高校课程学习兴趣正负关联规则分析
2018-09-26梁宝华岳俊辉
梁宝华 岳俊辉
(1 巢湖学院,安徽 巢湖 238000)(2 合肥学院,安徽 合肥 230601)
1 引言
随着信息时代的发展,多数高校已采用网上教务管理系统管理日常教务工作。在教务工作中,会产生大量的教学数据。而这海量的信息中,隐藏着很多有益于培养高素质人才的知识,可以辅助高校制定合理的培养方案、探讨灵活多变的教学方法、多样实用的教材改革等,更好地培养综合能力强、专业素质高的应用型人才。如何挖掘并利用这些有价值的信息,是目前多数高校教务管理的新课题。
数据挖掘(Data Mining)是从海量的、模糊的、有干扰的、无规律的数据中提取隐藏一些用户未知的、有潜在价值的信息和知识的过程[1-2]。随着信息技术快速发展,各领域的行业数据量呈指数级增长,市场的发展、商业机密等重要信息都匿身其中,谁占有先机,谁就占有市场。所以,当务之急是如何从海量数据中快速发现商业行情,数据挖掘就是顺应这种形式下产生的一种数据处理技术。目前,数据挖掘技术已广泛应用于购物篮工程、银行业、保险业、各类辅助决策系统等[3-5]。关联规则是数据挖掘的研究热点之一,最早由 Agrawal、Imielinski和 Swami等人于 1993年首先提出了挖掘顾客交易数据库中项集间的关联规则问题[6]。关联规则发现已成功应用于购物篮工程,经典的案例是啤酒与尿不湿的故事。关联规则可以辅助管理人员规划货架排放,采取何种促销方式。若能够将关联规则挖掘技术应用于教学管理,势必会发现一些有利于提高教学管理效率的方式和手段。
2 关联规则概念
所谓关联规则,是指两个或两个以上变量的取值之间表现的规律性[7]。设关联规则挖掘对象集记为D,D中所包含的实例数为。每个交易的实例记为T,T是由若干个项item组成的集合,所有 T的 item 组成项集 I,则T⊆I。为了区分,每个事务赋予唯一的标识TID。若 X⊆I,且由称集合X为k项集。若X与交易实例T中某项相符,则T包含X。关联规则是一形如X⇒Y的蕴涵式,其中X⊂I,Y⊂I,且X∩Y=φ,一般称A为前项,B为后项。
关联规则发现过程中,通常会伴随以下现象:1)任何两项均可能有相关性,若这些相关的项均构成关联规则,则导致规则灾难,实际有用的规则只有少数几条;2)大量冗余规则的存在,如 X⇒Y,Z⇒Y,且 Z被包含在 X中,表明规则Z⇒Y相对规则X⇒Y是多余的;3)矛盾规则同时出现,如X⇒Y,Z⇒Y且Z⇒,表明规则Z⇒Y与X⇒Y是相互矛盾的。
在数据分析时,由于存在上述不足,对整个决策过程有害无益。为了避免冗余规则的出现,Apriori算法在挖掘时设置了支持度和置信度阈值,但不能有效处理矛盾规则。
关联规则度量的几个参数:
支持度(Support):规则 X⇒Y 的 support表示项集X与Y同时出现的的实例数占总样本数的比例,记 Support(X∪Y)。
置信度(Confidence):在X出现的实例中,Y也出现的实例所占的比例,记Confidence(X⇒Y),即Y相对 X 的条件概率 Support(X∪Y)/Support(X)。
只要设置适当的最小支持度和最小置信度,就可快速筛选出用户感兴趣的规则。
3 改进的Apriori算法
