基于修正KMV模型的上市公司信用风险测度
2018-09-15王传鹏李春蕾
王传鹏 李春蕾


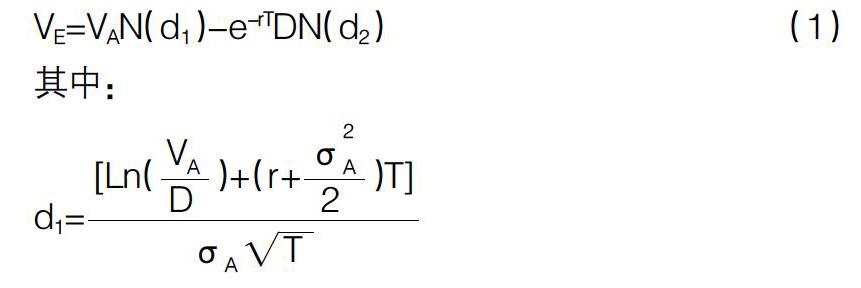
【摘 要】 我国上市公司的规模不断扩大,其信用风险整体呈现出上升趋势,信用风险的精确识别已成为金融机构和投资者非常关注且亟须解决的问题。文章选取KMV模型对上市企业信用风险进行度量,由于中国金融市场的特殊性,对经典KMV模型的部分参数进行了修正,选取2016年ST企业和非ST企业各30家作为数据样本,利用修正后的KMV模型对60家上市企业的信用风险进行度量,并对模型的有效性进行检验,结果表明:修正后的KMV模型能准确识别上市公司的信用风险,非ST企业的违约距离比ST企业的违约距离大,企业股权价值均低于其资产价值,资产价值波动率和违约距离负相关。对不同违约点下的违约距离和违约概率进行独立样本T检验,找出最优违约点应设定为短期负债+0.8倍长期负债,研究结果表明修正后的KMV模型对我国上市公司的信用风险度量有较高的适用性。
【关键词】 KMV模型; 上市公司; 信用风险; 违约距离; 违约概率
【中图分类号】 F832.5 【文献标识码】 A 【文章编号】 1004-5937(2018)13-0093-07
一、引言
我国证券市场始建于20世纪90年代,经过近30年的发展,上市企业数量逐渐发展壮大。截至2017年6月,我国证券市场有3 412家上市公司,同比增长8.3%,股票市场总值达64.6万亿元,同比增长42.61%。上市企业是我国证券市场的基石,企业质量的高低、行为的规范与否及其财务状况的好坏将直接影响到我国证券市场的发展和投资者的利益。当前,我国市场经济发展的时间还不长,企业的信用意识不够强烈,信用缺失现象普遍存在。2016年,中国证券监督管理委员会共对183起上市公司违规案件做出处罚,较上一年度增加21%,各种罚没款达42.83亿元,同比增长288%,实施市场禁入合计38人,同比增长81%[1]。我国证券市场的上市企业因财务虚假信息而被处理的现象屡禁不止,信用风险已成为金融机构和投资者非常关注且亟须解决的问题。
如何有效管理信用风险已成为整个金融市场最重要的任务之一,信用风险管理首先要对风险进行识别,准确地度量信用风险是识别风险的一种有效方法,本研究对经典KMV[2]模型的部分参数进行改进,选取上市超过两年且交易数据较为完整的企业作为样本,利用改进后的KMV模型对样本企业的信用风险进行计算,检验改进后模型是否有效,并找出参数最优值,本研究对度量我国上市企业信用风险进而提高风险管理水平具有参考价值。
二、KMV模型概述及其修正
(一)KMV模型的基本思想
KMV模型将公司资本作为标的资产,把公司权益作为看涨期权,负债作为看跌期权,股东选择是否持有股权类似于持有看涨期权。公司的全部负债为该期权的执行价格,资产价值为标的市场价格,如果该期权的执行价格低于其标的资产的市场价格时,行权可获利,也即公司负债低于资产价值,公司不会违约。否则,该期权的执行价格高于其标的资产的市场价格时,行权会亏损,不过权利金是其最大损失,此时公司负债高于资产价值,公司会违约。
(二)KMV模型的基本假设
布莱克—斯科尔斯—默顿期权定价理论是KMV模型的理论基础。KMV模型基本假设主要有:
1.企业的资本结构包括短期负债、长期负债和所有者权益。
2.股票价格是随机波动的,并服从对数正态分布,即dS=Sμdt+Sσdz。
3.股票价格和股票交易均是连续进行的,无风险利率已知,市场无风险套利机会。
4.企业的债务价值高于资产价值时,企业会选择违约;企业的债务价值低于资产价值时,企业不会违约。
(三)KMV模型的计算步骤
1.估算公司的资产价值及其波动率
KMV模型在布莱克—斯科尔斯—默顿期权定价模型基础上,得出标的资产市场价值和股权价值之间的关系如下:
上述公式中:VE表示股权价值;VA表示资产价值;D表示负债;r表示无风险利率;σE表示股价波动率;σA表示公司资产价值的波动率;T表示债务期限;N(*)表示标准正态分布函数。
假定公司股票每日收盘价格符合正态分布,本文采用日收益率来近似估算股权价值波动率,由于上市公司会进行派息和增发股票,故收盘价采用复权后的价格,具体计算方法如下:
其中:Pi、Pi-1为复权后的股票收盘价,那么股票日收益率的波动率为:
其中,μ为日收益率的均值,n为一年中的交易天数。
股价对数收益率的年波动率计算方法如下:
2.計算违约距离
KMV模型用违约距离(DD)来度量违约风险,违约距离的大小表达了违约可能性的大小。违约距离越大,企业违约的可能性就越小;否则,违约距离越小,企业违约可能性越大。违约距离与违约风险呈反比例关系。
