人类标注参与,低配置的这样一个现成的、可用的语言识别工具。研究表明,在微博方面,现有的语言识别系统中在性能方面表现相当不错,但针对微博的具体语言识别系统langid似乎做得更好[6]。
2.1 laannggiidd语言识别模型结构
langid.py是基于朴素贝叶斯分类器模型,是一个有监督分类器。langid模型主要包括7个模块index.py、tokenize.py、DFfeatureselect.py、IGweight.py、LDfea⁃tureselect.py、scanner.py、NBtrain.py,工具包使用情况如下所示:
(1)准备语料库,把相应的语料以及与其对应的语言把到规定的文件下,其中每个文本是一个单独的文件,每个文件放到两层深的目下,./corpus/domain1/en/File1.txt,通过命令python index.py./corpus来建立相应训练语料及其语言对。
(2)分别对每种语言的每个文件进行分词处理,使用的分词模型是N-Gram,这里的N分别取值是1、2、3、4,经过分词后形成词的集合,使用的命令为python tokenize.py corpus.model。
(3)通过采用文档频率DF,来选择特征值,把一些信息贡献少的词过滤掉,主要是进行特征值的降维,使用的命令为python DFfeatureselect.py corpus.model。
(4)对选择的特征值进行权重的赋值,这里使用信息增益来给每个特征值进行赋值,使用命令为python IGweight.py-d corpus.model。
(5)在特征值的权重基础上,求出每个特征值的LD分数,然后根据LD分数,选择最终的特征值出来进行训练朴素贝叶斯分类器,使用的命令为python LD⁃featureselect.py corpus.model。
(6)通过建立一个扫描器,用来求出每个特征值的词频以及贝叶斯分类器的相关参数,使用的命令为py⁃thon scanner.py corpus.model。
(7)用这些选择出来的特征值进行贝叶斯分类器的训练,使用的命令为python NBtrain.py corpus.model。
(8)利用训练好的贝叶斯分类器进行分类,先导入langid模块,使用langid.classify方法把帖子中的维吾尔语、音译维吾尔语、英语以及汉语识别并分离出来。
2.2 laannggiidd模型训练
基于朴素贝叶斯的langid模型分类器,其工作原理如下:
确定目标函数。使用langid进行语种分类,目的是对于一篇包含n个特征的x1,x2,...xn的文档D,计算出属于闭集C中某一分类Ci的概率,并将其分配给最可能的分类[7]。

根据贝叶斯定理:
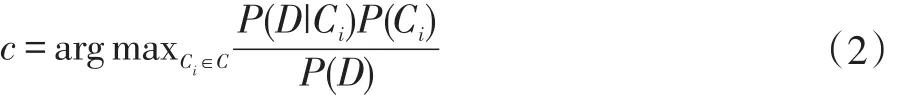
其中P(D)是常数,P(Ci)根据最大似然法得到。为了得到P(D|Ci),假设每一项是条件独立,即:

ND,ti是ti项在D中出现的频率。
使用多项式贝叶斯分类模型,将上述问题放在贝叶斯学习框架中建立一个参数模型,使用训练数据估计出贝叶斯最优的参数模型[8]。设参数为θ,由上式可以得到:

根据训练数据我们最终可以得到θND,ti|cj的0≤θND,ti|cj≤1最大似然估计值θ∧。
确定目标文档的分类。根据给定的参数值,我们可以通过计算目标文档对每个分类后的检验概率,并选择最大概率值作为目标文档的分类,即:
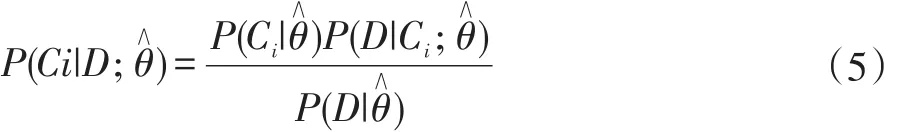
3 实验结果及分析
由于微博的短而杂乱以及微博中常含有结构比较相似的音译维吾尔语和英语,因此本节主要目的是通过langid模型识别汉语、维吾尔语、英语、音译维吾尔语。本文通过反复实验发现langid模型语言识别效果主要与以下几种情况有关:
①训练语料大小会影响语言的识别效果,语料规模大,会相应的提高语言的识别率;
②当音译维语和英语比例会影响语言的识别效果;
③训练文本都是长文本时,对短文本的识别效果不佳;
④增加分组会提高语言的识别效果;
⑤增加域会影响语言的识别效果;
⑥特征的选择会影响语言的识别效果。
实验结果表明,因实验数据全部来源于新浪微博,因而域增加,相应的训练语料增加,使langid模型提取的特征更能够较全面地反映出语言的特性,从而直接影响语言的识别效果,如表2所示。