为了有效地获得强关联规则,Agrawal等人于1994年首先提出经典的Apriori算法。该算法首先是利用support参数寻找频繁1项集,再在频繁1项集基础上寻找频繁2项集,依此类推,直至找不到频繁项集;在找到所有频繁项基础上,利用置信度参数产生强关联规则。
该算法是利用广度优先逐层迭代搜索的方法,先找出所有频繁项集。运用Apriori算法挖掘时,会产生大量的频繁项候选集,算法不能有效剪枝。另外,重复扫描数据库全部记录,也是算法存在不足的表现,增加系统I/O开销,降低算法的效率,具体改进算法可参考相关文献。
Apriori算法只有支持度和置信度这两个参数还不够,有些矛盾规则无法剔除。在实际挖掘过程中,还有一些相互抑制出现的因素存在,这些规则被称为负关联规则,但传统的关联规则算法无法挖掘出负关联规则。所谓负关联规则,即X不发生导致Y发生的规则,可表示为﹁X⇒Y。为此,还引用另一参数,对比影响度[8]cont_int:①当 corrX,Y≺1,sup port(X)≺sup port(Y),cont_int②当 corrX,Y≺1,sup port (X)≻sup port(Y)时③当 corrX,Y≥1,sup port (X)≺sup port (Y) 时,cont_int=1-④当 corrX,Y≥1,sup port(X)≻sup port(Y)时其中 corrX,Y为 X,Y 的相关性, 即当一条关联规则的对比影响度corrX,Y大于0时为正相关,当corrX,Y小于0时为负相关,且值越接近1则正相关性越强,越接近-1负相关性越强,越接近0相关性越弱。
4 关联规则挖掘系统模型构建
4.1 模型建立
随着当代经济的蓬勃发展,就业压力的加剧,学生多数选择应用性强的课程,导致很多课程很少人选修,甚至不选。本文以英美文学学习为例,为加强国际合作,人们已习惯用英语作为国际化的沟通工具。但为了追求实用性,学生多数选择商务、外贸、旅游等应用型课程英语,导致英美文学课程越来越边缘化,学生学习兴趣也越发淡薄。为了激发学生学习英美文学课程的兴趣,文章建立关联规则挖掘模型,试图找到一些能够激发英美文学课程学习动力的相关因素。
关联规则挖掘模型通常分四步进行:数据收集、数据挖掘、规则解释、实践应用。在实际工作中,这四步往往循环进行。
4.1.1 原始数据收集
原始数据的收集渠道关系到数据的客观性、有效性。由于涉及到英美文学学习兴趣的因素,关系到的人员主要有教师和学生,他们也是数据分析模型的基础。在设计调查问卷时,他们也自然成为主导。问卷的主要问题通过文献搜索、学生访谈、教师专访方法完成,在收集到相关信息后,进行数据分析并设计调查问卷、发布问卷,然后通过web端或QQ收集已作答的调查问卷,形成原始数据。
4.1.2 数据清理并挖掘
由于被调查对象在进行问卷答题时,可能存在部分信息的不确定性及数据的错录或漏录现象,会产生一些不合理的数据,这对后期的挖掘效果产生影响,所以要进行数据清理、去噪。清理工作完成后,依据算法对数据格式的要求,进行必要的数据转换。
原始数据可能存在以下不足,要用相应技术处理,具体如下:
A、数据缺失:学生填表或录入员在录入数据时,可能对部分选项遗漏,可以适当填充缺失数据。一般用均值代替,或用回归技术进行处理。B、噪声数据:有效范围外的数据、重复数据等,可借助相关数据分析工具检测。C、数据转换:不同算法对数据的类型、格式要求不同,要做相应处理。对于数值类型的字段,是连续值的,可以分成若干段;是离散值的,若类别较多,也可分成若干类型。对于字符型字段,用不同数值取代,如学校名称,每个学校用一个数值代码。
4.1.3 知识解释
经过算法挖掘出的规则虽然很多,但实际有用的规则却不多,还有一些矛盾规则要过滤,否则会影响判断结果。另外,Apriori算法只能得到正相关规则,无法获取起抑制作用的因素。所以,要计算规则的“对比影响度”,得到正、负关联规则,这样可充分了解一个因素的出现会对另外哪些因素的出现起促进作用,哪些起阻碍作用,更有利于辅助决策。
4.1.4 知识应用
结合历史数据的分析结果及相关经验,预测将来行为,指导用户对未来工作方向的把握。当然,挖掘结果也不完全是正确的,更需要拿到实践中去检验。现实生活中的数据是客观、真实、多变的,要不断的、反复的检验知识,得到的知识也是不断变化的,只有适应现实生活,才是对我们最有价值的。
5 教学管理中的应用
关联规则在教学管理过程中的应用较为广泛[9-10],本文就英美文学学习兴趣进行挖掘。
5.1 原始数据
调查问卷从教材选用、教学方法、课程兴趣、不同题材阅读体验、考核方式等五个方面设计并收集数据。问卷设计重点以“教材选用”为主,涉及到 “文体的类型”“内容的包含”“教材的偏好”“教材的编排线索”“教学方法”“课堂语言选择”“教学方式选择”等多个子问题。数据搜集主要来自巢湖学院、合肥学院、铜陵学院、安徽理工大学、东华大学、湘潭大学等高等院校英语专业的学生参与,通过QQ或Web技术获取问卷结果,共产生有效问卷341份,将收集来的数据导入sql server2010,完成数据收集工作。
5.2 数据处理
将所有数据数值化,对缺失数据补全,对噪声数据用均值(或以出现频率高的属性值代替),将有多选项的问题进行组合并编号,对部分问题以满意度打分的离散化……
处理后的数据如表1所示。问卷共有30个子问题,所以数据表除了序号列外还有30列,共有341行有效数据,每行数据表示每个被调查者对问卷作答的答案。
西双说这还不是什么问题,大不了这三万块钱我不要了,可是,假如我们真的又成为夫妻,你说我是应该希望她好起来还是希望她好不起来?万一真的出现奇迹,万一她的病治好了,死不了了,两个人一起面对婚后的漫长生活,怎么办?继续疙疙瘩瘩凑和着过?肯定不行。还得离!那么,不希望她好起来?希望她结了婚就马上死掉?那还是一个正常人的想法吗?那我就丧尽天良了。
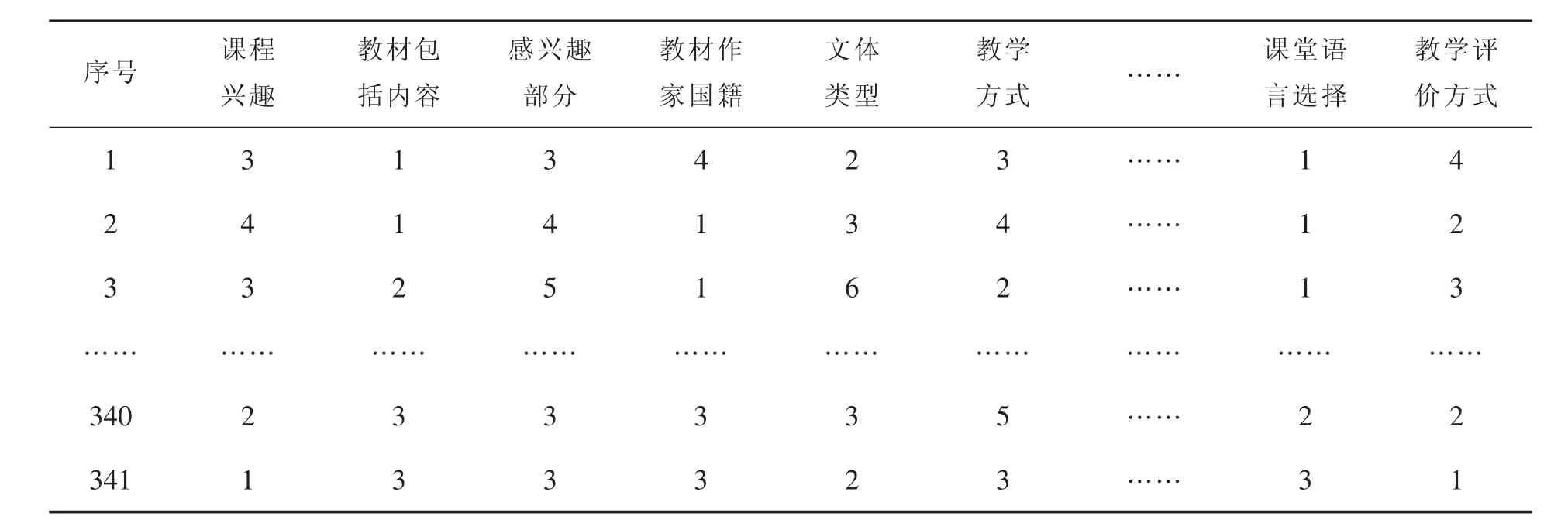
表1 预处理后的数据表
5.3 规则处理及解释
系统是以最小支持度为0.2,最小置信度为0.80进行规则筛选,共产生203条规则。这些规则中,有部分相关性不强的、有相互包含规则等。
规则A:选读内容还应包括:非经典、非文学作品 ^课堂语言选择:用英语教学为主、汉语为辅 ==>作家最好是:两者结合,以英国为主[0.289,0.836,0.199]。
规则B:选读内容还应包括:非经典、非文学作品==>作家最好是:两者结合,以英国为主[0.314,0.833,0.395]
很明显,规则A的前项包括了规则B,但规则A、B的后项相同,规则B属于冗余规则,应剔除。
