计算机高速缓存相关概念的案例教学
2018-09-17赵佳利彭双和
赵佳利,彭双和,韩 静
(北京交通大学 智能交通数据安全与隐私保护技术北京市重点实验室,北京 100044)
0 引言
近年来,基于计算机微体系结构相关知识进行侧信道攻击[1]的研究成为热点之一。其中,基于计算机存储体系访问不同存储部件时间差异的侧信道攻击,利用Cache与主存之间的存取时间差异进行攻击,从而获取密码算法中的私钥信息,给信息安全造成了极大的威胁。
Cache[2]是一种高速缓冲存储器,用于保存CPU频繁使用的数据,解决CPU与内存之间的显著速度差异。在使用Cache技术的处理器上,当一条指令要访问内存的数据时,首先查询Cache缓存中是否有数据以及数据是否过期,如果数据未过期,则从Cache读出数据。处理器会定期回写Cache中的数据到内存。
目前主流的CPU Cache分为一级缓存[3](简称为L1)和二级缓存,部分还有三级缓存。一个四核三级缓存的缓存结构见图1,每一级缓存中存储的全部数据都是下一级缓存的一部分。CPU在读取数据时,首先会在一级缓存中寻找数据,如果没有找到就去二级缓存中寻找,如果还没有找到就去三级缓存中寻找,如果整个Cache都没有,则去内存中寻找,然后将数据缓存到Cache中。Cache的级别越低,离CPU越近,相应地速度越快,而存储容量越小。

图1 四核CPU三级缓存的缓存结构
这种侧信道攻击从理论上来讲,比较容易理解,但实现起来学生觉得无从下手,主要原因是教学涉及的实践环节比较少。
1 教学改革的重要性
在本科教学中,很多课程(如操作系统、计算机组成原理、系统结构等)都提到了Cache;在最终考核中,Cache也占一席之地。然而在实际教学中,教师往往只对Cache进行简单介绍,导致学生只学会了概念而没有理解原理,就进行下一步的学习;教师也将重点放在如何进行Cache分组等内容上。因此,学生难以理解和吃透这部分内容,后续想针对Cache进行进一步的研究存在一定的困难。
当前真正研究硬件和计算机微体系结构的人才越来越少,因此教学改革不仅是为了让学生理解Cache的相关概念,也想激发学生对计算机底层研究的兴趣。
2 相关原理介绍
2.1 预取技术
预取技术[4]的好坏很大程度上决定了CPU的性能,是CPU 设计者在设计CPU时需要重点考虑的问题,现代处理器大多实现了硬件预取。预取技术主要利用时间和空间局部性原理[5]:时间局部性指程序即将用到的指令/数据可能就是目前正在使用的指令/数据,即访问过的数据在未来仍有可能被访问;空间局部性指程序即将用到的指令/数据可能与目前正在使用的指令/数据在空间上相邻或者相近,即访问数据的邻近数据在未来可能会被访问。
CPU检测运行程序的存储访问模式,并且预测哪些数据下次会被访问。举例来说,固定步长预取[6]是:如果运行的程序有规律地读取数据,则CPU读取一次数据就进行预取。如果预取未命中,说明预取的地址与偏离的地址有一定的距离,CPU调整预取值;而当一次预取命中后,CPU会将固定偏移值的数据缓存到Cache中,使下一次读取不必再从内存中读取数据。
预取的目的是为了使CPU读取需要的数据时,直接命中缓存,从而避免从更慢的数据源访问,提升系统的性能。CPU将数据缓存到Cache中都是以Cache Line为单位的,Cache Line[7]是Cache的基本单位,一般为64字节。也就是说,一次缓存会缓存64字节的数据到Cache中。
2.2 Pointer-chase
现代CPU通常具有多种预取方式来提高性能,但在用时间测试Cache大小时往往会因为CPU的预取功能而使测试遇到阻碍,可以参考Afborchert[8]的pointer-chase消除CPU的预取。
Pointer-chase[9]是一种指针遍历机制,即用指针将下一个元素地址存放在上一个元素中,有多种方式,如线性的或者随机的。笔者采用随机方式,其原理见图2。
以10个元素的存储空间为例,每个元素都存有下一元素的地址,见图2。Mem[3]←&Mem[1],Mem[1]←&Mem[4],Mem[4]←&Mem[8]……这样,遍历Mem中元素时消除了CPU预取的发生。

