基于粒子群的HLS的自动化架构实现
2018-09-26吴家飞施文灶
吴家飞 黄 晞 施文灶
(福建师范大学,福建省光电传感应用工程技术研究中心 福建 福州 350007)
0 引 言
随着大数据时代的来临,以数据为驱动的深度学习已经在语音识别、机器视觉、自然语言处理等领域引发突破性的变革[1]。2015年由Kaiming He等提出的Resnet网络在ImageNet比赛中错误率降低到惊人的3.57%,已经超过人眼的水平[2]。2016年,由谷歌开发的AlphaGo与世界冠军李世石对战,成功赢下了人机对战的比赛[3]。但是伴随着深度学习的发展,计算规模也越来越大,比如VGG-16的参数达到1亿3千万个,基于传统的CPU平台已经难以满足如此大规模的计算,因此我们需要一种较好的硬件加速方式来满足计算需求。
传统对图像处理算法的加速采用的平台主要是GPU、DPS[4],虽然易于编程,但在功耗、性能、成本,以及图像实时处理等方面还是FPGA更具有优势。因此在嵌入式系统中采用FPGA来对算法进行硬件加速无疑是一种不错的选择[5]。
FPGA是以硬件语言Verilog或HDL来完成电路设计,设计期间需要仿真、时序分析和综合一系列步骤来完成设计[6]。复杂的时序设计、逻辑转化以及花费很多时间重复地进行仿真和优化,这需要设计者有扎实的相关基础和多年的经验才能完成。Xilinx公司发布的HLS工具,使设计者无需用传统的硬件描述语言来编写复杂的程序,只需将算法用C、C++等可读性高、易于维护的高级语言来完成。HLS工具能将相应的代码转换为硬件描述语言,并且还可以进行C/RTL协同仿真测试算法方案的正确性,满足了设计的灵活性。
