基于大数据技术的EAST实验数据访问日志分析系统的设计
2018-09-26章琦皓王月婷
章琦皓 王 枫 王月婷
1(中科院等离子体物理研究所 安徽 合肥 230031)2(中国科学技术大学 安徽 合肥 230026)
0 引 言
MDSplus作为EAST聚变实验数据存储的主要工具之一,每年有大量的聚变科学家对MDSplus实验数据进行访问[1-2]。伴随着实验室的MDSplus存储的数据量日益增长,访问MDSplus的用户也随之增加。防止用户恶意访问MDSplus中某单一节点数据从而导致服务器负载过大、监控MDSplus服务器的流量的出入变得尤为重要。目前正在使用的MDSplus服务,其日志系统只是单一的记录了用户的TCP/IP连接记录,并没有记录用户任何其他相关的操作记录,这给MDSplus的监控带来一定的盲区。如果能对MDSplus上所有用户的操作进行监控,并且及时、没有偏差地记录下来,就可以通过统计知道用户对聚变实验某些数据的偏好,体现该信号量所具有的研究价值。对MDSplus日志进行数据分析,提取有效的日志信息,采用现有的大数据技术上的机器学习等方法,搭建出一套可用的MDSplus日志应用平台。
据统计目前每天EAST上的MDSplus日志大概有3万条日志记录,这些还只是单一的TCP/IP记录,如果通过完善目前的MDSplus日志系统,可以记录所有用户的操作,那么每天会有百万条日志记录。当然这一日志记录很有可能在实验期间某一时间段呈现爆发式增长,在秒级别内产生百万条日志记录,在为了应对未来海量的数据日志消息的产生,本文借助大数据技术进行海量日志的分析。
另外,MDSplus聚变实验数据存储量很快要达到PB级,未来聚变实验数据很有可能使用类似于Hadoop这样的大数据框架进行存储,使用大数据技术进行日志分析迎合了未来数据存储的发展趋势。
目前国内外所有使用MDSplus的实验室或者研究机构没有针对MDSplus日志这一项功能进行相关的技术上的完善,更没有相关的日志上数据的分析,所以在原有日志的基础上构建一个基于大数据技术的MDSplus日志分析系统具有技术上的挑战和实际实验中的意义和价值。
1 主要目标
作为EAST实验数据重要的存储工具,MDSplus日志系统需要改变以往的简单的记录方式。EAST上MDSplus access日志原有的格式如下:
1) {date} (pid number) Connection received{or disconnected} from {username}@{ipAddress}
2) Invalid message
格式只是单一的记录下了简单的远程用户的连接记录,包括用户名和IP地址,其次还有一些无效的日志信息参杂在日志中。实际情况中,MDSplus日志系统需要记录下更多有效的日志信息。如表1所示,希望能够记录更多关于用户在MDSplus上的数据操作类型,如GetData、GetSegment等操作。
