一种改进的社交词嵌入算法
2018-09-26叶天顺
叶 天 顺
(复旦大学软件学院 上海 201203)
0 引 言
进入21世纪之后,互联网的飞速发展,一个极度信息化时代的到来,对人们生活的各个方面都产生了极大的影响。这些年来世界各地的网络技术飞速发展,伴随着移动互联网的出现,各种手持智能设备的普及,微博、论坛已经离开不了我们的生活。大量新兴社交媒体不断涌现,各种创新技术不断地推动网络传播向普遍性、多样性的方向发展。由于移动互联网的普及,普通群众可以方便地在网上发表自己的观点,对于消费后的餐厅酒店可以方便地进行评论,发表意见变得越来越方便。用户使用Facebook、Twitter、Yelp、微博和微信等社交媒体平台接收朋友的生活更新,并从朋友那里学习知识。众所周知的社会网络效应是“同质性”的概念,这种概念在心理学[1]中发展并在社交网络[2]中观察到。这表明用户和朋友之间往往会有相似的意见或主题。另一方面,社会语言学家还发现,社会中的自然语言理解需要理解语言所嵌入的社交网络。一个网络可能会松散或紧密,这取决于成员之间如何互动[3],并可能影响发表者采用的发言模式[4]。世界上的每个人都有自己的语言模式,并且会受到其他人的影响,所以扩展语言模型以进行社交化是非常有意义的事情。最近,人们已开发出社交化语言模型,但是这些模型主要用于社交媒体文本搜索[5-7]。Zeng等[8]提出一种社交词嵌入的算法,但是其社交正则化有不足之处。本文提出的社交词嵌入的算法通过实验证明,所生成的词向量的性能要优于其他算法。
本文介绍了一种社交化的词嵌入语言模型来为社交媒体中的词生成依赖社交关系的向量。该模型采用了最简单但最有效的word2vec[8]中使用的词嵌入模型作为基础模型。为了结合朋友关系,当训练词向量时,本文提出了一个社交正则项将社交关系融入模型。为了演示社交化词嵌入算法,本文使用Yelp商业评论数据来训练社交词嵌入语言模型。随后进行了Perplexity实验和SVM情感分类实验来验证社交词嵌入语言模型生成的词嵌入向量要优于其他的词嵌入模型。
1 社交词嵌入语言模型
1.1 用户向量加入模型中
在将社交关系融入模型之前,我们需要将每个用户向量加入模型中。为了训练词嵌入向量,本文将连续词袋模型(CBOW)[9]作为基础模型。与CBOW不同的是,社交词嵌入模型为每个用户分配一个词向量,并且加入模型进行训练[8]。对于每个词不仅像CBOW模型一样,提供每个词的上下文,而且为每个词加入这个词所对应的用户向量到模型中,在完成每个词向量训练的同时,也为每个用户训练出了每个用户的向量。

(1)
