基于模型堆叠的上网行为日志用户画像方法
2018-09-19,,,
,,,
(1.山东科技大学 计算机科学与工程学院, 山东 青岛 266590;2.山东科技大学 电子通信与物理学院, 山东 青岛 266590)
随着互联网技术的不断发展和普及,网民的数量迅速上升,根据中国互联网络信息中心(CNNIC)发布的《第40次中国互联网发展状况统计报告》,截止2017年6月,我国网民规模达7.51亿。网民在遨游网络的同时,在网络中留下了海量的上网行为日志数据。分析上网行为日志数据,挖掘出用户兴趣、喜好、基本属性(性别、年龄等),可以为个性化推荐、精准营销、商业决断分析、风险控制等提供数据支持。
用户画像作为大数据技术的重要应用之一,为分析和挖掘上网行为日志数据提供了可靠的方法。用户画像是由交互设计之父Alan Cooper提出的[1],定义用户画像为真实用户的虚拟代表,根据一系列用户的真实数据来挖掘出目标用户。用户画像根据用户的基本属性、生活习惯和上网行为等信息,筛选出一类用户标签,给用户信息进行结构化处理。其目的是在多维度上构建用户的标签属性,利用这些标签属性构造用户真实的特征,可用于描述用户的兴趣、偏好、特征等。Fawcett T等[2]利用规则发现的方法在大量电话记录中发现欺诈行为标签,利用这些标签构建用户画像模型,该方法可以产生高可信度的报警。Adomavicius等[3]展示了针对个性化的用户画像模型,利用分类规则、关联规则等数据挖掘方法来发现潜藏在用户商品交易记录中的行为档案信息。Nasraoui等[4]根据动态网站的网络日志数据构建了动态可演化的用户行为画像模型,提出的网络使用日志挖掘框架可以挖掘、追踪和验证动态的多方面用户画像信息。陈志明等[5]基于“知乎”网站的数据,构建了基于用户基本属性、社交属性、兴趣属性和能力属性四个维度的动态用户画像模型,并通过对“知乎”网站PM2.5话题下1303位用户进行实证分析,得出的动态用户画像模型可以很好的区分用户的能力。Burger等[6]通过提取Twitter的个人简介中隐藏的特征标签构建用户画像方法,利用SVM[7]、朴素Bayes[8]和Balanced Winnow2[9]等分类器针对性别标签进行实验,得到了较好的实验效果。Iglesias等[10]根据用户在Unix Shell上的命令日志数据研究用户画像,获得了计算机用户的行为画像。