基于深度主动学习的磁片表面缺陷检测
2018-09-19姚明海陈志浩
姚明海,陈志浩
(浙江工业大学信息工程学院,杭州 310023)
0 引言
随着机器化的发展,机器视觉技术在工业流水线的检测中发挥着越来越重要的作用。传统的磁片缺陷检测主要以人工提取特征为主,国内外很多学者做了这方面的研究。石聪等人通过基于边缘特征的金字塔匹配算法快速提取磁片边界,再结合各向异性滤波方法进行缺陷分割,然后根据几何形状识别特征进行分类,由于该算法比较依赖光照特性和磁片的缺陷形状,具有一定的局限性[1];杜柳青等人提出,定义扫描线梯度,将其标准差与扫描线灰度标准差构成特征向量,提出基于两类支持向量机的图像分割方法来提取缺陷,该方法只能针对特定行缺陷,缺乏通用性[2]。现有的传统方法主要可分为目标分割-人工特征提取-统计方法这三步骤[3]。由于磁片表面对比度低,磨痕纹理干扰和缺陷块小且亮度变化大等难点,想要有个通用方法分割出各种情况下的缺陷是十分困难的,很大程度上依靠个人经验,而且人工特征提取方法往往存在算法实用性不强的缺点,大多数方法都是针对特定缺陷或者特定光源场景条件下,缺乏通用性。
卷积神经网络 (convolutional neural networks,CNN)近几年来已经在图像、语音领域发挥着越来越重要的作用。神经网络只需要简单的提取目标预处理,而特征提取和统计分类都不需要人工干预,从而提高了模型的通用性。相比于传统神经网络的全连接网络,卷积神经网络拥有局部感受野、权值共享和降采样三大特性,因而大大减少了网络自由参数的个数。随后Krizhevsky Alex等人[4]提出ReLU作为激活函数和Dropout层来防止过拟合,开启了深度学习的新时代。卷积神经网络已经应用到人脸识别、行人检测、车牌识别和自然语言处理等领域中,取得了一个接一个的突破性进展。
卷积神经网络庞大的网络参数离不开庞大的数据量进行支持,而且传统的监督学习方法做分类的时候,往往是训练样本规模越大,分类的效果就越好。然而实验过程和实际生产中发现,庞大的数据量获取容易但人工标签成本高,有些数据可能还需要领域内的专家才能完成,不可能实现快速或者低成本的数据标记。如何使尽可能少的训练样本达到或者接近完整带标签数据集的效果一直是图像分类的研究热点。主动学习通过一定的算法提取出未标记样本中分类困难的样本,往往这些样本是包含着更多分类信息,然后将挑选标记好的样本加入一起训练分类模型来提高模型的精确度。
针对上述问题,提出了一种基于深度主动学习的磁片表面缺陷检测方法。首先,结合边缘检测和模板匹配算法将磁片前景和背景进行分割;其次设计改进Inception-Resnet-v2深度网络进行训练;然后,由于实际生产中巨大数据量获取容易但人工标签成本高,提出一种改进的主动学习方法来克服这一难点;最后,通过实验证明,此方法提高了分类器精度,而且通过主动学习方法节约了大量人力标注成本。
1 算法实现
1.1 算法描述
如图1所示,基于深度主动学习的磁片表面缺陷检测方法主要分为图像预处理、CNN特征提取及分类、主动学习三部分。在图像预处理中将图像进行背景分割、图像增强和归一化处理、图像分块处理;卷积神经网络部分将进行自学习提取特征以及分类,将Inception-Resnet-v2网络根据实际情况进行尺寸上的修改;主动学习部分将参考“信息量”(用熵衡量)和“多样性”原则,在海量图像数据中挑选出更具有代表性的样本数据,从而快速达到分类器性能临界值,减少大量人力标注成本。
