面向患者的智能医生框架研究
2018-09-12吴高巍任俊宏张似衡牛景昊张文生
谢 刚,吴高巍,任俊宏,张似衡,牛景昊,张文生+
1.中国科学院 自动化研究所,北京 100080
2.贵州师范大学 大数据与计算机科学学院,贵阳 550001
1 引言
由于医疗资源紧缺和分级诊疗实施困难,“就医难”、“就医贵”成为当今中国医患矛盾的焦点,如何借助互联网和人工智能来有效解决远程健康咨询与智能问诊成为国际人工智能应用的热点。
智能医生属于医疗领域自动问答的范畴。目前,一部分研究者研究基于传统检索技术的问答系统,如 MdeQA[1]、AskHERMES[2]、MiPACQ[3]、Enquire-Me[4]、HealthQA[5],这类系统利用关键词匹配技术对问题答案对进行检索;一部分研究者研究基于语义技术的问答系统,如MEANS[6]、AskCuebee[7]、QASSD[8]、Watson[9]这类系统从语义层面理解用户提出的问题,同时将数据以资源框架(resource description framework,RDF,https://baike.baidu.com/item/RDFS/9869002)三元组形式进行存储,从而实现医学知识的共享和利用。但在已有文献里,对中文医学领域的问答系统研究不多,尤其是针对患者的医学领域问答系统则更少,因此迫切需要针对患者的中文医学领域的问答系统。
由于患者缺乏相应的医学知识,对问题和意图的表述往往不清楚,同时在表述问题时口语化现象比较严重,因此怎样正确识别患者的意图和将口语化的临床表型数据转换成相应的医学术语将是医疗问答系统的一大挑战。本文在这样的需求下提出一种“一问一答”智能医生框架,该框架以自建的中文医学知识图谱和抓取的健康网站的问题答案对为基础,对用户的提问进行分析,根据问题分析出结果,对产生出来的候选答案采用多种问题评分策略和答案生成策略。实验表明该框架是有效的。该项成果已成功应用于某公司的健康咨询APP中。
本文组织结构如下:第2章介绍了智能医生架构;第3章对实验结果进行了描述;第4章总结全文。
2 智能医生架构
本文的智能医生架构如图1所示。该系统主要包括问题分析、候选答案生成和答案生成等三大模块。系统主要流程为:首先,系统对用户输入的问题进行分析;其次,根据问题分析的结果,生成候选答案;最后,将生成的答案返回给用户。下面对各模块进行相应的介绍。
2.1 知识库
知识库的构建是实现智能医生的第一步。本文构建的知识库包括词库、知识图谱、问题答案库和答案模板库等4类。其中,词库用于分词和词性标注,知识图谱用于生成语义三元组和答案生成,问题答案库和答案模板库也用于答案生成。
2.1.1 词库
本文用到的词库如下:
(1)通用词库:系统使用了上海林原信息科技有限公司的开源汉语言处理包(han language processing,HanLP,http://hanlp.linrunsoft.com/)中的通用词库。
(2)医学词库:包括疾病词库、检查词库、症状词库、手术词库、药品词库、医院词库、医学单位词库。
(3)自定义词库:疑问词词库、否定词词库、同义词库。
2.1.2 医学知识图谱
本文构建的医学知识图谱部分如图2所示。
可见,医学知识图谱是一张图G,由模式图、数据图和边构成,其形式化定义如下:
定义1(模式图)[10]模式图Gs=<Vs,Fs,Es>,其中:

Fig.1 Intelligent doctor architecture图1 智能医生框架
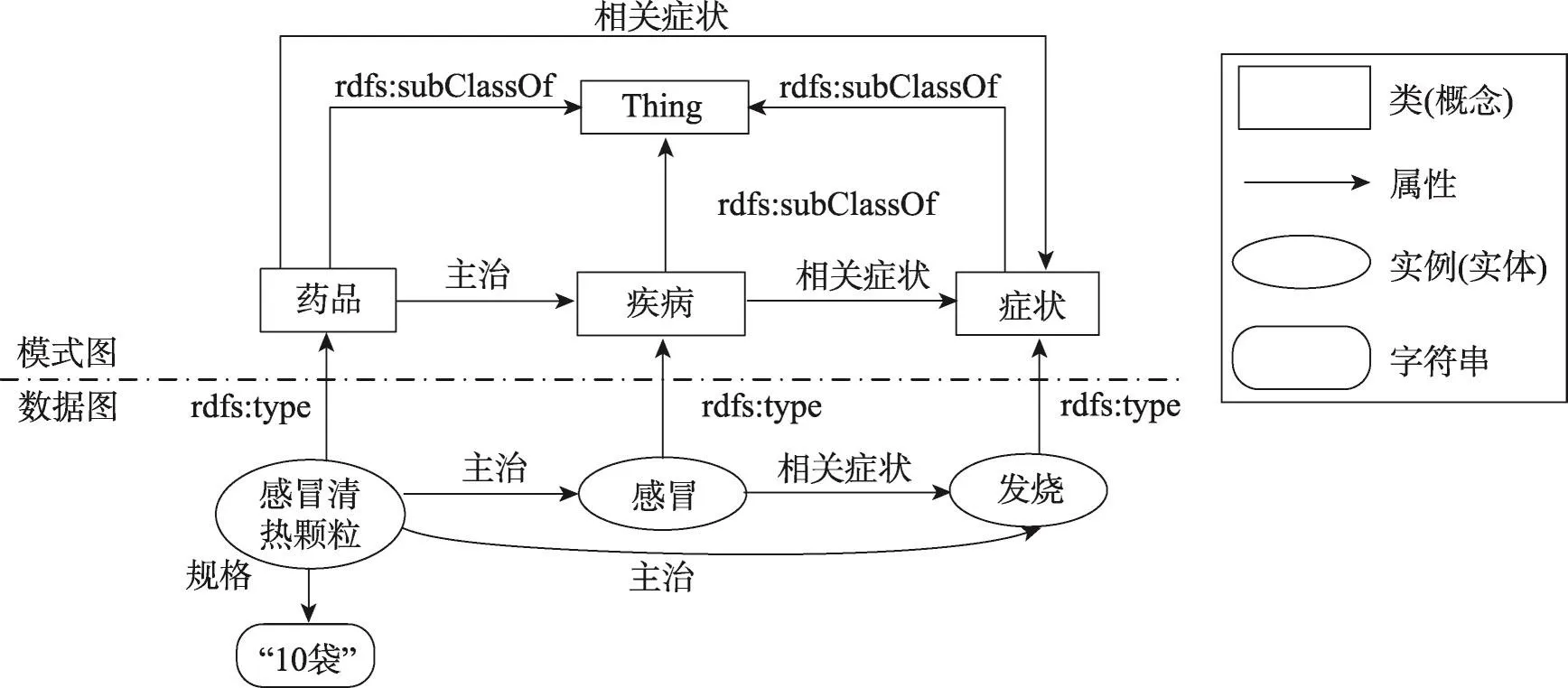
Fig.2 Example of knowledge graph图2 知识图谱示例
Vs表示模式图的顶点集,每个顶点表示一个医学概念,如药品、疾病等。
Fs表示模式图的边标记集,每个标记表示一种概念之间语义关系,其元素为像rdfs:subClassOf、rdfs:equivalentClass这类来自语义网络现有标准RDFS的属性和像“主治”这类用户自定义的属性。
Es表示模式图的边集,即Es={<vi,vj,Fk>|vi,vj∈Vs,Fk∈Fs(i=1,2,…,n,j=1,2,…,m,k=1,2,…,h)},<vi,vj,Fk>表示结点vi与vj具有关系Fk。如<医生,专家,rdf:subClassof>表示专家和医生是子类关系。
定义2(数据图)[10]数据图Gd=<Vd,Fd,Ed>,其中:
Vd表示数据图的顶点集,每个顶点要么表示一个概念的实例,如“感冒”为疾病的一个实例,要么表示属性的值,如“10袋”为药品规格这一属性的值。
Fd表示数据图的边标记集,定义与Fs相同。
Ed表示数据图的边集,即Ed={<vi,vj,Fk>|vi,vj∈Vd,Fk∈Fd(i=1,2,…,n,j=1,2,…,m,k=1,2,…,h)},<vi,vj,Fk>表示一个结点vi的属性Fk的值vj。例如<感冒,发烧,@相关症状”>表示“感冒”的相关症状为“发烧”。
定义3(知识图谱)[10]知识图谱G=<V,E>,其中:
V表示知识图谱的顶点集,包括模式图和数据图的顶点,即V=Vs∪Vd。
E表示知识图谱的边集,包括模式图和数据图的边及标记为rdf:type的边,即E=Ed∪Es∪{<vi,vj,rdf:type > |vi∈Vs,vj∈Vdi(i=1,2,…,n,j=1,2,…,m)}。
在定义1~定义3和现有本体[11-12]的基础上,本文首先利用protégé(https://protege.stanford.edu/)构建医疗领域知识图谱的模式图;其次,利用D2R(relational database to resource description framework,http://d2rq.org/d2r-server)将关系数据库转换成RDF三元组。目前已有1 126 214个三元组,构成知识图谱的数据图,并以RDF三元组存储在fuseki(http://jena.apache.org/documentation/fuseki2/index.html)服务器中。
2.1.3 问答库
本文的问题答案库来源于智能问医生、99健康网和名医在线的问答数据,通过人工整理了60万条,并以(编号,问题,答案)的形式存储在数据库管理系统中,其表结构如表1所示。

