中国人口预测结果检验及影响因素比较
2018-10-09石人炳
石人炳,陈 宁
(华中科技大学 社会学院,武汉 430074)
0 引言
人口预测是依据人口发展内在规律对未来人口图像的描绘。在计划生育政策酝酿之初,人口预测就致力于为有计划的人口控制提供科学依据[1]。发展至今,人口预测不仅应用于人口领域,在社会保障、教育以及城市规划等方面都被广泛运用。这一方面说明人口预测在社会经济决策获取最优方案中有着重要作用;另一方面,这对人口预测结果的精度也提出了更高的要求。因为预测精度不仅关系到对未来人口态势的科学研判,也关系到对经济、社会可持续发展的合理规划。
过去的二三十年里,各类机构和学者们进行了大量的人口预测研究。根据研究目标判断以往研究主要集中在两个方面:一是专门预测未来的人口数量趋势和结构变动,二是考察人口变动对经济、社会各领域的影响;同时过往研究也呈现出两个明显的特征:一是“重结果预测,轻结果检验”,二是“重未来描述,轻过往总结”。可以说人们往往只关注人口预测的结果,而结合人口发展实际对过往人口预测结果的精度进行检验的研究却往往被学界所忽视。其实,过往的人口预测研究中,不同学者和机构对预测过程的处理存在很大的差异,而且呈现出的预测数字之间也是矛盾重重。
那么过往人口预测结果精度究竟如何?哪些因素影响了预测结果的精度?从应用价值上来讲,如果人口预测结果的精度得不到有效保证,对相关决策所起到的作用将不是参考而是误导;从学术研究角度来讲,当前学术界尚没有学者做这项工作,而通过对人口预测过程进行回顾分析,将对推进人口预测研究具有一定的理论价值。基于此,从学术的严谨性角度出发,对过往人口预测结果的精度进行梳理、检验,有效考察人口预测结果出现偏差的缘由,进而为我国今后的人口预测工作提供借鉴,无疑具有重要的理论和现实意义。
1 预测结果检验
过往人口预测研究数量众多,为确保文献选择的权威性,本文设定如下挑选原则:一是选择有影响的学者、机构发表的人口预测类文章或专著;二是为能够和已经发生的人口统计结果进行比较,将选择的预测研究年份限定在2010年以前;三是选择全国性、中长期和数量型预测为主的研究。此外,鉴于预测研究一般将中方案设为最优方案,故呈现的预测结果为中方案结果。同时,从中按照1980年代、1990年代、2000年代三个时期,抽取8篇[2-9]具有代表性的成果进行深度研究,本文称之为研究样本。