基于卷积神经网络的拒绝服务攻击数据流检测
2018-10-18谢洁韩德志
谢洁,韩德志
(上海海事大学信息工程学院,上海201306)
云环境;拒绝服务攻击;卷积神经网络
0 引言
现今云计算的兴起,云平台给用户提供了各种便利的互联网应用服务,随之产生的针对云环境的各种攻击事件不断发生,威胁着云网络的安全。在针对云环境的攻击中拒绝服务攻击是主要的攻击方式,攻击强度高,损害大,并且呈现增长态势,云安全问题形势严峻。目前针对拒绝服务攻击的检测方法主要有,针对TCP拥塞控制机制的Shrew攻击、随机化端系统的最小超时等待时间、控制路由器队列缓冲区、算法匹配、数学工具如小波特征。卷积神经网络是模式分类领域的研究热点,在图像识别上避免了对图像的前期处理过程,精简了识别程序,结构简单,且提高了识别效果,因而已成功应用于手写字符识别、人脸识别、医疗诊断等领域中。
1 卷积神经网络
卷积神经网络模型是一个多层的神经网络,每层由多个二维平面组成,每个平面由多个独立神经元组成。网络包含输入层、卷积层、池化层和输出层。输入层只有一层,卷积层和池化层一般设置多层,输出层一般为一维线阵,用于分类。下图1是卷积神经网络的示范:输入图像通过和三个可训练的过滤器和可加偏置进行卷积,卷积后在C1层产生三个特征映射图,特征映射图中的像素再进行求和、加权值和加偏置,通过一个sigmoid函数得到三个S2层的特征映射图。映射图经过过滤器得到S3层。这个层级结构再和S2一样产生S4。最后像素值被处理规则化,并连接成一个向量输入到传统的神经网络得到输出。简单来说,就是提取出了特征数据,每个层有多个特征图,每个特征图通过一种卷积核提取输入的一种特征,每个特征图有多个神经元。根据卷积核学习的特征产生特征映射,特征映射如图2所示,找到第一次特征后,将第一层发现的特征作为第二层的输入,做第二次的特征查找,把特征更抽象化。
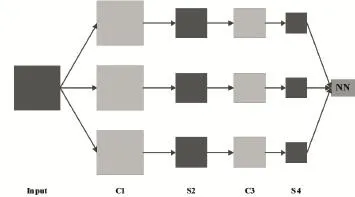
图1 卷积网络基本构型
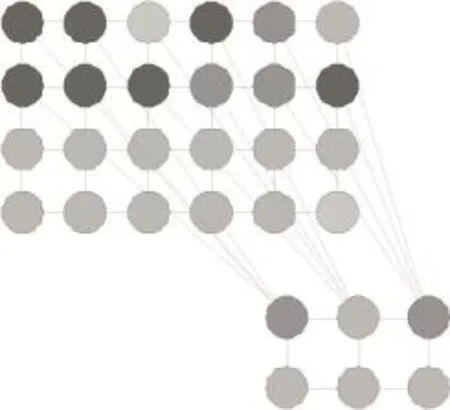
图2 特征映射
卷积层的输入为前一层的局部区域,对输入数据应用若干卷积核加入偏差项进行卷积操作,提取多种特征。每做一次卷积得到一个此层的特征图(Feature Map),每个卷积核可提取一种特征,每个特征图可能是与上层几个特征图连接形成的映射平面。卷积层计算公式可以表示为:

第l层的第j个映射平面表示为,Mj为感受区域即输入的特征图集合,卷积核的权值和偏置分别为w和b,激活函数为f。
池化层对输入进行抽样,缩减输入数据的规模,特征图经过池化后大小变化,特征图个数不变,特征维数降低,计算量减少。确定池化区域的大小a×b,用区域内的平均特征作为卷积特征,常见的方法是最大值合并、平均值合并和随机合并。最后一个池化层通常连接到一个或多个全连接层,全连接层的输出就是最终的输出。池化层的计算公式可以表示为:

其中,down()为池化函数,每个输出特征图都有自己的系数a和b。
2 基于粒子群算法的卷积神经网络模型