规则C:认为这教材:凑合,兴趣不大 ^作家最好是:两者结合,以英国为主==>课堂语言选择:用英语教学为主、汉语为辅[0.327,0.839,0.041],虽然支持度、置信度均达要求,但由于对比影响度为0.041接近0,所以相关性不强,也应剔除。
删除这些相关性不强、冗余规则后,剩下61条有用规则,最后选择对比影响度接近0.5或-0.5的部分规则如表2所示:

表2 挖掘部分结果
规则2:认为选读文体类型最好是:各种类型应兼顾的学生,同时也不喜欢传统教学方式支持度为35.4%,其中,认为文体应用各种类型兼顾的学生中82.3%不喜欢传统教学方式,对比影响度为-0.562,说明此规则是强负相关规则。
规则3:认为课堂语言选择“英语为主,汉语为辅”且 授课重点“文学的社会、历史背景”的学生中有87.5%只读自己感兴趣的部分。英语结合汉语的方式,能够用学生了解的文化背景来体会作者的感受,使文化背景理解更透彻、更准确。
规则4:认为“新教材以日常生活为话题”且“授课重点:文学作品选读”的学生中有89.1%最喜欢的教学方式为 “课本+多媒体辅助 (包括电影、视频、电视剧等)”,对比影响度为0.67,属于强正相关规则,因为日常生活话题有很多借助于多媒体方式,更易表达作者的情感,且作者有丰富的想象空间。
规则5:认为“新教材以日常生活为话题”的学生中,有84.2%认为“阅读体验不感兴趣主要因素:离生活太远,用处不明显”,说明现在的教材有很多过时的文化,离我们的生活太远,学生迫切希望以日常生活话题注入新教材。
规则6:认为“对文学课程感兴趣”且 “不喜欢以期末考试或课程论文的评价方式”同时“对于选读内容只读自己感兴趣”的学生中有86.1%认为评价体系主要问题在于“传统评价方式忽略了弹性评价方式”。对文学课程感兴趣的学生,他们认为期末考试或课程论文评价方式不能客观评价一个学生的学习效果及喜欢程度,多数建议用“课堂讨论、与合作贡献程度”等弹性评价方式。
5.4 知识应用
1)影响学生学习英美文学课程兴趣的因素很多,本文就关联规则工具挖掘的知识,应用于提高英美文学课程学习兴趣,提出几点关于课程改革建议:教材的作家不要局限于英语国家,还要补充其他作家的作品,广泛吸取他国文化。
2)课堂语言选择最好以英语为主,汉语为辅,用母语来说明语境更充分体现作家的感受。
3)授课重点在于文学的社会、历史背景介绍,兼顾文学作品选读。文学选读最好是以日常生活为话题,以诗歌、短篇小说等形式为主,对于篇幅较长的要节选部分。若远离生活,学生对文学背景、环境无法理解,影响学习效果。
4)教学方式以“最喜欢的教学方式:课本+多媒体辅助(包括电影、视频、电视剧等)”为主,此方式能扩大学生的知识面,对场景的理解有身临其境的感觉,效果更好。
评价方式要灵活弹性,不能仅以期末考试或课程论文方式。多采用课堂讨论参与度、回答问题积极度、与同学合作贡献度等方式。
6 结论
关联规则目前已得到广泛应用,但多数应用未考虑负关联规则的影响。本文针对正、负关联规则挖掘建立决策模型,从数据收集、数据处理、数据挖掘、知识应用等环节着手,详细描述每个关键点的设计模型,并将挖掘模型应用于对学生学习“英美文学兴趣”相关因素的挖掘,分别从教学方法、教材改革、选读内容等方面阐述知识的应用。同时,也为类似教务管理中辅助决策提供了很好的开发模型。