目前已有许多应用HLS成功开发的项目,比如在文献[7]中,作者用HLS工具基于FPGA完成对数据挖掘中非常耗时的频繁项集挖掘(FIM)部分进行加速,速度比6核心的CPU快约3.2倍。和GPU相比,如果用最新的FPGA来完成算法,在低功耗的情况下性能甚至高于GPU。文献[8]中用机器学习的方式构建一套客观感知图像质量的方法。然后用HLS工具设计实现,在FPGA上完成算法的硬件加速。
虽然HLS能够方便地完成C/C++语言到硬件描述语言的转换,但如果我们想要充分地利用FPGA上的资源,我们需要用HLS工具对代码的函数、循环、接口、数组添加相应的优化指令来加快算法运行速度。具体的优化指令如表1所示。如果一段算法代码需要的优化点较多,比如:我们对离散余弦(dct)进行优化,优化4个循环部分、2个函数部分、2个接口部分,共8个优化点,将产生84×72×52=5 017 600种优化方案。假设每一种方案花费20 s时间分析,那么人工手动遍历每一种方案,从中选出最优方案,将会花费约3年多的时间,显然这是不可取的。

表1 粒子的编码
目前,在国内外,还有没有关于HLS工具优化方法的综合性研究,大多是对HLS的粗糙使用。比如:文献[9],把SHA-3加密算法用HLS进行优化设计时,只考虑到算法最大吞吐量,将算法中的子函数全都设置为pipeline指令,提高并行能力,将代码中的数组采用partitioned和dependece来解决循环执行中的相关性问题。虽然将吞吐量提高了200多倍,但是优化过于简单粗糙,且没有给出资源使用情况。