支持大规模地震探测数据快速可视化的云端数据缓存技术
2018-10-09魏晓辉崔浩龙李洪亮
魏晓辉, 崔浩龙, 李洪亮, 白 鑫
(吉林大学 计算机科学与技术学院, 长春 130012)
地震勘探是勘测地下石油与天然气资源的重要方法, 在地壳研究等领域应用广泛. 勘探过程由数据采集、 数据处理和数据解释3个阶段组成. 通过数据采集获得反射回来的原始地震波信号, 运用降噪、 削弱干扰、 提高分辨率等进行数据处理, 对处理后的三维地震体数据进行可视化, 可直观地展现地球深部的具体构造, 方便领域内专家对地震数据进行解释, 为科学研究和资源勘探提供了便利工具.
目前, GOCAD,GeoEAST,Petrol,Ocean等三维建模软件主要以处理解释一体化的模式运作, 在集中的数据管理层上对地震数据进行可视化, 随着数据采集技术的迅猛发展, 以及人们对高精度、 高分辨率数据的需求增加, 地震数据量级也呈指数级增长, 而计算机的存储能力并不会无限扩展. 因此许多平台在面临大规模数据的存储瓶颈时选择将其分成多个小数据块进行加载, 但该方法并未解决计算机存储能力有限的问题, 使可视化平台的发展受到限制. GOCAD是目前国际公认的主流建模软件, 具有强大的三维建模、 数据可视化、 地质解释和分析的功能, 实现了高水平的半智能化建模[1-4]. GeoEast地震数据处理解释一体化系统是国内在该领域探索的代表, 系统整体功能已达到国际先进水平[5-6]. 但这些三维地震体数据可视化系统都有一个共同缺陷, 就是对地震数据进行集中处理解释, 面对地震数据规模的快速增长, 在未来必将产生地震数据规模过大与存储容量不足之间的矛盾.
用户在对地震数据访问的过程中不会随时都需要完整的数据, 而是仅关注其中的某些区域, 称为“兴趣区域”[5,7-8], 随着用户的拖拽、 放大、 缩小等操作, 兴趣区域也会随之转移, 带来不同分块文件的更替. 如果能对用户的访问行为进行预测, 在用户关注当前区域时预测其下一步需要的数据, 提前从文件系统加载到缓存中, 就能大量减少用户等待时间. 文献[9-10]对经典的访问预测算法——LS(last successor)算法进行了研究: 文献[9]提出将文件访问顺序与用户身份绑定, 以应对不同用户在访问同一文件后分别访问不同文件的情形; 文献[10]则提出记录当前访问文件的两个后继, 作为对LS算法仅记录一个后继文件的扩充. 但上述方法均不适用于地学数据可视化过程中复杂的访问模式, 用户对地震数据的访问会根据不同的可视化需要而变化, LS访问预测算法无法适应该需求.
基于以上地学数据可视化平台面临的问题, 本文提出一个构造云数据中心存储数据, 在客户主机上部署轻量级客户端程序按需远程加载数据的计算模式, 解决了海量地震数据的存储难题; 并提出使用分布式缓存技术, 避免客户端与服务端之间频繁的网络通信, 同时减少服务端访问云端文件系统带来的延迟; 基于关联规则挖掘用户对地震数据的访问模式, 将符合概率条件的文件访问顺序记录下来, 用于预测用户下一步访问, 适应用户多种访问模式的情形. 实验结果表明, 本文工作有效减少了客户端的存储占用, 实现了远程地震数据在本地的快速可视化.
1 地震探测数据云存储架构
1.1 系统模型
本文提出的云存储系统分为提供大规模数据存储服务的云数据中心与对地学数据进行可视化解释的远程客户端两部分, 利用网络进行通信. 在云端存储部分, 采用八叉树结构对地震数据进行分块处理, 将数据块线性排列进行编码, 一个数据块称为一个tile, 若干tile构成一个file, 组成地震数据块的索引. 利用地震数据一次写入多次读取的应用特性, 将建立索引的地震数据分块存储在Hadoop分布式文件系统(HDFS)中, 解决了单机集中存储大规模地震数据时面临的存储容量瓶颈问题, 同时依靠HDFS对数据文件副本的管理策略, 使得云端存储系统能为用户提供高可用性的数据服务. 远程客户端可部署在计算机、 工作站、 移动设备等多种硬件平台上, 按需从云端存储获取数据块进行可视化. 为了避免客户端与云存储频繁进行数据传输, 加速数据加载过程, 在客户端与云端设立分布式缓存, 将常用的数据块缓存到内存或本地存储中, 降低了频繁数据传输带来的额外时间开销, 实现了大规模地震数据在轻量级客户端下的快速可视化.
基于云端数据缓存系统架构的地学数据可视化平台, 能实现轻量级的客户端软件, 简化平台部署流程, 减少客户端的存储容量占用, 同时云端存储的数据能支持多用户共享, 允许多个远端用户对数据的并发操作, 利用分布式缓存加快了数据加载过程, 实现地震数据的快速可视化.
