基于卷积神经网络和XGBoost的文本分类*
2018-10-15龚维印
龚维印,王 力,2
(1.贵州大学 大数据与信息工程学院,贵州 贵阳 550025;2.贵州工程应用技术学院 信息工程学院,贵州 毕节 551700)
0 引 言
随着信息技术的发展,互联网上的文本数据呈现爆炸式增长。面对海量的文本数据,准确高效地从中挑选出有价值的信息,使文本分类处理技术变得至关重要。文本分类主要包括文本预处理、文本表示、特征提取和构造分类器等过程。文本预处理是文本分类的关键步骤,需要对数据进行清洗,去除非中文字符,提取数据预特征,降低数据维数,这对最终分类结果具有决定性作用。目前,常用的文本内容表示方法是基于词袋(Bag-of-Word,BOW)法[1],即将文本中的词看作一个集合,词与词之间相互独立,忽略其语序、语法和语义信息。特征提取方法一方面能够更好地数字化表达原始数据,另一方面也起到了降维作用。特征提取主要包括词频(Term Frequency,TF)、文档频率(Doucment Frequency,DF)和信息增益(Information Gain,IG)等方法[2]。最终,将提取的数据特征与常用的分类器进行组合,对文本进行分类处理。常用的分类器有支持向量机(SVM)、最近邻分类(KNN)、贝叶斯分类(NB)、决策树、RBF神经网络和随机森林等[3-5],但是基于词袋法的文本分类存在一定的问题:向量维数太高,训练集和测试集必须保证词数一致,否则无法完成特征匹配;基于词袋法的文本表示矩阵较为稀疏,特征词利用率较低,不利于自然语言处理任务;由于词袋法考虑词与词之间相互独立,忽视词与词之间的语法、语序和语义关系。
近年来,随着深度学习的研究与应用,词的向量表示方法得到了进一步发展。Mikolov等人提出了用于词向量计算的word2vec模型[6-7];Kim[8]将词向量运用于简单的CNN结构,充分证实了词向量的优越性;Mandelbaum等[9]人基于TensorFlow实现Kim模型并进一步改进,提高了该模型的分类精度,弥补了词袋法文本表示的不足。
本文主要工作如下:通过多尺寸卷积核提取不同的数据特征进行特征融合;将卷积神经网络与XGBoost组合进行文本分类。
1 相关工作
本节主要介绍文本分类预处理工作,主要包括数据预处理和文本表示。数据预处理的结果会影响后期特征提取和分类精度,是文本分类必不可少的步骤。
1.1 数据预处理
中文文本处理复杂,词与词之间缺少明显的空格分隔符。预处理包括编码转换、文本去噪、中文分词和去除停用词等。文本预处理需要对文本数据进行清洗,使用正则表达式去除文本中的数字、标点、地址等非中文符号,将其转化为纯文本数据。纯文本数据中还含有大量对理解上下文含义无实际意义的词,通过对纯文本数据进行分词处理,引入停用词去除无实际意义的词,降低数据的维数,提高文本分类的精确度。
1.2 文本表示
计算机只能识别机械语言。为了使计算机能够识别文本语言,需要将文本中的词转化为数字表示,即将词生成词向量,表示成数据矩阵。最初,在自然语言中将词表示成向量常用的方法是One-hot,即将词表示成字典大小的向量,向量的分量只有一个1,其余全为0。1的位置表示对应该词在词典中的位置[10]。这种方法虽然简单,但是容易造成维数灾难、数据稀疏以及无法表述语义信息等问题。为了弥补One-hot表示方法存在的不足,Hinton提出了分布式表示,即将词映射到低维向量空间,使得意思相近的词在空间中的距离变近[11]。
Mikolov等人通过借鉴Bengio提出的神经网络 语 言 模 型(Neural Network Language Model,NNLM)以及Hinton[12-13]提出的Log_Linear模型,提出了快速词向量训练模型word2vec,并受到了自然语言研究者的广泛关注。word2vec词向量训练模型主要包括连续词袋模型(Continuous Bagof-Words Mode,CBOW)和Skip-Gram模型,其中CBOW模型通过当前词上下的词预测当前词,而Skip-Gram模型(如图1所示)可以通过当前预测词预测当前词周围的词。本文使用Skip-Gram模型将数据预处理后的文本数据进行词向量表示,生成形如w=(d1,d2,…,dn)的词向量。其中,w表示特征词,di(0<i≤n)表示特征词w的第i个维度。本文训练的词向量维度为128维,即i=128。若存在一组词汇w1,w2,…,wn,则Skip-Gram模型的目标是将J最大化:
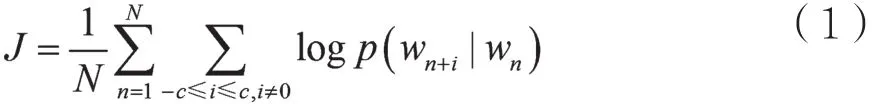
其中n是词汇中的词数,i是上下文窗口的大小,wn是当前词。
2 CNNs-XGB模型
本文提出的CNNs-XGB文本分类模型主要包括卷积层、池化层和构造分类器等。若一个句子的长度为n,通过预先训练的k维词向量进行词嵌入,将每个词表示为k维的向量,即可将该句子转化为n×k维的数据矩阵作为输入。卷积层通过使用3×k、4×k、5×k尺寸的卷积核进行特征提取,对提取后的特征再进行池化处理,然后将不同尺寸卷积核提取的特征进行全连接,最后通过XGBoost分类器完成文本多分类处理。如图2所示,假设一个句子由6个词组成,每个词为4维词向量,则该句子可以表示为6×4的数据矩阵作为卷积层的输入,通过3×4、4×4、5×4的卷积核进行特征提取,得到4×1、3×1、2×1的特征图,然后经过最大池化处理得到3维的特征图,最终通过XGBoost分类器进行分类处理。