文献[10]中,对FFT算法进行优化,主要分析了代码中3个循环使用不同优化指令的情况下,latency和资源使用情况。选出最小latency和资源使用较少的方案,满足了设计需求,但由于对算法的针对性较强,且算法规模较小,因此可拓展性不强。文献[11]中,通过对LeNet卷积神经网每一层都进行硬件分析设计,在节省硬件资源的情况下,利用HLS精细地划分最消耗时间的循环部分,并在MNIST手写识别数据库测试了架构的运行效率,取得了非常不错的效果。但这种方式需要设计者具备较多经验,对于一般软件设计者来说难度较大。
综上所述,由于目前基于HLS工具的应用还普遍比较粗糙,通过人工的优化方法,需要了解算法的结构,掌握并行运算的知识,并通过不断的尝试,从大量的组合方案中挑选合适的方案,这个工作量是非常巨大的,因此工作效率不高。本文提出的一种基于HLS的智能优化算法的架构,并在此架构上采用模糊离散粒子群算法将待转换的原代码进行编码,并通过自动调用HLS,进行仿真优化处理,分析提取latency和资源评估图的BPRAM_18K、DSP48E、FF、LUT等参数,并对产生的优化方案进行评估,从中优选合适的优化方案。从实验结果看,本文方法有效地提升工作效率。
1 总体优化架构
粒子群算法是一种群智能算法,具有算法简单、运算速度快、精确度高等特点,非常适合在大规模集合中迭代寻优。因此本文基于粒子群算法,设计一套HLS优化架构,流程如图1所示。
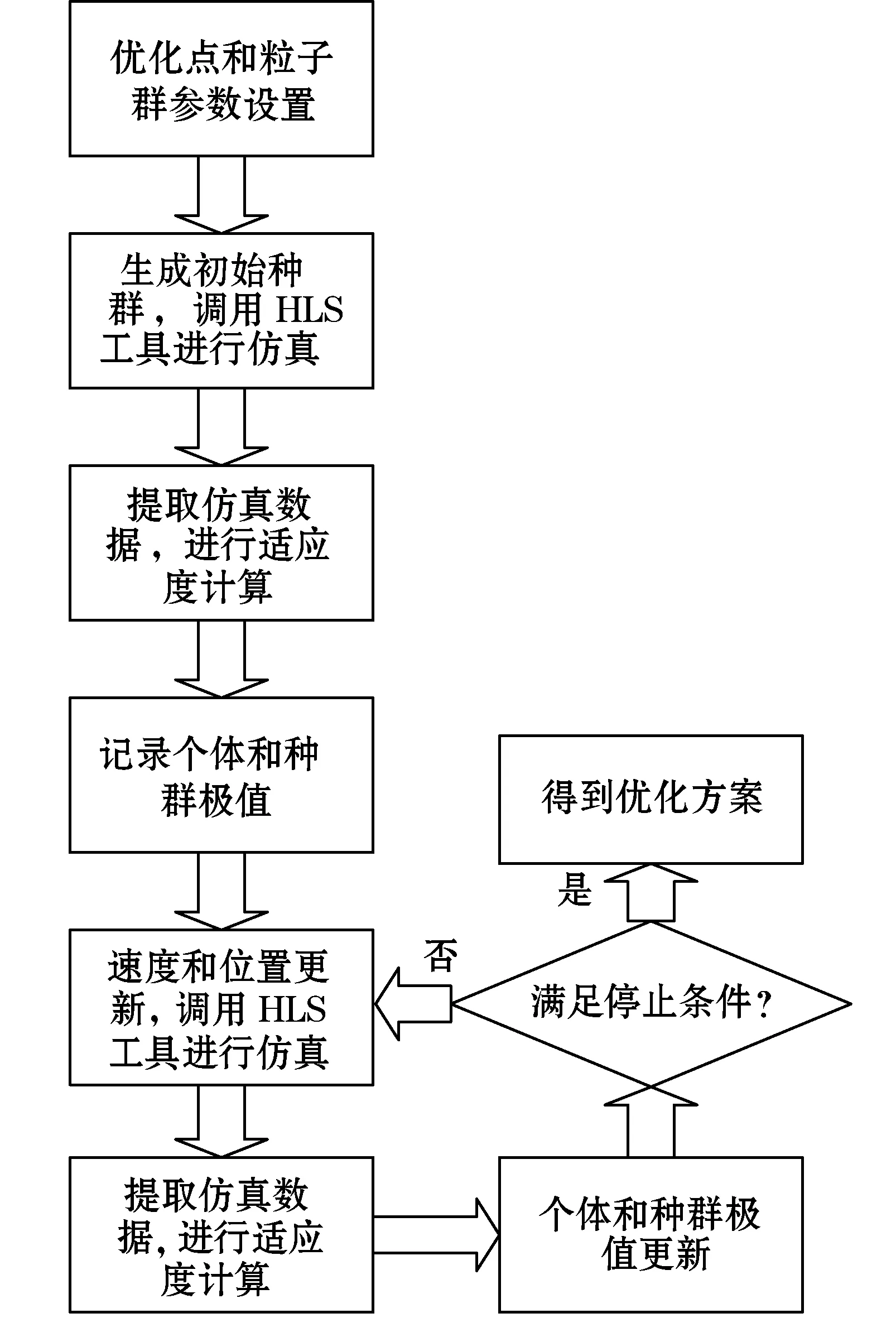
图1 流程框图