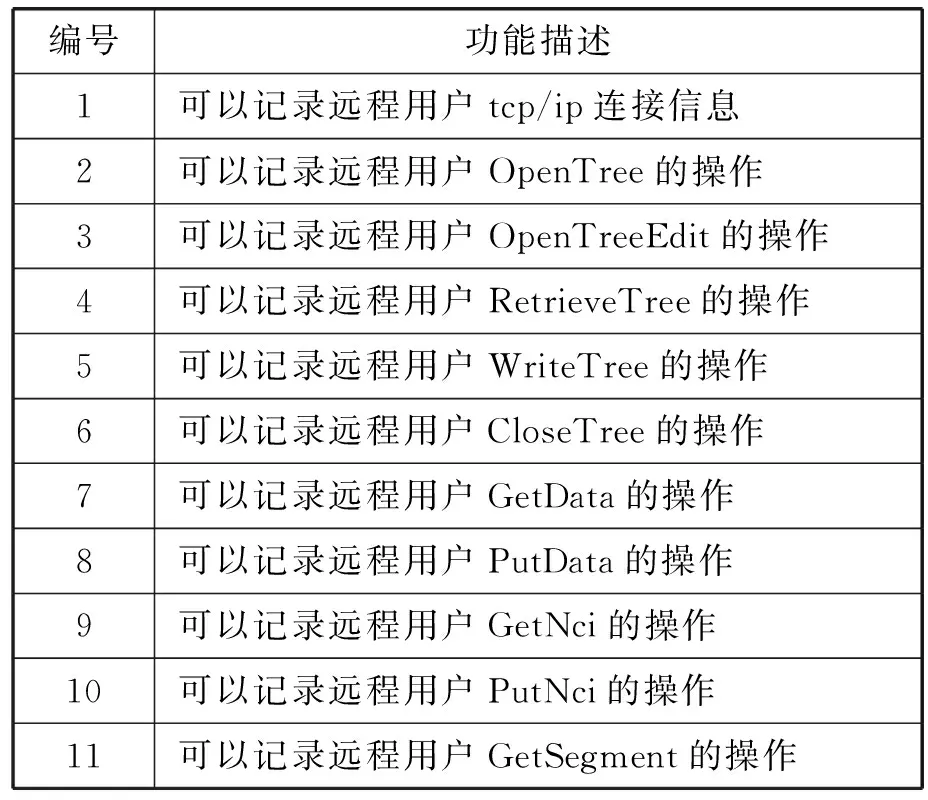
表1 MDSplus日志设计需求
完善现有的MDSplus日志系统,增加更多的日志记录信息之后才能建立一个集离线与实时于一体的日志分析系统。整个架构系统能够达到线上实时预警、流量监控。线下提取有效信息,采取应对手段的功能。整个工作分成四步:
1) 完善的MDSplus日志功能。
2) 针对MDSplus日志进行离线。
3) 针对MDSplus日志进行实时分析。
4) 日志数据可视化。
2 系统设计
2.1 系统架构的设计
日志分析系统整个软件架构如图1所示。整个系统的设计是在拥有完整的日志信息前提下借助于现有的大数据技术对日志信息进行处理。
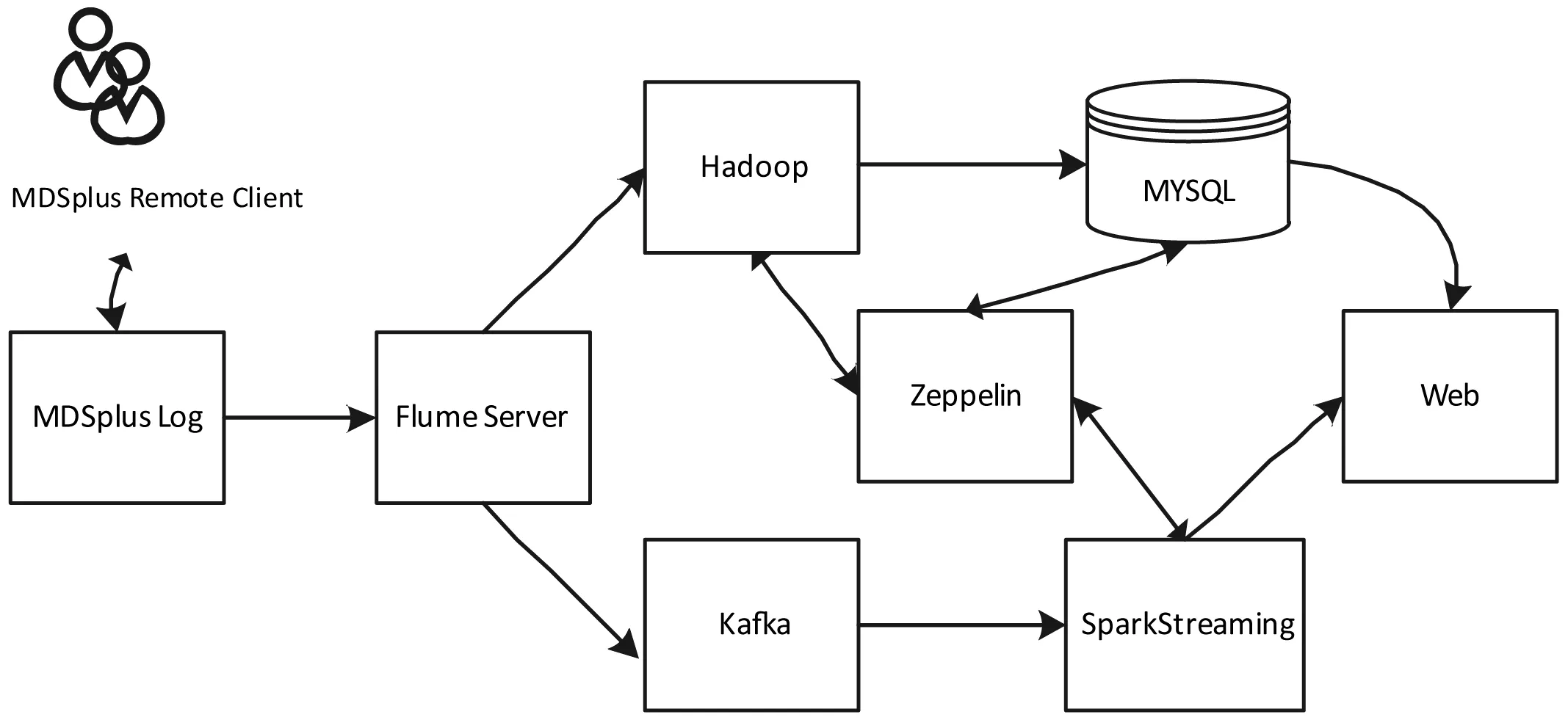
图1 系统总体架构图
系统用到的大数据技术和概念包含以下几个方面:
1) Flume:分布式、可靠、高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据[3]。
2) Kafka:高吞吐量的分布式发布订阅消息系统,形成流式数据,供Spark Streaming 进行流式计算[4]。
3) Hadoop:大数据分布式开发框架,使用HDFS进行数据存储。
4) Spark Streaming:基于Spark生态圈的准实时流数据计算框架[5]。
5) Zeppelin:大数据可视化工具,除了能够接入传统的MYSQL数据源以外,还能很好地接入Hadoop和Spark的数据源。
6) Web端:传统的数据展示手段,其中使用到了Echarts等开源插件。
由图1可看出,远程用户针对MDSplus服务器进行数据访问,产生大量的数据访问日志。该日志信息实时被Flume服务监听,监听到日志的变化,一方面将其发送到Hadoop集群中的HDFS(Hadoop分布式文件系统)中进行持久化存储,方便日后的离线处理,另一方面将日志信息发送到Kafka服务中,转换成实时数据流供Spark Streaming进行实时的流数据处理。因为原有的MDSplus日志信息在一段时间后会自动被新的日志信息给覆盖,所以在数据采集方面为了保证原有的MDSplus日志信息持久化,在数据收集时先在Flume端进行自定义正则过滤器,将不必要的日志信息过滤掉。一方面在离线数据存储时候将日志信息按照年月日时间被归分到HDFS存储下不同的目录中,另一方面在实时数据传输中将日志信息按照不同的日志类型存储在Kafka不同的Topic中。采用这样方式进行数据采集,将传统的服务器日志信息和新生的大数据采集框架有机地结合起来,从离线和实时两个方面使得日志信息的收集存储有很好的条理性和逻辑性。数据还可以持久化到MYSQL数据库中,中间利用到Zeppelin数据可视化工具和Web数据展示工具。至此,整个流程将日志的产生、处理、展现综合起来,形成了一个完整的EAST实验数据访问日志分析系统。