Table 1 Question answer table表1 问题答案表
2.1.4 模板库
为了更自然地把答案展示给用户,根据意图类别和是非问题的类别利用可扩展标记语言(extensible markup language,XML)共制定了112个答案模板(answermodel,AM)。例如询问概念定义的模板如下:
其中,<AM>和</AM>表示一个答案模板的开始和结束;<AMID>和</AMID>表示答案模板的编号;<parameters>和</parameters>表示答案模板需要的参数;<Answer_Model>和</Answer_Model>表示答案模板的内容;<EXAMPLE>和</EXAMPLE>表示该模板对应的问题实例。
2.2 问题分析
问题分析是整个智能医生的第一步,其结果对后续处理过程有很大影响。问题分析的结果表示为八元组 <It,Qc,Nel,N,Ss,I,TL,P>。其中:It表示问题类型,类型与表2中的类型一致;Qc表示问题主题类别,具体类别见表3;Nel表示命名实体集;N表示否定词集,N={(key,value)};Ss表示问题的依存关系集合;I表示疑问词;TL表示语义三元组集合;P表示意图。
问题分析的过程:用户输入问题后,(1)利用HanLP根据词库进行分词和词性标注;(2)利用词的标注信息得到命名实体集Nel、疑问词集I和依存关系集合Ss;(3)识别问题类型It、否定词集合N和问题主题类别Qc;(4)识别问题意图P;(5)生成语义三元组集合TL;(6)输出分析结果。其流程图如图3所示。下面对问题分析的各个模块进行介绍。
2.2.1 分词和词性标注
本文使用了HanLP对问题进行分词,同时利用新增的领域专业词库和自定义词库,对相应的词语重新进行词性标注,然后通过同义词替换操作,得到如下的问题向量表示:
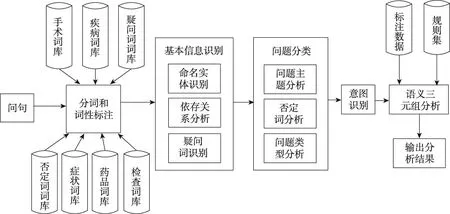
Fig.3 Question analysis flow chart图3 问句分析流程图
Q=(q1,q2,…,qn)
其中,qi为(word,nature),word表示单词本身,nature表示单词的词性。
例1“感冒了不发烧也不咳嗽应该吃什么药”对应的向量表示为((感冒,JB),(不,NW),(发烧,ZZ),(也,d),(不,NW),(咳嗽,ZZ),(应该,v),(吃,v),(什么药,WHT))。
2.2.2 命名实体识别
本文需要单独识别的实体包括疾病、症状、检查、药品、手术和医院。因为已经收集了大量的专业词汇,所以直接使用词性标注来进行命名实体识别,识别算法如下。
算法1命名实体识别算法
输入:问题向量Q。
输出:命名实体集Nel。
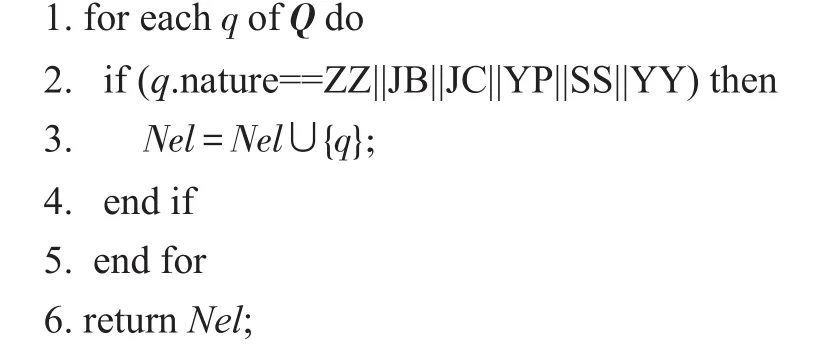
2.2.3 依存关系分析
本文使用了HanLP的条件随机场(conditional random field,CRF)依存句法分析器进行问题的依存关系分析。例1对应的依存关系如图4所示。