1.2 图像预处理
铁氧体磁片原图来自浙江省一磁片厂,采用basler工业相机拍摄了1050张磁片图片,分辨率为659×494,缺陷主要表现为工业处理或者流水线运行中边缘磕碰导致的“掉皮”,部分样本如图2所示,其中 (a),(b),(c),(d)为缺陷样本,(e),(f)为正常样本。图像预处理主要分为背景分割、感兴趣区域的图像增强和图像分块三步骤。
首先进行背景分割,将圆磁片和背景进行分离。本文采用的是结合边缘轮廓检测的模板匹配方法,由于磁片在流水线上运动时,光源与磁片存在各个角度,磁片周围存在一个较浅的黑色光晕,这时如果采用单纯的轮廓提取或者模板匹配方法往往会导致提取到带黑色光晕的感兴趣区域 (region of interest,ROI),存在一定偏差。本文根据圆磁片表面轮廓与背景像素差距较大的特点,通过轮廓提取方法,找到轮廓并加黑像素,加深这种像素偏差,生成新的模板,大大提高了模板匹配的准确度,感兴趣区域提取结果如图3所示。
接着,将提取到的圆磁片进行gammar校正,这是种符合韦伯定律的图像预处理方法,这样在进行人工标注时能一定程度上减少由人为主观误判带来的标注错误。

图1 算法流程图

图2 原始样图
然后进行图像分块,这是一种数据扩充的方法,同时由于缺陷面积小,这样也能突出缺陷特征。经过实验分析,为了使缺陷特征都能包含在一个窗口中,本文以圆心处18度扇形区域的外接矩形作为一个分块单元,每次以圆心旋转的步长为18度,然后截取成正方形,因为所有的“掉皮”缺陷都表现在磁片边缘上,如示意图4所示。这样每个分割窗口的重叠率为15.4%,还保留了轮廓信息,这样每个磁片图像能得到20个分块图像数据,所有的最终图像都经过均值化和归一化处理。事实证明,图像字块像素尺寸为48×48时能包含所有完整缺陷。图像分块处理不仅能大大扩大数据集,而且能完整的突出缺陷特征,减小后面CNN的网络参数。

图3 感兴趣区域
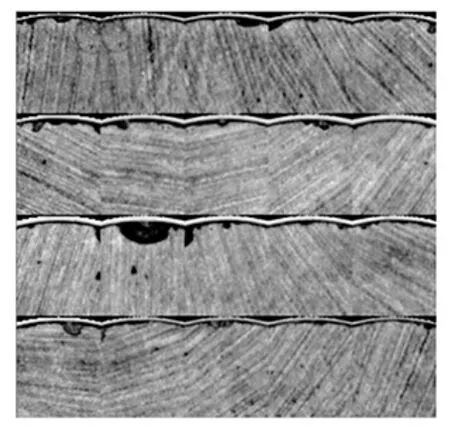
图4 子图像的分割
1.3 卷积神经网络
由于各个磁片表面由于打磨的原因导致反光情况各不相同,而且“掉皮”的深浅导致反光的缺陷有暗有亮,同时人工打磨过程产生的纹理也会大大影响到缺陷的检测精度,所以普通的人工特征提取方法效果不佳,并且人工提取特征时往往带有一些的主观能动性,这时特征的提取就需要一定的专家经验。而CNN在处理二维数字信号 (图像)时,特征提取层是通过自学习训练数据的方式进行特征提取,这样在学习时避免了显示的专家经验性特征抽取,从而大大提高了精度和鲁棒性。