郭光明[11]基于微博行为数据进行了用户信用画像的研究,利用带有L2正则的逻辑斯蒂回归分类器对用户进行分类,实验结果表明学习出的用户行为模式可以很好地解释用户的信用标签。但由于上网行为日志数据的复杂性,传统的用户画像方法不能很好的应用于上网行为日志数据中。本文通过分析校园网日志的特点,提出了一种多维度标签用户画像方法。结合五种特征选择算法构建多指标融合的特征选择方法,融合二元特征和关联规则特征提取方法构建标签库,在两层叠加式框架中组合支持向量机、随机森林、决策树、朴素贝叶斯和逻辑斯蒂回归五种单一分类器模型构建基于Stacking的用户画像。实验结果证实了本文用户画像方法比单一分类模型在识别用户性别、年级、年龄属性的准确性上有较大提高。
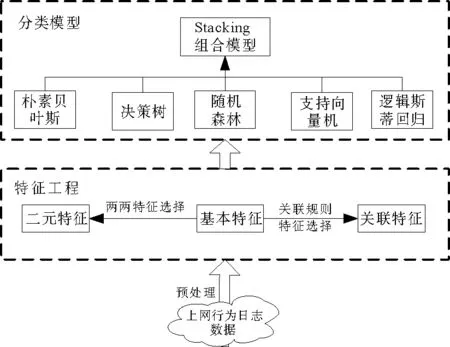
图1 用户画像框架Fig.1 The framework of user portrait
1 基于上网行为日志的用户画像框架
参考数据挖掘的一般研究流程框架,本研究基于上网行为日志的用户画像框架如图1所示,主要包括特征工程和分类模型两个关键环节。其中,特征工程是通过特征选择和特征提取(基本单特征、二元特征、关联规则特征)来构建标签库;而分类模型是利用支持向量机、逻辑斯蒂回归、决策树、随机森林和朴素贝叶斯五种单一分类器模型构建Stacking组合模型。
2 用户特征选择与提取
2.1 构建标签库
标签是用户特征的符号标识。标签具有两个重要特征,一是具有一定的种群性,可以在一定程度上抽样出概括事务的特征;二是可以使用符号来表示用户的某一类特征,这个符号可以是中文、英文,也可以是数字。标签库则是对标签进行集中管理,最终用于对用户行为、属性的标记。
本研究基于上网行为日志数据的特性构建了三级标签。一级标签分为学生基本属性和行为标签两部分,二级标签则是对一级标签的细分,三级标签是标签库中最详细的标签描述。标签库的分级层结构如图2所示。
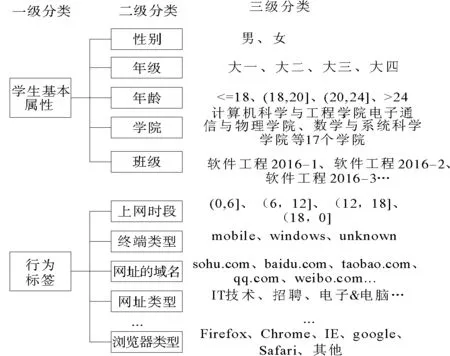
图2 标签库分级结构图Fig.2 Hierarchical structure map based on label Library
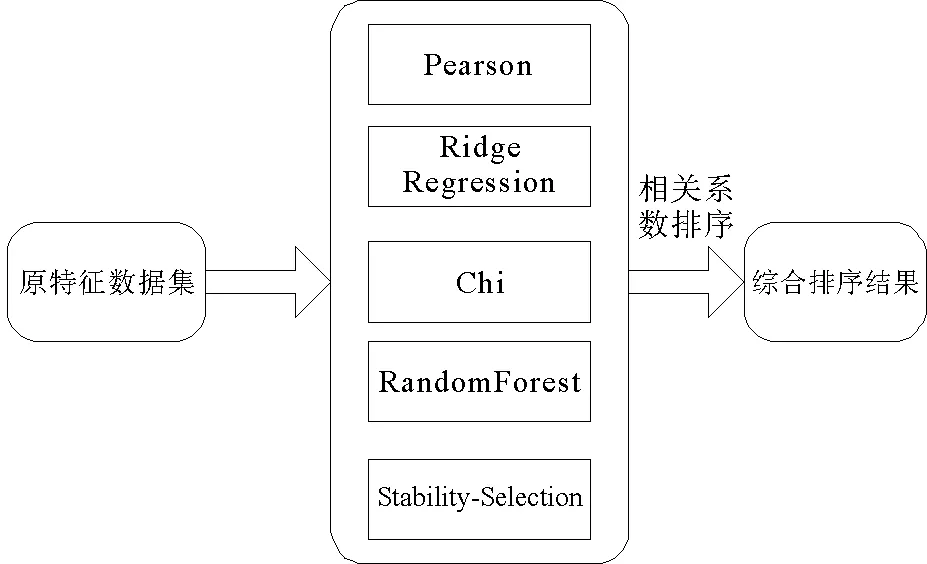
图3 特征选择方法架构图Fig.3 Architecture diagram of feature selection method
