异步连接操作的峰值功率建模
2018-10-08,,
, ,
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
计算机能效是当前计算机领域研究的热点议题之一.随着云计算与大数据时代的到来,数据中心的能效问题更加凸显,大型数据中心耗费一座城市的电能.据统计,数据中心的电力消耗以每年15%~20%的速度在增长,大规模数据中心的能源成本快速攀升并迅速超过硬件本身的成本.数据中心的能耗成为日益关切的问题,能耗管理成为现代数据中心重要的度量与设计标准,已开展了大量研究工作[1-2].在降低能耗方面,古辉等[3]在构建停车场无线传感网络过程中,基于某个特定的场景,提出了基于LEACH的簇树网络的路由算法改进方法,使节点能耗有很大的下降.郝平等[4]在自主开发的能源监测系统上提出了利用基于数据仓库的OLAP分析和改进的分层挖掘Apriori算法,并以此建设成一套区域能耗预警系统,从而提高区域能耗监察管理和预警能力.峰值功率是数据中心的一个重要因素.在数据中心,冷却与电力供应是根据峰值功率来设计的,降低峰值功率可以缓解这方面的限制.Felter等[5]通过单独估算各个耗能部件的峰值功率来估算系统整体峰值功率,根据对服务器部件前一区间的活动检测来预测下一区间活动情况,而由此根据事先分配的功率来确定处理器、内存的节流阈值,限制各部件的活动来进行功率调节.Meisner等[6]为解决数据中心的功率封顶开展了数据中心峰值功率建模,功率封顶是数据中心对服务器设置功率消耗上限的技术,通过CPU利用率与转换模式功率供给单元间的关系,建立数据中心的峰值功率估算模型.但在数据库系统应用中,各个部件不会同时达到峰值点,系统供能超额配置.Chen 等[7-8]分别从进程以及函数级对功率进行了评估;杨良怀等[9]考察了CPU、内存、外存和CPU执行频率等因素,对数据库服务器系统整机系统进行功率建模,构建其软功率计,考察的是实时功率.由于峰值功率是并发操作最大聚集和,在查询执行中需要捕捉猝发或短期功率现象,评估峰值功率需要获取CPU瞬时利用率,而CPU瞬时利用率在操作执行过程中才能获取,因此这项指标不能用于预测峰值功率.
数据库系统是数据中心的核心软件之一,对其峰值功率的感知与控制具有重要的意义.获取数据库系统查询操作的峰值功率是通过实际测量获取峰值和通过软件评估的两种方式预测峰值.对于功率感知查询优化器,需要在查询执行前选择具有合适峰值功率的查询计划,无法事先测量,通过软件评估的方式预测峰值功率才是可行方案.Kunjir等[10]剖析了3个商用数据库系统的峰值功率行为,查询处理中峰值功率有时相当大,可以覆盖计算平台整个动态范围,其实验结果表明峰值功率的行为与相应的平均功率行为大为不同,需要对这两个指标分别进行研究;同一查询,不同商用数据库系统峰值功率差别很大,说明对峰值功率的控制是数据库系统可一进行决策的参数.Yang等[11]在串行操作方式下针对查询操作中的连接算法,在不同频率下建立了峰值功率评估模型,并用4种连接算法进行了验证,取得了一定的准确性.数据库系统中为改善连接算法的性能通常是基于异步I/O方式实现的,如何解决异步I/O连接算法的峰值功率建模问题成为热点.
1 模型建立
查询处理器需要在系统运行前知道操作可能产生的功耗.峰值功率中需要对并行操作显式处理,峰值功率是并发操作最大聚集和,运行时CPU利用率是一个密切相关指标.但CPU利用率是运行时指标,无法用于峰值功率建模,需要找到一个类似CPU利用率的综合指标来估算峰值功率,即使用CPU密集度指标来建立峰值功率估算模型.