Fig.4 Dependency relation graph图4 依存关系图
从分析结果中可以看出,句子的核心词是“感冒”,主语是“感冒了不发烧也不咳嗽”,谓语是“应该吃”,宾语是“什么药”;感冒、发烧、咳嗽是并列关系;“不”是修饰“发烧”和“咳嗽”的否定词。
2.2.4 疑问词识别和问题类型分析
中文将疑问句分为特殊疑问句、是非疑问句和选择疑问句。根据统计,在医疗咨询方面是非问句占30%,选择问句占1%,特殊疑问句约69%。因此本文只讨论是非问句和特殊问句。首先提取是非问句和特殊疑问句的疑问词,然后按照表2所示的分类体系对疑问词进行分类。
算法2疑问词分析算法
输入:问题向量Q。
输出:疑问词集I和问题类型It。


Table 2 Classification system of interrogative表2 疑问词分类体系

利用上述算法可以得到例1的疑问词集I={(什么药,WHT)}和问题类型It=WHT。
2.2.5 否定词分析
在医学领域的信息咨询中,用户往往用否定词来排除某种情况,因此,需要对否定词进行正确分析。本文的否定词分析包括否定词的识别和否定词修饰的范围,其算法如下:
算法3否定词分析算法
输入:问题向量Q,命名实体集Nel和依存关系集Ss。
输出:否定词集N。


利用上述算法可以得到例1中的否定词集N={(不,发烧),(不,咳嗽)}。
2.2.6 问题主题分析
问题主题分析主要是分析句子的主题。本文按照表3的分类体系进行分类,利用支持向量机(support vector machine,SVM)[13]模型进行分类,首先对每个类别标注200个问题进行训练,然后随机挑选了100个问题进行测试,均取得了较好的效果。

Table 3 Classification system of subject表3 问题主题分类体系
按照上述的分类体系,例1的问题主题是“JB”。
2.2.7 意图识别
本文首先利用词、问题主题和问题类型之间的搭配关系和次序构造了如表4所示的254条规则;其次,利用规则构造如表5~表7所示的条件概率统计表;再次,根据如下公式得到相应的意图:

其中,ai表示第i类意图;qj表示Q中的第j个词。
如果根据上述公式计算出来的值为0,则利用SVM分类器进行分类。意图识别算法如下:

Table 4 Rule example表4 规则示例

Table 5 Probability table of intention example表5 意图概率表示例

Table 6 Conditional probability tablep(focus|intention)表6 条件概率表p(焦点词|意图)

Table 7 Conditional probability tablep(entity type|intention)表7 条件概率表p(实体类型|意图)
算法4意图识别算法
输入:Q,Nel,It,Qc;PT,意图的概率表(表5);CPT,条件概率表(表6、表7)。
输出:问题意图P。
1.for each focus wordqofQdo
2.利用相似度求q.word在规则集中的同义词f;
3.将f替换Q中的q.word
4.end for
5.利用表5~表7所示的概率表和式(1)计算P
6.ifPnot exist then采用SVM分类器对Q进行分类得到P;
7.end if
8.returnP;
利用上述算法识别出例1的意图为“药品”。
这种混合意图识别方法,既不需要分类模型对特征明显的问题进行训练,同时也不需要使用多个分类器达到多分类的效果,因而能够保证分类准确率的前提下,取得较好的时间效率。
2.2.8 语义三元组
本部分根据意图、问题主题类别生成语义三元组。本文根据语义三元组的作用,将语义三元组分为主三元组(main)、条件三元组(condition)和否定三元组(negative),其中主三元组对应于句子主干的语义,条件三元组是对主三元组的限制,对应于句子的肯定修饰成分,否定三元组也是对主三元组的限制,对应于句子的否定修饰成分。语义三元组的生成思想:首先,从命名实体集合和否定词中确定三元组的主语和类型;其次,将意图作为所有三元组的谓语。其具体生成算法如下:
算法5语义三元组生成算法
输入:P,Nel,Qc,N。
输出:TL。