具体来看,违约距离设定为企业资产价值与设定的违约点之间的差额,为使不同规模的企业具有可比性,该指标需经过标准化处理,公式如下:
上式中,E(VA)表示公司资产价值的期望值;DPT表示违约点,也就是企业需要偿还的债务;σA表示公司资产价值波动率。
KMV公司通过对大量样本进行统计分析,得出违约发生概率最大的点为:企业的短期负债与长期负债的一半之和,公式如下:
DPT=DS+0.5DL (5)
上式中,DS表示短期负债,DL表示长期负债。
3.计算预期违约概率
预期违约概率的计算方法通常分为两种:一种是EDF经验法,另一种是EDF理论法。
(1)EDF经验法
通过海量的历史违约数据,并根据KMV模型将观测到的违约频率与模型计算的违约距离进行比较,从而更加精确地计算出现实的违约概率值。具体的计算方法如下:
经验EDF=
(2)EDF理论法
EDF=N(-DD)=1-N(DD) (7)
上式中,N(*)表示标准正态分布函数。若假设公司的资产价值服从正态分布,则由计算出的违约距离来测算企业的预期违约概率值。
(四)KMV模型的修正
关于KMV模型,我国很多专家和学者进行了较为系统的研究,文献[3-6]对模型的有效性进行了验证,文献[7-10]对模型的参数进行了修正。本文试图在前人的基础上,找出模型在我国应用过程中存在的不足,并试图加以完善。
1.对违约距离进行修正
由于我国资本市场的特殊规定,上市的企业股权结构中包含流通股和非流通股两大部分,对于非流通股的理论价值,无法直接用当前的股价与股本简单乘积进行计算。本文针对这种情况,计算非流通股的賬面价值时采用每股净资产来代替当前股价。具体计算方法如下:
VE=流通股市场价值+非流通股市场价值 (8)
流通股市场价值=流通股收盘价P×流通股股数N
非流通股市场价值=每股净资产P'×非流通股股数N'
其中,流通股股数采用A股流通股股本,同时为了规避投机炒作等行为导致股票的异常波动,本文选取年度复权后日收盘价均值作为流通股收盘价。
2.对违约点进行修正
经典KMV模型通常将违约点设定为短期负债与长期负债的一半之和,这是KMV公司对近8 000家公司的违约数据进行实证研究得出的结果。然而,此违约点确定的数据来自美国及欧洲一些成熟的金融市场,我国金融市场起步晚,各种金融监管机制有待进一步健全,从历史来看,我国上市公司信用缺失情况较为严重,时有违约行为发生,与国际成熟市场存在一定差距。所以,在选取违约点时,需要对经典模型进行一定的修正。
本文预设置三个不同的违约点DPT1、DPT2、DPT3,并验证三个违约点所计算的违约距离,检验不同违约点下样本企业的违约数据是否存在显著的差异,最后选择一个最优违约点。
其中:
DPT1=STD+0.2LTD
DPT2=STD+0.5LTD
DPT3=STD+0.8LTD
三、实证研究
(一)样本的选取
通常,与正常上市企业相比,被ST或*ST处理的上市公司的信用风险更大一些,本文实证首先从上证和深证交易所选择样本,所选择的样本企业的上市时间超过两年,并且在2016年有较为完整的交易数据,分别筛选出30家被ST或*ST处理的企业和30家未被ST或*ST处理的企业。
(二)模型计算
1.公司资产价值及其波动率的计算
收集60只样本股票2016年全年的收盘价,并利用公式3计算股票价格的年波动率,企业负债和股权价值均来自各企业2016年财报,具体数据如表1所示。
债务偿还期设定为1年,负债采用企业资产负债表当中的总负债,无风险利率设定为人民银行公布的一年期整存整取基准利率1.5%。
利用MATLAB软件对上述数据进行计算,得到企业资产价值及其波动率,如表2所示。
2.违约距离和预期违约概率的计算
本文设置三个违约点DPT1、DPT2、DPT3,其中:DPT1=
STD+0.2LTD;DPT2=STD+0.5LTD;DPT3=STD+0.8LTD,应用公式4和公式7进行计算,不同违约点下企业的违约距离和预期违约率如表3和表4所示。
3.实证结果分析
对上述ST和非ST合计60家上市公司的实证研究结果进行分析,其信用风险特征如下:
(1)非ST企业的违约距离比ST企业的违约距离大,非ST企业的预期违约率低于ST企业,具体如图1、图2所示,这表明KMV模型对度量企业违约可能性是有效的。但也有例外的情况,如ST生化和ST明科的违约距离分别为2.872和2.9025,比部分非ST企业要高,见表3。这主要是由于企业被ST后经过一段时间的发展,整体实力较之前已有大幅度提高,因此准确估计企业的信用风险还需结合其他因素进行综合分析。