2.2 特征选择
特征选择[12]是模型识别的关键因素之一,特征选择结果的好坏直接影响分类结果的精度,因此需要有效的方法进行特征选择,提取对标签区分能力较高的特征,同时删除无用的噪声特征。
目前,特征选择的方法有很多,但是针对实际问题的研究仍存在各自不足。本文融合Pearson相关系数(皮尔森相关系数)[12]、Ridge Regression(岭回归)[13]、Chi(卡方检验)、RandomForest[14](随机森林)和Stability-Selection(基于随机lasso的稳定性选择)[15]五种不同类型的特征选择算法构建多指标融合的特征选择方法,有效地避免了一种特征选择方法的不稳定性。本文特征选择方法的架构如图3所示。
假设X=(X1,X2,…,Xk)为n维k列满秩矩阵,代表由k列不同属性特征组成的n维样本训练集合,其中Xi=(xi1,xi2,…,xin)T代表第i(i≤k)列训练样本。Y=(Y1,…,Yl)代表n维l列目标类向量(类标签),其中Yj= (y1,y2,…,yn)T代表第j(j≤l)列类标签。{F1,F2,F3,F4,F5}代表Pearson、Ridge Regression、Chi、RandomForest、Stability-Selection五种特征选择方法。coefj(j∈[1,5])代表由第j类特征选择方法得到的X与Y的相关系数集合。
由图3可以看出,本研究多指标融合的特征选择方法,首先利用五种特征选择算法得到X与Y的相关系数coefj,然后通过k种不同特征对相关系数进行排序,最后综合五种特征选择排序结果选择出排名前t的特征子集F_select。
本研究的特征选择算法如图1所示。
2.3 特征提取
本研究提取了三类特征用于训练用户画像模型: 基本特征、二元特征和关联特征。
1) 基本特征
首先对数据库数据属性进行筛选、离散化处理得到离散化特征;然后根据特征选择方法选择特征。假设离散化属性直接分为K个特征,例如性别直接划分为男、女两个特征。非离散化属性则采用等距离划分算法与等频率划分算法。
算法1: 多指标融合的特征选择算法
输入:属性特征X,标签特征Y,特征选择方法Methods={F1,F,2F3,F4,F5}。
输出:特征子集F_Select。
步骤:
1.F_Select←φ