云存储架构具有客户端和云数据中心两层缓存, 其中云数据中心由地震数据索引、 HDFS、 云端数据缓存、 ARLS(association rule last successor)访问预测算法组成, 大规模地震数据被分布存储在HDFS中, 任意地震数据中tile数据块在HDFS中的存储位置由地震数据索引维护, 便于云存储系统快速定位到所需数据的存储位置进行加载, ARLS访问预测算法根据用户的访问模式预测用户行为, 提前预取用户所需的数据, 云端数据缓存与客户端缓存按照分布式缓存管理策略存储近期经常使用的数据块, 减少数据通信及对文件系统的访问频率, 以支持大规模地震数据的快速可视化.
1.2 大型地震数据快速三维可视化
地震探测数据云存储系统结合了地震数据索引[11-12]、 分布式文件系统HDFS、 访问预测算法、 分布式缓存[13]、 Boost网络通信等技术, 整合了广泛分布的存储资源, 将大量丰富的大型地震数据资源放置在云存储系统中进行统一管理和调度, 以低成本、 高可靠性地为用户提供高性能、 按需的数据资源. 用户无需关心云存储的架构和存储方式, 可在任何地方快速访问需要的地震数据, 克服了集中存储模式的不足, 实现了云端大型地震数据的快速三维可视化.
云存储系统不仅以八叉树结构对地震数据进行分块处理, 还利用八叉树对地震数据进行了多种分辨率的采样, 以满足用户需求的多样性. 当客户端设备与云存储系统建立初始连接时, 云存储系统先为用户返回所需数据的低分辨率采样, 保证客户端设备能快速显示出可视化的地震数据. 用户之后会对低分辨率可视化结果进行操作, 如拖拽、 拉伸、 放大、 缩小等, 这就需要更高分辨率的数据来完成, 因此客户端向服务器提出数据加载请求.
服务器在等待客户端数据请求的这段空闲时间内, 利用用户的历史访问记录, 通过ARLS访问预测算法找出用户下一步最可能访问的数据, 提前预取到云端数据缓存. 当接收到用户的数据请求后, 先到云端数据缓存中进行查找, 如果数据已经预取, 则可直接返回给用户, 避免了用户等待, 同时访问预测模型会继续预测下一步需要的数据; 如果数据未预取到缓存中, 则需要根据地震数据索引获得数据在集群中的位置, 将其加载到云端数据缓存中, 并返回给用户, 访问预测模型也会根据用户的访问实时进行调整, 以保证预测的准确率.
服务器可以并行处理多用户的数据请求, 并在服务器和客户端建立了双层数据缓存, 客户端部分利用内存作为高速缓存, 用于存储近期可视化的数据; 云端数据缓存则根据访问预测模型的结果, 存储未来热点区域的数据, 避免数据查找和读写持久化存储设备, 加速了地震数据的可视化进程.
1.3 API接口
集中存储地震数据的云数据中心需要提供一些API接口, 便于客户端远程连接到数据中心对文件进行相应操作, 也为服务器检索、 加载数据文件、 获取访问预测结果、 维护云端数据缓存提供工具, 其中对八叉树结构的索引记录在.ldm文件中, 由SEG-Y转换的tile数据存储在.dat文件中, 二者共同构成LDM文件供平台加载数据使用. API接口功能列于表1.
云数据中心为开发者提供了对云端数据缓存和并行文件系统操作的应用接口, 直接对外提供了针对地震数据的数据服务, 使开发者可远程使用数据中心开放的地震数据构建自己的独立应用, 进行地震数据的研究与分析工作, 研究数据不再仅局限于科研领域, 而是供各行业根据自身需要发掘其中蕴含的价值, 真正实现数据开放与共享.
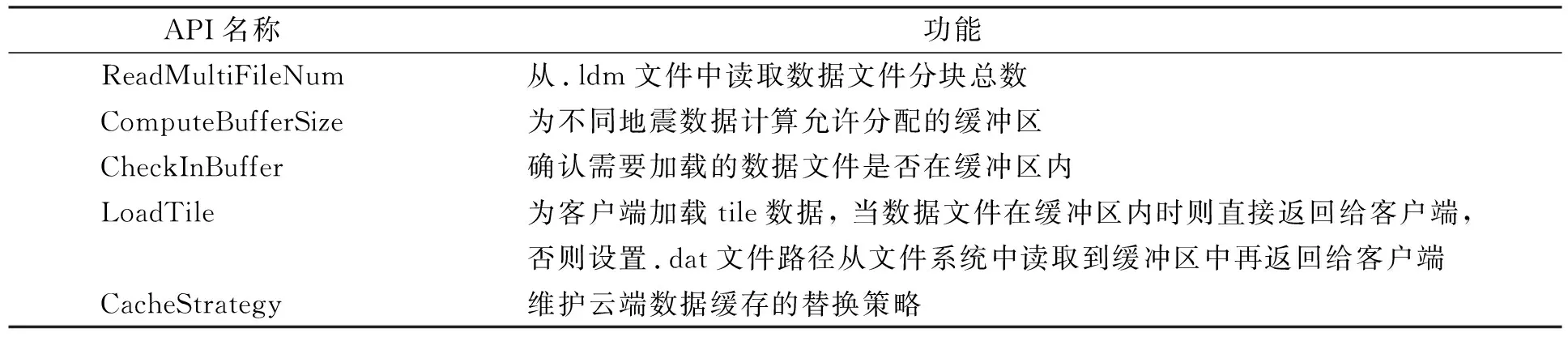
表1 API接口功能
2 云端数据缓存
2.1 数据组织与索引
OpenProbe地学数据可视化平台是一个具有自主知识产权的可视化平台, 也是对本文缓存技术进行验证的实验平台, 该平台解决了数据规模过大与内存容量有限的矛盾, 实现了内存的动态加载机制, 能在集中模式下对数据进行快速可视化. OpenProbe平台的OpenProbeLDM模块为上层渲染模块提供了面向大规模地震数据的数据访问接口, 支持对勘探行业普遍使用的SEG-Y格式三维地震数据的快速可视化, 能将海量三维体数据以八叉树的格式进行分层和分块, 以获得多分辨率数据块, 在数据渲染过程中根据需要实时将所需数据块加载到内存中, 实现在有限的内存条件下对大规模地震数据的实时渲染.