首先,我们将C/C++算法代码中需要优化部分进行设置,设置完成后运行粒子群的主程序,随机产生初始种群,把种群的参数信息传入HLS工具的API接口进行RTL仿真,提取仿真后产生XML文件中的Latency、DSP48、BRAM_18k、LUT、FF参数进行适应度计算。其次,记录个体适应度极值和种群适应度极值。再次,反复进行速度和位置更新、RTL仿真、适应度计算、个体和种群更新等迭代寻优的操作,直到满足停止条件。最后得到一个优化方案。
2 离散模糊粒子群编码实现
2.1 粒子的编码
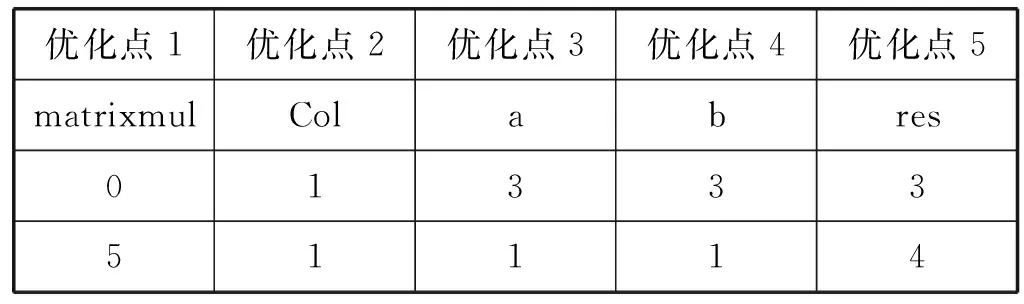
以矩阵乘法(matrixmul)程序为例:
void matrixmul(
mat_a_t a[MAT_A_ROWS][MAT_A_COLS],
mat_b_t b[MAT_B_ROWS] [MAT_B_COLS],
result_t res[MAT_A_ROWS][MAT_B_COLS]
)
{
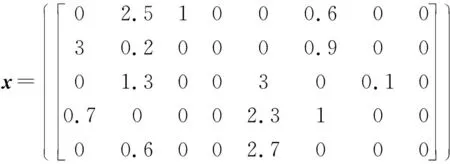
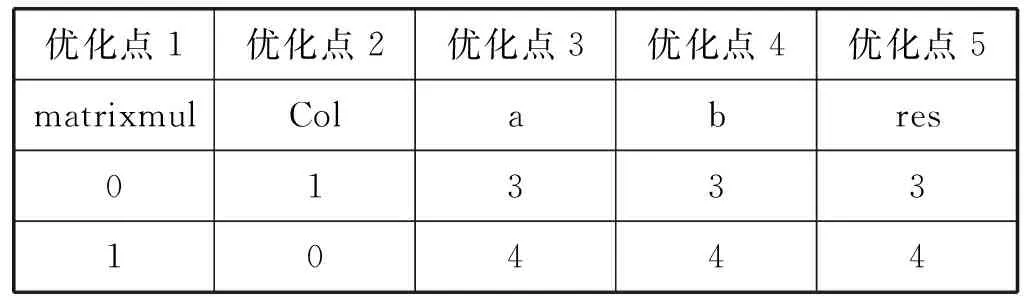
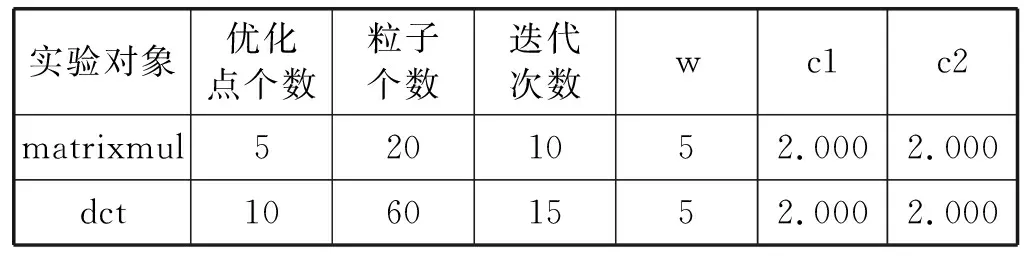
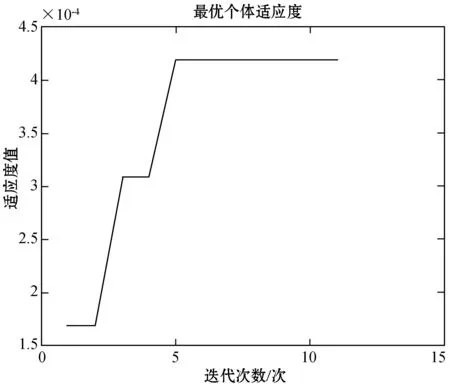
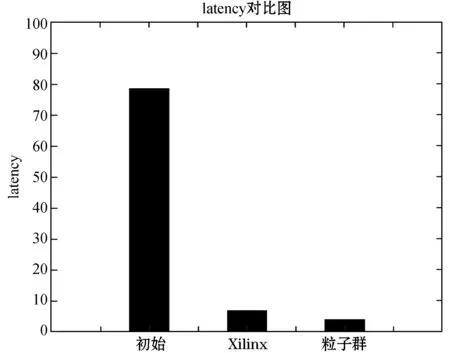
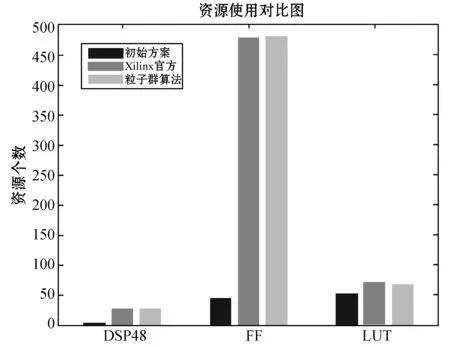
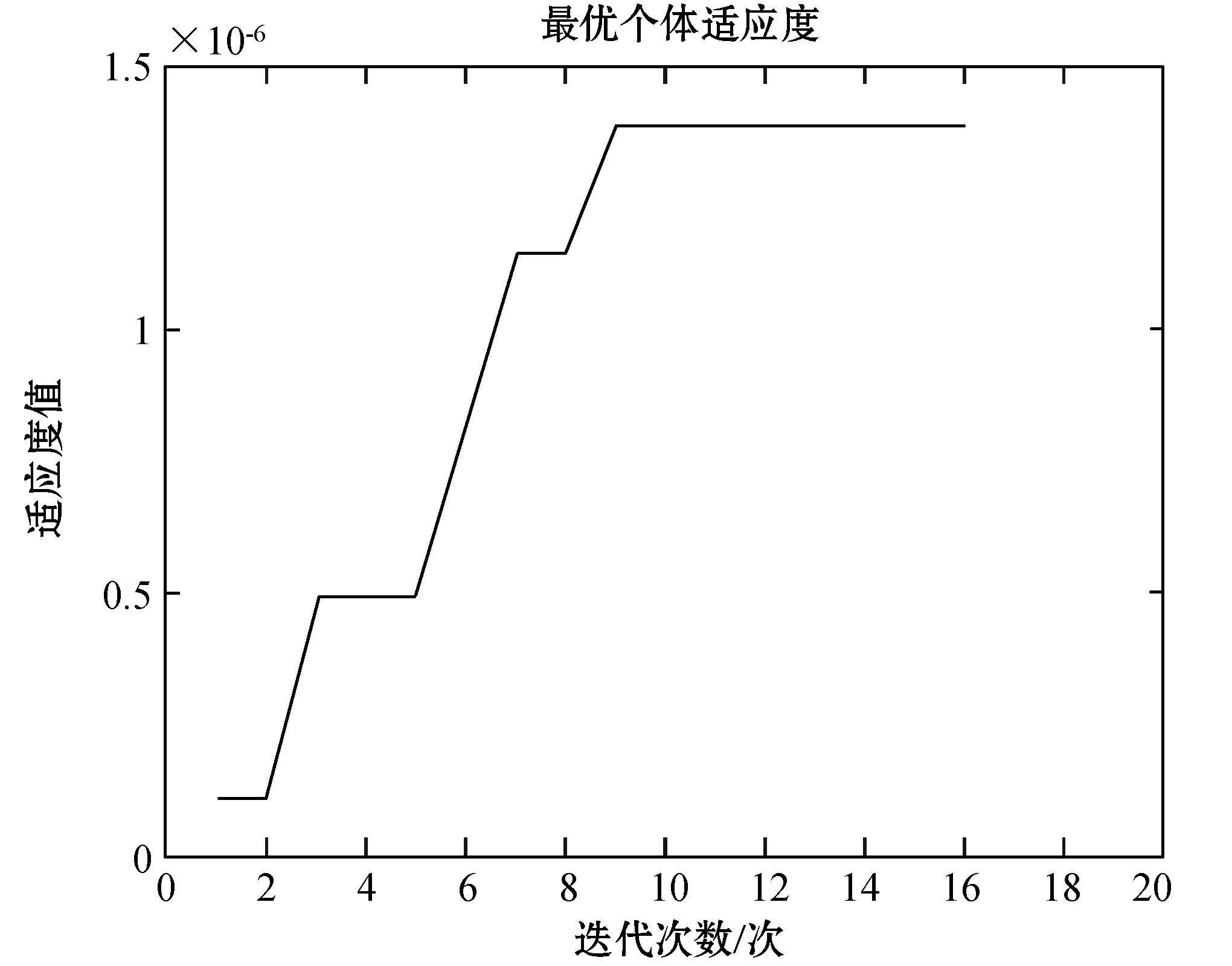
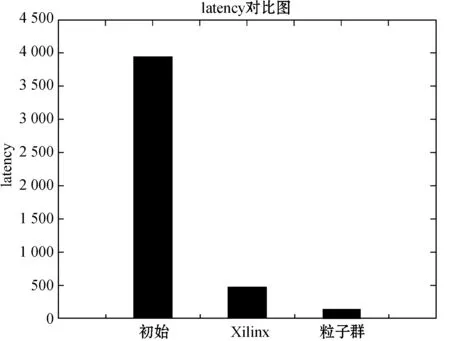
