基于CUDA加速的TLD算法实现
2018-09-19张旭标林尤添梁金伟
张旭标,卢 迪,林尤添,梁金伟
(哈尔滨理工大学电气与电子工程学院,哈尔滨 150000)
0 引言
目标跟踪在导航制导、医学诊断、智能监控等领域有着广泛的应用,目标跟踪算法[14]通常面临着光照变化、外观变形、背景相似干扰、快速移动和运动模糊等[5-7]几大难点。Kass等人提出的主动轮廓模型 (Snake模型)[8]不仅考虑图像的灰度信息,而且考虑了整体轮廓的几何信息,跟踪可靠性更强,但是Snake模型计算量较大且对于形变较大或快速移动的物体跟踪效果不够理想;Yizong Cheng改善的均值漂移算法 (Meanshift算法)[9]利用了梯度优化方法实现快速目标定位,对目标的变形、旋转等运动有较好的适用性,但在跟踪过程中没有利用目标在空间中的运动方向和运动速度信息,当周围环境存在干扰时 (如光线、遮挡 ),容易丢失目标[10]。Zdenek Kalal提出的 TLD算法[11-16],通过将传统的跟踪算法与检测算法相结合,并通过在线学习机制不断更新跟踪模块的显著特征点和检测模块的目标模型与相关参数,从而有效的解决目标物体发生形变、光照变化、尺度变化以及遮挡等问题,使得跟踪效果鲁棒性更好。
本文对传统的TLD算法进行了嵌入式设备的移植,加入了离线目标模型的初始化操作,并使用CUDA(Compute Unified Device Architecture)并行化编程方式对方差滤波器进行并行计算,缩减了原来的CPU单线程的计算时间;对通过集合分类器的样本使用聚类算法,将远离目标的图像框排除,提高跟踪鲁棒性。在保证跟踪效果的前提下,减少了资源的占有率,缩短了运行时间。
1 TLD跟踪算法原理
TLD算法主要由追踪、检测和学习3个部分组成,TLD算法的运行流程图如图1所示。用第一帧图像中手动圈定需要跟踪的目标物体对跟踪模块、检测模块进行初始化操作,从第二帧图像开始,跟踪-检测-学习3个模块互相补充,不断的对错误进行评估,从而实现目标在发生形变或被遮挡的情况下仍然能准确追踪的效果。
跟踪模块采用中值流跟踪法 (Median Flow),该算法本质上是基于前后误差估计 (forward-backward error)的金字塔LK光流法。其基本原理为:在上一帧的目标框中选择若干个像素点作为特征点,利用金字塔LK光流法在下一帧中寻找上一帧的特征点在当前帧中的对应位置,然后将这若干个特征点在相邻两帧之间的位移变换进行排序,得到位移变化的中值,将小于中值的50%的特征点作为下一帧的特征点,并依次进行下去,从而实现动态更新特征点的目的。跟踪器是用于跟踪连续帧间的运动,只有在物体始终可见时跟踪器才会有效,跟踪器根据物体在前一帧已知的位置估计在当前帧的位置,同时在估计过程中产生一条目标运动的轨迹作为学习模块的正样本。
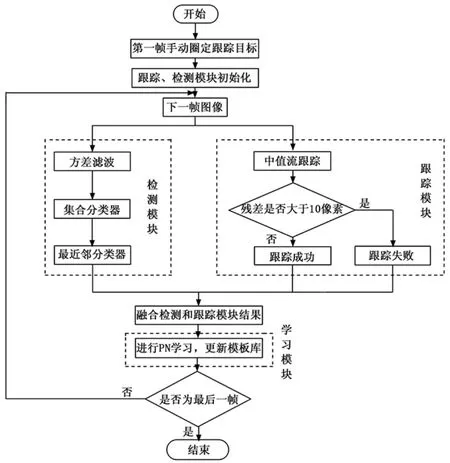
图1 TLD算法流程图
检测模块是将方差滤波器、集合分类器以及最近邻分类器级联。方差滤波器是计算图像片像素灰度值的方差,将方差小于原始图像片方差一半的样本标记为负;集合分类器是利用随机森林的形式,对图像片中任意选取的两点进行亮度值的比较,若A点的亮度大于B点的亮度,则特征值记为1,否则记为0,每选择一对新位置,就是一个新的特征值,随机森林的每个节点就是对一对像素点的比较。最近邻分类器是通过设定阈值对新样本进行相对相似度的计算,大于设定的阈值则认为是正样本。通过对每一帧的图像进行全面扫描,找到与目标物体相似的所有外观的位置,从检测产生的结果中生成正样本和负样本,传到学习模块。
学习模块采用一种半监督的机器学习算法P-N学习(P-N Learning),根据追踪模块和检测模块产生的正负样本,使用P专家 (P-expert)检出漏检 (正样本误分为负样本)的正样本,使用N专家 (N-expert)改正误检 (负样本误分为正样本)的正样本。由于每一帧图像内物体最多只可能出现在一个位置,且相邻帧间物体的运动是连续的,所以连续帧的位置可以构成一条较平滑的轨迹。P专家的作用是寻找数据在时间上的结构性,它利用追踪器的结果预测物体在t+1帧的位置。如果这个位置 (包围框)被检测器分类为负,P专家就把这个位置改为正。也就是说P专家要保证物体在连续帧上出现的位置可以构成连续的轨迹;N专家的作用是寻找数据在空间上的结构性,它把检测器产生的和P专家产生的所有正样本进行比较,选择出一个最可信的位置,保证物体最多只出现在一个位置上,把这个位置作为TLD算法的追踪结果。同时这个位置也用来重新初始化追踪器。