利用上述算法得到的语义三元组列表TL={<(感冒,药品,?),main>,<(咳嗽,药品,?),negative>,<(咳嗽,药品,?),negative>}。
2.3 候选答案生成
候选答案生成模块的功能是生成候选答案。本文利用搜索、查询和推理3个技术来生成候选答案,因此本模块包括搜索、查询和推理3个子模块,其流程图如图5所示。
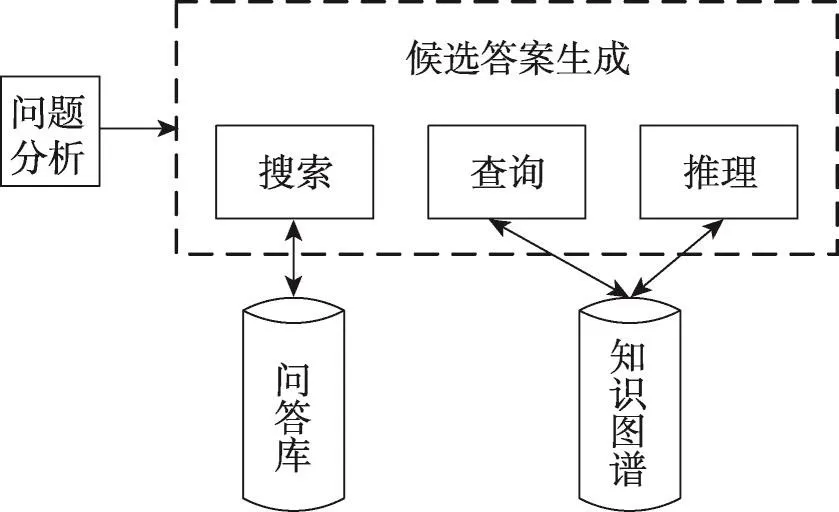
Fig.5 Candidate generation flow chart图5 候选答案生成流程图
2.3.1 搜索
本模块首先根据问题分析得出的命名实体集、主三元组、同义词,问题通过搜索引擎solr(http://lucene.apache.org/solr/)在问题答案库中搜索出排名前60的问题答案对。本模块的核心任务就是搜索语句的构造。本文构造的搜索语句形式如下:
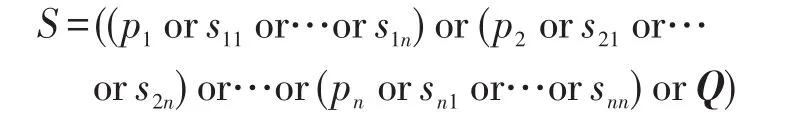
其中,pi∈Nel,sij为pi的同义词。
例1对应的查询语句为(感冒or(发烧or发热)or咳嗽or什么药or(感冒and不and发烧and也and不and咳嗽and应该and吃and什么药))。
2.3.2 查询
本模块根据文献[14]的思想首先将语义三元组转换成SPARQL查询语句,然后利用查询语句查询知识图谱。三元组转换成SPARQL是本模块的主要任务,其转换思想为:语义三元组的word对应于SPARQL语句的Subject,P对应于SPARQL语句的Predicate,?号对应于SPARQL语句的?object。转换后的SPARQL示例语句如下:

2.3.3 推理
所谓推理就是利用知识图谱中已有的知识推出新的知识。例如用户想问“腹痛和发烧有关系吗?”,假设知识图谱中只有症状和疾病的关系,此时就需要推理出症状和症状的关系。
在医疗领域大量用到这样的推理,尤其在疾病诊断当中。本文利用Jena(http://jena.apache.org/)推理机实现知识的推理。Jena推理机使用规则进行推理。Jena中的规则包括通用规则和自定义规则两类,其中通用规则为Jena自带的规则,这类规则主要是对知识的有效性进行检验,如模式图与数据图的一致性,不能对实际应用的领域知识进行推理;自定义规则是用户自己定义的领域知识,能对领域知识进行推理,因此,本文共定义20条规则,例如:
[rule1:(?A rdf:type症状),(?A疾病?B),(?B症状?C)->(?A相关?C)]
该规则说明如果症状A是疾病B的症状,而疾病B有症状C,则症状A与症状C相关。
2.4 答案生成
答案生成模块的功能是让智能医生将评分排名第一的答案展示给用户。答案生成的思想是:首先判断答案是否为问题答案对,如果是,则进入问题答案评分和排序;否则直接生成答案。该模块流程图如图6所示。