这里与之前介绍word2vec模型不同的地方是,对于不同的用户文档进行输入时,模型中加入不同用户的向量。与CBOW模型不同,这里指定上下文单词是依赖于用户的,不同的词不仅要对应其上下文信息,还要对应不同的用户。这意味着对于每个用户ui,他/她将考虑预测的词,即给出全局词的含义并将其定制为他/她自己的偏好。更具体地说,假设使用wj∈d,其中d是向量wj的维数,作为单词w的全局向量表示。本文还将使用用户向量ui∈d来表示每个用户。然后,将全局词向量和用户向量组合为新的向量如果有一个单词序列wj-s,…,wj+s,那么用户ui的组合词向量表示为与word2vec最大的不同之处是,在输入向量时,对于不同的单词,加入其对应的每个用户向量。由于logP(wj|Cwj,ui))的计算需要对词汇表中所有单词进行归一化,所以当词汇量很大时,CBOW模型难以优化。因此,最初有两种技术用于优化问题:分层softmax模型[10-11]和负采样模型[9]。由于社交词嵌入语言模型实现的代码是用负采样为基本模型来实现的。本文以负采样作为例子来进行介绍,需要优化的目标函数是:
(2)
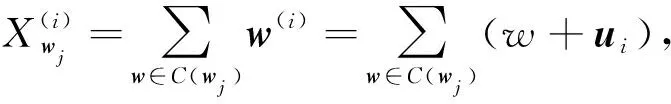
为了最大化目标函数,使用随机梯度上升法对上式进行优化,可以推导出相应的更新函数。
(3)
(4)
(5)
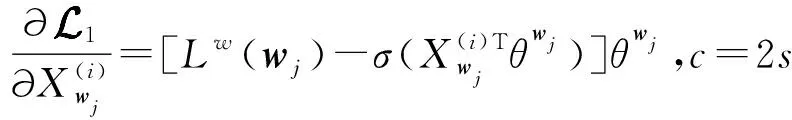
通过迭代学习,最后可以得到每个单词的词向量和每个用户的向量。
1.2 社交正则化
将用户的好友关系通过本文提出的社交正则项,融入到语言模型中,对于改善词嵌入向量的学习效果可以起到很大的帮助。
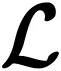
(6)
(7)
(8)
当我们使用由ui发布的文档时,用户向量ui应该根据其所有朋友的uj的向量进行更新,而用户向量uj仅基于ui进行更新。可以将第二个目标函数与第一个目标函数相结合,并对全局词向量、参数向量和本地用户向量交替执行随机梯度上升法。但是,由式(7)、式(8)可知用户向量将被更新的次数比单词向量多得多。最初在CBOW优化中,所有全局词向量不受约束,因为单词向量的大小可以由学习速率(与单词的频率组合)限定。本文使用了一个用户向量的约束,使数值优化稳定。所有的损失函数是:
(9)
算法1社交词嵌入算法
输入:N个用户(u1,…,uN)的社交媒体数据,其中每个用户有一个语料库Wi={di,1,…,di,Mi},Mi为用户ui写的文档数量。
初始化:最大迭代次数T,学习速率η1、η2,社交正则化权重λ,上下文窗口大小c,约束参数r。
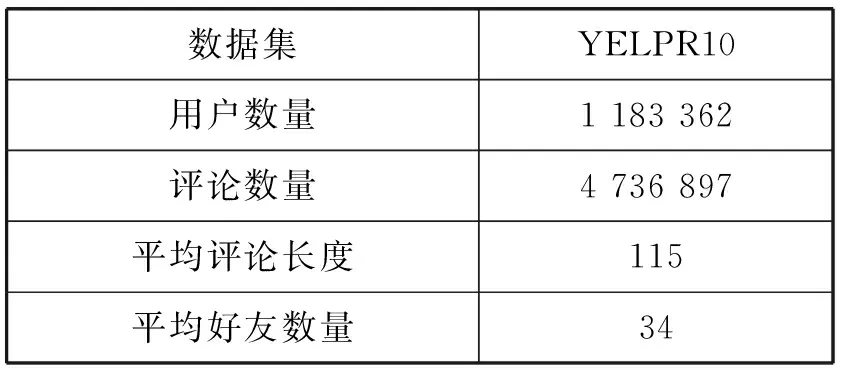
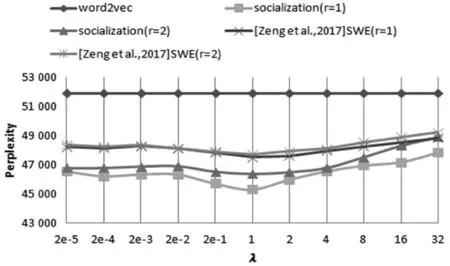