2 基于CUDA加速的TLD改进算法
将图1所示的TLD算法移植至嵌入式设备时,由于其串行运算特点,运算时间较长,不能满足跟踪系统的实时性要求。而目前随着GPU发展的越来越强大,其计算能力已经超越了通用的CPU,将CPU与GPU并用,进行协同处理,是计算行业发展大趋势,基于此NVIDIA发明CUDA运算平台。本文利用CUDA运算平台,采用多线程方式计算大量数据,缩短运算时间,以满足嵌入式设备运动目标跟踪系统的实时性要求。此外,本文在初始化操作中加入了离线目标模型模块,增强了TLD算法目标跟踪的自适应性能;采用基于K均值的聚类算法对经过集合分类器后的样本数据进行了聚类,降低最近邻分类器的阈值,从而提高检测率,最后将跟踪目标传输到C/S服务器的上位机端进行显示。基于CUDA加速的TLD算法框图如图2所示,其中虚线部分即为改进部分。

图2 基于CUDA平台的TLD算法框图
2.1 离线目标模型的初始化
图1所示TLD算法在每次启动时都需要手动选取跟踪目标,本文在此基础上加入离线目标模型的初始化操作过程。对于已圈定的跟踪目标,在第一次启动系统时进行目标的选取操作后,将目标模型进行保存,下次启动系统时,只需读入目标模型即可实现对跟踪模块和检测模块的初始化,增强了TLD算法的自适应性能。
2.2 CUDA平台下方差滤波器算法
在TLD算法中,检测模块功能是在视频当前帧中定位与目标模型匹配的目标图像,因此要构建扫描窗口扫描当前帧图像,并判断当前扫描窗口内是否存在目标图像。对图像使用不同尺寸的扫描窗 (scanning grid)进行逐行扫描时,就会在每一个位置产生一个包围框 (bounding box),包围框中确定出的图像区域即为图像片 (patch),所有图像片的集合进入到学习部分就成为了一个样本。经过扫描窗口产生的样本是无标签的样本,需要使用分类器对无标签的样本进行分类,从而确定其标签。
假设视频的分辨率为m×n,步长为k个像素,尺度缩放系数为l,则扫描过程中会产生m×n×l/k个图像片。图1所示TLD算法中采用的步长为10像素、尺度缩放系数有21种的扫描窗口策略,需要计算每一个扫描窗口与输入目标的重叠度,由此带来了大量的样本数据进行同样的计算。由于采用CPU单线程依次计算,势必导致了大量的时间损耗。
采用NVIDIA推出的CUDA运算平台,运用多线程方式计算大量的样本数据,具体步骤如下:
1)设置视频分辨率为240×180,选用尺度缩放系数有{0.16151f, 0.19381f, 0.23257f, 0.27908f, 0.33490f,0.40188f,0.48225f,0.57870f,0.69444f,0.83333f,1.0f,1.20000f, 1.44000f, 1.72800f, 2.07360f, 2.48832f,2.98598f,3.58318f,4.29982f,5.15978f,6.19174f} 共 21种,步长为10像素。则产生240×180×21÷10=90720个图像,记为N;
2)在CPU端计算帧图像积分以及帧图像平方的积分,分别记为I和II;
3)GPU每一个线程块中设置256个线程,则线程网络中产生 (N+255)/256个线程块;
4)将图像片数据量N、阈值T、帧图像积分I、帧图像平方的积分II传入GPU显存中;
5)调用核函数,每一个线程块下的每一个线程计算一个图像片的方差,并与阈值进行比较。大于阈值的是正样本,相应的数组下标的值记为1,小于阈值的是负样本,相应的数组下标的值记为0;
6)将显存中的数组数据从显存传回到内存中,将正负样本过滤分离,传入集合分类器。
2.3 集合分类器的聚类
方差滤波器过滤后的图像片传入集合分类器中,集合分类器中采用随机森林计算后验概率,根据阈值判定出需要进入最近邻分类器的正负样本。随机森林包含了10棵树,每棵树为完全二叉树,每棵树都包含13个节点,每个节点作为一个特征,每个节点是一个像素对的比较,每个像素对的采点位置是通过第一帧初始化随机生成的,并且互相垂直,将13个点的值统计做成一个13位的二进制数字从而进行后验概率的统计计算。若该图像区域的后验概率平均值大于设定的阈值,则判定为正样本,否则判定为负样本。