1.1 CPU密集度
Yang等[11-12]都引入了CPU密集度的概念,区别在于后者所考虑的负载特征中,CPU运行状态只包括CPU计算密集型与内存访问密集型两种,而前者把操作算法运行中,I/O访问密集型也考虑进CPU的状态中.CPU的运行状态可细分为4种:CPU运算、访问内存、访问外存(I/O)和空闲.前3种统称为活动态.从功率评估的角度来看,CPU在不同状态所消耗功率不同,若在不同状态的时间能够进行估算,则可以近似计算计算相应算法的功率消耗.对于数据库连接操作,通过功耗仪测量实际运行的功率可知,CPU在运算和访问内存这2种状态下功率基本一致,而与IO访问时的功率差别较大,其原因是CPU为系统主要的耗能部件,前2种状态CPU的利用率较高,而访问外存对CPU的利用率较低,因此把CPU运算、访问内存这两种状态统称为CPU密集型.采用CPU密集度定义,即在单位时间(1 s)内CPU密集型时间所占比率(CPU密集型时间+I/O密集型时间=1 s),CPU密集度计算式为
(1)
式中:Bcpu为CPU密集度;tcpu为CPU密集型操作的时间;T为单位时间.计算CPU密集度的关键在于对tcpu的估算,而tcpu的估算与操作的负载特征相关.
在软硬件配置不变的情况下,算法的峰值功率产生阶段是不变的,连接算法的峰值功率产生在连接阶段.合理使用异步I/O可以减少CPU等待数据的阻塞时间,故使用异步I/O来实现的块嵌套循环连接(BNLJ)算法为例来说明峰值功率的估算.
1.2 BNLJ算法峰值阶段密集度计算
假设连接的两个关系表设为R表和S表.令|R|与|S|分别表示两个关系表的大小,且设|R|<|S|;磁盘I/O基本单位为数据块,|IB|表示输入缓存大小,即S表1次读入的数据块大小;|OB|表示输出缓存大小,即连接结果一次写出到磁盘的数据块大小;Rblk表示R表每次读入到缓存的大小;可用总缓存大小为M.
基于异步I/O方式实现的连接算法采用传统双缓存机制.输入缓存由两部分组成,分别用IB和IB'表示,它们的大小都用|IB|表示,其中IB区表示正在进行CPU密集型操作的缓存区,而IB'区表示正在读入元组的缓存区;同理,输出缓存也由两部分组成,分别用OB和OB'表示,它们的大小都用|OB|表示,其中OB区表示正在写入结果的缓存区,而OB'区表示正在将结果写出到磁盘的缓存区.在某些情况下,IB区和OB区分别也可以进行CPU密集型操作和写出操作,即当IB'区还在进行读入操作时,而IB区已完成CPU密集型操作,这时将会阻塞,IB区可同时进行读入操作;同理,当OB'区还在进行写出操作时,而OB区已完成结果的写入操作,这时也会阻塞,OB区可同时进行写出操作.
单位时间内tcpu的长短与读和写数据块的时间密切相关,因此需要估算读、写操作的耗时.设磁盘的输入、输出速率分别为γi,γo;读入|IB|大小的数据块所需的时间Tr=|IB|/γi,写出结果的时间Tw=|OB|/γo.其次,需要估算CPU密集型操作的耗时.
对于BNLJ算法,最理想的状态是两个关系都可以完全读入到内存中并进行连接操作,这时其性能可以达到最高.但由于内存有限,小表R往往不能一次性读入到可用内存中,需要通过分割成多个数据块多次读入内存来进行.基于异步I/O实现的BNLJ算法基本流程是:先确定输入缓存大小|IB|和输出缓存大小|OB|,将R表的一部分读入缓存中并构建其哈希表;然后将S表循环读入输入缓存IB和IB'区进行连接操作,连接结果放入输出缓存OB和OB'区,最后输出到磁盘中;遍历完S表后(内层循环结束),清理原先读入的一部分R表并读入新的一部分,重复以上操作,直至将小表R完全遍历(外层循环结束).