2.Merge←φ//相同特征的相关系数排序集合
3.foreachFi∈Methodsdo
4.coefi←Fi(X,Y)
5.Sort(coefi)
6.Merge=Merge∪coefi(X,Y)
7.endfor
8.Sort(Merge)//综合5种特征选择结果排序
9.foreachi∈[1,t]//do选择排名前t的特征子集
10.F_Select=F_Select∪Merge[i]
11.endfor
12.returnF_Select//输出特征子集
等距离划分算法:在每个属性上,根据给定的参数把属性值划分为距离相等的断点段,假设某个属性的最大属性值为χmax,最小属性值为χmin,用户给定的参数为K,则断点间隔为δ
为此得到此属性上的断点为χmin+iδ(i=0,1,…,K)。
等频率划分算法:根据给定的参数K把m个对象分段,每段中有m/K个对象。首先将此属性在所有实例上的取值排序,然后每隔m/K取一个值作为断点。
2) 二元特征
提取二元特征是指对不同类型的特征进行两两组合后利用选定的特征选择算法进行特征选择。
假设离散化之前的特征集合为F={f1,f2,…,fm-1,fm},离散化之后的特征集合为F1={f1_1,f1_2,…,fk_1,fk_2,…,fk_e,…,fm-1_r,fm_t},其中,fm表示一共有m个特征,fk_e表示特征fk离散化后的第e个离散特征。则组合后的二元特征集合为F2={f1_1Xf2_1,…,f1_1Xfk_e,…,fm-1_rXfm_t}。
3) 关联特征
利用关联规则挖掘算法计算特征组合与目标属性Y的关联强度,然后为每个特征组合计算在该目标属性中不同取值上的关联强度熵,据此得到该特征组合的权重weight,根据所有特征权重集合results_weight排序得到排名前p的特征组合,用于后续的模型训练。本文提取关联特征的算法如算法2所示。
算法2中,LK代表频繁K项集,all_frequents代表频繁项集集合,apriori-gen(LK-1)函数根据Lk-1中的频繁项集连接、剪枝产生候选K项集CK;D是由基本特征X组成的数据集,函数Sort(results_weight)对所有关联特征根据权重进行排序。
得到上述三种特征后,按照如下方式构建模型的特征库,其中top_n表示选取排名前n的特征。
基本特征×top_n二元特征×top_m关联特征
(6)