在实际情况中,集合分类器所表示的是目标的大概位置,能很好的表示物体的位置,最近邻分类器利用保守相似度和相关相似度去判断是否能通过级联分类器,从而保证成功获得目标。为了提高精度,提高识别度,在集合分类器后进行K均值聚类,对通过集合分类器的相关性大的图像片进行聚合,将远离目标的图像片去除,降低最近邻分类器阈值,在综合出新的目标图像片后传入到最近邻分类器中进行评估。
具体步骤如下:
1)提取出所有通过集合分类器的每个样本的中心坐标点;
2)将当前样本的中心坐标点与其他的样本中心坐标点做差得到一系列的距离值;
3)对每个样本求得的所有距离值取平均,作为该样本的参考值;
4)将参考值由小到大进行排序,取出前1/2的样本进行聚类,若样本数量超过50个,则只取前50个样本;
5)降低最近邻分类器的阈值,对新目标进行分类。
2.4 客户端/服务器的设计
客户端/服务器 (C/S)部分采用socket网络编程技术,通过TCP/IP协议编写基于P2P模型的客户端和服务器精灵进程,实时的向指定路径写入和读取数据。
在实际情况中,保证系统服务器平台的鲁棒性,系统采用了如下几种技术细节保证高效性及扩展性:
1)采用Reactor模式事件处理机制,利用主进程作为监听网络事件,如果有事件发生,则通过主进程利用管道技术通知并分发到各个处理进程。相比于Select的I/O复用技术,为了突破网络端口的监听上数量上的限制,采用Epoll模型的边缘触发的ET模式提高系统的鲁棒性。
2)在满足多目标跟踪的设计下,利用单例模式创建进程池,提高扩张性,单例设计模式保证进程池的唯一性,进程池的维护减少了进程创建和销毁所带来的CPU负荷和内存的是使用情况。
3)系统在设计时,利用多进程技术和加权Round Robin算法对子线程的分发进行处理提高服务器的处理能力,完成了Reactor的主线程与Worker线程均衡分发,增加了理解性和简化了调试。Round Robin算法可以有效的解决单进程的任务负载过重时,保证均衡负载。
4)使用管道统一事件源机制保证父子进程信号及信号处理函数尽可能快的被执行完毕,有效的防止服务器的父进程程序的提前退出的情况活宕机而导致产生僵尸进程。利用统一事件源管理机制可以有效的解决该问题。
5)本系统设计了采用高性能定时器,基于时间堆的心跳定时器,在对方心跳超时或者宕机的情况下,则自动杀死该进程,重新启动,保证了系统正常的运行。对于传统的降序链表定时器,升序链表定时器和基于hash的时间轮来说,最小堆定时器在空间上位O(1),相较于O(N)的hash时间轮的空间复杂度优越的多,当系统连接数很大的时候,最小堆的添加时间复杂度位O(lgn),相较于升降序链表定时器的O(n)时间复杂度要优越。对于执行效率来说,升序链表和最小堆定时器都是O(1)比时间轮定时器要好,为此系统采用最小堆位时间定时器。
6)本系统设计的日志系统,采用4级日志实时输出系统日志,降低了调试难度,提高了程序的可靠性。

表1 传统TLD算法与本文优化算法各个过程时间对比(ms)
7)为了使不同读写格式或不同平台能互相兼容、保证数据传输的完整性、提高传输的准确性,使用der编码的方式,对图像进行der格式的编码,转成统一的二进制格式。客户端通过读取到数据后进行der编码传输,服务器端接受到数据后进行der解码并显示。
3 实验结果
实验硬件平台为NVIDIA Jetson TK1嵌入式开发板,软件环境为Ubuntu 14.04.4+opencv 2.4.13+CUDA6.0。服务器端位于局域网内,配置为ubuntu 64位操作系统,intel core i7-4710HQ CPU@2.5 GHz,8 G内存,IP地址为192.168.92.134,网络环境如图3所示。TK1作为客户端,采用intel7260网卡作为数据传输媒介,使用传输端口为8000,以二进制形式实时的将图片传送到服务器端,客户端网络环境如图4所示。

图3 服务器端网络环境

图4 客户端网络环境
实验中选用书本作为跟踪目标,与传统TLD算法运行时间 (ms)对比如表1所示,实验结果表明,本文优化的TLD算法在保证了传统的TLD算法跟踪效果的情况下,大幅的缩短了时间。
4 结论
本文通过对传统TLD算法进行分析理解,将其移植到NVIDIA Jetson TK1嵌入式开发板中,并分别使用CUDA平台和距离聚类算法对方差分类器和集合分类器进行优化。实验结果表明,相比于传统的TLD算法,本文的优化算法的实时性更强。此外,本文设计了C/S服务器用于远程监控目标跟踪效果,配合嵌入式开发板,使得整个系统的应用范围更加广泛。