本文采用 Inception-Resnet-v2[5]的网络模型,根据磁片尺寸太小,对网络模型进行了适当的调整。Inception-Resnet-v2网络与一般简单的神经网络相比存在很多优势。首先,继承Inception v1[6]中的多尺度堆叠,融合了1×1和3×3多种卷积的不同层特征,使高级特征和低级特征相互融合;其次,使用Network in Network[7]中提出的 1×1卷积核,不仅在前一层的学习表示上添加了非线性激励,提升了网络的表达能力,而且在卷积高通道层时,降低通道数,从而大大降低了维度;另外,结合Inception v3中的卷积分解,将7×7卷积核分解成一维的7×1卷积和1×7卷积,将3×3卷积核分解成一维的3×1卷积和1×3卷积,由此设计了35×35、17×17和8×8三个小模块,这样既可以进一步降低维度,加快计算速度,而且网络深度进一步增加,增加了网络的非线性性能,这效果在中间层十分突出;最后,网络加入了ResNet[8]中提出的残差模块,每一个节点学到的不再是参数本身,而是残差,ResNet的结构可以极大地加速训练,同时性能也得到提升,解决了网络层数加深带来的收敛问题。因为Inception-Resnet-v2的输入图像大小为299×299,而本文图像只有48×48,但是没有将尺寸直接进行缩放,而是在原论文进入分支前加了5个3×3卷积和1个4×4卷积,通道数和原论文相同,这样使得在进入网络分支前图像尺寸和原 Inception-Resnet-v2网络相同,方便网络设计。
1.4 主动学习
我们知道数据量大小决定了模型的精确度,那么是不是数据量越大精确度一直越大呢?大量深度学习的实验证明[9],模型精确度和训练样本的关系呈现着一般规律,大致走向曲线如图5所示,其中实线部分表示随机挑选的样本,虚线表示经过主动学习挑选的样本。在一开始训练集较少时,分类器的性能随着样本数的增加而快速增长,但当训练集达到了一定的临界值时,增长速度逐渐变缓,直至不变,由此说明分类器性能临界值与样本数据和分类器本身有关,而训练样本的选择能决定到达分类器性能临界值的速度。如此同时,如果用相同数量的更具代表性的样本进行训练时,会发现这个临界值更早的到来,所以如果用主动学习方法去挑选这些“难的”、“信息量大的”样本,这样分类器性能可以最更早的达到饱和,以节省大量的人力成本。
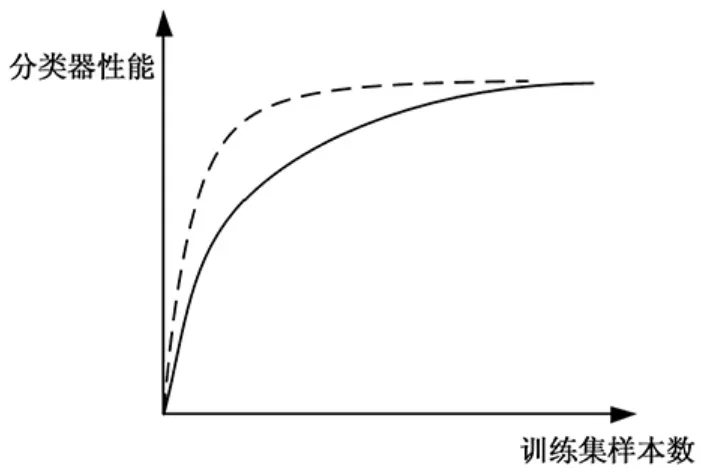
图5 训练集样本数与分类器精度关系示意图
本文的主动学习方法主要参考“信息量”(用熵衡量)和“多样性”来进行挑选样本[10]。基于“信息量”的标准有一个很直观的办法,就是基于熵的不确定采样方法,首先计算出测试样本在分类器中对于各个类的概率,然后根据信息熵的公式比较哪些样本所包含的信息量高,熵越大的样本代表不确定性越高,信息量越多。基于“多样性”挑选,就是比较已标注数据和未标注数据之间的相似度,将与已标注数据相似的样本作为简单样本,那么每次主动学习挑选那些差异比较大的样本作为“多样性”样本。
深度主动学习的具体算法流程如下:
1) 先随机选择样本数量为n的训练集L=(x1,xj,...xn),进行标注;
2) 使用训练集 L=(x1,xj,..xn) 来训练 Inception-Resnet-v2网络,得到网络参数w;
3)在样本数量为 m的未标定样本集为 U=(x1,xi,..xm)中,用式 (1) 计算出各个样本xi的信息熵S(y|xi,w);
S(y|xi,w)= - ∑y∈YP(y|xi,w)logP(y|xi,w)(1)
其中:y表示分类类别,Y={1,2,..}为所有可能的类别标号,P(y|xi,w)为在w参数中样本xi属于类别y的概率;