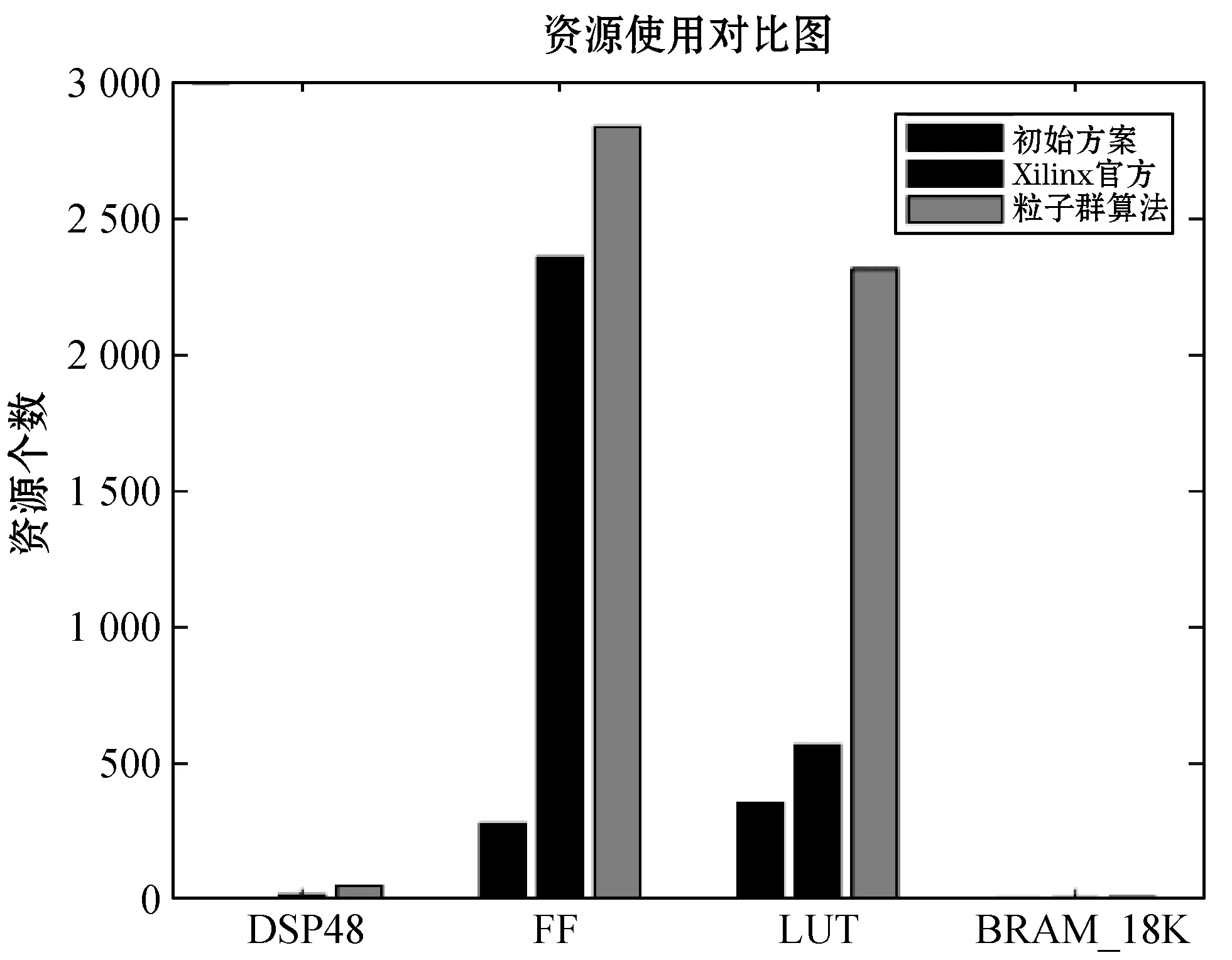
Row: for(int i=0; i { Col: for(int j=0; j { Res[i][j]=0; Product: for(int k =0; k res[i][j]+=a[i][k]*b[k][j]; } } } 假如我们想要优化这段代码中的函数matrixmul,接口a、b、res,循环Col,将这些优化点进行相应的编码设置,编码方式如表1所示。 我们将每个优化点设置为3位,第1位为相应的标签名;第2位表示优化点的类型,0、1、2、3、分别代表优化点的类型为函数、循环、数组、接口;第3位表示的是添加优化指令的编号,可通过查看表2中优化类型所对应的指令编号得出。举例说明:(matrixmul 0 5),表示优化点标签为matrixmul,优化的类型为函数,添加的优化指令为interface。(Col 1 1),表示优化点的标签为Col,优化的类型为循环,添加的指令为pipeline。由多个优化点组成一个例子,随机初始化一个粒子,如表3所示。 表2 HLS常用优化指令 表3 随机初始化一个粒子 本文中,粒子适应度(Fitness)的表达式如下: (1) 式中:Cost如下: Cost=latency×(BPRAM+DSP48E+FF+LUT) (2) 当方案具有较小的latency和较小的BPRAM、DSP48E、FF、LUT时将取得较大的适应度,适应度越高表示优化方案越优秀。 在一个N维搜索空间中,n个粒子组成粒子种群X=(X1,X2,…,Xn),第i个粒子在N维搜索空间中的位置用Xi=(x1,x2,…,xn)T表示,在本文中Xi代表优化指令解的集合。