图1 Skip-Gram词向量训练模型
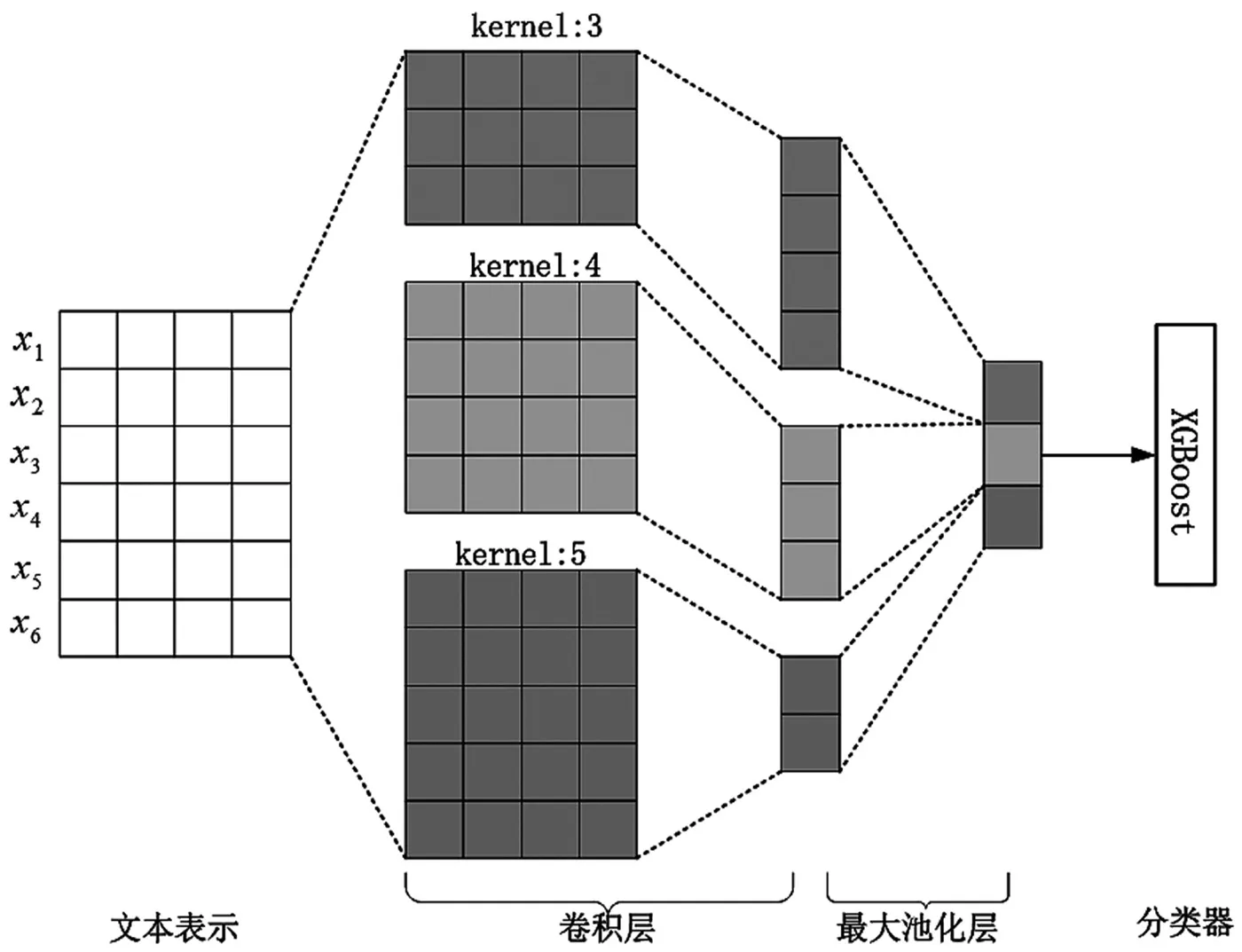
图2 CNNs-XGB文本分类模型
2.1 词向量
经过word2vec词向量训练得到每个词的词向量表示,无法获取文档的完整信息。假设一篇文档可由多个句子组成,则可以表示为d={s1,s2,…,st},sj表示文档中的第j个句子。句子可由多个词组成,则该句子可以表示为sj={x1,x2,…,xn},xi表示句子中的第i词,词可以表示为xi={k1,k2,…,km},ki表示词的第i维度上的权重。经过词向量的拼接,句子可以表示为:

文档是由多个句子组成,则文档表示为:

其中⊕表示连接符,将组成的数据矩阵当做卷积层的数据进行特征提取。
2.2 卷积层与池化层
若句子可以表示为n×k维的数据矩阵,则通过高度为h(h=3,4,5)、宽度为k的卷积核进行卷积,提取新的特征向量,每个特征向量可表示为:

式(4)中,w、b分别表示卷积核权重、偏置项;f表示激活函数,常用的非线性激活函数有Sigmoid、Tanh和ReLu等;*表示进行卷积操作。首先通过卷积核对词序列(x1:h,x2:h+1,…,xn-h+1:n)进行卷积操作,获取一个新的特征向量:

然后采用池化减少输出维数,降低过拟合。本文使用1-max-pooling进行最大池化处理获取最大特征值,通过拼接组成新的特征向量作为分类器的输入。
2.3 XGBoost
XGBoost[14](eXreme Gradient Bosoting) 是Tianqi Chen在Gradient Boosting Decision Tree的基础上提出的。与传统的GBDT相比,XGBoost对损失函数利用二阶泰勒展开式增加正则项寻求最优解,避免过拟合。同时,在算法上加以改进提高了XGBoost的分类精度。
3 实 验
本文基于服务器搭建实验环境:操作系统Ubuntu 16.04 LTS,内存63GB,处理器为Intel Xeon E5-2650 V4,CPU 为 2.2GHz×8。 采 用以TemsorFlow为后端的Keras搭建卷积神经网络,以Python3.6为编写语言,实验开发工具为PyCharm3.6。
3.1 数据集
实验采用清华大学自然语言研究室提供的新浪新闻RSS开源的数据进行实验,共包含74万新闻文档,共14类别——财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐。每个类别标签有2 000样本数据,共计28 000样本数据集。其中,随机抽取20%作为测试集合。为了使结果具有统计意义,实验方法采用10折交叉验证。
3.2 性能评价
多标签分类问题类似于二分类问题,能够通过混淆矩阵进行性能评价。根据真实类别和预测类别可以分为真正类(TP)、真负类(TN)、假正类(FP)和假负类(FN)。采用准确率(Precision)、召回率(Recall)及F1值三个指标测试分类精确度。