元组在连续的连接过程中不访问外存,是CPU密集型操作;但在连接过程中,元组连接速度很快,且输入输出缓存大小有限,在所考察的单位时间T内可能会发生I/O,即从磁盘中读入S表/R表或写出连接结果到磁盘,而这两种操作皆为IO密集型操作,所以tcpu为单位时间内连接元组的时间长度.由于需要估算CPU密集型操作的耗时,故设连接|IB|大小的数据块所需的时间设为Tij,连接结果填充满|OB|大小的输出缓存所需的连接时间设为Toj.
估算BNLJ的连接时间tcpu时,笔者采用单位时间内连接元组数N与平均每对元组连接用时的乘积来计算.元组在连接时分两种情况,一种是元组探测后找到可连接元组,并进行连接;另一种是元组探测后发现没有匹配的连接对象,直接丢弃.因此,估算连接时间时需要对这两种操作进行区分.假设输入缓存IB或IB'中可与Rblk元组进行连接概率为P,其估计可以根据关系R与S在连接属性Y上相等的概率为1/max(V(R,Y),V(S,Y))计算,其中V(*,Y)表示某关系在属性Y取相异值的个数,则输入缓存IB或IB'连接所需要的时间计算式为
Tjoin(P,Njoin)=NblkR·Njoin·Tprobe+
P·Njoin·Tjoin
(2)
式中:NblkR为Rblk包含的元组数;Njoin为单位时间里连接S表的元组数;Tprobe,Tjoin分别为探测和连接.
式(2)中直接确定连接总元组数Njoin比较困难,在每次读入输入缓存后,通常连接过程会遇到两种情况:1) 连接结果未填满输出缓存区,而输入缓存区的元组已经完成连接,必须从磁盘读数据至输入缓存;2) 连接结果填满输出缓存区,必须对其进行输出.由于连接过程可能是非连续的,为了计算Njoin则必须重现连接的逻辑过程,对整个单位时间里的连接元组数量进行累计,为此需设计相应算法进行处理.
在提出算法之前,还需要估算Tij和Toj两个参数.评估这两个参数需要分别确定|IB|大小数据块中包含的元组数量NblkS和产生|OB|大小的连接结果所需连接元组条数NS-needed.假设元组大小均匀分布,R表与S表的平均元组大小分别表示为|tR|与|tS|,则NblkR与NblkS分别为Rblk/|tR|,|IB|/|tS|;由于连接是将两条元组进行拼接,对应产生的结果大小可表示为|tR|+|tS|,再结合连接概率为P,则NS-needed计算式为
(3)
由式(2,3)可得:Tij=Tjoin(P,NblkS),Toj=Tjoin(P,NS-needed).
1.3 CPU密集度估算方法
按照CPU密集度的定义,峰值阶段从不同的起始位置取单位时间间隔得到的CPU密集型操作时间长短不同,即CPU密集度不一样,而功率测量值是单位时间的积分值.故从理论上来说,峰值功率对应操作执行过程中CPU密集度最大点,对峰值功率对应的CPU密集度的估算需要选择使CPU密集度最大的起始点.
评估连接算法的峰值功率就是找出算法执行过程中CPU密集度最大的单位时间段.对此,有以下命题:
命题在无I/O阻塞情况下,形成最大CPU密集度的单位时间段起始点在输入缓存区IB读取完成,且IB'读取完成的时刻不晚于IB连接完成的时刻.
证明首先证明起始点是在输入缓存区IB读取完成时.假设起始点不在输入缓存区IB读取完成时,即当前IB未读取完数据,那么单位时间内必定有段时间是要等待其完成读入,CPU密集度无法达到最大,故起始点是在输入缓存区IB读取完成时.其次证明由于IB'读取完成的时刻不晚于IB连接完成的时刻.由于使用双缓存形式来实现基于异步I/O的BNLJ连接算法,故在整个连接过程中,IB和IB'会不断重复地进行“读取数据-连接”循环操作.当IB区完成连接时,若IB'区未完成读入,则会阻塞一段时间,在单位采样时间内,将会有段时间用于I/O操作.对于IB'而言,就相当于其计算密集度的起始时间前移.因此,IB'读取完成的时刻不晚于IB连接完成的时刻.综合上述情况,可得出在无I/O阻塞情况下,形成最大CPU密集度的单位时间段起始点在输入缓存区IB读取完成,且IB'读取完成的时刻不晚于IB连接完成的时刻这一结论.