八叉树存储结构在对三维体数据进行划分与存储时, 将体数据放置在一个能容纳它的最小满八叉树中, 根据体数据的规模计算八叉树的层数, 逐层对体数据进行八等分, 每个数据块作为八叉树结构的一个节点, 称为tile, 其中第(n-1)层的数据块由第n层的数据块采样而形成, 据此形成上层的低分辨率数据. 将三维体数据划分而成的八叉树结构线性存储在磁盘文件中, 对所有数据块进行编码, 使用tileID标识唯一的数据块, 从而建立数据索引, 对三维体数据用八叉树划分过程如图1所示.

图1 三维体数据的八叉树存储结构Fig.1 Octree storage structure of three-dimensional data
本文将远程数据缓存技术应用在OpenProbe平台上, 使用八叉树结构对三维地震体数据进行数据索引, 利用云数据中心的API接口进行客户端与云端系统的交互, 实现了以下目标:
1) 构建云数据中心集中存储大规模地震数据, 节约了客户端的存储资源;
2) 建立远端服务器数据缓存, 提出ARLS访问预测算法, 提高了缓存命中率, 加速了数据加载过程;
3) 建立客户端的本地数据缓存, 减少网络通信频率, 使远程数据加载的时间开销接近本地数据加载;
4) 节约客户端设备的软、 硬件资源, 在低消耗的前提下完成数据的快速可视化.
2.2 ARLS访问预测算法
在地学数据可视化过程中, 人们通常在同一时间无法关注整个地震数据, 而是仅关注某一特定区域, 该区域称为“兴趣区域”. 伴随着对地震数据诸如拖拽、 放大、 缩小等操作, 兴趣区域会随之转移, 导致对不同分块文件的频繁访问, 在很多系统中, 这种数据访问模式都被视为独立事件. 事实上, 数据请求并非完全随机, 而是用户或程序行为驱动的, 存在特定的访问模式[14]. 如果能对用户的访问模式进行预测, 将下一步要访问的文件预取到服务器缓存中, 即可节省大量的文件检索与读取时间, 因此本文在服务器端根据用户对地震数据访问的历史记录运行文件访问预测算法, 对用户未来的访问模式进行预测.
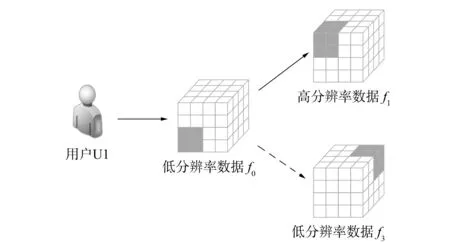
图2 用户的不同访问模式Fig.2 User’s different access modes
对用户访问记录进行分析表明, 由于不同时刻用户对数据浏览的需求不同, 其对文件的访问模式并不唯一. 如图2所示, 用户U1在初始加载低分辨率数据f0后会有两种访问模式: 当用户需要仔细查看当前区域, 对当前区域进行放大时, 会需要该区域内的高分辨率数据f1; 当用户大致浏览整个地学数据时, 会快速移动可视区域, 需要剩余的低分辨率数据f3. 用户有多种访问需求时, 会形成多个访问模式. 经典的文件预测模型LS在面对这种情形时只能选择一个后继作为f0的预测结果, LS预测严重依赖于访问顺序, 面对用户切换访问模式时会失效.
本文提出一种ARLS算法, 通过使用数据挖掘中常用的关联规则, 挖掘文件访问顺序之间的联系. 其中用户的历史访问记录为H, minsup为最小支持度, 最终预测结果存储在STL关联容器M中, 算法描述如下.
算法1(ARLS) ARLS (H,minsup,M).
遍历历史记录H;
产生单元素构成的频繁项集L1={large 1-items};
根据L1生成二元项构成的候选集C2;
forall recordr∈Hdo begin
选出出现在C2中的记录r, 构成集合Cr;
forallc∈Crdo
c.count++;
end
从C2中选出c.count≥最小支持度minsup的项构成二元频繁项集L2;
end
遍历二元频繁项集L2, 以第一个元素为key, 第二个元素为value生成访问预测记录, 存储在关联容器M中;
end.