为了衡量研究样本的预测效果,本文构造“误差率”这一指标来测量。鉴于2020年及以后的人口事件尚未发生,将结果检验分成两个部分:一是用“绝对误差率”测量2015年以前的预测结果与实际统计结果的差异;二是用“相对误差率”测量2015年以后各类预测结果之间的差异。
绝对误差率:用实际统计结果衡量绝对误差率。即同一时点预测结果与实际统计结果之差,然后和实际统计结果之比。用P表示人口实际统计结果,用V表示人口预测结果,用e表示绝对误差率。用公式可以表示为:
相对误差率:为便于计算,本文选择用样本预测结果的平均值代替2020年及以后的实际统计结果,来衡量相对误差率,用e′来表示。计算方法同上。由于绝对误差率和相对误差率的分母并不一致,所以二者并不具有比较意义,只能反映二者所在时期的结果差异。
表1提供了1990—2015年部分年度《中国统计年鉴》中公布的我国人口发展实际数量,以及人口预测的结果比较和根据上述公式所计算的绝对误差率和相对误差率。
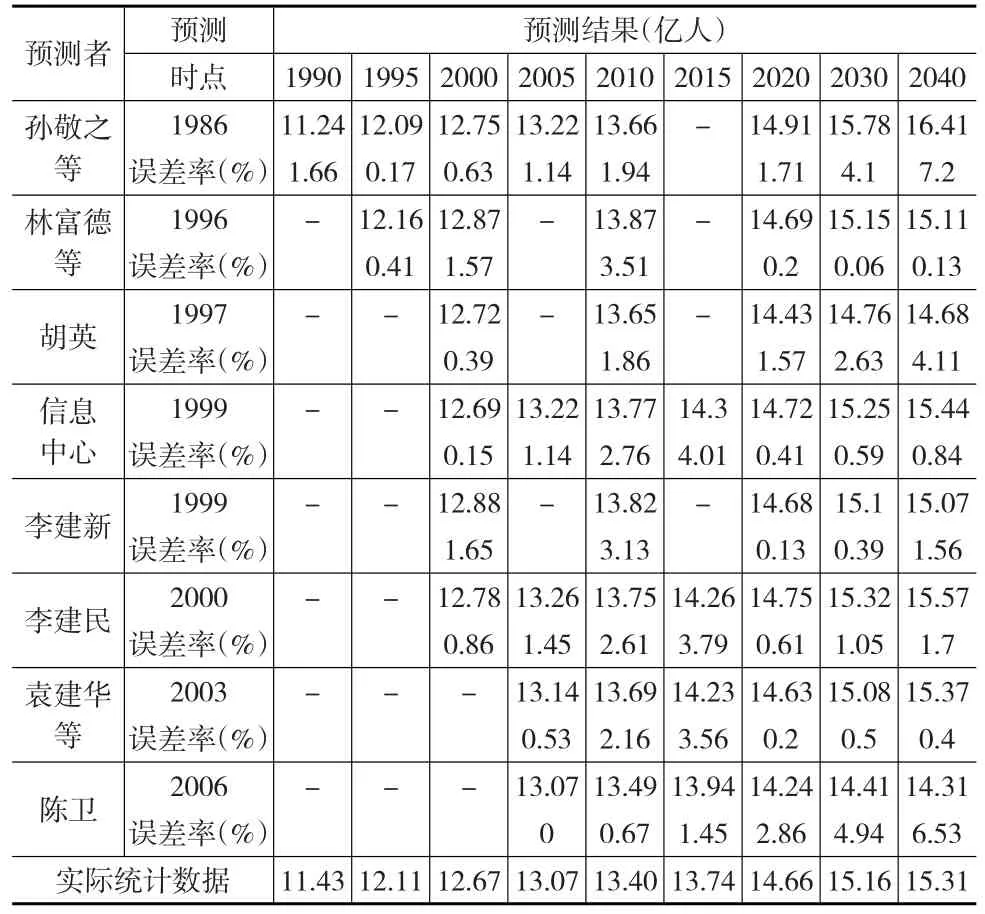
表1 不同来源的人口预测数量与人口实际统计数量以及误差率比较
从结果比较来看,可以发现:(1)不同来源的人口预测数量与人口实际统计数量存在差异,有的预测结果贴近实际统计结果,而有的预测结果则与统计结果相差较大;(2)不同人口预测结果之间存在明显差异,而且有的预测结果之间的绝对数量相差很大;(3)人口预测结果基本都大于实际统计结果,而且随着时间推移二者差距越大。
从误差率比较来看,不难看出如下特征:(1)人口预测结果精度存在一定的差异,有的预测绝对误差率较小,而有的预测绝对误差率则相对较大;(2)人口预测结果的绝对误差率基本都随着时间推移而逐渐扩大;(3)2020年及以后人口预测结果的相对误差率存在明显差异。
通过检验,发现针对同一个预测总体(中国),并不是所有预测都贴近人口发展实际。同时,不同预测结果之间也存在很大差异。那么是什么原因造成这些现象呢?理论上而言,在人口预测过程中,主要面临的三大难题就是基础数据是否完备、参数设定是否符合规律预测以及模型选择是否恰当。这三者是直接影响人口预测结果是否符合客观实际的关键因素。本文将围绕影响人口预测结果精度的这几大关键要素作进一步分析。