图2 random-chase原理图
3 实验设计
实验的设计原则是让学生对Cache的各种概念(如:预取时Cache Line的大小,各级Cache的大小及其工作原理)有更深的认识。可根据Cache 的工作原理和特性设计如下的相关实验,通过实验,教师在上课时能更直观地讲解Cache及其相关知识内容。
论文设计实验的测试都基于Intel(R) Core(TM)i5-2400@3.10GHz的PC,其CPU相关信息见表1。

表1 测试机CPU配置信息 KB
3.1 实验一:Cache Line预取
本实验主要让学生理解Cache基本单元Cache Line的概念及其大小。依据计算机存储体系,数据访问时Cache命中的时间要比Cache未命中的时间短很多,而Cache预取是将一个Cache Line大小的字节缓存到Cache中。当数据第一次被访问时,一般都处于未命中状态。随后预取部件将该地址处的数据及其后续连续一个Cache Line的数据从内存中缓存到Cache中,因此接下来的63字节都是命中的状态。通过比较两次未命中的间隔可以得出Cache Line的大小。
实现过程:定义两个char型字符数组data1和data2,定义两个循环。循环1顺序访问data1中的数据,循环2每隔8步访问data2中的数据,time_access_no_flush是一个记录访问时间的函数。假设Cache Line的大小为64,则循环1两次未命中的时间间隔为63,而循环2两次未命中的时间间隔为7,通过记录访问时间可以得到Cache Line的大小,也验证了Cache预取,核心代码如下:

实验结果分析:随着数组下表的增长绘制访问时间得到图3,可以看出步长为1时,大概每隔63个点出现一个峰值,此时为Cache未命中状态,因此访问时间较长;而步长为8时,每隔7个点出现一次峰值,此时也为Cache未命中状态。由图3可以看出,CPU一次缓存一个Cache Line的大小是64字节,即Cache Line = 64B。
3.2 实验二:固定步长预取(两种方式)
本实验让学生理解CPU在访问数据时会进行固定步长数据的预取,因此会大大提高CPU访问数据的效率,分两种方式进行验证。
1)通过不同步长的平均访问时间验证预取。
CPU会进行固定步长的预取,不管步长为多少,CPU每次访问数据的时间应该是一样的。
实现过程:对于固定步长预取,首先定义一个整型数组times存放每次访问数据所需时间,设计二层循环。第一层循环代表步长逐渐增大,每次重新分配一段固定的内存用来数据访问,确保将要访问的数据不在Cache中;第二层循环则使用设置的步长间隔地访问数据,最后将得到的数据除以访问的次数得到平均一次访问时间。核心代码如下:


图3 Cache Line 大小测试结果
实验结果分析:随着步长的增长绘制实验数据平均访问时间得到图4。随着步长的增大,平均访问时间一直保持在较平稳的状态。因此固定步长访问数据时,CPU会对固定步长的数据进行预取从而优化性能。
2)通过比较随机步长和固定步长的访问时间来验证。
固定步长的平均访问时间是相同的,那么随机步长的访问时间是怎样的呢?根据猜想,固定步长时CPU能正确预取,但是随机步长时,CPU无法成功预取,因此每次访问应该都是未命中的情况。
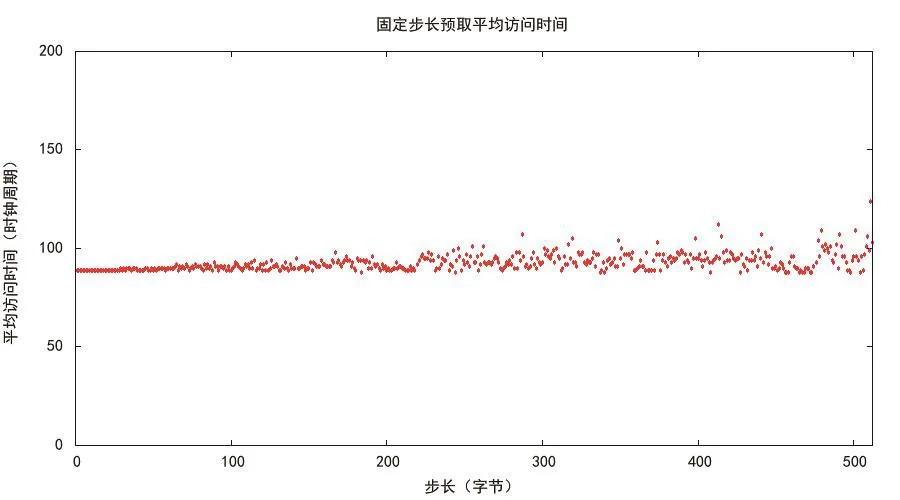
图4 固定步长预取平均访问时间
实现过程:定义循环1,为了消除Cache Line预取带来的影响,固定步长为64,记录每次访问数据所需的时间;定义循环2,将步长设置为大于64的随机数,但为了获得较多组数据,因此设置上限为320(可自定义),并将每次访问数据的时间记录下来。核心代码如下:

实验结果分析:随步长变化将固定步长和随机步长的平均访问时间绘制成图5。固定步长为64时,CPU在几次访问后能调整预取值,成功进行预取,之后一直都是Cache命中状态。而随机步长时,因为每次的步长都为随机值,CPU无法预取成功,因此一直都是Cache未命中状态。
3.3 实验三:各级Cache 大小
本实验是让学生理解Cache的缓存结构,目前通常分为三级缓存,Cache的级别越低,容量越小,速度越快。

图5 固定步长和随机步长的差异
在Cache Size测试时设计了几个实验,都无法得到Cache Size。经过分析,发现是预取引起的,因此参考了pointer-chase的random-chase机制,创建一个随机指针追逐的数组来消除CPU预取。每个数组元素存放的是下一个随机的数组元素地址,使用指针可以轻松地遍历数组元素。
random-chase的实现过程:首先定义一个索引数组indices,一个随机指针追逐数组len和二重指针memory,然后顺序赋值索引数组indices,使每个数组元素等于它的索引值。使用g++11的随机数生成器,随机交换元素的值,生成乱序的indices数组,然后根据乱序的索引数组indices赋值随机指针追逐数组len。使用二重指针memory以及打乱的indices索引为len的每个元素赋值,将memory[indices[i]]的地址赋值给memory[indices[i-1]],生成随机指针追逐数组len。核心代码如下:


通过random-chase机制,消除了Cache测试中预取带来的麻烦,接下来对Cache Line的大小进行测试,由于每级Cache的大小不同,并且每级Cache的访问速度也不同,越接近CPU的L1越快越小,以此类推。因此,对不同大小的数组进行大量访问(例如230次),根据数组的大小和Cache每级大小的关系[10](以3级Cache为例),可以分为以下4种情况。
(1)Array_Size (2)L1≤Array_Size (3)L2≤Array_Size (4)Array_Size>L3:数组大小大于L3,则整个Cache缓存不下所有数组,部分数据会存在内存中。访问内存的时间肯定大大高于访问Cache的时间,因此平均访问时间一定突增并随着Array_Size的变大而持续增大。 每个阶段代表每级Cache的平均访问时间,但每两个阶段之间会有一个时间上的突变,而临界点即是每级Cache的大小。 定义二重指针p,将随机指针追逐数组的首地址赋值给p,然后使用p进行SAMPLES次指针访问,记录时间,并除以SAMPLES得到平均一次访问的时间,核心代码如下: 实验结果分析:随着数组大小的增长绘制平均访问时间得到图6。可以看出,在数组大小为32KB之前,平均访问时间都是较小的平稳值,在32KB之后平均访问时间产生了变化,因此可得出L1级数据Cache的大小是32KB的结论;在256KB的时候,平均访问时间又增大,因此可得出L2级Cache的大小是256KB的结论;在6MB之后,平均访问时间迅速增大,因此可得出L3级Cache的大小是6MB的结论。由实验得到的结果与表1测试机器的配置完全吻合。 笔者就Cache的相关特性、预取、Cache Line的大小、各级Cache的大小和访问速度进行了实验设计和验证。Cache及其相关特性是本科计算机教学中相当重要的一块。对学生而言,可以自己动手设计几个实验获得计算机相关Cache信息,能更深刻地领会其中的原理,且动手参与实验能增加学生的思考能力,激发学生兴趣,增强学生的动手实践能力。 后续,笔者将依据虚拟地址与物理地址转换[11]、TLB相关原理[12]设计实验进行原理展示与验证,让学生对操作系统内部地址转换机制有更深层次的理解与探索。
4 结语
