基于GRU网络和矩阵分解的混合推荐算法
2018-10-18徐彬源高茂庭
徐彬源,高茂庭
(上海海事大学信息工程学院,上海 201306)
推荐算法;门控循环单元;数据降维;长期状态;短期状态
0 引言
随着互联网技术的快速发展以及智能移动终端产品的普及,人人皆是网民的时代即将来临,手机网民指数不断攀升,互联网中的数据爆发式增长,而信息处理能力远远跟不上信息增长的速度,导致出现了信息过载问题。为有效解决该问题,推荐系统[1]诞生了,而推荐系统中最关键的部分是推荐算法,推荐算法的好坏直接决定了推荐系统的优劣。目前主流的推荐算法[2]包括基于内容的推荐、基于协同过滤的推荐以及混合推荐。
其中,最成功的算法是协同过滤推荐算法[3],被广泛应用在各大推荐系统中。其基本原理非常简单,就是根据用户的行为历史数据分析用户对项目的兴趣偏好,发现用户或项目之间的相似度,然后基于这些相似度对用户进行推荐。协同过滤推荐又分为基于用户的推荐、基于项目的推荐以及基于模型的推荐[4]。但随着用户数和项目数的剧增,前两个算法的计算复杂度太大,并且受到数据稀疏性的影响较大。基于模型的推荐能有效缓解上述问题,并做出更好的推荐。因此,基于模型的推荐算法逐渐成为推荐领域中的研究热点。基于模型的推荐算法中最关键的一步就是用户模型的建立,因此很多流行的建模技术都可以应用在推荐算法上,如聚类[5]、分类、关联规则、矩阵分解[6]等。后续学者利用这些建模技术提出了很多基于模型的改进推荐算法。
文献[5]针对传统协同过滤中没有考虑用户偏好的问题,利用联合聚类技术结合用户属性相似性和用户评分相似性来分析用户偏好,采用了用户属性信息有效缓解了数据稀疏性,提高了评分预测准确度。文献[6]在基于矩阵分解的推荐算法中引入标签构建向量,作为对用户兴趣建模和项目特征表示的补充,提升了推荐精度。文献[7]在矩阵分解模型中引入用户属性构建用户属性特征向量,计算新用户与旧用户之间的相似度,以解决新用户冷启动问题。虽然上述算法在一定程度上提高了算法预测准确度,考虑了用户属性和标签等数据源,但是缺乏对用户和电影的长短期状态的考虑。
本文针对电影领域传统推荐算法中的上述问题,提出基于GRU网络和矩阵分解的混合推荐算法。首先,严格按照评分时间顺序划分数据集,得到用户序列和电影序列,针对序列中高维稀疏的向量,使用自编码器对其进行降维处理,然后使用两个GRU(Gated Re⁃current Unit)[8]网络处理时间序列数据以得到用户和电影短期内随时间变化的状态特征,使用矩阵分解算法捕获用户和电影长期内固定状态特征,最后用线性回归模型结合长期状态的内积和短期状态的内积的线性加权结果作为该混合算法的最终预测评分,并在多个公开数据集上通过与传统推荐算法的对比实验,验证本文提出的算法在预测评分的有效性和准确度。
1 GRU网络
选择GRU网络来处理时间序列数据,是因为GRU网络是一种改进的循环神经网络[9],并且解决了循环神经网络中的梯度消失问题,实现了更长距离的传播。因此,GRU网络能够从时间序列数据中记忆历史时刻的信息,并基于历史信息和当前时刻的输入来预测下一时刻即将发生的行为。
GRU控制信息流动原理是,利用门控机制控制当前输入、历史记忆等状态信息在当前时间步做出预测。图1给出了GRU模型的结构。从图中可以看出,GRU的结构比较见到那,只有两个门:重置门(reset gate)和更新门(update gate),即rt和zt。从信息流动的角度来说,重置门控制如何将新的输入信息与前一时刻的状态信息相结合;更新门控制前一时刻的状态信息保存到当前状态中的量。
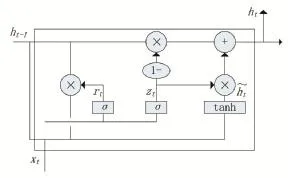
图1 GRU结构图
上图1中,xt表示时刻t处GRU单元的输入,ht表示t时刻的状态信息,表示当前记忆内容。
(1)更新门
在时间步长t处,更新门的计算公式如下所示,其中Wz表示更新门的权重:

对输入向量xt和前一时刻t-1隐藏状态ht-1分别做线性变换,通过Sigmoid激活函数将两部分的信息相加的结果压缩到0到1之间。更新门决定前一时刻的状态信息和当前时刻的状态信息继续传递到未来的量。
(2)重置门
在时间步长t处,重置门的计算公式如下所示,其中Wr表示重置门的权重:

与更新门类似,先对xt与ht-1分别做线性变换,然后通过Sigmoid激活函数输出0到1之间的激活值。重置门决定了前一时刻的状态信息要被遗忘的量。
(3)当前记忆内容
在当前记忆内容的计算中,将重置门直接应用于前一时刻的状态信息上,以存储前一时刻隐藏层的信息,计算公式如下,其中Wh˜表示当前时刻输入数据生成当前状态信息的权重:

将前一时刻的状态信息ht-1与重置门rt做对应元素的乘积,这一步骤确定了前一时刻所要保留的信息,然后对该乘积结果rt∗ht-1和当前时刻的输入xt做线性变换,通过tanh激活函数将两部分相加的结果映射到-1到1之间,以得到当前记忆内容h˜t。
(4)当前时间步的最终记忆
当前时间步的最终记忆ht将保留当前隐藏层的状态信息并继续传递到下一时刻。在这一步,使用更新门来决定当前记忆内容和前一时刻的状态信息ht-1要保留的量,计算公式如下所示:

(1-zt)∗ht-1表示前一时刻的信息保留到当前时刻最终记忆的量,zt∗表示当前记忆内容保留到当前时刻最终记忆的量,两个部分的相加结果作为GRU最终的输出内容。本文使用ht=GRU(ht-1,zt)来表示GRU的前向计算过程

GRU网络的参数更新方式采用BPTT算法[10]进行更新。
2 基于GRU网络和矩阵分解的推荐算法
2.1 基于GGRRUU网络的推荐算法
本文使用两个GRU网络模型分别解决用户和电影状态的时间演变,获取短期内用户和电影的时间状态,并将用户和电影时间状态的内积作为最终预测评分。其中用户的状态变化取决于用户先前对哪些电影进行评分,同样的,电影的状态变化依赖于前一段时间内对其进行评分的用户。
首先,将评分数据严格按照时间戳进行划分,以得到用户序列和电影序列。但序列中的向量都是高维稀疏的,不利于模型的训练。然后,利用自编码器的编码过程对数据进行降维,将降维后的低维稠密向量作为GRU网络的直接输入,并将预训练期间自编码器[11]隐藏层节点数和权重作为输入嵌入层(即Embedding层)的节点数和权重。最后,通过GRU网络能够记忆历史信息,并基于最新输入对下一步的评分行为做出预测。
图2给出了基于GRU网络的推荐模型完整结构。
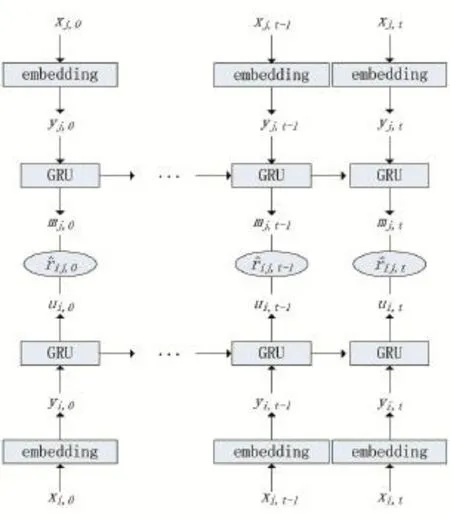
图2 基于GRU网络的推荐模型
其中,{xi,0,...,xi,t-1,xi,t}和{xj,0,...,xj,t-1,xj,t}分别表示原始用户序列和电影序列,包含了0到t时刻的原始用户i的向量和电影j的向量,Embedding层表示由自编码器预训练得到的模型的隐藏层,以实现数据降维,{yi,0,...,yi,t-1,yi,t}和{yj,0,...,yj,t-1,yj,t}分别表示由Embedding
层降维后直接用于GRU网络输入的用户序列和电影序列,{ui,0,...,ui,t-1,ui,t}和{uj,0,...,uj,t-1,uj,t}分别表示由GRU网络对输入序列的处理得到的用户和电影的时间状态,{ri,0,...,ri,t-1,ri,t}表示0到t时刻对下一时刻用户i对电影j的评分。
给定M个电影,N个用户的数据集,则xi,t∈RM(xj,t∈RN)表示给定用户i(或电影j)在时间t的评分向量,=k表示给定用户i在时间步长t对电影j的评分为k,=k表示给定电影j在时间步长t处被用户i的评分为k,否则对应元素值为0。由上述内容可知,用户和电影时间状态的计算公式如下所示:
将三种单矿物用玛瑙研钵研至-5 μm,采用D8Advance/Bruker型X射线衍射仪进行定量分析,分析结果及XRD衍射图分别见表1和图1。