CPU密集度估算需用到几个变量:tij为完成IB未连接部分预计需要的连接时间,根据前述命题,最大CPU密集度发生在输入缓存IB读取完成后,因此tij初始值赋为Tij;toj为填满输出缓存OB剩余空间预计需要的连接时间,由于输出缓存初始为空,因此toj初始值赋为Toj;tir为从磁盘读取数据填满IB剩余空间预计所需的读取时间,同理根据最大CPU密集度发生在输入缓存读取完成后,tir初始值赋为0;tow为完成OB未写出部分预计所需的写出时间,由于一开始输出缓冲区为空,故tow初始值赋为0;tr为从磁盘读取数据填满IB'剩余部分所需的读取时间,根据命题IB与IB'一开始可以同时异步读取完成,故tr初始值赋为0;tw为完成OB'未写出部分所需的写出时间,由于一开始输出缓冲区为空,故tw初始值赋为0.由于CPU密集度定义为在单位时间(1 s)内CPU密集型操作时间所占的比率,故引入表示剩余运行时间的变量tleft,初值赋为1 s.
得到上述参数后,可以进行模拟BNLJ连接算法峰值功率产生阶段的执行过程.算法在连接阶段的基本流程为:初始状态时IB和IB'已完成读取,可进行连接操作;OB和OB'为空,可进行连接结果的写入操作.IB进行连接时,将其连接结果写入OB,使用异步I/O的方式实现算法,故与此同时可进行IB'的读入与OB'的写出,要分别更新两者的时间tr和tw.当IB的元组完成连接时,若IB'已完成读入,则交换IB与IB',继续进行连接;否则,阻塞.同理,当OB被连接结果填满时,若OB'已完成写出,即已可用,则交换OB与OB',继续进行连接;否则,阻塞.
连接过程中将会出现3种阻塞情况:
1) 当IB完成连接操作,而IB'还未完成读取操作,其阻塞时间取决于IB'的tr时间;
2) 当OB完成连接结果的写入操作,而OB'还未完成写出操作,其阻塞时间取决于OB'的tw时间;
3) 当上述2种情况同时存在,即当IB'未完成读取且OB'未完成写出造成阻塞,其阻塞时间为tr和tw两者中的较长者.阻塞时,只进行I/O操作.
给定参数上述参数后,可对tcpu进行估算.CPU密集度最大的单位时间段的计算算法,见算法ComputeAIO-tcpu.
算法1ComputeAIO-tcpu
输入:|IB|,|OB|;输出:单位时间中CPU密集型操作的时间tcpu.
1) 初始化CPU占用时间tcpu←0,单位时间1 s中所剩余时间tleft←1,完成连接输入缓存IB中元组所需时间tij←Tij,填满输出缓存OB所需连接时间toj←Toj,读取IB'未读入部分所需时间tr←0,读取IB未读入部分所需时间tir←0,写出OB'未写出部分所需时间tw←0,以及写出OB区未写出部分所需时间tow←0.
2) 判断tleft是否大于0,若是则转至步骤3),否则终止并输出tcpu.
3) 若剩余时间tleft足够连接完IB,转至步骤4),否则转至步骤8).
4) 若IB连接的结果不够填满OB,则转至步骤7),否则转至步骤5).
5) 若IB连接的结果多于填满OB所需的量,则将IB的部分元组进行连接(tij←tij-toj),与此同时,可异步进行IB'的读入(Update(tr,toj))与OB'的写出(Update(tw,toj)),直到连接结果填满OB为止(tow←Tw),更新tcpu←tcpu+toj和tleft←tleft-toj,获取可用的输出缓存(getEmptyOB())并记为OB,重复步骤2),否则转至步骤6).