2.2 MDSplus日志功能的完善
根据现有的MDSplus源码接口,采用钩子函数监听的方式对整个MDSplus服务器进行监听[6]。设计对应的钩子函数可以对所需要的信息进行钩取。将需要监听MDSplus的用户操作使用枚举的方式存储,然后对应到相应的Notify通知中,针对不同的操作调用CallHookback函数,通知到MDSplus的日志文件中去。整个MDSplus日志架构和流程如图2所示。
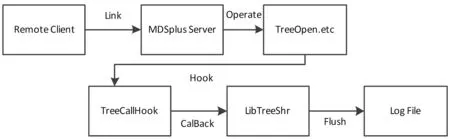
图2 MDSplus日志完善架构图
1) 远程客户发出请求,连接到MDSplus服务器;
2) 客户在服务器上进行一系列的TreeOpen、GetData等操作;
3) 对应的操作触发TreeCallHook函数;
4) TreeCallHook函数触发libTreeShrHook.so动态链接库;
5) 动态链接库将相应的日志内容以刷新缓冲的方式打印到日志文件中;
6) 客户端断开与服务器的连接。
完善的日志系统中调用的动态链接库LibTreeShrHook.so使用到的钩子函数算法如下(伪代码):
int Notify(TreeshrHookType Htype, char *tree, int shot, int nid)
{
SomeVarDefine();
//定义一些记录信息变量
switch (Htype) {
//匹配对应的数据操作类型
case OpenTree:
name=″OpenTree″;
Operation_1();
break;
…………………… 省略……………………
case GetSegment:
name=″GetSegment″;
Opreation_n();
break;
}
printf(Meassage);
//打印日志信息
fflush(stdout);
//刷新日志信息到标准输出中
if (path != na && path != (char *)0)
free(path);
//释放节点路径
return 1;
}
值得注意的是,目前钩子函数的触发条件是远程的客户端连接方式,暂不支持本地操作日志记录功能。该算法基本能够实现目前所需要的MDSplus Log的功能。图3是目前完善后的日志文件能够记录到的日志内容,新增加了{date} (pid number) HookType called for {node absolutely path}日志格式,使得日志信息更加完整、可靠。