学习算法对于卷积神经网络的学习至关重要,卷积神经网络的学习是指通过已有的数据训练出输出层产生的超平面,完成分类任务,将数据分成两类。在学习的过程中,每一组不同的卷积核都对应一个目标模型,根据已有数据的输入结果是否符合预期来判断卷积核的准确度,通过不断的更新卷积核最终确定一组最优的卷积核。
2.1 误差反传算法
传统的卷积神经网络学习采用误差反传算法,分为两个阶段进行,一个阶段是向前传播计算出网络的输出,从样本集中取一个样本输入网络,进行卷积计算和池化计算,计算相应的实际输出。另一个阶段是反向传播,逐层递推至各层计算权值误差梯度,按极小化误差的方法反向传播调整权矩阵。理想输出是指神经网络的输出和训练样本的标准值一样,实际上不可能达到这么精确,只能希望实际输出尽可能地接近理想输出。计算实际输出与相应的理想输出的差值用E(W)表示表示训练样本为s的情况下第i个输出单元的输出结果。

梯度的方向就是对函数求偏导∇E(W)。假设第k次更新后权重为,如果 ∇E(W)≠0,则第k+1次更新权重如下:

式中η为卷积神经网络的学习率。当∇E(W)=0或者∇E(W)<ϵ时停止更新,ϵ为允许的差值,将此时作为最终的卷积神经网络卷积核的权重。
2.2 粒子群优化算法
粒子群优化算法中,粒子群由m个粒子组成,在n维空间搜索,每个粒子的位置体表优化问题中的潜在解,粒子群优化算法的数学描述为:在一个n维搜索空间中,包含m个微粒,种群x=(x1,x2,…,xm)T,第i个微粒在的n维搜索空间中的位置xi=(xi,1,xi,2,…,xi,n)T,第i个微粒当前速度为vi=(vi,1,vi,2,…,vi,n)T。第i个微粒的个体极值即自身最优历史位置为pi=(pi,1,pi,2,…,pi,n)T,整个微粒群的全局极值即区域内所有粒子最优位置为pg=(pg,1,pg,2,…,pg,n)T,对于第k次迭代的第i个微粒其第d维更新自己的速度与位置如下式所示:
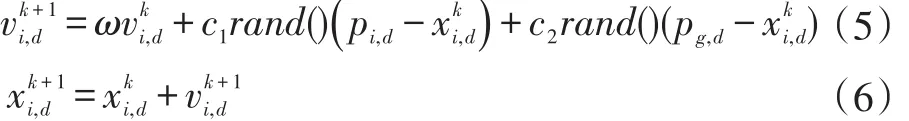
其中,ω为权重因子,使粒子有运动惯性,c1和c2为学习因子,c1调节粒子飞向自身的最好位置,c2调节粒子飞向全局最好位置,rand()为介于(0,1)的随机数,和分别为粒子i在第k次迭代中d维的速度和位置,为粒子i在d维的个别极值,为群体在d维的全局极值,为了将粒子的活动范围限定在搜索区域内,如果搜索空间限定在[-xmax,xmax],可设定vmax=kxmax,0≤k≤1。算法的流程图如图3所示。
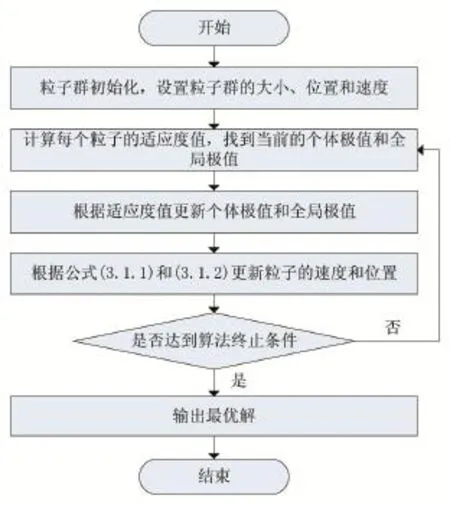
图3 粒子群算法流程图
2.3 卷积神经网络模型的参数粒子化
卷积神经网络模型的参数粒子化是指将卷积神经网络的卷积核的权值和阈值等参数进行编码,映射成为粒子群优化算法中的粒子,可以将网络的权值和阈值等参数看做是粒子的位置分量。设卷积神经网络的卷积核的个数为ni,全连接层的结点数为nj,则第i个粒子的位置所表示的网络为:
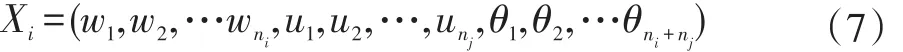
其中,其中wni表示卷积层与池化层之间的卷积核的权值,unj