最小支持度minsup由用户确定, 最终L2保存了符合筛选条件的二元频繁项集, 即为用户最常用的访问顺序, 将结果以〈front, successor〉的键值对形式保存在关联容器M中, 一个前驱文件可对应多个后继文件, 全面覆盖用户常用的访问模式. 实验证明, ARLS访问预测算法的平均准确率达到91.3%, 能有效预测用户的访问行为.
3 系统原型设计与实现
3.1 云存储系统
地震探测数据云存储系统借用OpenProbe项目实现, 客户端保留了OpenProbe的绝大多数功能, 但不再保存完整的地震数据, 而是通过内存缓存保存近期可视化区域用到的数据. 首先将近期使用的数据存储在内存缓冲区, 当内存缓冲区容量不足时, 根据LRU替换策略将最近不常用的数据删除, 以减少网络通信开销, 保证最近正在使用的数据文件一直存在于本地缓存中. 客户端缓存的生命周期从数据可视化开始到会话结束为止, 对地震数据可视化结束后, 客户端程序将缓存池中的缓存数据清空, 始终保持客户端的轻量级特性.
服务器端则是一个全新的系统实现, 仅保留了八叉树的数据索引规则, 利用基于关联规则的ARLS算法挖掘用户历史访问记录中的访问模式, 在满足当前用户访问请求的同时预测用户下一时刻需要的数据, 预取到云端缓存. 云端缓存是长期缓存, 如果客户端请求的地震数据被访问预测算法正确预测, 则数据文件会提前预取到缓存中, 服务器直接将数据文件发送给客户端, 充分利用了服务器空闲等待的时间, 提高了数据获取效率. 尽管访问预测算法对用户单独建模, 但由于服务端的同一地震数据对多个客户端是共享的, 因此在缓存时, 不同用户对同一数据的预取存储在一个缓存区中. 服务端的缓存长期存在, 可最大限度减少当某个用户的访问预测失败时所需数据不在缓存中的情形出现, 以满足众多客户端的快速可视化.
3.2 分布式缓存空间管理
分布式缓存中的客户端是短期缓存, 存储的分块文件大小均等, 因此数据文件在缓存中驻留时间仅与访问频率有关, 使用LRU替换策略维护本地内存缓存, 根据不同设备设置内存缓存的最大阈值, 避免对设备运行产生过重负担. 使用队列记录内存缓存的数据标识, 当对某一数据文件进行访问时将该标识重新放到队尾, 缓冲队列容量超过阈值后将队首的数据文件移出当前缓冲区, 并从客户端删除. 由于地震数据在使用过程中仅涉及到读操作, 因此无需对其进行一致性维护.
云端数据缓存是长期缓存, 为多个客户端的不同数据请求提供服务, 需要存储多个地震数据不同规模的分块文件, 因此数据文件在缓存区驻留的时间由访问频率和文件大小共同决定, 对每个数据文件计算一个称为使用度的值M, 该值与客户端访问数据文件的频率F及数据文件占服务端缓存区的百分数S有关, 可将M表示为:M=Fa1×Sa2, 其中指数a1和a2均为大于0的整数, 由服务端管理员指定, 决定访问频率F与容量占用S之间的相对重要性, 当服务端缓存容量不足时, 替换出M值最小的数据文件.
3.3 数据分发与传输
分布式缓存机制避免了数据反复的读入、 取出, 减少了I/O开销, 客户端的短期缓存保证使用频率高的数据存储在本地, 减少了网络通信次数, 当数据可视化所需的数据不在本地时, 与云数据中心建立连接, 进行网络通信, 因此需要构建相应的数据通路.