6) 若IB连接的结果刚好填满OB,更新tcpu←tcpu+toj和tleft←tleft-toj,与此同时,可异步进行IB'的读入(Update(tr,toj))与OB'的写出(Update(tw,toj)),直到IB连接完成并且连接结果填满OB为止(tir←Tr,tow←Tw).若IB'的未读入部分所需时间比OB'未写出部分所需时间短,即阻塞等待OB'完成写出,先获取可用的输入缓存(getReadyIB())并记为IB,再获取可用的输出缓存(getEmptyOB())并记为OB;否则,阻塞等待IB'完成读入,先获取可用输出缓存并记为OB,再取可用的输入缓存并记为IB,重复步骤2).
7) 连接IB的所有剩余元组(toj←toj-tij),与此同时,可异步进行IB'的读入(Update(tr,tij))与OB'的写出(Update(tw,tij)),直到完成IB连接(tir←tr),更新tleft←tleft-tij和tcpu←tcpu+tij,获取可用的输入缓存(getReadyIB())并记为IB,重复步骤2).
8) 若剩余时间tleft足够连接填满OB,则将IB剩余部分元组进行连接(tij←tij-toj),与此同时,可异步进行IB'的读入(Update(tr,toj))与OB'的写出(Update(tw,toj)),直到连接结果填满OB为止(tow←tw),更新tleft←tleft-toj和tcpu←tcpu+toj,获取可用的输出缓存(getEmptyOB())并记为OB,重复步骤2).否则转至步骤9).
9) 即剩余时间tleft不够连接完IB且不够连接填满OB,将IB的部分元组进行连接,连接结果写入OB,更新tcpu←tcpu+tleft,直到tleft←0.
算法2Update(t,tp)
输入:t,tp;输出:缓存区剩余读/写所需时间t.
1) 若tp小于等于缓存区剩余读/写所需时间t,则更新t←t-tp,否则转至步骤2).
2) 缓存区剩余读/写所需时间t←0.
算法3getReadyIB()
输入:tleft,tr,tir,tw,tow;输出:可用的输入缓存IB,tleft.
1) 判断IB'是否读取完整,若是则转至步骤5),否则转至步骤2).
2) 判断剩余时间tleft是否足够读取填满IB',若是则转至步骤3),否则转至步骤4).
3) 将元组读取填满IB',与此同时,可异步进行IB的读入(Update(tir,tr)),OB和OB'的写出(Update(tw,tr) , Update(tow,tr)),更新tleft←tleft-tr,转至步骤5).
4) 剩余时间tleft不够读取填满IB',则tleft←0,转至步骤5).
5)IB'已读取完整,则交换IB与IB',更新IB'未连接部分时间tr←tir,IB未连接部分时间tir←0.
算法4getEmptyOB()
输入:tleft,tr,tir,tw,tow;输出:可用的输出缓存OB,tleft.
1) 判断OB'是否完成写出,若是则转至步骤5),否则转至步骤2).
2) 判断剩余时间tleft是否足够写出OB',若是则转至步骤3),否则转至步骤4).
3) 将OB'数据进行写出,与此同时,可异步进行IB和IB'的读入(Update(tr,tw) , Update(tir,tw)),OB的写出(Update(tow,tw)),更新tleft←tleft-tw,转至步骤5).
4) 剩余时间tleft不够完成OB'写出,则tleft←0,转至步骤5).
5)OB'已完成写出,则交换OB与OB',更新OB'未写出部分时间tw←tow,OB未写出部分时间tow←0.
1.4 峰值模型建立
峰值功率对应于算法执行过程中CPU密集度最大点,在测量数据过程中峰值功率对应的实际起始点与理论起始点可能会略有偏差,考虑到测量的准确性,对测量进行多次重复,为了避免偏差较大的值干扰,取每组测量所得的众数作为测量结果.为产生不同CPU利用率的人工负载,对BNLJ算法进行改造,通过控制读入数据块(多次重复连接同一块数据),改变连接结果输出缓存的大小,从而产生不同大小的CPU密集度,据此进行CPU密集度与峰值功率关系的建模.