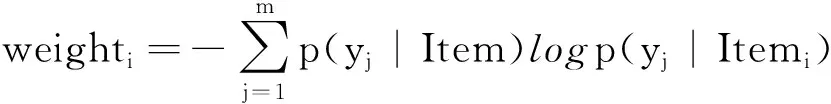
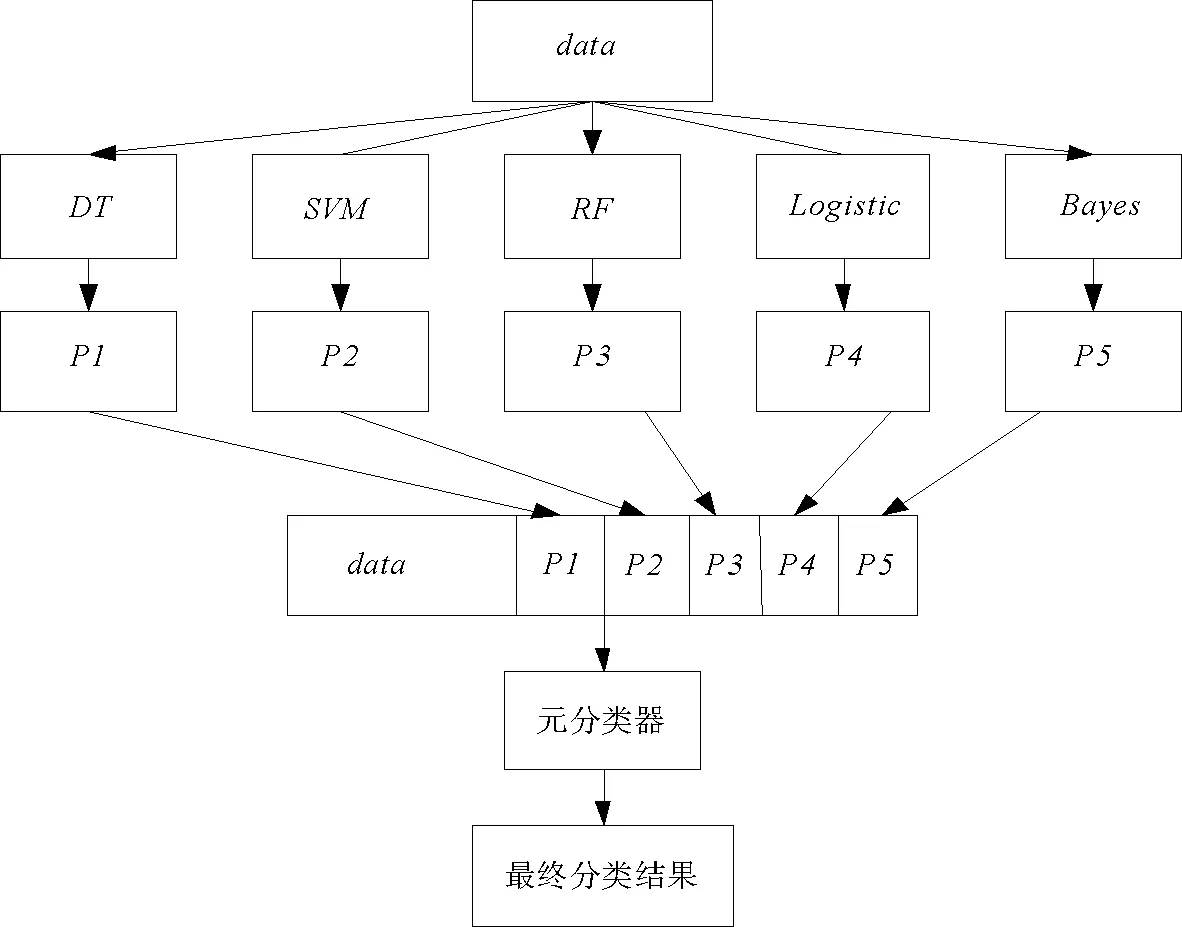
图4 基于Stacking的组合模型架构Fig.4 Architecture diagram of stacking model
3 Stacking组合模型
Stacking组合模型是指将多种分类器组合在一起来取得更好表现的一种集成学习模型。本文采用逻辑斯蒂回归(logistic regression,LR)、支持向量机(support vector machine,SVM),决策树(decision tree,DT),随机森林(random forest,RF)和Bayes(朴素贝叶斯)五种单一分类器模型构建Stacking组合模型,采用两层叠加式框架,第一层对数据集data进行K折交叉验证训练多个单一分类器模型,然后将第一层训练模型的输出加入原训练样本集作为输入,在元分类器下训练第二层模型,得到一个最终输出。其中单一分类器模型中预测效果最好的模型作为第二层模型训练的元分类器。基于Stacking的组合模型架构如图4所示。
Sacking算法如算法3所示。
算法3:Stacking模型组合算法
输入:数据集data,特征选择方法Models,交叉验证次数K。
输出:分类结果output
步骤:
1.output=φ
2.foreachclf∈Modelsdo
3.predicted=φ//得到候选K项集
4.foreath(train,test)∈cross_validation(K,data)do
5.clf.fit(train)//训练分类模型
6.predicted=predicted∪clf.predict(test)//得到预测结果
7.endfor
8.data=data∪predicted//将预测结果加入预测样本特征
9.endfor
10.output=bestmodel.fit(data)//对关联特征进行排序
11.returnoutput//输出分类结果
其中,函数cross_validation(K,data)是对数据集进行K折交叉验证,bestmodel表示第一层模型中分类效果最好的单一分类器模型,在第二层模型中做元分类器。