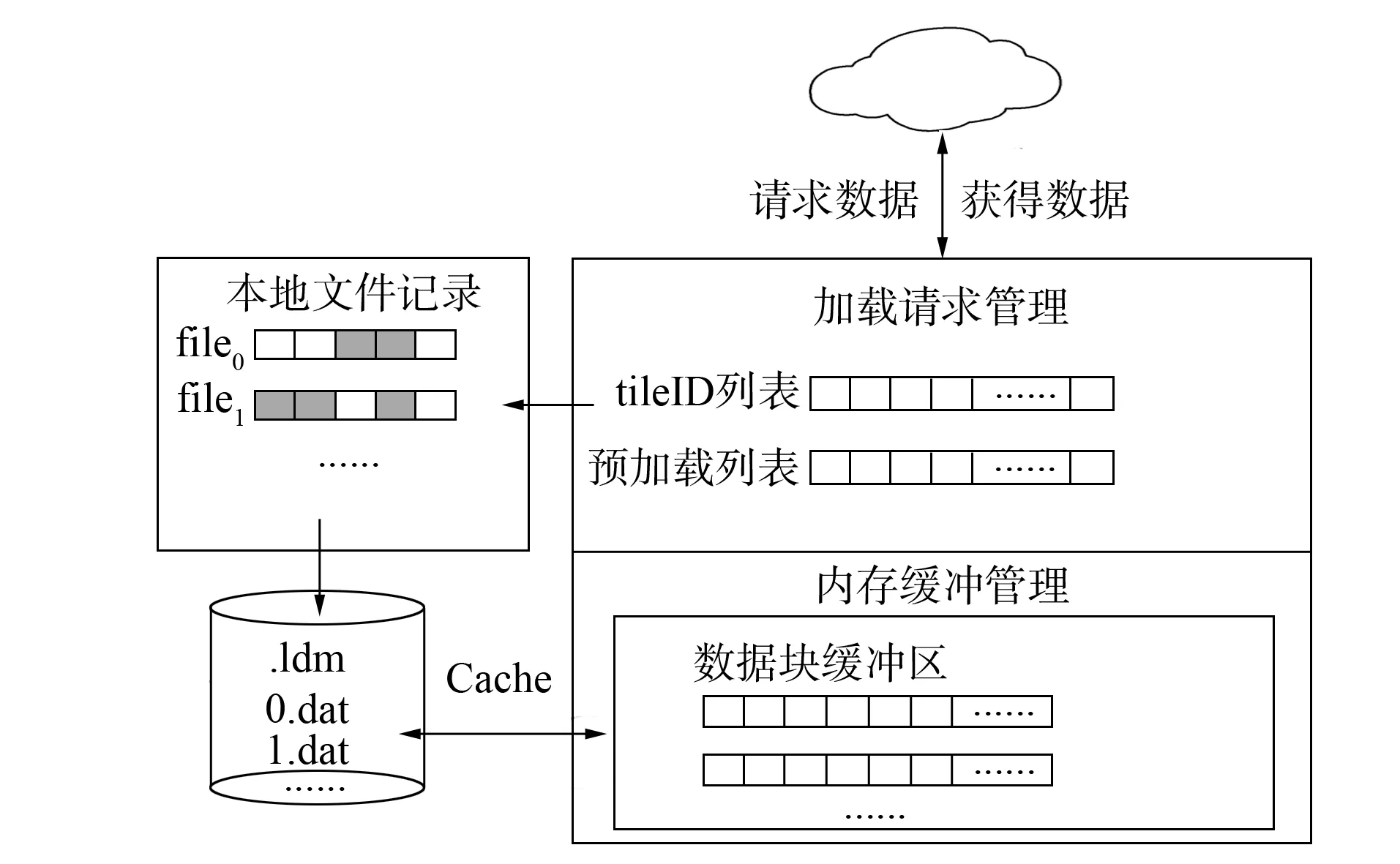
图3 数据加载流程Fig.3 Data loading process
客户端在提出数据加载请求时, 根据tileID找到对应的.dat文件标号fileID, 查找本地文件记录判断是否需要远程数据加载, 如果需要则构造通信消息, 携带如fileID、 文件路径、 tileID和tile数据的偏移量等信息发送到云数据中心, 服务器返回tile所在的整个文件到客户端形成数据缓存, 数据加载流程如图3所示.
在数据通信过程中, 需要传递消息和数据文件对象, 因此需要对数据对象进行数据序列化, 转换成二进制字节流在网络上传输. 服务器与客户端传输的数据文件规模超出了Socket对传输数据量的限制, 需要实现分包等操作. 基于以上两点原因, 本文使用Boost作为函数库, 其中的Serialization在数据序列化方面不需要其他中介文件(如XML等)提供序列化支持, 支持对用户自定义类的对象和STL容器对象进行序列化; Asio对Berkeley Socket APIS进行了封装, 提供了网络编程常用的操作系统接口, 使得底层的数据分包等操作对程序员不可见, 因而无需考虑传输数据量的限制, 极大简化了数据通信流程, 提高了网络传输效率.
4 实验结果
4.1 实验环境
云存储系统: 吉林大学高性能计算中心节点. 中科曙光A620r-G机架式服务器, 配置如下: 2×AMD Opteron 6386 SE(16核, 2.8 GHz, 16 MB L3级Cache); 64 GB(16×4 GB)DDR3 1 600 MHz内存; 9×500 GB SATA2.5″硬盘; Linux 操作系统: Redhat Enterprise Linux 5.5, 64 bit.
客户端: ThinkStation C30工作站, 2×Intel Xeon E5-2620(6核, 2.0 GHz, 15 MB L3级Cache); 4 GB(2×2 GB)DDR3, 1 600 MHz内存; 1 TB SATA Ⅲ3.5″硬盘; Windows操作系统: Windows10 Professional 64 bit.
网络带宽: 100 M以太网, 平均传输速率15 MB/s. 应用软件: OpenProbe V1.0. 测试用例: 107 MB, 770 MB, 2.15 GB.
4.2 地震数据可视化效果
OpenProbe平台在数据可视化过程中最重要的环节是数据加载, 本文首先测试平台在云存储结构中加载不同规模数据的效果, 如图4所示, 其中: (A)为107 MB数据; (B)为770 MB数据; (C)为2.15 GB数据; 缓存规模为32 MB, 用于模拟实际环境中地震数据规模与缓存规模相差数倍的情形. 测试结果表明, 对于不同规模的数据, 客户端能从云数据中心加载到本地获得良好的可视化效果.