Fig.6 Answer generation flow chart图6 答案生成流程图
由图6可知,问题评分是答案生成的主要组成部分,其作用是计算候选答案的问题与用户的问题之间的相似度。现有的评分算法都是直接计算这两个问题的相似度。但这种方法只能说明问题之间的句子含有词语的相似度,而不能说明它们的语义相似度。本文利用多种评分算法从不同的侧面计算它们的相似度,从而使评分更准确。下面将介绍相关的评分算法。
2.4.1 问题词条匹配算法
该评分算法主要是计算候选答案的问题词条与用户的问题词条的匹配程度,该评分越高,说明与用户的问题越相似。假设t为问题Q中除疑问词以外的词条,即t={t1,t2,…,tn},则该算法的评分公式如下:

其中:

例2Q:“流产有什么危害?”
P1:“流产可能会导致什么?”
P2:“流产危害是什么”
根据式(2)可知,P2>P1,显然符合实际。
2.4.2 依存句法匹配算法
该算法主要是计算候选答案的问题与用户的问题句子结构的相似度,值越高,说明句子结构越类似。算法思想是:首先得到问题及所有候选答案的依存关系,然后根据公式得出评分。该算法的评分公式如下:

其中,Ps表示从候选答案问题中抽取出来的依存关系二元组集合;Qs表示从问题中抽取出来的依存关系二元组集合。


根据式(3)~式(5)可得,P1>P2,显然与实际相符。
2.4.3 文本余弦相似度算法
本文算法首先基于改进的TF-IDF(term frequencyinverse document frequency)词频技术[15]计算问题Q和候选答案问题的TF-IDF值向量,然后利用向量余弦相似度计算用户的问题和候选答案问题的相似度。假设QTF-IDF={x1,x2,…,xn},qTF-IDF={q1,q2,…,qn},其中xi、qi为相应词的TF-IDF值,则文本余弦相似度公式如下:
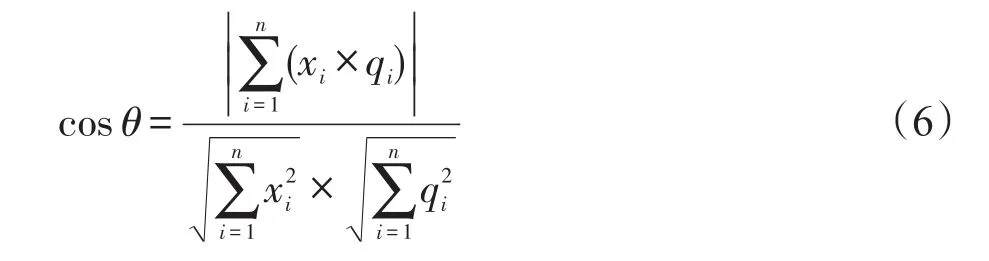
2.4.4 问题评分算法
本文将问题词条匹配算法、依存句法匹配算法和文本余弦相似度算法的结果按照式(7)计算出问题的最后得分:

其中,si为每个评分算法的评分;wi为评分算法的权重,本文通过实验发现,当wi为1/3时,效果最好。
3 实验与结果
本文利用Eclipse开发环境、Java开发语言和Jena框架,初步实现了“一问一答”的妇产科智能医生,并利用真实的妇产科问答语料测试了本文的系统。
3.1 度量标准
采用正确率(precision)来度量本系统的性能,计算公式如下:

3.2 数据集
本文使用真实的有关怀孕这一主题的问答语料447个问题作为实验数据集,并进行人工评测。这些问题基本涵盖了怀孕这一主题的全部类型和关系。实验数据集中的部分问题样例如表8所示。

Table 8 Question example表8 问句示例
3.3 实验和结果
本节首先将真实的语料共计447个问题分别输入计算机,得到相应的答案,其次将答案提交给医生进行审核,具体实验结果如表9所示。