本文的Stoceking模型组合算法时间复杂度分析:假设每个单一分类模型的训练时间复杂度为O(M),由于在stacking模型组合过程中需使用K折交叉验证的方式训练每个单一分类模型,故Stacking模型组合算法的训练时间复杂度为O(Models·K·M)。
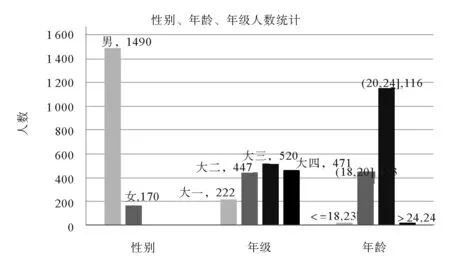
图5 性别、年级、年龄的人数分布图Fig.5 Population distribution of sex, grade and age
4 实验结果与分析
4.1 数据集描述
选取校园网访问行为日志作为实验数据,共有9 963个学生55个属性,约1 155.6万条日志数据。通过日志数据的筛选、离散化得到1 660个学生样本及91个标签。其中性别、年级和年龄的人数分布如图5所示。
通过图5可以看出性别标签中男女比例约为9:1,说明了男生上网人数比较多。四个年级中大一上网学生人数比较少,其余三个年级上网比例较为均匀。年龄标签属性中在(20,24]年龄范围中的学生上网人数比较多。由此发现日志行为数据的属性分布不均衡,故进行二元特征提取和关联特征提取是有意义的,不仅可以扩展原始数据,而且可以避免过拟合现象。
3.2 实验结果与分析
基于用户画像模型,为了显示不同特征集合的有效性,本文采用的评价指标主要有精确率(Precision)、召回率(Recall)和F-Measure值(F-Measure为Precision和Recall的加权调和均值)。
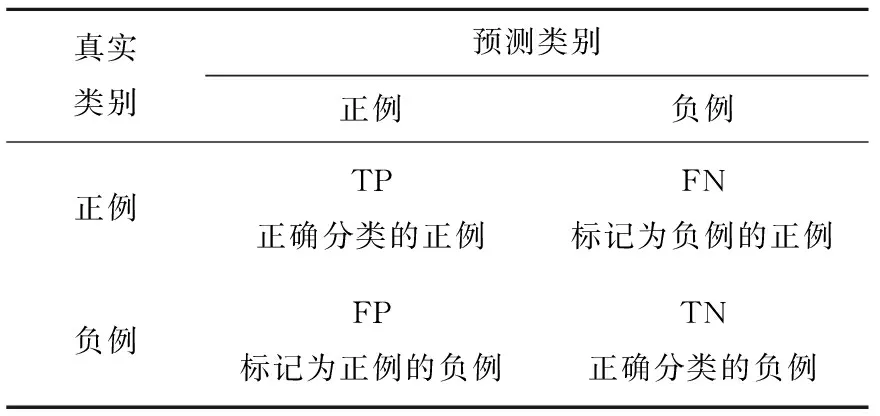
表1 混淆矩阵Tab.1 Confusion matrix
由表1混淆矩阵,得到精确率、召回率和F-Measure值的定义如下:
,
(7)
,
(8)
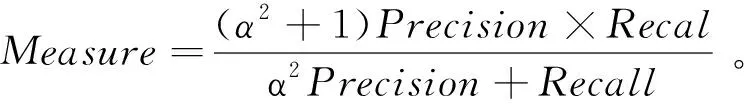
(9)
当参数α=1时,是常见的F1,即:
(10)
由于F1集成了Precision和Recall的值,故当F1较高时能更好地说明实验方法的有效性。
为验证本文提出方法的有效性,在性别、年级和年龄三个维度上进行实验。
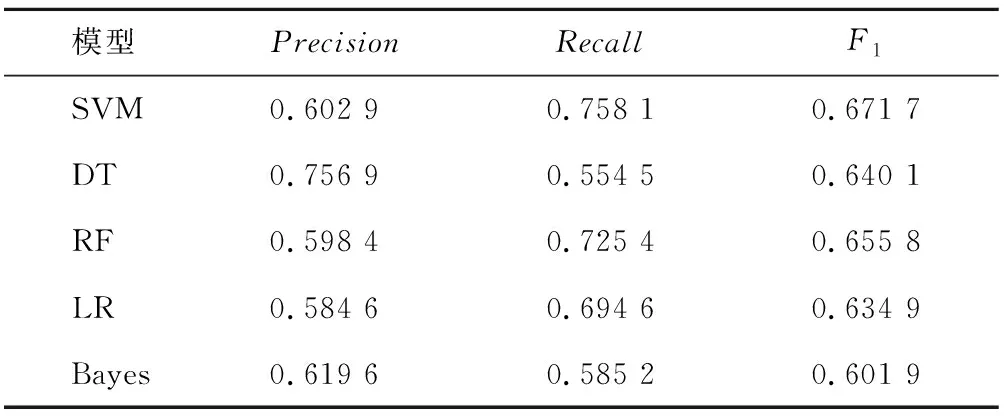
表2 基本特征下单一分类器对性别的分类实验最优结果Tab.2 The optimal results of a single classifier for gender classification under basicfeatures