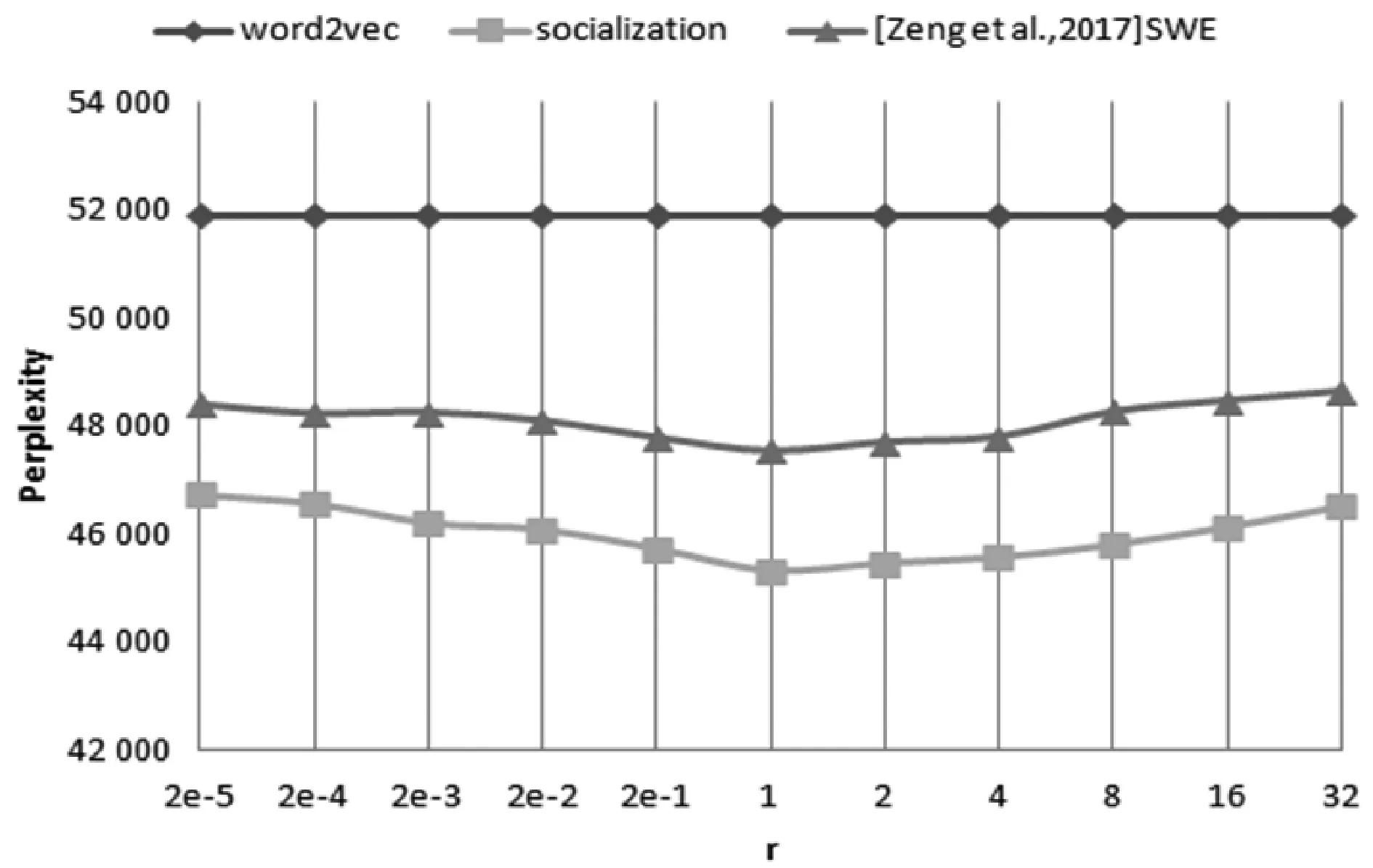
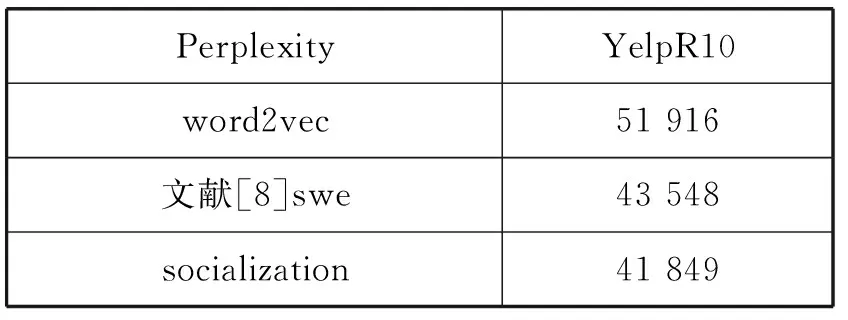
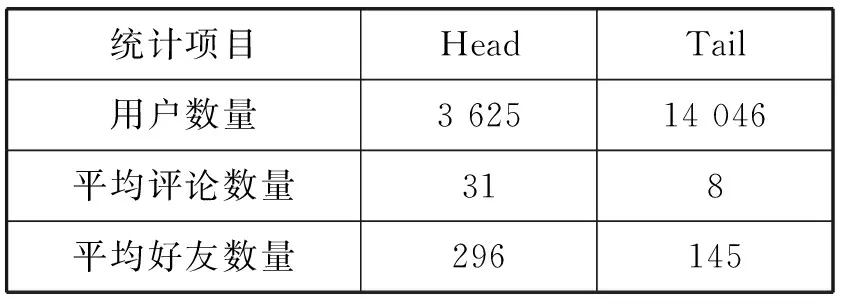
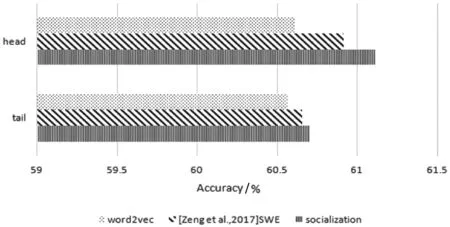
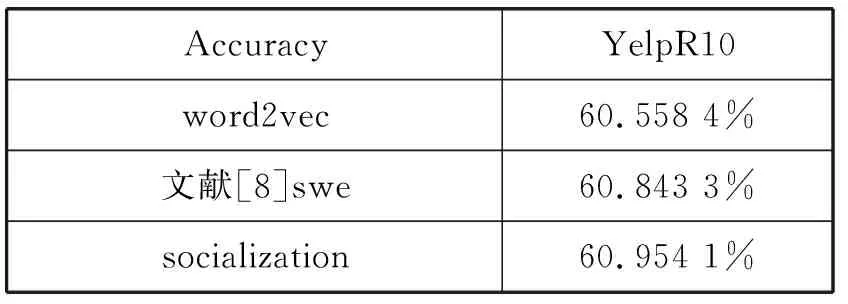
If Iterationt for alluido for alldiinWido end for if ‖ui‖>rthen end if if ‖uj‖>rthen end if end if end if 输出:词向量wj和用户向量ui。 本节使用Yelp数据集来训练社交词嵌入语言模型,通过两个实验来展示本文所提出来的语言模型生成社交词嵌入向量的有效性。 实验中使用Yelp Round 10数据集。Yelp网站在国外就是类似于中国的大众点评网站。在Yelp,用户可以为一些商家撰写评论,例如餐厅,酒店等。用户可以为餐厅或者酒店进行打分,也可以彼此关注以接收来自朋友的信息(一些朋友信息来自Facebook或其他社交网络)。这个数据集和其他数据集有的优势是提供了好友关系,这也是为什么本实验选择这个数据集的原因。Yelp数据集统计如表1所示。Yelp发布的数据量在数年内增长很多,所以数据量大、用户撰写的评论之多适合社交词嵌入语言模型进行词向量的训练。Yelp是美国最大的点评网站,令人兴奋的是:Yelp公开了他们内部的数据集。这是可获取大量文本的最大的社交网络数据之一。实验中将数据随机分为训练集、开发集和测试集,其比例为8∶1∶1。如表1所示,所有结果均基于此分段的数据集。 表1 Yelp数据库数据统计结果 对于Yelp提供的数据集,本实验并没有使用它所提供的所有数据,而是选取了模型所需要的数据,比如:每个用户及其评论、好友关系、对不同商品的评分等。本实验基于分离出的训练数据训练了所有的词嵌入模型。对于下游实验,本实验将根据想要测试模型的不同意图来更改设置。词嵌入模型代码是基于用C语言编写的原始版本word2vec。word2vec源码是Google所公布的源码。本实验以此为基础在word2vec源码上面写入社交词嵌入模型代码。本实验和文献[8]所进行的实验进行了对比,为了进行公平比较,本实验将原始word2vec的超参数设置为对于所有模型都是相同的。例如,窗口大小设置为5,并且单词的维度被设置为100。实验对所有的词嵌入使用了CBOW模型和负采样训练语言模型。 如果要对一个语言模型评判其好坏,最佳的方式是把它应用到实际问题中去,比如机器翻译、语音识别等。然后观察这个语言模型在这些实际任务中的具体表现。