Vi=(Vi1,Vi2,…,Vin)T为第i个粒子的速度,相对应的个体极值为Pi=(Pi1,Pi2,…,Pin)T,种群极值为Pg=(Pg1,Pg2,…,Pgn)T。速度和位置的更新公式如下: (3) 式中:ω为惯性系数;d=1,2,…,n;k为当前迭代的次数;c1、c2为非负常数;r1、r1是分布于[0,1]之间的随机数。 在本文中将粒子的位置用优化指令的集合表示。我们需要将速度矢量和位置矢量用模糊集合来代替。以表3这个随机初始化的粒子为例,由5个优化点组成的粒子的位置(也就是每组第三位优化指令的编号)为(5,1,1,5,4),从表1 中可以得到优化指令编号的域为{0,1,2,3,4,5,6,7}。因此可以将位置模糊化为如下矩阵: 同样道理速度也可以用这样方式来表示。之后将位置和速度模糊集合代入式(3)进行速度和位置的更新。 这个粒子经过位置更新之后的粒子位置如下所示: (1) 标准化 标准化的方法为每行除以每行相对应的最大的数: (2) 去模糊化 去模糊化就是将模糊化的集合重新恢复为矢量: 最终,初始粒子在经过位置和速度更新之后的粒子如表4所示。 表4 位置更新之后的粒子 matrixmul函数优化指令由interface设置为pipeline,Col循环的优化指令由pipeline设置为unroll,a、b、res接口的优化指令都被设置为array_stream。 本文的实验采用的FPGA为Xilinx kintex7,xc7k160tfbg484-1。粒子群算法的框架通过VS2013编写,选取矩阵相乘(matrixmul)和离散余弦变换(dct)进行实验,其中算法的参数设置如表5所示。 