一种语音增强中新的噪声预估计算法*
2018-10-15何鑫,高勇
何 鑫,高 勇
(四川大学 电子信息学院,四川 成都 610065)
0 引 言
在语音通信系统中,语音信号总是不可避免地被环境噪声所污染,降低了通信系统的可靠性和有效性。语音增强技术便是从带噪语音中尽可能提取出纯净语音,保证语音通信的质量[1]。
语音增强算法的核心步骤在于噪声估计。噪声估计过大,会导致语音失真;噪声估计过小,会导致残留噪声较大。良好的噪声估计算法要求能够自适应跟踪噪声变化且收敛时间短[2]。现有噪声估计算法如最小值控制的递归平均(MCRA)算法[3]、最小值统计(MS)算法[4]等,都是预先设定一个噪声估计的初值,然后在此初值的基础上利用算法跟踪噪声的变化。上述噪声估计初值通过前导噪声段的功率谱计算均值得来。在一些特定场合,输入信号的前导段不再是纯噪声段,而是带噪语音。此时,若用传统预估计算法计算功率谱均值,便会导致噪声估计初值估计过大,进而增强语音会出现失真、掉字、损伤语音的可懂度。这种损失在通信质量要求高的场合是不允许的。为方便叙述,本文中将用于计算噪声估计初值的输入信号前导段称为预估计段。
针对上述问题,本文提出了一种新的噪声预估计算法,通过对输入信号预估计段的每一帧检测是否为噪声帧或带噪语音帧,对两种情况采用不同的方式进行噪声估计,能够使噪声估计初值更接近原始噪声水平,改善预估计段有语音时会出现掉字、失真的情况。2002年,Cohen提出了最优修正短时幅度谱对数最小均方误差(OM-LSA)算法[5]。该算法在非平稳以及低信噪比噪声环境下都能够保持良好的性能。因此,本文以OM-LSA算法为语音增强算法的框架,加入了本文提出的新的噪声预估计算法。实验表明,改进后的算法增强后的语音能够更好地保留语音成分。
1 OM-LSA算法介绍
假定噪声信号d(n)和纯净语音信号x(n)相互独立,互不相关,则被加性噪声污染的带噪语音y(n)的数学模型为:

对输入信号进行分帧加窗,作N点短时傅里叶变换(STFT)可得:

其中k为频点,l为帧数,Y(k,l)、X(k,l)、D(k,l)分别对应分帧后带噪语音、纯净语音、噪声的频谱。
OM-LSA算法是在MMSE-LSA算法[6]的基础上结合了语音存在概率得到的最优修正短时对数谱(LSA)估计器。OMLSA算法的流程如图1所示。
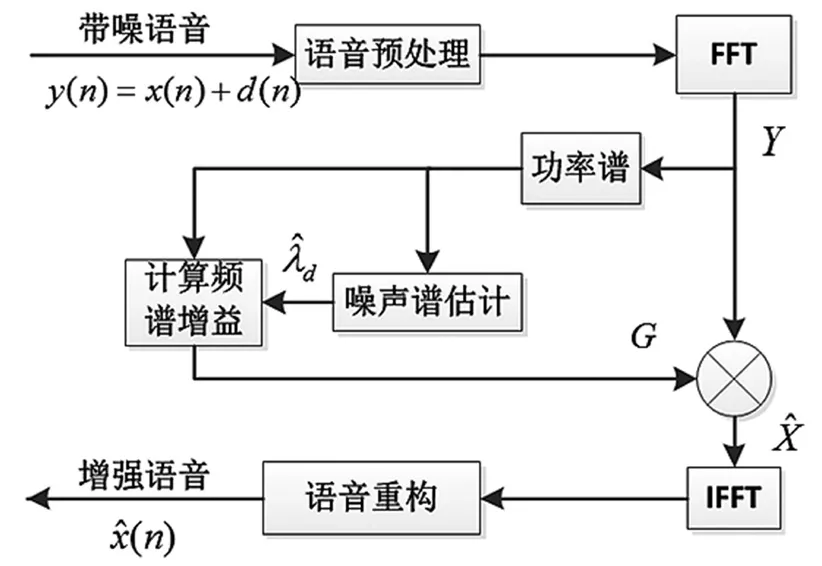
图1 OM-LSA算法
MMSE-LSA算法是计算一个谱增益因子DLSA(k,l),使(k,l)=GLSA|Y(k,l)|,(k,l)为纯净语音信号的估计谱,且ˆX(k,l)满足:
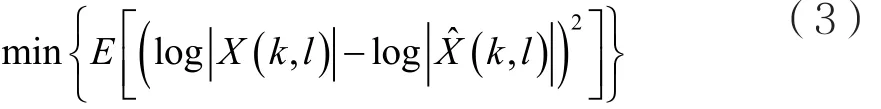
其中min{·}代表最小值,解式(3)可得[6]:
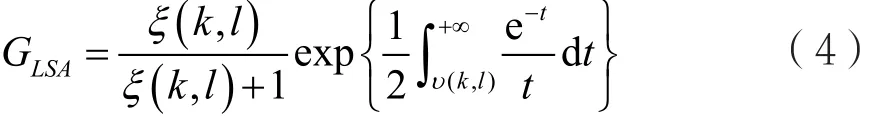
OM-LSA算法提出的语音存在概率是基于一个二元假设模型[7]:

其中H0(k,l)表示该帧语音不存在,输入信号为噪声;H1(k,l)表示该帧语音存在,输入信号为带噪语音。在H1(k,l)条件下,OM-LSA算法的谱增益因子就是MMSE-LSA算法的谱增益因子GLSA(k,l)。在H0(k,l)条件下,增益函数设置为最小值Gmin,以此来抑制音乐噪声。实验表明,Gmin的值取0.06有较好的效果。以p(k,l)代表一帧语音存在的概率,则可得到OM-LSA算法的谱增益因子为:
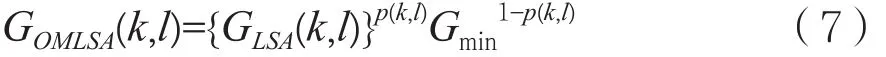
2 新的噪声预估计算法
对一帧语音信号进行N点短时傅里叶变换得到Y(k,l),计算其功率谱S(k,l)=|Y(k,l)|2。改进的噪声预估计算法检测预估计段中每一帧输入信号是否为带噪语音。若当前帧为带噪语音时,则使用本文算法从该帧中估计出噪声值,若当前帧为噪声时,直接用该帧功率谱为该帧噪声估计值。
具体方法为:

其中λ(k,l)为第l帧估计的噪声值,speechFlag=1代表第l帧为带噪语音帧,speechFlag=0代表第l帧为噪声帧,()ˆ,k lλ为该帧为带噪语音时从该帧估计出的噪声功率谱。
由于语音信号的能量主要分布在低中频区域,噪声对语音频谱的影响在频率上并不是均匀分布的。因此,当在预估计帧为带噪语音时,通过带噪语音功率谱的高频区域提取的信息可以更可靠地估计和更新噪声谱[8]。
高频区域功率谱的计算选取为:

通过高频区域功率谱求平均得到的值在有些频点上可能会过大估计噪声。为防止过估计,由式(10)进行调节。
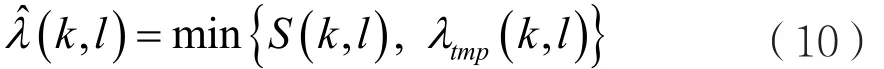
语音和噪声在功率谱域差异较大。语音段的功率谱在频带上分布不均匀,在共振峰处有大的峰值。而噪声的功率谱在整个频带则为均匀分布,变化较为缓慢[9]。功率谱方差能够很好地反映各频带之间的起伏程度,因此根据一帧输入语音信号中低频与高频功率谱方差的差异,可以很好地来区分一帧语音是否为带噪语音[10]。
功率谱方差计算为:

利用语音信号能量主要分布在中低频、噪声能量在全频段这一信息,对每一帧语音的功率谱的中低频和高频计算功率谱方差得到D1(l)、D2(l):
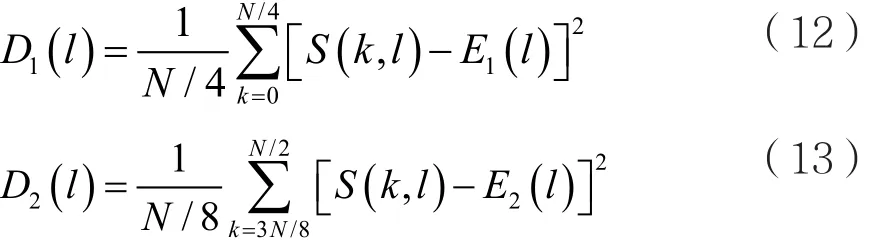
通过2个不同频段功率谱方差的比值,确定此帧是否为带噪语音。
具体方法为:

其中α为一个经验值,本文经过大量试验后选取 α=10。
最后,通过预估计段中每一帧估计的噪声功率谱计算均值得到噪声估计初值为:
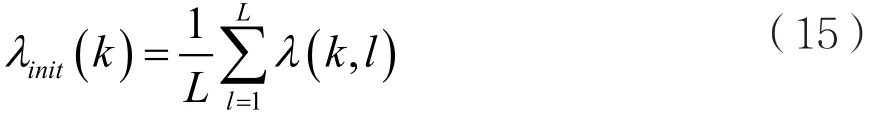
其中L为预估计的总帧数,λInit(k)为最终得到的噪声估计初值。
3 实验及结果分析
为验证算法的效果,进行数据实验和分析。实验数据采样率为8 kHz,帧长和离散傅里叶变换的点数都取256,帧间重叠1/2,采用汉明窗对每帧数据加窗。实验从噪声库Noise-92中选取高斯白噪声,从TIMIT库中任意选取出多条纯净语音,分别生成
0 dB、3 dB、5 dB、10 dB的带噪语音。
实验以OM-LSA算法为语音增强的框架,以传统预估计和本文提出的预估计算法进行比较,通过时域波形图、分段信噪比(segSNR)和感知语音质量评估(PESQ)音质测度对语音增强算法的性能进行评测。
segSNR的计算公式[11]为:

segSNR越大,增强效果越好。PESQ是2001年国际电信联盟(ITU-T)推出的P.862标准,用来评价语音的主观试听效果,PESQ是基于人对语音的感知模型来评价语音质量的方法,其分值在1~4.5,4.5为最好(纯语音),1为最差。PESQ得分越高,表示语音质量越好[12]。
时域波形图对比如图2所示。
通过图2可以看出,在输入信号预估计段为带噪语音信号时,传统预估计算法增强后的语音信号出现了较多失真,这是由于对预估计段的带噪语音功率谱求均值得到的噪声初值估计过大导致的。改进预估计算法增强后的语音信号,则很好地保留了语音成分,且降噪量和传统预估计算法相当。
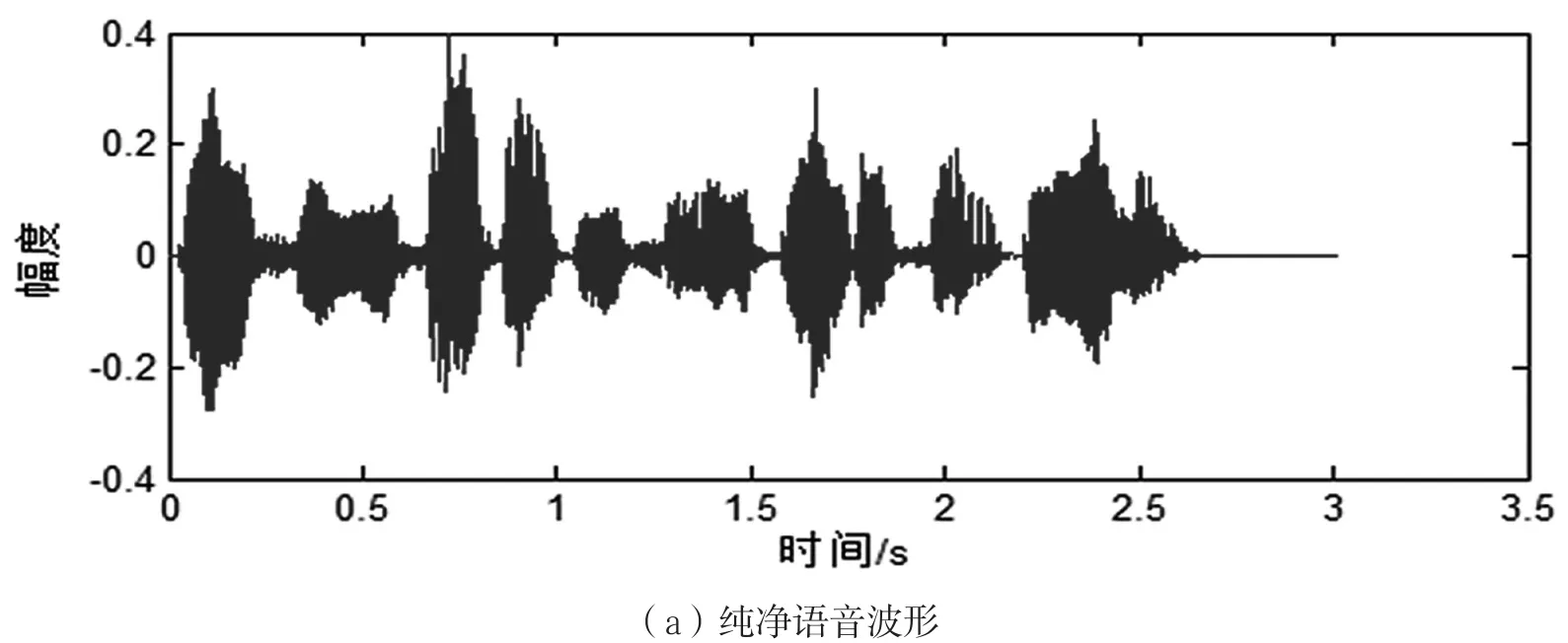