表2 实验结果与域数
实验结果表明,英语和音译维吾尔语训练语料比例会影响对英语和音译维吾尔语的识别效果。英语和音译维吾尔语都是以拉丁字母书写的一种语言,因结构相似、书写相似,则langid模型对这两种语言提取的特征也比较相似,故英语和音译维吾尔语语料比例会直接影响识别效果。
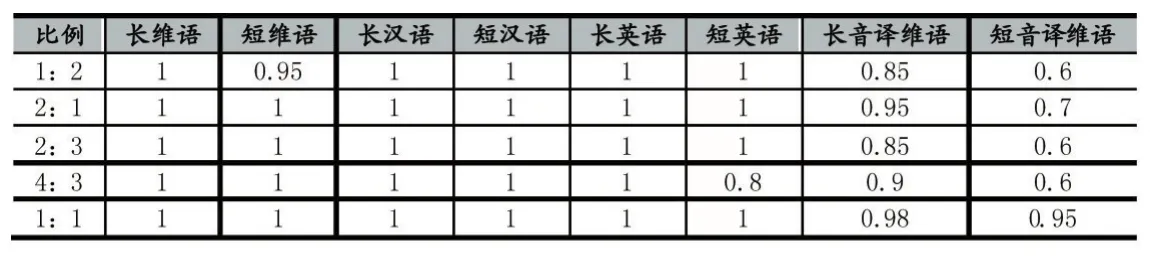
表3 英语和音译维吾尔语的比例
实验结果表明,langid模型中训练语料的长短对长文本、短文本的识别效果有直接影响,如表4所示。相对长文本而言,短文本数据稀疏且杂而乱,直接把比较规范的长文本特征应用到短文本识别方面,不能够较全面地反映出短文本特性。

表4 实验结果与训练文本的长短

表5 实验结果与分组数
实验结果表明,预训练的langid模型在实验过程中,分组数会影响实验结果,分组数增加会相应的提高对语言的识别效果,特别是对短文本的识别效果影响较大。因为本模型在每个分组内提取等量的特征,分组越多,每种语言提取的特征数越多,语言的识别率也相应的提高。

表6 实验结果与特征提取的数量
实验结果表明,因langid模型对语言的识别依赖于所提取的特征,特征数越多越能够较全面的反映出特定语言的特性,特征数相对来说对语言的识别效果有直接影响。
结合实验 1、2、3、4、5,本实验采用的语料库是采用自编爬虫程序爬取来自多语言微博用户的微博数据,该数据集包含4w条微博样本(音译维吾尔语1w,英语1w,汉语1w条,维语1w条)。本文的实验数据全部来源于多语言用户发布的新浪微博,以下的domain中数据全部来源于基于多语言用户发布的新浪微博,本文通过4w条微博样本进行反复实验,将实验结构设计如下效果最好:
domain1(en,yug,zh,ug):每种语言各 2000 条,共8000条
domain2(en,yug,zh,ug):每种语言各 2000 条,共8000条
domain3(en,yug,zh,ug):每种语言各 2000 条,共8000条
domain4(en,yug,zh,ug):每种语言各 2000 条,共8000条
domain5(en,yug,zh,ug):每种语言各 2000 条,共8000条

表7 实验结果

表8 语言识别模型准确率对比

表9 传统语言识别工具
传统的机器学习模型中,相比TextCat模型[9]、CLD模型[10]、LangDetect模型[11],langid 获得了最优的性能,准确率最低达到了95%。这与基于多项式的朴素贝叶斯分类器模型的训练目标有关,它追求结构风险最小化。该方法降低了数据规模和数据分布的要求,在小样本条件下获得了较好的性能。同时发现对短文本微博维吾尔语和音译维吾尔语识别率可达100%,对结构比较相似的短文本英语和音译维吾尔语而言,在识别过程中会相互影响。一方面,音译维吾尔语和英语都是以拉丁字母书写的一种语言,结构比较相似,书写比较相似。另外,音译维吾尔语和英语在书写方面,某些单词通用,例如“man”等,导致提取的特征比较相似,为后期模型训练埋下了隐患;另一方面,langid模型提取的特征难以反映词与词之间的语义关系,使提取的特征无法满足这种结构相似的语言识别分类。
4 结语
本文根据微博的特点,综合考虑了影响langid模型识别效果的影响因子,通过反复实验验证了langid模型对微博数据的有效性和可行性,同时对结构比较相似、书写相似的英语和音译维吾尔语识别效果俱佳。
另外,虽然该方法在维吾尔语和汉语识别准确率为100%。但在英语和音译维吾尔语识别效果上相对来说较弱一些,未来的工作将考虑在英语和音译维吾尔语上做进一步的研究。