计算机空闲态功率是维持各个部件正常运行的基本功率,不同执行频率下对应的空闲态功率相同,这部分功率作为静态功率.为了更直观地表示算法执行状态对功率的影响,在构建功率模型时将去除这部分功率,即用测量得到的整机功率减去静态功率所得到的动态功率作为测量功率在图表中进行展示.测量人工负载在不同CPU密集度时在不同频率下(2.8,3.1,3.3 GHz)其峰值功率的大小,得到峰值功率与CPU密集度(Bcpu)关系如图1所示.
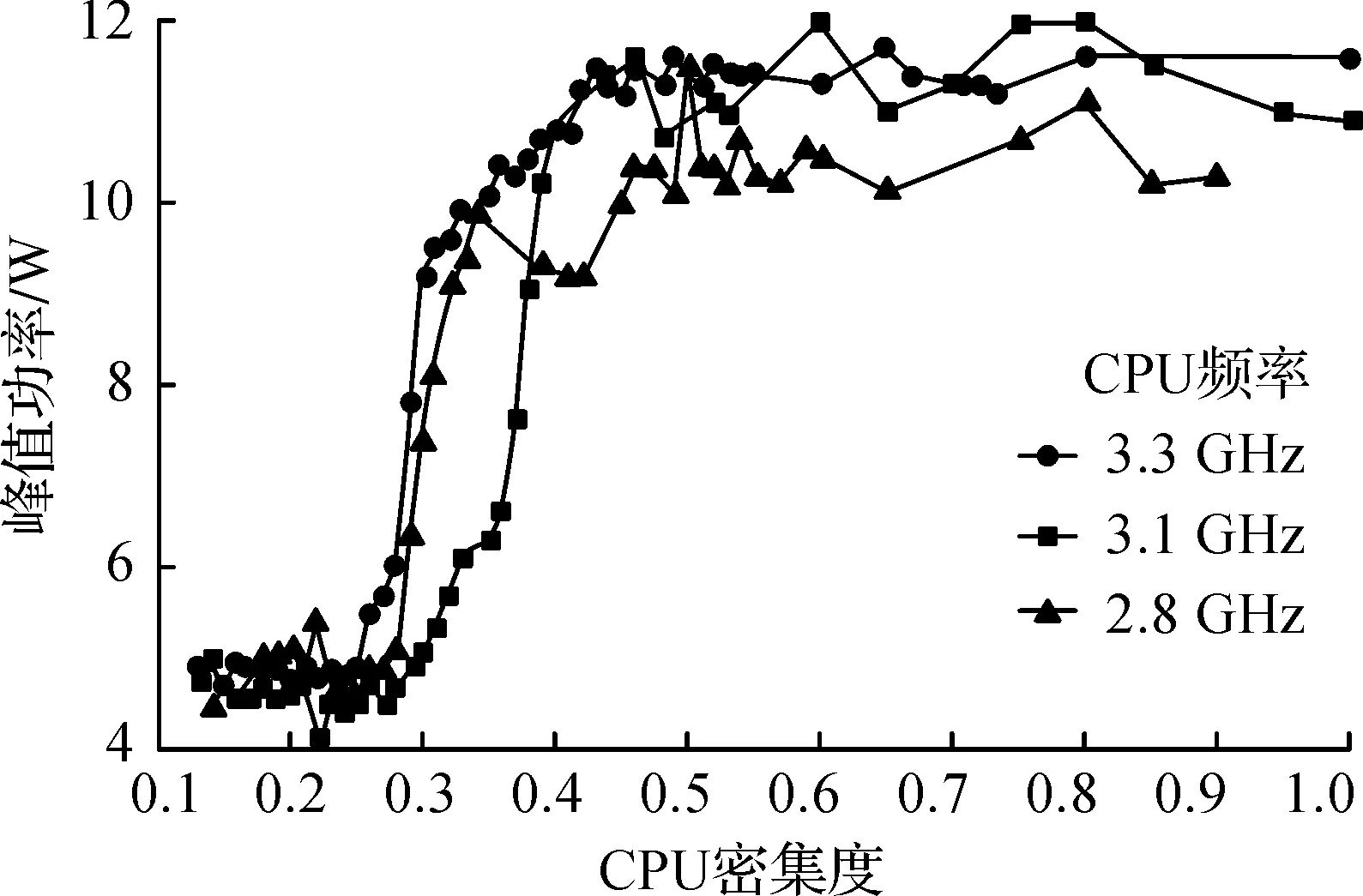
图1 不同频率下CPU密集度与峰值功率关系Fig.1 The relationship between CPU-boundedness and peak power with varying frequencies
由图1可知:不同频率下,峰值功率随CPU密集度变化呈现了3个阶段.CPU密集度在第1阶段时处于平稳状态,其原因是算法运行时必须要耗费一定的能量才能维持基本的运行,所以在这个阶段呈现平稳趋势;CPU密集度在第2阶段时处于较为明显的上升状态;CPU密集度在第3阶段时又处于平稳状态,其原因是CPU被不断请求操作,在机器耗能尚未瞬间降低时,而新的请求又到达,从而导致CPU一直处于高耗能状态.可见CPU密集度对峰值功率的影响只是在一定范围内呈现正相关的关系.为此,先针对CPU执行频率为3.3 GHz的情况对CPU密集度与峰值功率进行建模,使用建模工具Eureqa对获得的测量数据进行回归建模,拟合曲线时可以选取不同类型的运算和不同的拟合曲线,选取常数C,变量x,+,-,×,/,power函数和logistic函数.经过多种模型的尝试,选取模型为