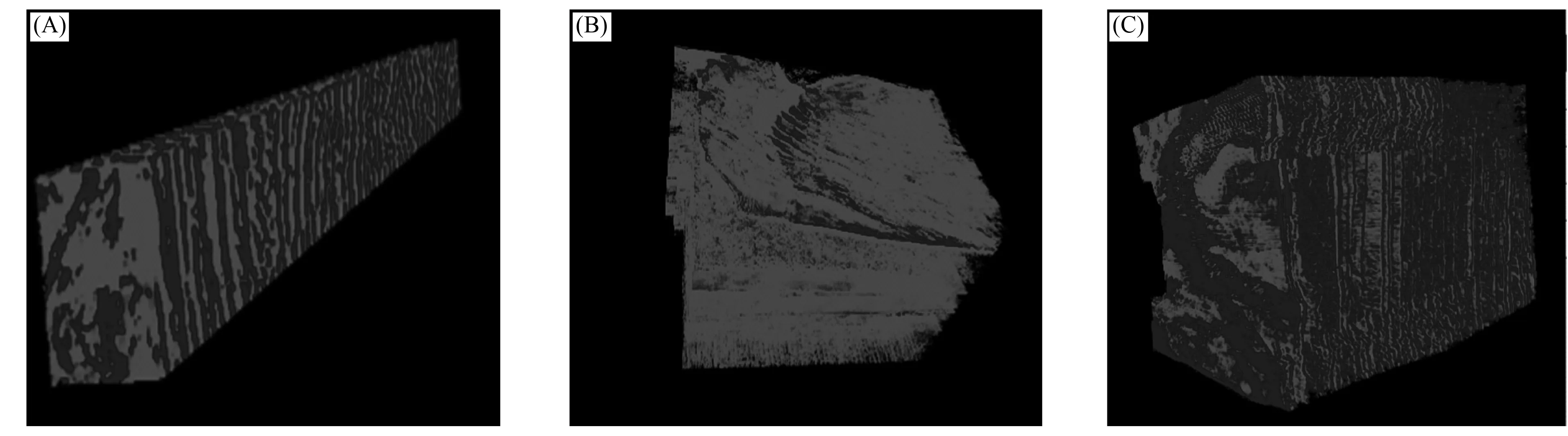
图4 地震数据可视化效果Fig.4 Visualization effect of seismic data
4.3 ARLS访问预测算法准确率分析
本文提出了基于分布式缓存和ARLS访问预测算法的分布式地震数据可视化平台, 其中ARLS访问预测算法能预测用户未来所需的数据文件, 利用服务器空闲时间预取数据到云端缓存, 通过提高云端缓存的命中率进一步节省服务器与云存储之间的文件检索和加载耗时. 图5为ARLS访问预测算法的准确率, 选取地震数据访问记录中的100条用于训练集, 25条用于验证算法准确率, 对测试用例在不同缓存规模(32 MB,64 MB,128 MB)下进行实验(实际环境可根据地震数据大小增大缓存容量). 由图5可见, 当地震数据被划分为约20个缓存文件时, 本文所用的预测算法能获得82%以上的准确率, 当缓存文件个数增至30个以上时(A点), 准确率只有47.59%, 但将历史记录增加为200条后, 准确率会增至75%. 因此访问预测算法需要获得大量的、 多样的历史数据进行训练, 并需要与缓存管理系统协调, 根据地震数据规模合理划分缓存文件大小, 在保证准确率的同时, 确保频繁访问的缓存文件会长时间驻留在缓存区. 根据数据加载时间可知, 即使在A点情形下(准确率47.59%, 缓存规模32 MB, 文件68个), 也可节省文件加载时间为194 s, 鉴于云端会面临多种地震数据的并发访问, 本文提出的ARLS访问预测算法能有效利用服务器空闲时间, 避免了文件系统导致的延迟.
4.4 不同访问预测算法比较
图6为对经典LS访问预测算法、 LNS算法[9]、 DLS算法[10]与本文ARLS算法在不同数据规模下的平均访问预测准确率的比较结果. 随着地震数据规模增大, 划分的数据文件个数也增多, 用户越有可能出现多样的访问模式. 测试结果表明, 本文提出的ARLS算法能适应不同规模的数据访问, 相对LS访问预测算法77%的平均准确率, ARLS算法的平均准确率达到91.3%, 能适应用户拥有多种访问模式的情形.