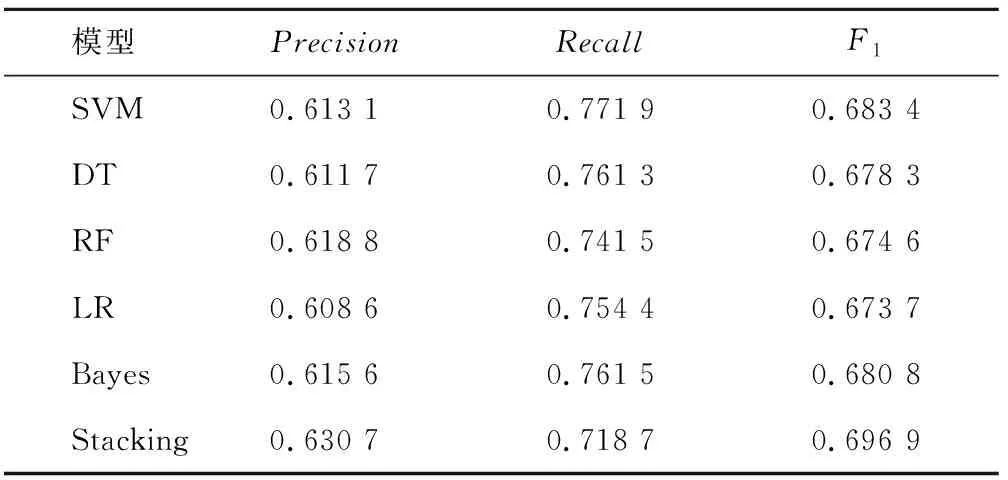
表3 特征组合下各分类器模型对性别分类的最优结果Tab.3 The optimal results of the classifier model for gender classification under the feature combination
1) 性别标签自动识别结果与分析
本组实验基于校园网行为日志数据,对性别标签进行用户画像研究。表2列出了基本特征下各单一分类器模型的最优实验结果。其中,RF和SVM对性别分类的实验结果较好,调和平均值F1均达到0.65。在组合标签下单一分类器模型和Stacking组合模型最优实验结果如表3所示。通过表2与表3对比发现每一个单一分类器模型在组合标签上的F1值均比基本标签上有较大提高,证明了特征标签可以提高对性别的分类结果。由于RF的结果最优,所以采用RF为Stacking组合模型第二层架构的元模型,表3中组合模型的F1值达到了实验的最优值0.696 9,可见,本文的用户画像方法可以提高性别预测的结果。
2) 年级标签自动识别结果与分析
本组实验基于校园网行为日志数据对年级标签进行用户画像研究。表4和表5分别给出了基本方法和用户画像方法下,对学生年级分类的模型最优结果。由表4可以看出,在基本特征下RF对年级的分类效果最好,其次是DT、LR、SVM,最差的是Bayes。由表5看出,在组合标签下,DT对年级的分类效果较好F1达到0.396 4,LR的分类效果最差。综合表4和表5可以得出:LR对年级的分类研究结果一般;相比基本标签,组合标签下模型的训练结果的F1值均有所提高,证明了组合标签有助于提高对年级的分类结果;由于单一分类器模型中DT的训练结果最好,故将DT用于组合模型中的第二层模型训练中,得到组合模型下对年级分类的F1值为0.412 1,相比单一分类器模型实验下的最好调和均值F1提升了12.28%,证明了Stacking组合模型对提高年级的准确性有显著的效果,在实际应用场景中可以更准确地捕获用户属性,更好地为校园网管理工作提供精准服务。故组合多种单一分类器的Stacking模型是有价值的。
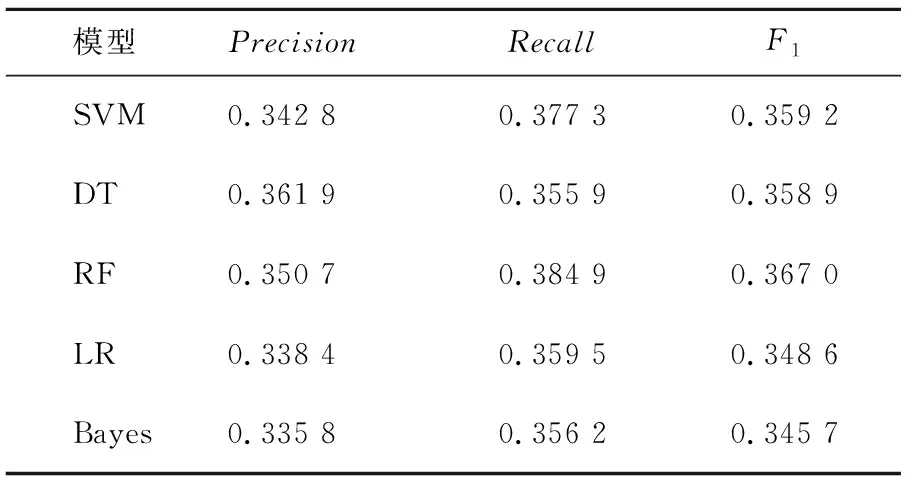