但是,这种方法首先是不容易进行操作,其次是需要大量的时间。因此,人们就希望找一种比较直接评判方法。希望按照语言模型本身的一些特点,来设计出一个简单又高效的指标。于是,提出了perplexity。Perplexity是一种使用在自然语言处理领域中用来评价一个语言模型的好坏的非常有效的指标。它可以评价一个语言模型是否为一个很好的预测样本的标准。如果复杂度越低,即perplexity值越小,表示语言模型的预测性能更好。本文在第一个实验中选用perplexity(复杂度)来评价社交词嵌入语言模型。Perplexity的定义如下: (10) 式中:wi代表第i个词,PP为Perplexity运算出来的结果。 在第一个实验中,使用不同的参数来测试词嵌入模型。首先在开发集寻找最优的超参数,然后在测试集上进行测试。使用perplexity作为实验的一种指标,由于本质上社交词嵌入语言模型和word2vec不是直接优化perplexity的语言模型,因此本实验的perplexity值要高于文献中的一些perplexity值。本实验仅用于展示本文所提出的模型的不同超参数设置。根据定义,perplexity是用来评估一个模型在预测当前单词的基础上有多少其他单词的指标。由于本实验使用大小为s=5的滑动窗口来训练所有单词嵌入,所以实验中提出的是六元perplexity,然后根据整个训练数据训练词嵌入。为了提高测试不同超参数的效率,对于开发集和测试集,实验中随机抽取每个用户的一个句子来评估基于perplexity的句子。 实验结果如图1和图2所示。实验目的是为了对比与之前相似文献中的实验和进行超参数的设置,而不是与文献中其他类型的perplexity进行对比。本类型perplexity值偏高主要有两个原因:(1) 本文提出的模型并不像其他语言模型那样直接优化perplexity。因此,该模型可能没有很好的拟合数据。(2) 本实验使用的Yelp数据比正式语言更嘈杂,因此,perplexity更高。这也在文献[7]中得到验证。在经验上,尽管word2vec和本文提出的模型并不直接优化perplexity,但它在训练的损失和测试有效性之间有良好的折衷,作为其他下游任务(下节中的SVM情感分类实验)的词表示,有着优秀的效果。 图1 Perplexity在开发集上的结果(r固定 λ变化) 图2 Perplexity在开发集上的结果(λ固定 r变化) 实验在YelpR10数据集上进行测试,如图1所示,固定r(用户向量的L2正则约束)和变化λ(社交正则化参数)的perplexity结果。在固定的r和变化的λ的情况下,本实验训练出的社交网络词嵌入的向量相比word2vec算法生成的词向量,可以明显地改善perplexity结果。