准确率是预测为正的样本数与所有实际为正的样本数之比,召回率是预测为正的样本数与该类实际样本数之比,F1是综合准确率和召回率考虑的文本分类精确度。通过准确率、召回率、F1评估每一类分类性能。宏平均是指对所有类别的准确率、召回率、F1取平均值,以评估文本分类的总体性能。F1值会随着准确率、召回率的提高而提高,值越大,说明分类效果越好。
3.3 实验结果及分析
将预先由word2vec训练的128维词向量进行词嵌入,组成数据矩阵作为卷积层的输入,用不同尺寸卷积核进行文本特征提取。卷积核尺寸分别为3×128、4×128、5×128,每个尺寸卷积核共128个,非线性激活函数函数采用ReLu。为减少模型参数,降低模型参数复杂度,采用1-max-pooling提取该区域的最大值组成新的特征向量。通过设置Droput避免数据过拟合。为进一步验证CNNs-XGB模型的有效性,使用卷积神经网络进行特征提取后组合贝叶斯分类器、最近邻分类器、随机森林分类器、支持向量机分类器与XGBoost分类器进行对比。通过宏平均进行性能评估,实验结果如表1所示。

表1 不同分类模型的Macro-P、Macro-R、Macro-F1对比
从表1实验结果可以得出,CNNs-XGB文本分类模型分类效果最佳,其CNNs-KNN文本分类模型的分类效果不明显。为进一步验证不同分类模型在不同标签中的分类效果,将不同的分类模型作用于每类标签,分类效果分别通过Precision、Recall、F1进行对比,结果如图3、图4和图5所示。

图3 不同分类模型在不同标签上的准确率对比

图4 不同分类模型在不同标签上的召回率对比

图5 不同分类模型在不同标签上的F1对比
从图3、图4和图5中可以看出,CNNs-XGB分类模型作用于每个类别标签的Precision、Recall、F1都相对于CNNs-KNN、CNNs-NB、CNNs-RFC、CNNs-SVM模型稳定,其CNNs-KNN模型分类器分类效果波动较大,分类效果不佳。究其原因,在于KNN算法需要计算每个特征词之间的相似度进行对比,然后进行最近邻分类处理。14个类别标签中又分别含有一级标签和二级标签,如股票属于财经下的子标签、家居属于房产下的子标签、星座是娱乐下的子标签。类别标签间存在较多共性,特征词之间出现交叉现象,以至相似度判别时极易出现误差。由于XGBoost分类器能够对缺失的特征值进行自动学习处理,为避免陷局部最优进行反向剪枝,可将成百上千个分类准确率低的模型组合成一个分类准确率较高的模型进行分类处理。从实验结果可以看出,将卷积神经网络与XGBoost分类器组合的模型(CNNs-XGB),分类精确度均优 于 CNNs-KNN、CNNs-NB、CNNs-RFC、CNNs-SVM模型分类器。
4 结 语
本文针对传统文本表示特征维数高、数据稀疏、无法表征语义信息以及分类精度低等问题,基于word2vec进行词向量训练,解决了特征维数高、数据稀疏以及语义信息问题,并通过多尺寸卷积核进行数据特征提取,最后将卷积神经网络与不同分类器成功进行组合。实验证明,本文提出的CNNs-XGB分类模型分类效果具有有效性。后期将继续深入研究相似标签之间相似度的判别,以进一步提高文本分类精度。