表4 基本特征下单一分类器对年级的分类实验最优结果Tab.4 The optimal results of a single classifier for grade classification under basic features
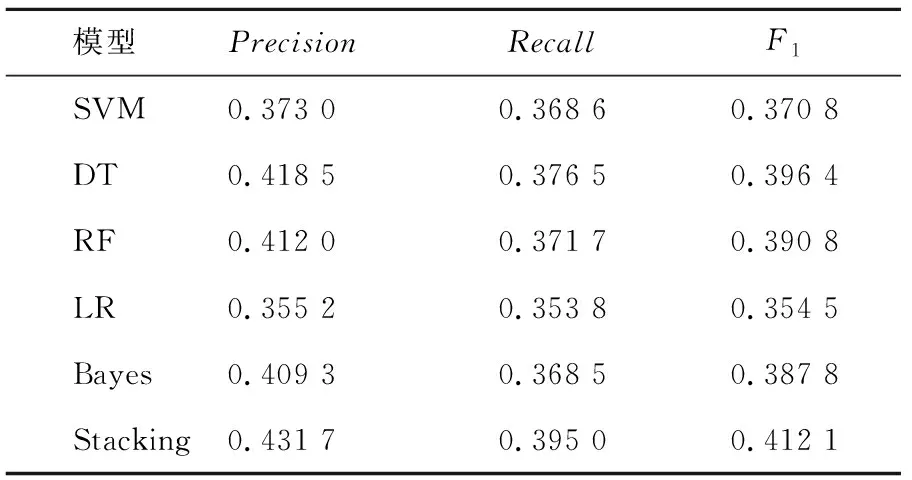
表5 特征组合下各分类器模型对年级分类的最优结果Tab.5 The optimal results of classifier model for grade classification under feature combination
通过对网络日志样本数据集中的学生用户性别和年级的分类实验结果分析可以得出,本文提出的方法比传统分类方法可以获得更好的属性预测结果。
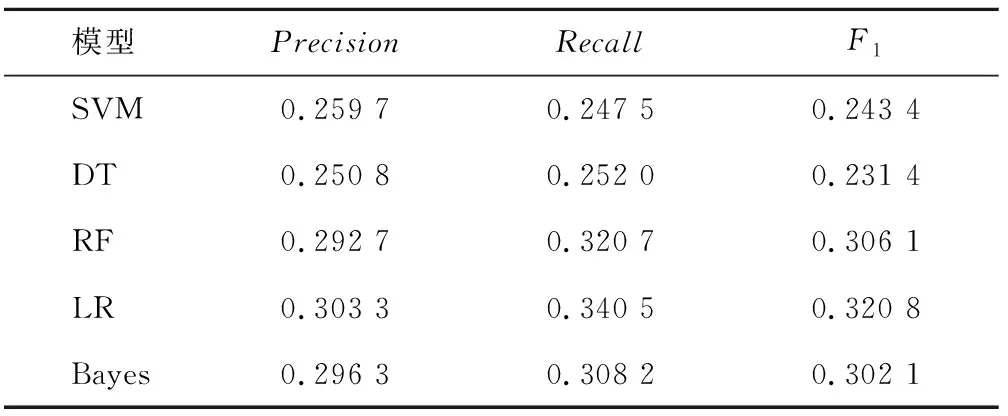
表6 基本特征下单一分类器对年龄的分类实验最优结果Tab.6 The Optimal results of a single classifier for age classification under basic features
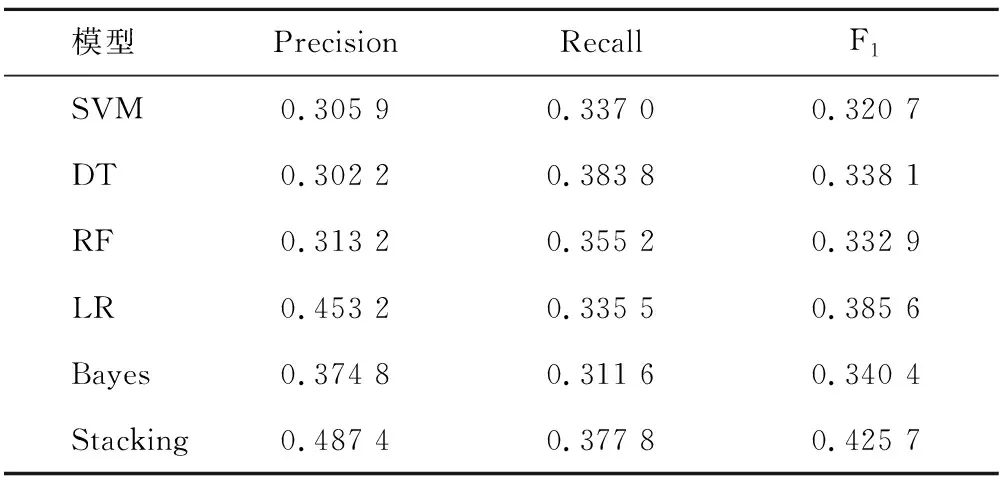
表7 特征组合下各分类器模型对年龄分类的最优结果Tab.7 The optimal results of the classifier model for age classification under the feature combination
3) 年龄标签自动识别结果与分析
该组实验基于校园网行为日志数据对年龄标签进行用户画像研究。表6和表7分类给出了传统的单一分类器模型和本文基于Stacking组合模型的用户画像方法下的实验最优结果。通过对比可以发现基于组合标签下的Stacking组合模型,对年龄的识别结果得到了提高,证明了组合标签以及Stacking组合模型对提高年龄分类结果是有效的。
4 结论
相对于传统的用户画像方法,本文提出的基于上网行为日志的用户画像方法,侧重于对用户标签进行组合,并利用Stacking组合模型来避免单一分类器模型的不足。通过在校园网行为日志数据上的实验分析,证明了本文所提出的基于上网行为日志的用户画像方法显著提升了对性别、年级、年龄属性的预测效果。下一步的工作中,将尝试在更大规模的数据集上,组合更多的单一分类器模型进行实验。