2 基础数据的使用与问题
基础数据是人口预测的基础,其质量的高低直接影响到预测的精度。现有经常被使用的数据包括人口普查数据、1%人口抽样调查数据、统计年鉴数据等。在人口预测中,对基础数据的处理经常存在一定的差异(见表2)。可见,对“三普”和“四普”数据,由于自身漏报率较低,学者们在使用时基本没有调整。而对“五普”数据,由于存在较高的漏报率,学者们在使用时有的则会进行评估和调整,当然也有学者直接使用。

表2 不同人口预测中基础数据的来源、处理以及部分年份结果比较
从表2可以看到基础数据不同,预测结果存在明显差异,即使同一基础数据所得到的预测结果也存在一定的差异。对于基础数据的使用与处理,存在两个方面的问题:
第一,漏报人口的总量与年龄、性别分布问题。国家统计局公布的普查数据以及抽样调查数据均有一定的漏报率,但并没有公布漏报人口的性别、年龄以及城乡分布,尤其是出生人口和低龄人口漏报的数量和孩次分布情况。对于人口预测而言,低龄人口和育龄妇女的数据质量不仅关系到时期生育水平的高低,还关系到育龄妇女的生育基数、生育结构和生育完成情况。针对出生漏报问题,学者们采取队列法、插补法、存活分析法等人口分析方法对漏报人口进行了估算、回填[10-12],但由于操作方法、认识思路不同,学界对漏报人口的总量与分布问题的处理仍存在较大差异。
第二,基础数据的统计口径、评估与修正标准问题。首先,由于各部门统计口径的差异,致使不同统计结果存在明显的差异。例如对一个地区人口数量和结构有着重大影响的流动人口的统计,由于界定标准、统计方式的不同,不同部门、不同时间下的统计就会有不同的结果。其次,即使是同一数据,具体人口预测的操作中有的学者、部门进行调整使用,而有的学者则是直接使用。即使在预测中都对同一基础数据进行评估调整,但是由于调整的方法不同也导致录入预测模型的基础数据不同。这样一方面导致预测结果的多样性,另一方面预测结果之间的可比性也大打折扣。
3 人口预测参数的选择与特征
对于封闭人口系统参数的选择主要包括反映生育水平的总和生育率和反映死亡水平的平均预期寿命。
3.1 生育水平
基于人口发展规律和统计数据可以发现,如果生育水平被过高估计,预测的人口规模将高于人口统计规模。因为当期的出生人口规模不仅决定了当时的人口规模增量,还决定了这一队列人口步入婚育期后的未来人口规模增量。那么,众多人口预测操作中生育水平是如何设定的?通过对生育水平的设定比较的分析(见下页表3),可以发现以下几个特征:

表3 不同预测中生育水平的设定
第一,对总和生育率的设定基本处于1.7~2.2之间。1990—2000年间对总和生育率的设定处于1.8~2.2之间;2000—2010年间基本处于1.8~2.0之间;2010年以后对生育水平的设定方向比较分化,一类是基本维持1.8的水平,一类是呈持续下降,另一种是出现回升。这种现象一方面可能是导致各类预测结果普遍高于人口实际统计结果的原因之一,另一方面也可能是导致各类预测结果出现明显差异的原因之一。
第二,生育水平的设定存在明显的差异。由于上述研究的时点存在不同,本文取2000年、2010年、2030年这一各个研究都覆盖的时间进行比较。可以发现2000年时,总和生育率的最高设定水平为1.85,最低水平为1.68,相差约0.17;2010年时最高水平为2.0,最低水平为1.76左右,相差0.24;2030年时最高水平为2.1,最低水平为1.74,相差约0.36。预测后期,设定的差异愈大,一定程度上导致后期预测结果差异也愈大。
生育水平是影响人口预测结果的关键要素,从结果检验来看,过往人口预测结果基本都高于实际统计结果,而且随着时间的推移,高出的幅度不断增大。那么是不是因为过往预测研究对生育水平的设定都偏高了呢?同样可以通过对比以往生育水平的统计结果进行判断。国家统计局根据“五普”、2005年“小普查”和“六普”调查数据得出的我国总和生育率分别为1.22、1.33和1.18。部分学者对这一数据存在质疑,认为由于瞒报、漏报等导致结果极度偏低[13-16]。
尽管学界对总和生育率究竟是多少存在认识上的差异,但是通过各类数据的比对和印证,可以得出两个方面的判断:一方面,各类人口预测中短期内亦或说2015年以前设定的生育水平下所得到的人口预测结果与实际统计结果虽然存在一定的误差,但是大部分预测结果其实比较贴近实际统计结果,这可以从另一个角度反应出国家统计局官方公布的生育水平是极度偏低的;另一方面,通过比较可以发现,过往人口预测研究对生育水平的判断是偏高的。20世纪90年代以来我国育龄妇女的生育水平下降非常快,超出了学者们的估计。因为以上研究对总和生育率的设定不仅远远高于官方公布的统计水平,而且也高于学者们根据历次普查以及统计调查数据所推算的生育水平。这一定程度上反应了既往研究中对生育水平的设定偏高,也一定程度上导致了对人口总数的预测结果高于实际人口统计结果。