本文所提出的社交正则项训练的词向量的效果要略优于文献[8]中提出的社交正则项。可以看出,当增大社交正则项时,perplexity可以得到进一步改善,当λ=1时,实验效果达到最好,但当λ过大时不会获得更多的改善。这个原因可能是:在固定用户向量大小时,增加社交正则项将倾向于首先通过其朋友来优化每个用户向量,但最终使所有用户向量变得尽可能相似,这将再次使其欠拟合。 图2中显示变化的r(用户向量的L2正则约束)与固定λ=1(社交正则化参数)的结果。它表明,当增加正则项约束r时,perplexity首先被降低。当r=1时,perplexity值达到最小。可以看出,本文所提出的优化模型略优于文献[8]所提出的社交正则项。当继续增加r时,再次会使perplexity值增大。如果用户向量的参数r变得太大,那么当优化代价函数时,它将支配单词向量。因此,在本文提出的算法中,参数r和λ是耦合的,没有任何一种趋势会使perplexity持续减少,所以需要通过实验选出最优的超参数。实验将参数在{2-5,…,25}的范围内执行网格搜索,根据验证集合选择最佳的超参数。 表2为测试集上进行测试的最终结果,可以看到,应用词嵌入社交化语言模型使最后的结果有显著的改善,并且本文所提出的社交正则项的改善结果要优于文献[8]所提出来的相关模型。 表2 Perplexity在测试集上的结果 在本实验中使用perplexity作为评价社交词嵌入语言模型的指标,首先在开发集上找出最优的超参数:r(用户向量的L2正则约束)和λ(社交正则化参数),然后在测试集上进行对比实验。本文所提出的社交正则项所训练出来的词向量在perplexity作为评价指标上要优于word2vec和文献[8]模型所训练的词向量,说明了本文所提出的社交正则项的有效性。 本节要测试社交化词嵌入的下游任务——Yelp评论的分数预测。在Yelp网站上,用户可以写评论给商家。同时,用户可以为服务提供评分,对每个商家可以打一到五分。实验目的是使用社交词嵌入模型训练出来的词向量,将用户发表的每句话相加求和进行平均表示成向量,使用支持向量机作为机器学习方法进行学习,然后进行预测得到结果。本实验遵循文献[8]中的任务,这是长文本情感分类。为了测试这个任务,实验采用简单的支持向量机(SVM)作为机器学习方法,其中特征是用户向量和单词向量的平均值,并选择不同比例的数据来训练SVM分类器。为了测试重要的数据选择或预处理如何影响最终结果,实验还将用户分为头部用户和尾部用户。头部用户,就是那些发布了大量评论的用户,而尾部用户发布较少。然后简单地对所有用户进行排序,并选择那些发布了全部评论的一半用户为头部用户,其他用户则作为尾部用户。随机选择五分之一的训练数据进行SVM训练以提高实验效率。 表3显示了头部和尾部用户的统计数据。