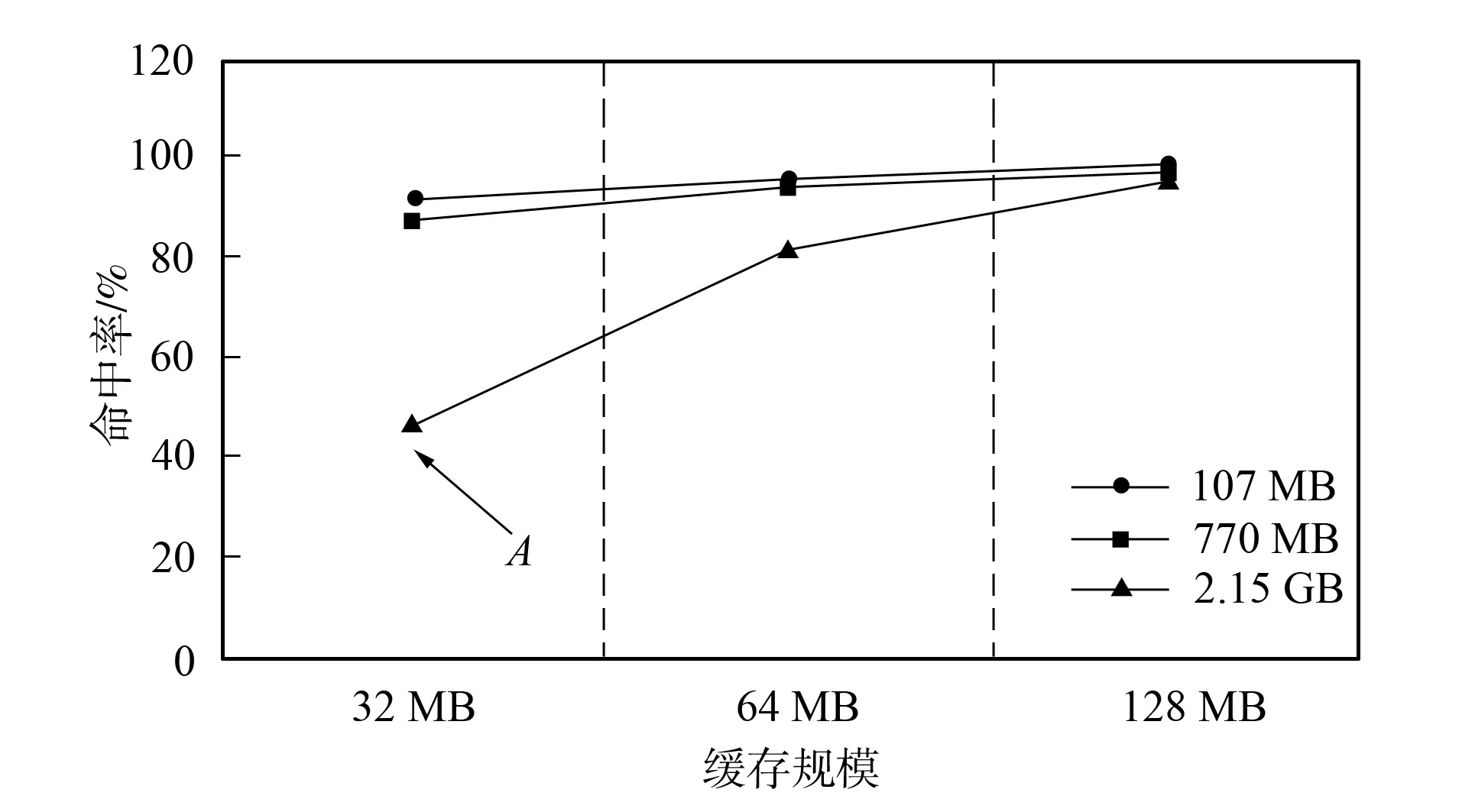
图5 ARLS访问预测算法准确率Fig.5 Accuracy of ARLS access prediction algorithm
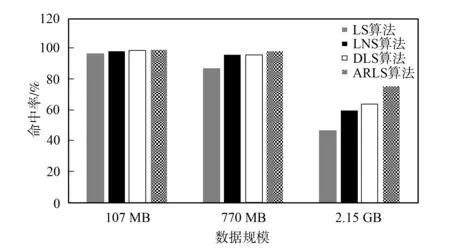
图6 不同访问预测算法比较Fig.6 Comparison of different access prediction algorithms
4.5 云端缓存命中率分析
图7为对本地缓存需要的数据能否在云端缓存命中进行分析的结果, 将3种示例数据分别在缓存规模为32 MB, 64 MB和128 MB情形下进行实验. ARLS访问预测算法通过数据预取的方法, 能够提高云端缓存命中率, 使用户的数据请求立刻被服务器响应, 降低了用户的访问延迟. 由于云端缓存存储了多个用户对于同一数据文件的预测结果, 因此可有效降低缓存未命中与ARLS访问预测失败同时出现的概率. 由实验结果可见, 云端缓存命中率在最差情形下也达到了69.1%, 平均缓存命中率达95.61%, 大幅度提高了远程数据的加载效率.
4.6 平台整体性能分析
为分析分布式缓存和ARLS访问预测算法对地学数据可视化平台整体性能的提升效果, 分别使用LS,LNS,DLS算法的C/S架构作对比研究, 结果如图8所示. 由于分布式缓存和云端ARLS访问预测算法的实现, 平台性能较对比架构大幅度提升, 尤其对大规模地震数据进行可视化的过程中, 地学用户能在可容忍的数据加载时间内(可视化过程的平均延迟, 横线标识为120 s, 实际使用过程中统计的经验值)获得理想的可视化效果, 并大幅度减少了本地存储资源的占用. 由实验结果可知, 基于云存储的地学数据可视化平台整体性能较其他平台架构提高了70%, 实现了云端地震数据在客户端的快速可视化.