3.2 死亡水平
平均预期寿命是反映死亡水平的重要指标,死亡是影响人口规模变动的重要因素,死亡水平的高低也就决定了人口减少的多寡。如果对平均预期寿命的设定偏高,相应的对人口死亡率的判断则会偏低,则一定程度上会导致人口预测结果出现偏高。
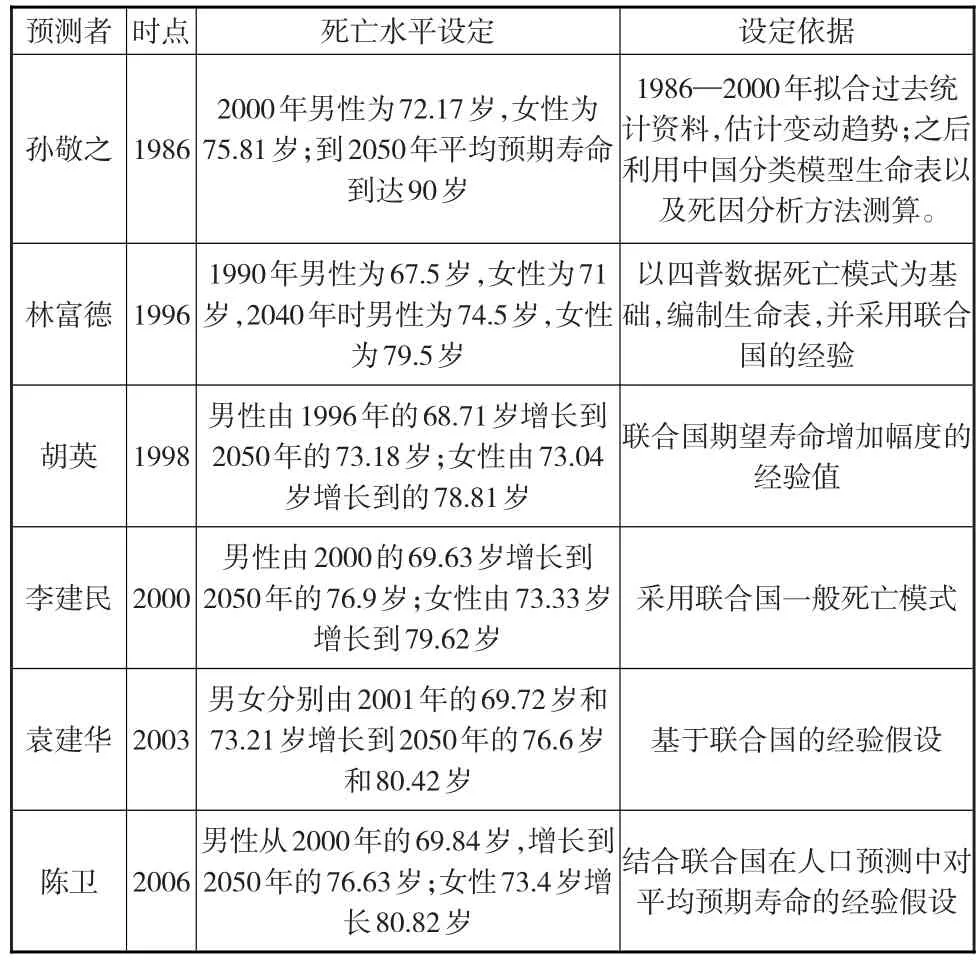
表4 不同预测中死亡水平的设定及依据
通过表4的对比,可以发现对死亡水平的设定以及设定依据存在以下几点特征:
第一,对平均预期寿命的判断存在一定的时期差异。20世纪80年代的人口预测对平均预期寿命的设定比较乐观。如孙文认为到2050年,平均预期寿命有可能达到90岁;90年代的预测基本认为到21世纪中叶男性平均预期寿命基本能够达到74岁左右,女性基本达到79岁;当然20世纪90年代和2000年以后的平均预期寿命的设定虽然存在一定的差距,但是差别不大,对平均预期寿命整体趋势的把握具有一定的相似性。2000年以后的预测认为到21世纪中叶男性平均预期寿命基本在76岁左右,女性基本在80岁左右。
第二,不同的设定依据对平均预期寿命的判断具有重要的影响。表4主要反映了两种判断依据,一是运用统计方法进行判断,二是运用联合国经验数据进行判断。统计方法依靠趋势分析和死因分析等手段对未来趋势进行预测,得出的结果并不一定可靠。一方面根据各国人口转变经验,平均预期寿命在达到一定水平后,将出现减速递增的趋势,另一方面随着时代的发展,很多未知的疾病导致的高死亡率并不在当时死因分析的考虑范围之内。按照趋势分析和死因分析往往会使得推算结果大幅偏离实际结果。而根据经验分析,由于人口规律的作用,对平均预期寿命趋势的大体判断相对具有一定的稳定性。
4 人口预测模型的比较与问题
建立人口预测模型的基本原则是能够把握人口过程及其规律,而不仅是数据和模型的简单拼凑。面对众多预测模型,如何找到适用于一个国家人口发展特点的模型至关重要。本文通过对比来分析这些人口预测模型的特点(见表5),对人口预测模型之间的共性与差异进行考察。
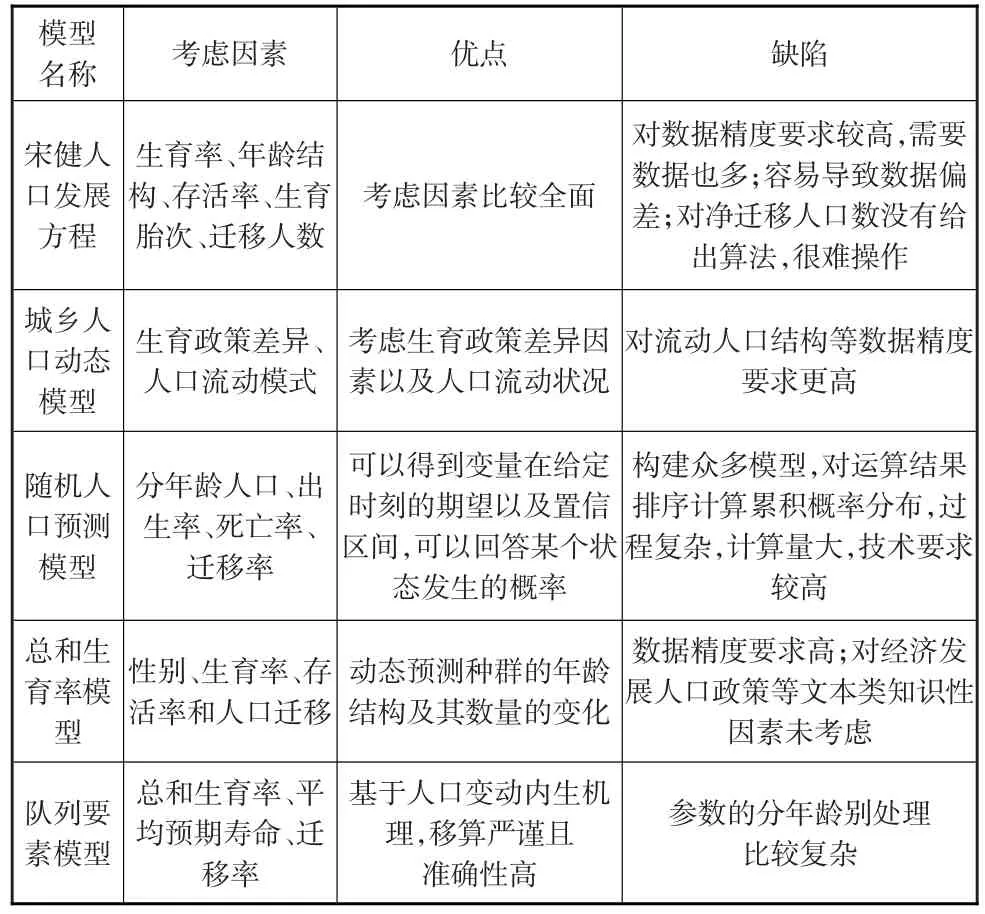