图3 MDSplus日志内容
3 离线数据处理
MDSplus日志内容作为Flume的代理对象Agent的数据来源,将日志信息缓冲到Channel中。采用了Flume的选择分流模式,将事件流向两个目的地。在离线模式下,Channel1介质设置为磁盘介质,一旦达到缓冲大小,就将日志内容发送到下游Sink1指定的HDFS中进行存储。分流模式如图4所示。
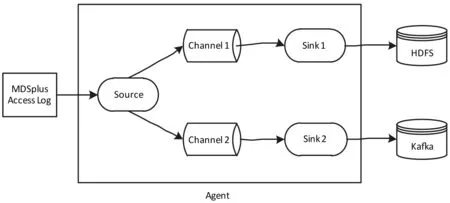
图4 Flume分流模式
HDFS中的存储内容是Flume过滤后以天数为单位存储的日志信息,使用Hadoop的MapReduce计算框架将日志信息分解成两种不同的数据模型[7]:
(1) 客户模型。记录着当前用户的信息,包括用户连接或者断开连接的时间、当前连接的进程号、用户名、IP地址、当前用户状态等信息:
client(linkTime:String,pid:Integer,user:String,host:String, status:String)
(2) 操作模型。记录着用户连接MDSplus服务器后一系列的操作信息,包括操作时间、进程号、数据操作类型、操作的树名、炮号名等信息:
operation(linkTime:String,pid:Integer,hooktype:String, tree:String, shot:Integer, nodepath:String)
考虑到日志信息中含有多种不同类型的日志信息种类,所以在MapReduce的map过程需要接收两种不同的输入数据类型进行序列化,分别是client数据类型和operation数据类型。然后继承Hadoop接口中的GenericWritable类,将两种数据类型结合起来,这样就解决了map过程中可能出现不同的数据类型的情况,具体如下:
public class logWritable extends GenericWritable {
private static Class[] CLASSES=null;
static {
CLASSES=(Class[]) new Class[] {
org.apache.hadoop.io.Text.class,
ClientWritable.class,
//自定义client类型
OperationWritable.class
//自定义operation类型
};
}
……………………………省略……………………………
}
经过数据的ETL过程,可以看到MDSplus日志信息被提取出来放在以下两个数据库表中。每个表中部分信息如图5所示。
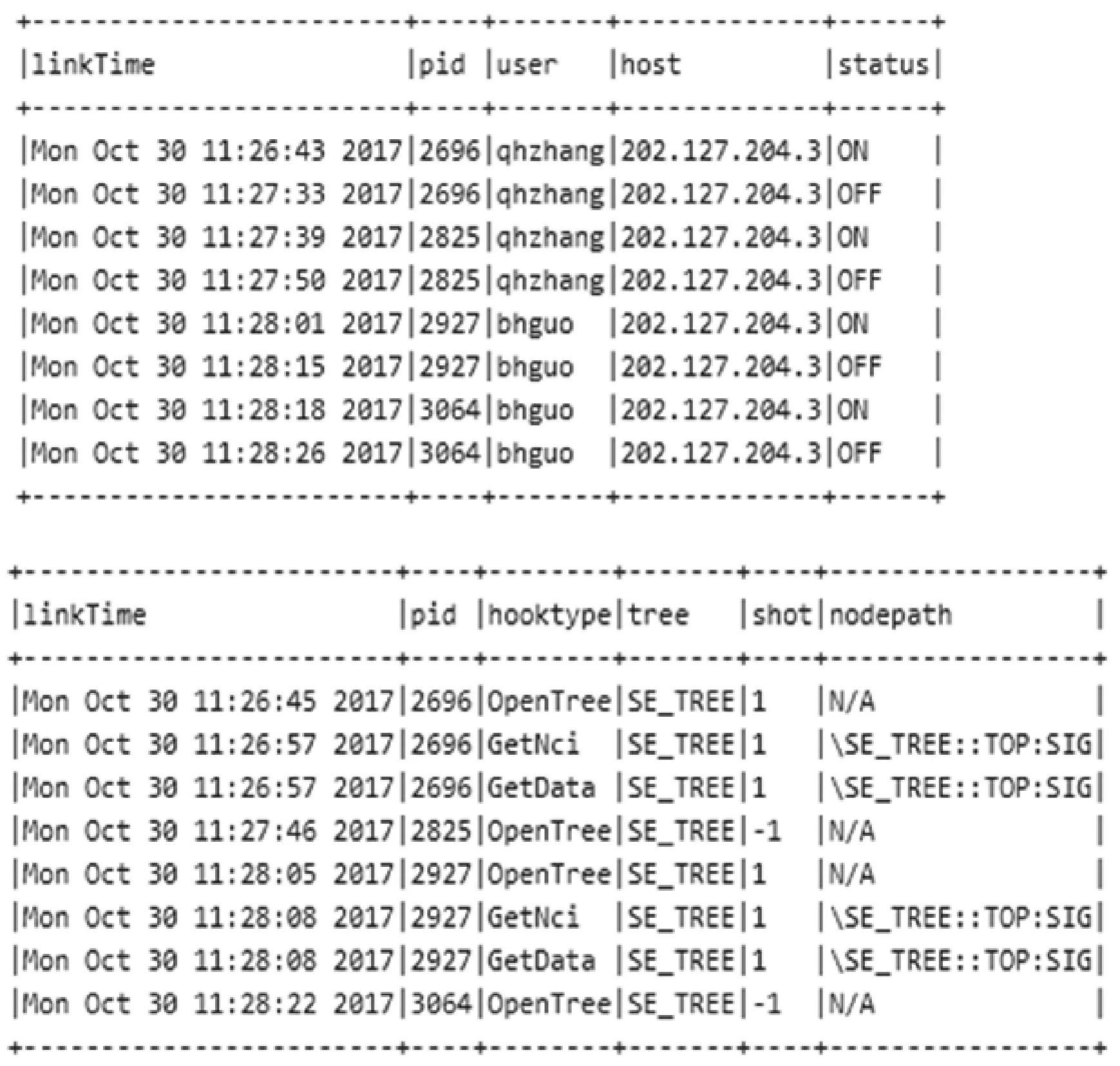