表5 粒子群算法参数设置 首先对matrixmul算法代码进行优化,优化点为5个,分别是1个函数,1个循环和3个接口。优化指令组合数共有(6+1)×(7+1)×(5+1)3=12 096种,加1为没有添加指令的情况。应用本文的HLS自动化架构能够从中快速的找出适应度较高的优化方案,迭代寻优过程如图2所示。初始个体适应度极值较低,经过多次的迭代,最优个体适应度极值得到了提升,由于matrixmul案例相对复杂度不高,因此最优个体适应度很快在第5代稳定下来,并且不再变化。 图2 matrixmul案例迭代寻优过程 在多次迭代后,我们找到了一个优化方案。为了评估该方案的性能和资源使用情况,我们将该方案与未添加优化指令的方案和Xilinx公司提供的方案进行对比。如图3所示,由本文自动化架构求得的方案和未作优化的方案相比,latency大大降低,甚至低于Xilinx公司提供的方案的latency。而从图4资源对比图中可以知道,在各项资源的使用量上,第3种和第2种基本持平。因此,综合时延和资源使用来说,本文得出的方案无疑可以很好地满足设计需求。 图3 matrixmul案例不同方案的latency对比图 图4 matrixmul案例不同方案的资源使用对比图 同理,我们对dct案例进行测试,由于选取的优化点有10个,分别是2个函数、4个循环、2个数组、2个接口,共有两亿多种方案的组合。因此我们增加粒子的个数,以及迭代的次数,粒子群迭代的过程如图5所示,最优个体适应度不断提高,最终在第10代稳定下来。 