图7 云端缓存命中率分析结果Fig.7 Analysis results of cloud cache hit rate
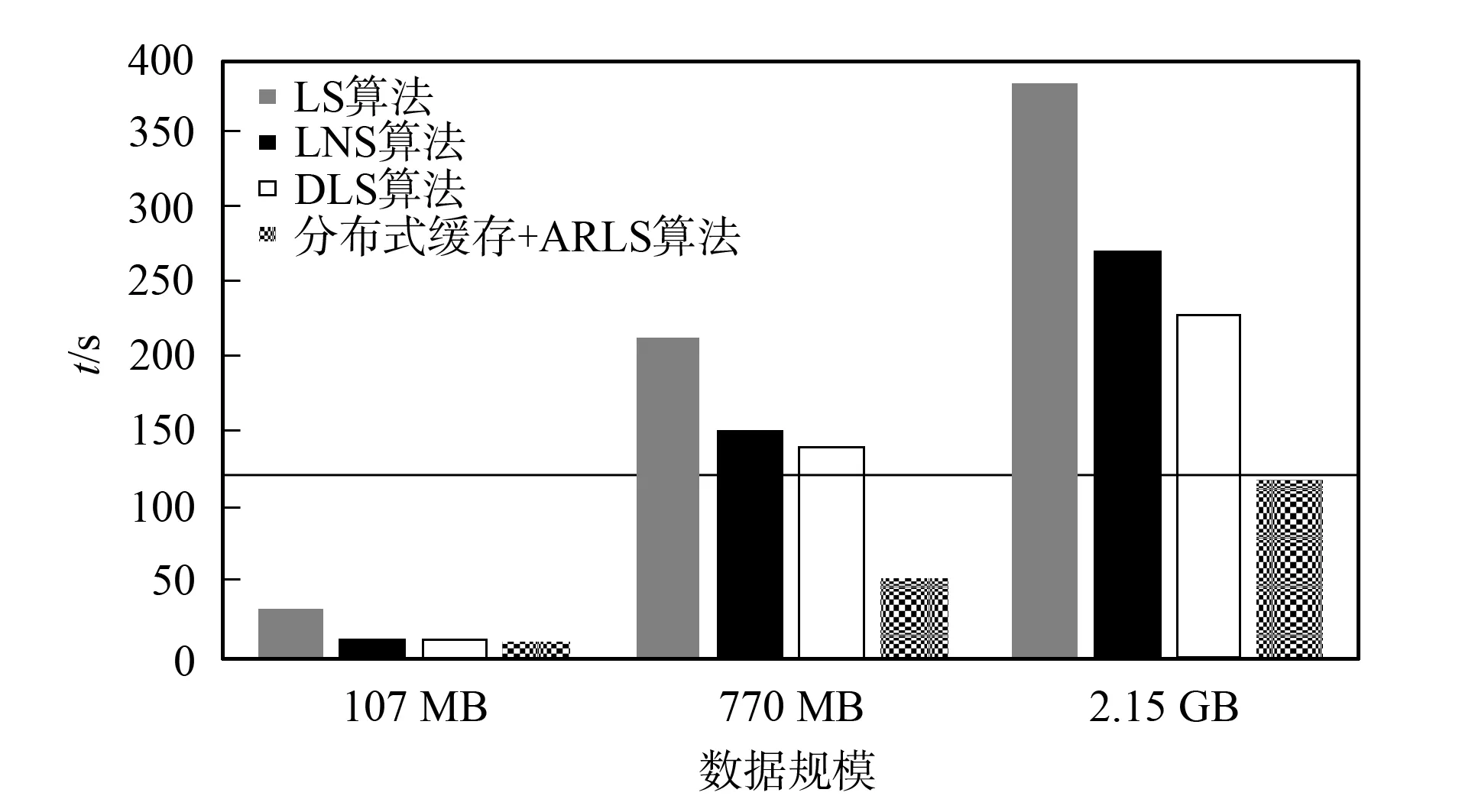
图8 平台整体性能分析Fig.8 Analysis of overall performance of platform
综上所述, 本文提出的分布式数据缓存技术实现了地学数据可视化平台地震数据存储与数据可视化的分离, 将大规模地震数据集中存储在云数据中心, 以可容忍的网络通信开销为代价极大减少了客户端的物理资源消耗. 基于Boost实现的数据通路优化了网络传输效率, ARLS访问预测算法的平均准确率达91.3%, 充分利用了可视化过程中服务器的空闲时间, 使云端缓存命中率平均达95.61%. 服务端缓存与客户端缓存提高了数据加载效率, 使地学数据可视化平台整体性能大幅度提高, 用户可在有限的数据加载时间内获得更好的地震数据可视化效果, 能有效支持对远程地震数据的快速可视化.