图5 离线处理结果
4 准实时数据处理
考虑到要从MDSplus日志中获取到实时的信息,从而即时地采取手段进行应对恶意的服务器攻击等行为。关于实时计算框架在Spark Streaming和Storm之间的选择,可以清楚地看见,Storm对于消息的处理是纯实时的,是一条一条消息进行处理,但是相比较于Spark Streaming吞吐量比较低[8]。基于以下几点的考虑,实时处理框架最终选择了Spark Streaming计算模型:
1) MDSplus日志分析不需要达到纯实时的精确度。
2) Spark生态对实时计算、离线批处理、交互式查询等业务功能可拓展性强。
3) Spark生态圈很容易和现有的Hadoop生态圈结合。
结合图4,很容易看到MDSplus的日志流的下一个目的地是Kafka,其中采用的缓冲通道Channel2是内存缓冲。为了避免Flume直接将日志文件直接发送给Spark Streaming处理导致的计算框架崩溃的情况,其将消息流先发送给Kafka这个消息中间件,日志数据以发布-订阅的模式实时记录到对应的topic里,Spark Streaming从相对应的Topic中读取数据流进行流数据计算。
在整个准实时数据处理流程中,采用Spark原生的编程语言Scala进行编程,降低了代码的冗余。处理的过程中,根据流数据的内容进行过滤,提取日志内容中有效字段。将原有的RDD(resilient distributed dataset)转换成以RDD为基础的分布式数据集的DataFrame形式。其中DataFrame应用于使用SQL处理数据的场景,在系统中采用了Spark的SQLContext类,将处理后的字段写入到MySQL数据库中。部分处理过程如下所示:
//开始处理整个日志内容
logs.foreachRDD(logs=>{
//创建一个sqlcontext单例模式
val sQLContext=
SQLContextSingleton.getInstance(logs.sparkContext)
import sQLContext.implicits._
//client日志内容处理
var flag =″OFF″
val logClient=logs.filter({s=>
s.contains(″Connection″)
}).map({k=>
k.split(″ ″)
}).map({t=>
if(t(9)==″received″)
flag=″ON″
else
flag=″OFF″
new client(
linkTime=t(0)+″ ″+t(1)+″ ″+t(2)+″ ″+t(3)+″ ″+t(4),
//后面转换成timeStamp
pid=t(7).replace(″)″,″″).toInt,