图5 dct案例迭代寻优过程 同理,我们将迭代后找到的最优方案与未添加优化指令的方案和Xilinx公司提供的方案进行对比,从图6和图7中我们可以得到,第3种方案的latency比第1种方案低数十倍,比第2种方案低3倍,但是第3种方案的各项资源的使用量也相应增加。因此综合而言,在资源充足的情况下,如果开发人员想要更低的latency,由本文方法得出的方案可以很好地满足要求。 图6 dct案例不同方案的latency对比图 图7 dct案例不同方案的资源使用对比图 HLS工具可以高效率地进行高级语言到硬件语言的转换,解决了传统FPGA开发周期长、难度大等问题。目前HLS开发大多是通过人工的优化方法,需要了解算法的结构,掌握并行运算的知识,并通过不断的尝试,从大量的组合方案中挑选合适的方案,工作量非常巨大。因此本文基于粒子群算法设计了一套HLS自动化架构,在无需提前了解相关知识的前提下,设计者只需设置需要优化的优化点及粒子群参数就可以完成优化方案寻找。之后的流程都是机器完成,极大地提升设计人员的设计效率。最后通过自动化HLS架构对两个matrix和dct两个案例进行实验,都成功地得到了优化方案。将优化方案与Xilinx公司提供的方案相对比,结果证明本文方法得到的方案在性能和资源使用上都能较好地满足需求,进一步证明本文的优化架构具有一定程度的可行性和通用性。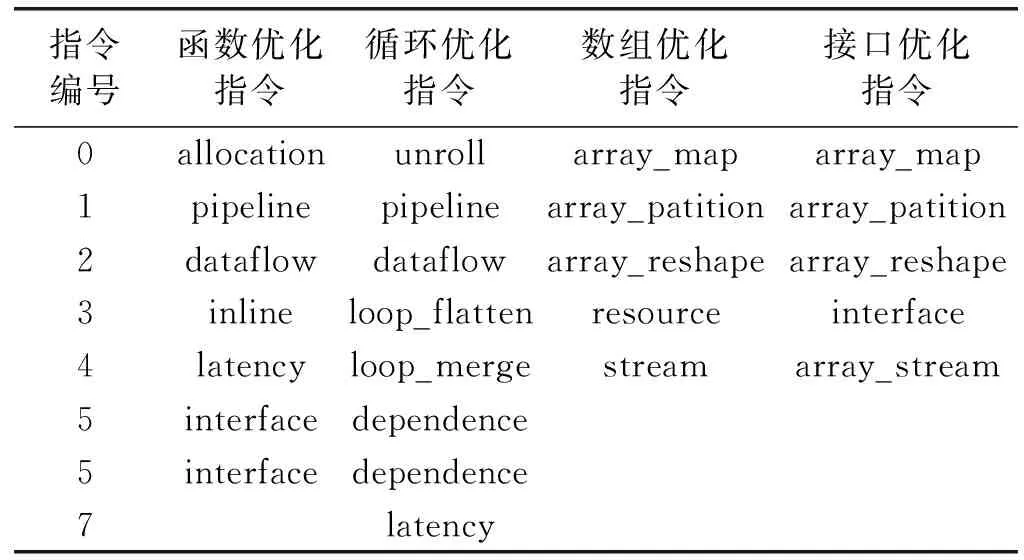
2.2 适应度计算方式设置
2.3 速度和位置更新操作
2.4 模糊化和去模糊化操作
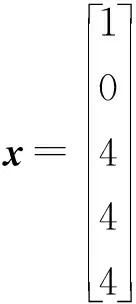
3 实验结果与分析
4 结 语