P=4.69+6.58×logistic(45.8×Bcpu-13.6)
(4)
式(4)拟合的均方根误差RMSE(Root-mean-square error)为0.351,模型拟合CPU密集度与峰值功率关系如图2所示,CPU密集度取值范围为0.13~1.
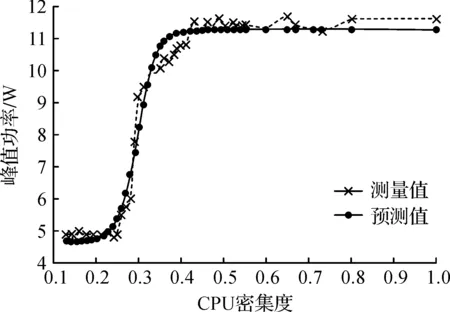
图2 不同模型的峰值功率预测Fig.2 Peak power prediction by different models
对不同频率下的CPU密集度与功率之间的关系仍然采用上述方法进行拟合,分别得到的标准误差RMSE均在0.37以内,整体模型用抽象形式表示,即在频率为f时峰值功率P与CPU密集度Bcpu之间的关系,即
Pf=α+β×logistic(γ×Bcpu-δ)
(5)
式中:α,β,γ,δ分别为常数参数,各频率下的常数参数值与RMSE值如表1所示.
表1不同频率下预测模型的参数值及RMSE值
Table1ParametersandRMSEofpredictmodelsunderdifferentCPUfrequency

f/GHzαβγδRMSE3.34.696.5845.813.60.3513.14.676.7555.320.40.3642.810.3-5.56-79.5-24.20.359
2 实验评价
为了评价第1节中预测模型的准确性,采用C++以及异步I/O机制实现了BNLJ算法,对BNLJ配置不同缓存,得到21组不同值的CPU密集度,用功耗仪测量不同CPU密集度时对应的峰值功率,比较峰值功率的实际值与预测值的相对误差来评价模型准确性.功耗仪采样率1 Hz.
2.1 实验环境
实验环境采用的硬件配置以及软件版本如表2所示.