user=t(11).split(″@″)(0),
host=t(11).split(″@″)(1),
status=flag
)
}).toDF()
logClient.registerTempTable(″client″)
经过SparkStreaming处理后提取出来的字段放置在不同的DataFrame中,最终的结果存到MYSQL数据库中,供数据展示前端进行可视化。
5 数据可视化
无论是离线的数据处理,还是涉及到的实时数据处理,都需要将数据进行可视化,方便大家快速直观地了解目前MDSplus服务相关的信息。在前端的展示上采取了Zeppelin数据可视化工具和传统的Web展示工具两种方式相结合的手段。Zeppelin作为大数据可视化工具,不仅能够很好地支持Spark和Hadoop,还能和传统的MYSql相互连接。Web展现的方式采用了Echarts插件,将MDSplus服务器状态能够直观展现出来[9]。图6是Web端日志数据可视化的内容之一,显示当前各国在线人数以及当前最长在线的用户。
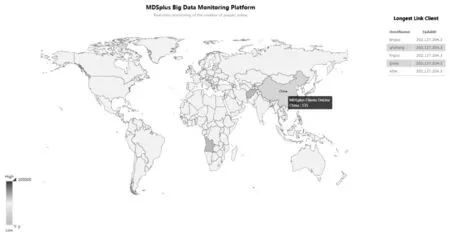
图6 数据可视化Web展示
6 系统测试与分析
系统测试过程中,采取多线程并发式模拟多用户访问MDSplus数据库,并对MDSplus数据库进行各种数据读取等操作。模拟并发用户量1 000多名,每个用户的操作平均产生20条日志,共计产生约3万条数据。测试采取两种不同的方式进行日志处理,分别是MapReduce方式的离线数据处理、Spark Streaming的准实时数据处理方式。表2是两种不同的处理方式的时间上的对比。
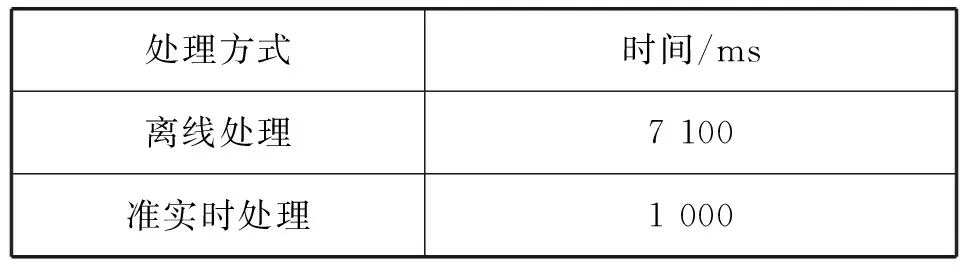
表2 MDSplus日志处理方式对比
由于离线数据在处理的过程中,需要启动系统的资源,所以耗费比较长的时间,但是在数据量达到海量时,该处理方式具有一定的优势。而准实时处理是按照时间切片进行数据拉取和处理,所以在实时性方面占有优势。该工作系第一次对MDSplus日志进行功能完善和日志信息处理的工作,目前还没有其他相关的工作对MDSplus进行日志完善和处理,属于原创性工作,所以暂时没有和其他的工作在时间和结果上进行对比。
7 结 语
本文介绍了利用大数据技术对EAST数据访问日志分析系统的设计和实践。该系统极大地方便了聚变科研人员对EAST实验数据的管理。首次对MDSplus的日志系统进行改进,完善了MDSplus日志信息。针对用户行为产生的海量日志数据,使用大数据技术中比较成熟的HadoopMR、SparkStreaming等技术很好地完成了日志的离线和在线的解析。这项工作不仅为 聚变领域中数据访问工作提供了借鉴,还对其他的海量日志的处理工作具有一定的参考价值。