图2 两种预估计算法语音增强后时域波形对比
表1和表2是对不同噪声环境下两种预估计算法增强后的语音segSNR和PESQ对比。

表1 两种预估计算法在不同环境下segSNR对比
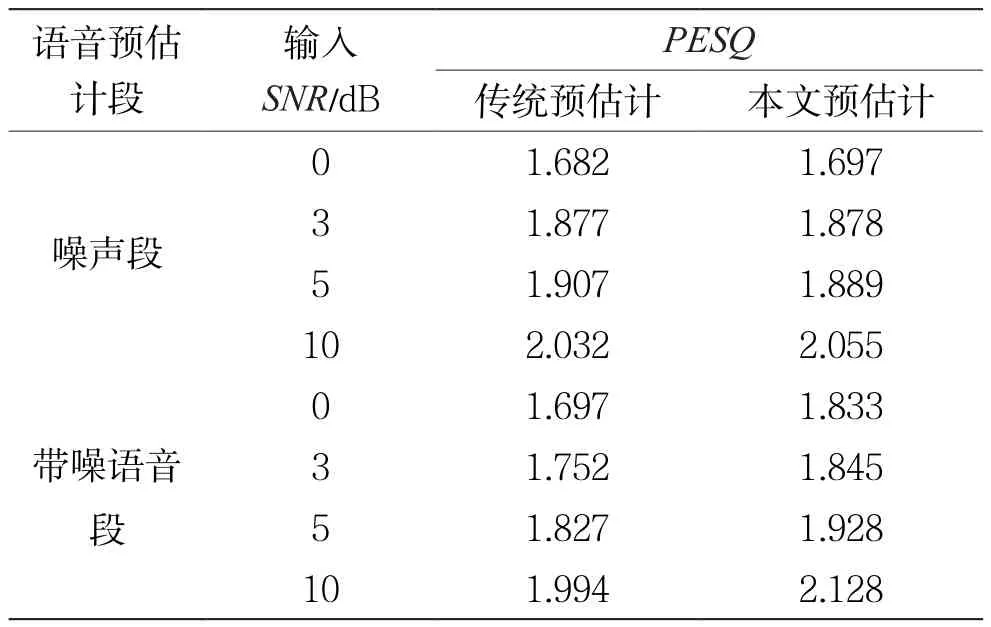
表2 两种预估计算法在不同环境下PESQ对比
通过表1与表2的数据可以看出,在预估计段为噪声段时,本文提出的改进预估计算法和传统预估计算法性能相当,说明在使用功率谱方差判断该帧是否为带噪话音帧时判断正确率高。而在预估计段为带噪话音段时,改进预估计算法增强后语音的PESQ和segSNR值明显比传统预估计算法高,表明增强后语音质量高,新的预估计算法能够更好地适应不同的通信环境。
4 结 语
与传统预估计算法不同,改进预估计算法能够在前导预估计段为带噪语音段时,使噪声初值估计更接近原始噪声水平。本文算法利用噪声与语音在整个频段上的分布特性和功率谱方差的差异特点,能够很好地检测输入信号的一帧是否为带噪语音,从而更准确地估计噪声初值。改进后算法在时域波形、PESQ、segSNR的对比结果表明,预估计段为带噪语音时有更好的降噪效果。