(2)样本企业资产价值均高于其股权价值。虽然60家企业来自不同行业,经营业务和企业规模都各具特点,但都呈现出资产价值高于股权价值的现象,这说明KMV模型的计算结果与企业具有较好发展前景、升值空间大的实际情况相符。
(3)资产价值波动率和违约距离呈现反比例关系。ST亚太、*ST智慧、*ST河化、*ST平能和*ST东数的资产价值波动率排前五位,违约距离正好排在最后五位(见表2),违约距离最高的两家企业中信证券和万华化学,其资产价值波动率最小(见表4)。整体情况如图3所示。
(4)借助SPSS软件对上述结果中的违约距离和违约概率进行独立样本T检验,验证ST企业和非ST企业的违约距离之间和违约概率之间是否存在显著性差异,结果如表5所示。
根据表5的检验结果,在5%显著性水平,DD3所对应的Sig值分别为0.029和0.037,均小于显著性水平,即拒绝ST公司和非ST公司的预期违约距离没有显著性差异的原假设,而DD1、DD2对应的Sig值均大于显著性水平,都不显著,即接受原假设。故本文选择将DPT3设置为最优违约点,即DPT3=STD+0.8×LTD。
四、结论
上市公司的信用风险水平是市场相关决策者进行投资的重要依据,准确计算上市公司的信用风险就成为一项重要的研究课题。本文借鉴国际上先进的信用风险度量模型——KMV模型(由于我国证券市场的特殊性,对现有KMV模型参数进行了修正),分别选择ST和非ST企业各30家作为数据样本,利用修正后的KMV模型对样本企业的信用风险进行计算,结果表明,修正后的KMV模型对上市公司的信用风险具有较强的识别能力,理论上为解决我国上市公司信用风险评估问题提供了有益补充,实践上有助于提高识别我国上市公司的信用度量能力,增强企业和投资者的风险防范能力,进而维护金融系统的稳定运行。主要结论有:
(1)KMV模型对ST和非ST上市公司的信用风险的测度呈现显著性差异,非ST企业的违约距离比ST企业的违约距离大,非ST企业的预期违约率低于ST企业。
(2)样本企业资产价值均高于其股权价值,企业的违约距离与该类企业的资产价值波动率呈反比。虽然样本源自不同行业,企业各自业务和规模都有区别,但均呈现出资产价值高于股权价值的现象,这说明KMV模型的計算结果与企业具有较好发展前景、升值空间大的实际情况相符。
(3)借助SPSS软件对不同违约点下的违约距离和违约概率进行独立样本T检验,最终得出适宜我国上市企业的最优违约点应设置为短期借款加0.8倍长期借款。
需要指出的是,本文虽对经典KMV模型的部分参数进行了修正,但原模型是基于一些假设条件进行推理的,参数的修正势必会对模型的结果有一定影响,这部分内容还有待进一步研究。此外,样本选取了部分上市企业(60家)和一定时间段内(2016年)的财务数据,将该方法推广到其他上市企业和其他时间段,还需进一步验证模型的有效性。
【参考文献】
[1] 朱宝琛.监管层亮剑违法违规行为斩断破坏市场稳定运行之手[EB/OL].http://www.ccSTock.cn/review/gushireping/2017-01-17/A1484586713562.html,2017-01-17.
[2] VASICEK O.A series expansion for the bivariate normal integral[M].KMV Corporation,1998:78-85.
[3] 张玲,杨贞柿,陈收.KMV模型在上市公司信用风险评价中的应用研究[J].系统工程,2004,22(11):84-89.
[4] 周沅帆.基于KMV模型对我国上市保险公司的信用风险度量[J].保险研究,2009(3):77-91.
[5] 曹萍.基于KMV模型的地方政府债券违约风险分析[J].证券市场导报,2015(8):39-44.
[6] 杨秀云,蒋园园,段珍珍.KMV模型在我国商业银行信用风险管理中的适用性分析及实证检验[J].财经理论与实践,2016(1):34-40.
[7] 王秀国,谢幽篁.基于CVaR和GARCH(1,1)的扩展KMV模型[J].系统工程,2012(12):26-32.
[8] 周海,王晓芳.地方政府债券信用风险研究——基于改进的KMV模型[J].审计与经济研究,2015(4):95-102.
[9] 冯敬海,田婧.基于遗传算法KMV模型的最优违约点确定[J].大连理工大学学报,2016(2):181-184.
[10] 类承曜,王星祺.类平台公司债信用风险度量及控制的实证研究——基于改进版LogiSTic-KMV混合模型[J].投资研究,2017(1):146-159.