表示全连接与输出层之间的连接权值,θni+nj表示阈值参数。每个粒子的位置唯一确定一个卷积神经网络,粒子的进化更新也应是卷积神经网络的卷积核的学习。
2.4 基于粒子群算法和误差反传算法的学习算法
传统的卷积神经网络的训练算法需要训练的参数数目多,不易学习到最优值,还会出现参数弥散的问题。粒子群优化算法是一种全局优化的算法,有收敛速度快,易于实现等优点,本文将粒子群算法应用到神经网络的训练中,结合传统的误差反传算法快速的局部搜索能力,发挥两种算法的优势,该算法的具体实验步骤如下:
(1)粒子群初始化,包括各个参数:粒子群的规模N、粒子维数D、惯性权重ω、加速常数c1和c2、位置空间的最大值和最小值xmax和xmin等。设置粒子群优化算法的最大迭代次数Tmax-pso,BP算法的最大迭代次数Tmax-bp,粒子群优化算法的能量函数变化次数阈值Tpso,当前进化代数iter=1,能量函数变化次数flag=0。
(2)初始化卷积神经网络结构、设置传递函数、学习率、权值、阈值等参数并确定目标函数。
(3)初始化各粒子位置,将卷积神经网络的卷积核的权值和阈值等进行编码作为粒子的位置。
(4)将样本数据输入神经网络,通过计算至输出层,计算粒子当前的适应度函数的偏差值。
(5)每个粒子将当前的适应值与其个体历史最好适应值比较,若当前适应值更优,则令当前粒子的适应值为个体历史最好适应值,选择当前粒子的位置作为个体最好位置。
(6)比较群体所有粒子的当前适应值与全局的最好位置的适应值比较,若当前适应值更优,则令当前粒子的适应值为全局历史最好适应值,选择当前粒子的位置作为全局最好位置,flag=0,否则flag=flag+1。
(7)如果flag>Tpso,则使用BP算法在全局最好位置附近进行局部细致搜索。如果搜索结果优于全局最优位置,则用此搜索结果代替全局最好位置,否则,用搜索结果代替性能最差的个体,flag=0,iter=iter+1。如果flag<Tpso,iter=iter+1。
(8)根据粒子群优化算法,更新粒子的速度、位置。
(9)判断是否满足终止条件,达到适应度值要求或者是最大迭代次数,iter>Tmax-pso,满足终止条件则输出优化问题的最优解,否则到步骤(5)。
(10)整个算法结束,输出全局最好位置为所求神经网络的卷积核等参数。
3 仿真实验
实验采用的数据集是网络入侵检测的常用数据集KDD CUP99,该数据集中总共包含大约500万条网络连接记录,本次模拟实验抽取10%的数据进行实验,从训练数据集中随机抽取5组不同样本数量的数据作为训练集,按照同样的比例抽取5组数据作为本实验的测试集。数据集中异常数据类型为:拒绝服务攻击(DDoS)、来自远程主机的未授权访问(R2L)、为授权的本地超级用户特权访问(U2R)、端口监视或扫描(Probing)。
为了评估模型的准确度,实验使用混淆矩阵、漏报率、平均漏报率和平均代价来进行评估最终的检测效果。不同的误分类会有不同的后果,这里使用KDD CUP99公布的代价矩阵对误分类进行衡量。
(1)准确率=预测值类型与实际类型相同的数量/预测为该类型的数量