Table 9 Experiment result表9 实验结果
通过分析实验结果发现,本系统的正确率为88.81%,在不正确的问题中有64%的错误是由于未能对是非疑问句进行准确分析造成的,如对“做输卵管通液能怀孕吗?”这样的问题分析不对;16%的错误是由于句子成分复杂和未对口语化的词语进行理解造成的,如句子“为什么那么多人说怀孕3个月以后就稳定了,没事了?”这样的问题分析不对;8%的错误是由于在否定词识别时未能对动词的否定进行识别造成的,如未能识别句子“怀孕不能吃西瓜吗?”中的否定词“不能”是修饰“吃”这个动词的;6%的错误是由于在答案中未对实体限制进行处理造成的,如“孕妇便秘怎么办?”的答案与“便秘怎么办”相同;4%的错误是由于知识库不完备造成的,例如未能识别句子“怀孕初期能吃桃子吗?”中的“桃子”;2%的错误是由于未能识别不连续的实体造成的,如未能将句子“输卵管为什么梗阻”中的实体识别为“输卵管堵塞”。
3.4 智能医生用户界面
本文提出的智能医生框架已经成功用于某公司的APP中,其用户界面如图7所示。
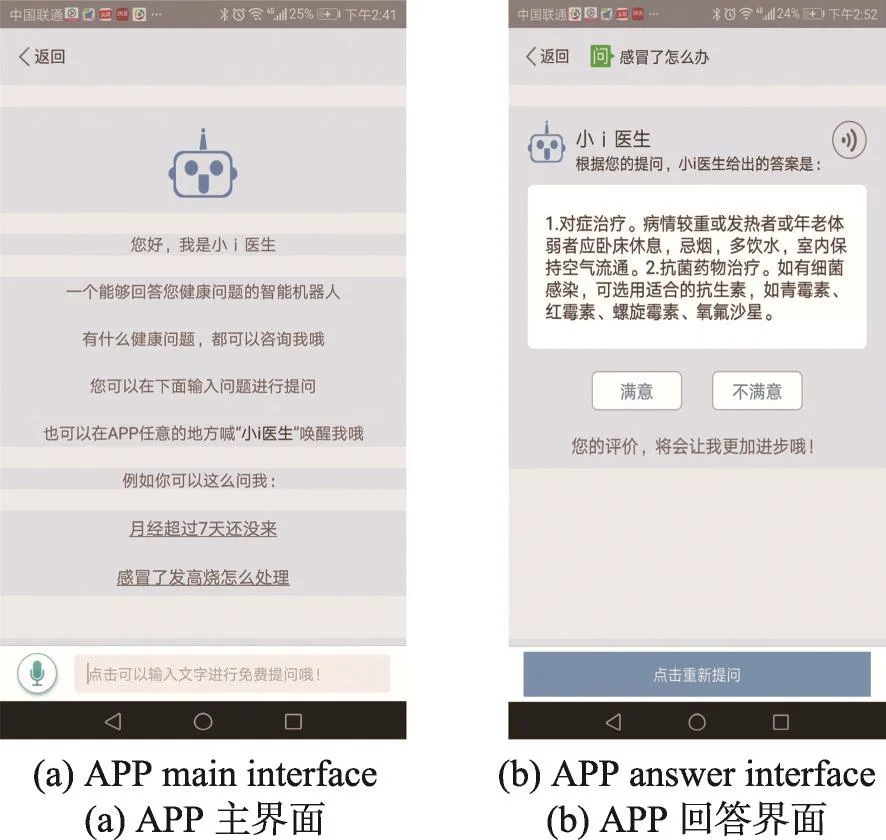
Fig.7 Users'interface图7 用户界面
4 总结
本文提出了一种“一问一答”的智能医生架构,该架构包括问题分析、候选答案生成和答案生成等三部分,并用真正语料对该架构进行了测试,实验结果表明,本文提出的架构的准确率达到80%以上,因此,该架构是有效的。但该智能医生的认知水平还有待提高,下一步将在以下几方面进行改进:(1)利用自动化技术对知识库进行扩充,增强知识库的自动更新能力;(2)利用关系抽取技术,对问题分析进行更精确的理解;(3)利用表示学习对意图和问题类型及主体进行识别;(4)增加推理规则对时间进行推理。