表5 样本预测模型的对比分析
通过对以上模型的对比分析,针对人口预测模型的使用可以总结出以下特点和问题:
第一,对于以统计分析为基础的人口预测模型,由于考虑因素相对较少,将观测数据带入公式即可,发展至今被广泛应用。当然这类预测模型对数据精度、数据质量要求较高,某一数据出现的偏差会对整个结果产生较大的影响;同时对于影响人口再生产的经济性因素和政策性因素没有加以考虑。如果预测地区的人口统计数据不够全面、准确或者人口变动受外生经济和政策等变量影响较大时,运用这类模型进行人口预测往往会产生一定的误差。此外,从预测期限分析,这类模型短、中、长期预测均可,但短期预测可以取得较好的精度。
第二,对于我国学者自主构建的人口预测模型,人口发展方程由于对数据要求较高,计算庞杂,1990年代以后应用相对较少。而由于我国当前人口流动的鲜明特征,城-乡人口动态模型等被广泛使用。这些人口预测方法是学者们利用传统人口预测方法,针对我国计划生育政策实际以及特殊的流动人口迁移模式进行了适当的优化和改进所得到。同时中短期预测精度较高,而长期预测则误差较大。因为结合表1可知,到2040年研究样本的相对误差率最大为7.2%,最小仅为0.13%。
5 结论
本文以人口实际统计结果为依据,对过往权威人口预测结果精度进行检验,同时通过对影响人口预测结果精度的三大要素进行比较分析,得出了以下结论:第一,过往人口预测结果呈现出多样性,从中短期来看这些研究对人口趋势的预测基本符合人口实际发展趋势,但从长期来看这些研究对人口总量的变动预测存在较大差异。第二,过往人口预测结果普遍高于人口实际统计结果,随着时间推移,高出幅度也越来越大。造成各类预测结果偏高的主要原因是对生育水平的设定偏高。一方面生育水平的设定高于实际统计水平以及学者们结合统计数据修正得到的生育水平;另一方面,死亡水平的设定高于实际死亡水平的变动趋势,又抵消了一部分因死亡水平设定相对过高所造成的预测结果偏高;第三,过往人口预测结果精度随时间推移不断下降,预测结果的绝对误差率和相对误差率都随时间推移而不断增加;第四,不同预测结果之间呈现出的差异,主要是由于对基础数据的处理和评估缺乏统一的标准,同时对总和生育率的判断缺乏共识,而不同的预测模型之间的运算过程、考虑因素、数据处理之间的差异也一定程度上造成预测结果之间出现差异。