4)用式 (2)计算出各个样本xi相对于训练集L=(x1,xj,..xn) 的相似度 Ri;
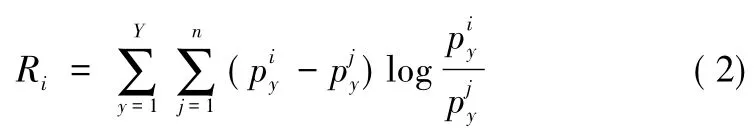
5)需要找到信息量大、相似度低的样本,所以设Di=进行D从大到小排序,在未标样本集U=i(x1,xi,..xm) 中挑选出 α 个的样本;
6) 将新得到的 α个样本加入 L=(x1,xj,..xn)中,代替原来的训练样本,重复 (2)、(3)、(4)、(5)、(6),直到分类器精度达到临界值或者未标注的样本集标注完为止;
2 实验结果
2.1 网络训练
本文实验设备是一台显卡为Tesla K40C的服务器,使用TensorFlow框架。训练时使用Xavier初始化网络参数,将AdamOptimizer作为优化器的优化算法,softmax交叉熵损失函数作为损失函数,网络训练的超参数如下:批处理大小(batch size)为128,最大迭代数 (max steps)为10 000,学习率 (learning rate)为0.001,学习率每经过5 000次迭代衰减50%,训练时的loss曲线如图6所示。
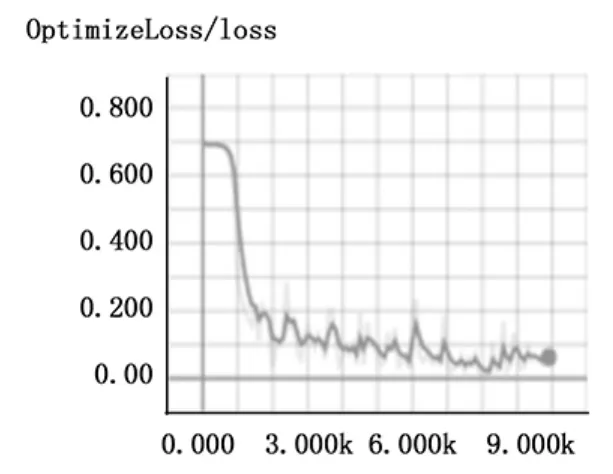
图6 训练时的loss曲线
2.2 实验结果
本文总共采集到1 050张磁片样本,切割完经筛选后共得到18 000张子图像,将14 000张作为训练集,2 000张作为验证数据,2 000张作为测试数据。
在精确度方面,本文将Inception-Resnet-v2网络与其他两个方法进行比较,一个是传统的支持向量机方法(SVM),另一个是简单的6层CNN网络,其中4层卷积层和2层池化层。各个方法的精确度比较如表1所示,Inception-Resnet-v2网络的精确度大大高于支持向量机这种传统的统计学方法,也高于简单的6层卷积神经网络。在实时性方面,由于Inception-Resnet-v2参数相对于简单的6层卷积神经网络要多很多,速度相对慢一些,但仍能满足工厂100 ms/个的要求,平均每次检测耗时60 ms/个。

表1 各分类器精度对比结果
2.3 主动学习结果
主动学习流程按1.4中所介绍的算法进行,取α=2 000,本文将随机挑选的样本来作为主动学习的对比实验,首先选取4 000个样本作为初始训练数据集,然后每次随机加入和经主动学习挑选后加入2 000个训练样本,共加入5轮样本。样本和精确度的关系图如图7所示,根据折点图可以看到,采用主动学习方法在9 000个训练样本时就比较接近最终准确率,最多可以节约样本标注约有3 000个样本,约能节省25%的人力标注成本。

图7 随机挑选和主动学习的比较图
3 结论
本文针对磁片表面“掉皮”缺陷进行了检测分析,使用Inception-Resnet-v2网络不仅不需要人工提取特征,增强了分类器的鲁棒性,而且精确度也是大幅度提高;另外针对数据上标签工作量大的情况,使用主动学习策略能减少标签数据,挑选更值得挑选的样本,提高工作效率。
但目前本文只能是针对“掉皮”缺陷,由于还缺乏其他缺陷的数据,笔者正在努力采集,下一步可以尝试增加缺陷种类,针对不同类别的缺陷对象,使此算法更加具有应用价值。同时,笔者也在考虑使用其他主动学习策略来进一步提高标签标注效率。