表2 实验环境Table 2 Experimental environment
2.2 实验设计及结果
实验涉及到CPU密集度的计算,给定具体的参数|R|,|S|,|IB|,|OB|,Rblk后,针对实验环境需要确定1.1节中各个待定参数γi,γo,|tR|,|tS|,P,Tprobe,Tjoin.使用Iometer工具对硬盘进行测量,得出磁盘I/O速率在不同块大小下的速率统计表如表3所示.
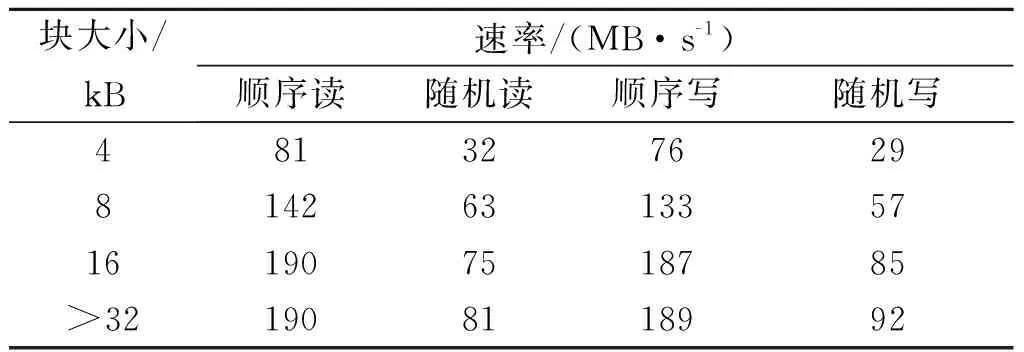
表3 磁盘I/O速率统计Table 3 The statistics of disk I/O rate
实验中连接的两张表采用TPC-H测试基准规模5产生的CUSTOMER(对应前面的R表,大小为129 MB,元组数NR=750 000)和ORDERS(对应前面的S表,大小为948 M,元组数NS=7500 000),作为连接算法的负载.经过估算R表与S表的平均元组大小|tR|与|tS|都均为170字节.
由数据表的分布特征可知max(V(R,Y),V(S,Y))为NR.对BNLJ算法而言,通常由于|R|>M而将R表分割多次读入,故每趟读入的Rblk<|R|,则S表与Rblk的连接概率P为NblkR/NR,其中Rblk大小为(M-2·|IB|-2·|OB|)/F.
通过连接探测或连接大量的元组对Tprobe和Tjoin估算,用测得的总时间除以连接的元组对数得到每对元组探测和连接排序的平均时间.笔者对2种频率下的数据进行测量,结果如表4所示.

表4 元组探测和连接时间统计Table 4 Time of probe and join
在获取以上参数后,便可以根据BNLJ运行时的软硬件配置环境计算得到21组不同的CPU密集度.利用21组输入输出缓存大小对BNLJ算法进行配置,测量对应的峰值功率,与模型预测值进行对比.两种频率的验证结果如图3所示,不同CPU频率下模型的平均相对误差如表5所示.

图3 不同频率下峰值功率实际值与预测值对比Fig.3 The comparison of real and predict values

f /GHz2.83.13.3平均相对误差/%3.753.943.27
由实验结果可知:各个算法在不同频率下的平均相对误差范围在4%以内,说明具有一定的准确性.
3 结 论
针对功率感知数据库系统中连接算法的峰值功率建模问题,使用了CPU密集度指标作为CPU功率的指示量,建立了基于异步I/O方式实现的连接算法的峰值功率预测模型,并对其进行了实验验证,结果表明:预测模型具有较好的准确性,其平均相对误差小于4%.数据库系统可采用此方法对查询操作各个算法的峰值功率进行评估,在连接算法执行之前只需给定数据库统计信息以及当时系统配置信息,便可以估算峰值功率产生阶段的CPU密集度来预测相应的峰值功率,可用于功率感知数据库系统的查询处理与优化.