(2)平均代价=种类被误分的数量×误分对应的代价/测试样本总数量
3.1 实验数据预处理
KDD CUP99数据集中,每条数据记录除去最后一个标签外,都包含41个特征,其中38个是数值型特征另外3个是字符型特征。对数据集进行预处理要将字符型的特征映射为数值型的特征,并且将数值型特征进一步处理,进行数值规范化。对数据进行预处理常常采用归一化的方式,将数据集中所有的数据转换成[0,1]之间的数,取消各维度间数量级之间的差别,减少网络预测产生的误差。数据归一化常用方法有两种,一种是最大最小法,函数形式为:
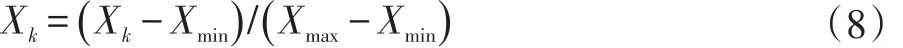
其中,Xmin表示数据序列中的最小数,Xmin表示数据序列中最大数。另一种是平均数方差法,函数形式为:

其中,Xmean表示数据序列中的均值,Xvar表示数据的方法。前41项数据特征可以被分为4大类:TCP连接基本特征、TCP连接的内容特征、基于时间的网络流量统计特征和基于主机的网络流量统计特征。表1为各层参数的一个示范,在4大类数据类型中,每类型取出9个数据,之后将这些数据矩阵化表示。
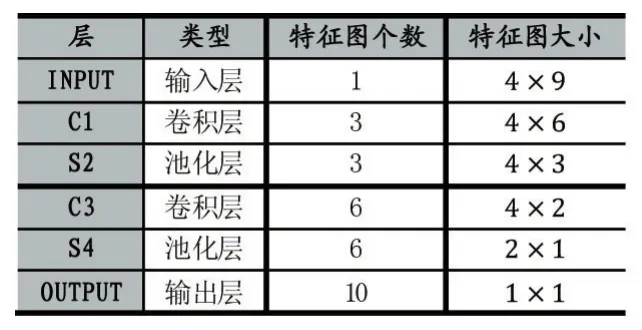
表1 实验各层参数示范
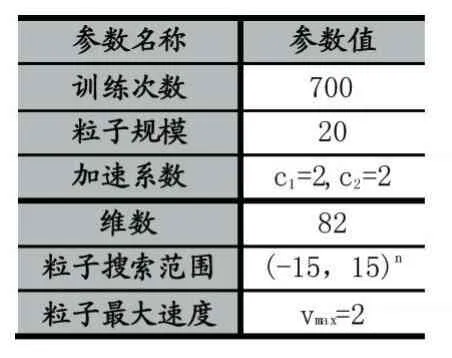
表2 仿真条件
3.2 实验结果分析
将训练集中的数据输入模型进行多次训练并调整和优化参数,选取训练和测试中实验结果最好的参数及模型。表3显示了训练次数与测试准确率之间的关系,在一定的范围内训练次数增加,样本测试的准确率随之提高,但经过500次以上的训练后,平均准确率没有提升,出现了过拟合问题,不能简单通过增加训练次数来提高准确率。
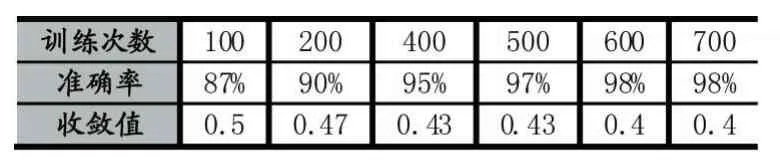
表3 训练次数与准确率的关系
为了测试模型的性能,将此模型决策树模型、支持向量机模型、卷积神经网络模型进行以比较实验,数据处理等步骤均同等操作,粒子群算法的仿真条件都保持一致,比较其对拒绝服务攻击的识别率,实验结果比较如下表表4所示,从中可以看到,结合粒子群算法的卷积神经网络模型在KDD CUP99数据集上有较好的正确率,且算法在实验中有较快的训练和运行速度。

表4 算法性能比较
综合以上实验分析,结合粒子群算法和误差反传算法的神经网络模型对云环境中攻击数据流的检测具有可行性,对数据有良好的适应性,对攻击数据流有较好的识别效果。
4 结语
为了适应对云环境中拒绝服务攻击数据流的检测,提高卷积神经网络的训练速度,本文提出了结合粒子群算法的卷积神经网络模型,该模型通过学习正常云环境中的数据流来训练模型,再用于拒绝服务攻击数据流的检测。实验结果表明,结合粒子群算法的卷积神经网络模型用于对拒绝服务攻击数据流的检测具有一定的可行性,并且识别准确率和识别速度都优于其他检测方式。在未来进一步的工作中,还需要对粒子群算法做出更多优化,使之更加适用于云端的大数据流环境,卷积神经网络模型也可以进行更多结构的实验设计找出最佳模型,并且对云环境中的大规模数据进行实时测试。