可以看出,头部用户倾向于发布更多评论并拥有更多朋友。图3显示了基于头部和尾部子集训练的结果。可以看到,本文提出的社交正则化模型的预测结果要高于word2vec和文献[8]模型的结果,进一步说明本文提出的社交网络正则化的有效性。从图中还可以推测出,头部数据的个性化和社交化的改善比尾部数据更大。这意味着,当用户评论较少,同时与该用户的关系链接较少时,当前的算法无法很好地进行训练。当用户评论较多并且有较多的好友关系时,可以用本文提出的模型算法进行较好的训练。另一方面,预测头部评论的准确度高于尾部。这意味着,当用户写的评论越多和拥有更多的好友时,社交词嵌入模型可以更好地提取相关信息生成更有效果的词向量。但是,实际上更有可能在网络中随机抽取用户来标注相应的数据。因此,当遇到需要为社交媒体注释数据的真正问题时,认真对待不同用户群体可能会更好。可以选择用户好友更多而且发表了较多评论的用户。 表3 1/5训练集的头部和尾部数据统计结果 图3 SVM分类在头部和尾部数据上的准确率 本实验还将支持向量机在全部的五分之一数据上进行训练,在开发集上进行超参数调整(包括用于SVM的参数),在测试集上进行测试,并将结果在表4中显示。可以看出,本文提出的社交正则化模型要比文献[8]模型准确率高0.11%,比word2vec模型要好0.4%,再次通过实验证明社交词嵌入模型的有效性。 表4 SVM分类在测试集上的准确率 本节提出了一种社交化的词嵌入算法,将社交关系加入语言模型的训练中,以从社交媒体文本中和用户社交关系中学习一组全局词向量和一组本地用户向量。一个简单但有效的社交正则化被强加给词嵌入语言模型。通过实验表明,用户向量本身的个性化和社交正则化可以改善下游任务。使用两组实验来演示本文提出的社交词嵌入算法的有效性。实验对比了Goolge提出的word2vec和文献[8]中的模型,均取得了略好于它们的效果,证明了本文提出的社交词嵌入语言模型的正确性和有效性。 本文提出了一种社交化的词嵌入方法来为社交媒体中的词生成依赖社交的词嵌入向量。该模型采用了最简单但最有效的word2vec中使用的词嵌入模型作为基础模型。为了结合朋友关系,本文为模型添加一个社交正则项,然后使用Yelp商业评论数据来训练社交词嵌入语言模型,进行了Perplexity实验和SVM情感分类实验,验证了本文提出的模型生成的词嵌入向量要优于其他的词嵌入模型。 本文工作中也存在不足,那些拥有较多好友和发表较多评论的用户,在应用社交词嵌入语言模型时所得到的实验结果的改进要优于好友数和评论数较少的用户。未来需要在模型中改善那些发表评论很少的用户和那些好友比较少用户。2 实 验
2.1 数据集和实验设置
2.2 Perplexity实验
2.3 SVM情感分类实验
3 结 语