将用户状态和电影状态的内积作为评分的估计值,计算公式如下:

<·>表示两个向量之间的内积。对GRU网络的输出层做了适当改进,我们不使用激活函数[12],只做简单的线性加权,其中,和分别是ui,t和mj,t的线性函数。即有:

其中,Wuser、Wmovie和buser、bmovie分别表示 GRU 的输出到输出层用户和电影的权重和偏置。用θ表示模型中所有需要学习的参数,即Wrx、Wrh、Wzx、Wzh、Wh˜x、Wh˜h、Wuser、buser、Wmovie、bmovie。因此,基于 GRU 网络的推荐模型的目标函数如下所示:
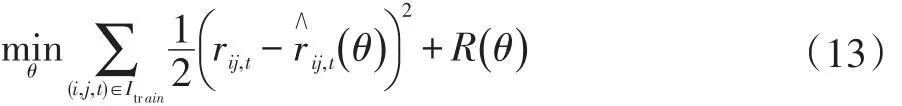
其中,Itrain表示训练集中观察到的(用户、电影、时间戳)的元组的集合,R是关于参数的L2正则化项。训练过程中,使用Adam优化器来优化训练模型,以便模型的目标函数以最快速度达到最小,得到最优参数。
2.2 矩阵分解算法
使用矩阵分解算法对用户和电影的长期状态进行建模。基于矩阵分解的推荐算法的原理很简单,就是将用户-项目评分矩阵分解为用户因子矩阵和项目因子矩阵,通过两个矩阵相乘,得到原始评分矩阵中的缺失值,进而对用户进行推荐。对于给定M个电影,N个用户的评分矩阵RN×M,对R做矩阵分解的结果如下所示:

其中,K表示潜在因子的个数,P和Q分别表示用户和电影与潜在因子之间的关系,RˆN×M表示由两个矩阵P和Q生成的预测评分矩阵。矩阵分解的目标是使预测评分矩阵和原始评分矩阵中的观察值之间的误差最小,即如下公式:

使用梯度下降法求得上述损失函数的参数变量的最优值。
2.3 基于GGRRUU网络和矩阵分解的混合推荐算法
综合前两节的内容,综合考虑长期和短期状态对评分行为的影响,并针对数据维度高的问题,提出一种基于GRU网络和矩阵分解的混合推荐算法。图3给出了混合模型的结构。
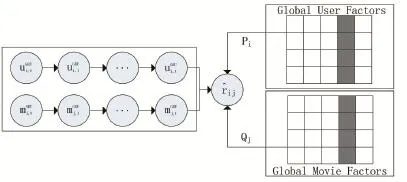
图3 GRU网络和矩阵分解的混合推荐模型
由上述内容,使用混合加权的方式将两个训练好的模型的预测评分结合起来以作为混合模型的预测评分,两个基础预测评分的权重通过线性回归模型求解得出。最终预测评分的计算公式如式(17),其中表示基于矩阵分解的预测评分,表示基于GRU的预测评分,WMF和WGRU分别表示和在最终预测评分中所占的权重。

用L上述线性回归模型的损失函数,则L的计算公式如下所示:

使用梯度下降法[13]确定式(17)中的权重WMF和WGRU,进而生成最终的预测评分。混合加权推荐算法综合循环神经网络和矩阵分解各自的优势,综合考虑长期和短期状态,提高评分预测准确度。
3 实验结果与分析
3.1 实验数据集
为了研究时间动态的有效性建模,在Netflix比赛和IMDB数据集上评估本文模型。IMDB数据集包含1998年7月至2013年9月期间收集的1429600个评分,完整Netflix数据集包含1988年11月至2005年12月期间收集的100400000个评分,其中6个月Netf⁃lix数据包含2005年6月至2005年12月期间收集的15800000个评分。每个数据点是一个时间戳粒度为1天的(用户id,项目id,时间戳,评分)元组。根据时间分割数据以模拟需要预测未来评分的实际情况。整个数据集都被分割成训练集和测试集。详细数据如表1所示。
3.2 实验设置

表1 实验数据集的详细数据
实验中使用具有20个隐藏神经元,40维输入嵌入和20维动态状态的单层GRU。本文模型在Tensor⁃Flow[14]上实现,这是一个开源的深度学习框架。
均方根误差(RMSE)和平均绝对误差(MAE)均是度量预测误差的指标,其中,RMSE对大误差比较敏感,MAE对小误差的积累比较敏感。由于RMSE加大了对预测不准的用户物品评分的惩罚,对系统的测评更加苛刻,实验中选择RMSE评估算法精度。对于完整的Netflix和IMDB数据集,采用2个月的时间步长粒度,对于六个月的Netflix数据集,采用7天的时间步长粒度。每个时期之后,计算RMSE。在验证集上给出最佳结果的模型上,计算在测试集上的RMSE。
3.3 实验结果及分析
为了评估本文提出模型(R-GRUMF)的性能,将其与PMF、TimeSVD、AutoRec进行对比实验。实验结果如表2所示。

表2 各模型在数据集上的RMSE
从表2可以看出,R-GRUMF模型的RMSE比所有对比模型的RMSE都要低,表示该模型能有效降低预测误差,并且在越稀疏的数据集上,其RMSE的差距越大,说明该模型可以在一定程度上缓解数据稀疏性对模型预测评分的影响。虽然对比方法在不同数据集之间排名忽前忽后,但是本文提出的模型在所有数据集中的预测误差都是最低的,说明该模型有很好的健壮性,适应不同的数据集。
4 结语
本文针对电影领域中传统推荐算法中数据维度高,缺乏考虑用户和电影长短期状态的问题,利用GRU网络在处理时间序列数据上的优势,捕获短期状态,利用矩阵分解对长期用户和电影之间的交互评分行为的建模分析,得到长期状态,综合考虑两种状态对预测评分的影响,提出一种基于GRU网络和矩阵分解的混合推荐算法,缓解了数据稀疏性问题,提高了评分预测准确度。
本文尝试将GRU网络用于推荐,并取得不错的效果。但是整个推荐过程中,也仅仅使用了评分及时间戳信息,目前推荐系统中还有很多更加复杂的数据源可供研究,如用户评论、电影的音频及图像等信息都可以被深度学习等技术利用起来,以建立更完善的用户个人画像,提高推荐精度。
