一种自适应参数调整的水波优化算法
2018-09-07杜兆宏夏培淞邱飞岳朱会杰
杜兆宏,夏培淞, 邱飞岳,朱会杰
(浙江工业大学 教育科学与技术学院,杭州 310023) E-mail:476876541@qq.com
1 引 言
为了寻求解决工程优化问题更好的方法,国内外许多学者从自然、物理和社会等现象中受到启发,相继提出了如粒子群优化算法[1]、蚁群优化算法[2]、蝙蝠算法[3]、布谷鸟算法[4]等众多群体智能启发式算法.相较传统算法而言,由于群体智能启发式算法在解决优化问题时采用了特有的全局和局部搜索机制,所以其性能更为优越.近年来,群体智能算法得到了人们极大的关注,许多研究者已将其应用到生产调度、组合优化等许多领域中.例如,学者Rahmani M等[5]把蝙蝠算法应用到机器人自适应控制中,研究表明利用蝙蝠算法对机器人进行控制具有较好的性能;Mirjalili S[6]已将蜻蜓算法应用到潜艇螺旋桨优化中,结果表明蜻蜓算法在潜艇螺旋桨优化方面具有很好的效果;Liao W等[7]将人工萤火虫算法应用到无线传感器部署中,研究表明基于人工萤火虫算法的无线传感器部署具有较好的鲁棒性.
水波优化算法(Water Wave Optimization,WWO)是由国内学者郑宇军[8]于2015年所提出的一种新兴群体智能启发式算法,该算法通过模拟浅水波运动的方式,在高维空间进行高效的搜索寻优.WWO具有控制参数少、种群规模小、实现简单和计算开销量小等优点.目前,WWO已在TSP求解[9]和高铁调度[8]等优化问题中得到了应用,并且取得了较好的效果.
WWO自提出以来,由于其在求解优化问题中不俗的表现而得到许多研究人员的关注.张蓓等[10]最初从执行传播和折射操作两方面对水波优化算法的收敛性条件进行了分析,并用具体实验验证了两种收敛条件的正确性.Zheng接着又提出了一种种群规模可变的水波优化算法[11],在这种改进的水波优化算法中,在折射操作中引入了学习机制,从而更好地提升了算法的性能.之后,郑宇军等[12]在对软件形式化开发关键部位选取问题研究中,通过建立该问题的0-1规划约束模型,并设计了离散水波优化算法来对大型软件系统应用的实例,研究结果表明,离散水波优化算法解决该问题是可行的,并且其优化效果明显要优于BPSO、IBPSO、GA和BDE等算法.
尽管水波优化算法在许多优化问题上表现出优越的性能,但由于其还处于发展阶段,所以仍然还存在一些不足.正如文献[8]所述,水波算法在理论分析和性能方面还有很大改进的空间,比如其收敛速度较慢、收敛精度较低等不足.
为了进一步提升水波优化算法的性能,已有研究者从不同视角提出了一些有效改进水波优化算法的策略.例如,张杰峰等[13]提出了另一种种群规模可变的水波优化算法,在该改进的水波算法中,通过将原水波算法固定种群规模改为线性递减的种群规模,使算法在早期更好地支持全局搜索,并在后期更多的支持局部搜索开发,这种改进策略在一定程度上提升了算法的性能.吴秀丽等[14]针对水波优化算法在局部搜索方面存在的局限,提出了将局部搜索能力较强的单纯形法融入到水波算法中,同时在种群初始化中采用混沌种群初始化,在迭代过程中对种群进行混沌扰动等一系列策略来改进水波算法,从而有效提升了水波优化算法的收敛速度和搜索精度.
本文对水波优化算法搜索过程中各个阶段控制参数变化进行分析的基础上,提出了一种自适应参数调整的水波优化算法(LOGWWO),即在算法执行前期以较大的参数来支持算法进行全局搜索寻优,在算法执行后期则以较小的参数变化以支持算法进行局部精细化探索开发,更好的平衡算法的搜索机制,从而进一步提升算法的整体性能.
2 水波优化算法概述
2.1 基本原理
水波优化算法(Water Wave Optimization,WWO)是从浅水波运动模型解决优化问题中得到启发发展而来的一种群体智能启发式算法.在对优化问题进行求解时,WWO将要优化问题的搜索空间看作海床,其中每个解在水波优化算法中看作一个“水波”对象,每一个水波都具有一个波高h和波长λ,每个水波的适应度值与其距海床的垂直距离成反比.因此,水波如果离海床的距离越近,其适应度值也就越大,对应的水波的能量也越高,波高h越大,波长λ则越小(如图1所示),这样就使得算法能够在全局和局部搜索较优解和较差解,从而不断使水波朝着更优的解靠近,从而保证水波算法能够搜索到最优解.WWO是通过执行传播、碎浪和折射等3个操作来对所优化的问题进行全局搜索的,在种群初始化时,水波的波高一般设定为hmax,波长一般设为λ=0.5.

图1 深水区和浅水区不同波形示意图Fig.1 Deep and shallow water different waveform diagram
2.2 传播
水波能量的积聚是由每个水波在运动过程中不断执行传播操作来完成的.传播前后的水波分别表示为x、x′,原始水波x是通过公式(1)来执行传播操作产生x′的.
xd=xd+rand(-1,1)*λLd,d=1,2,…n
(1)
式(1)中,rand(-1,1)为[-1,1]之间分布的均匀随机数,λ表示水波长度;Ld为搜索空间第d维的长度,且d∈D.在执行传播操作过程中,如果Ld超出了所求问题搜索空间的范围,则将其按公式(2)随机重新设置为搜索空间中的一个新位置.
Ld=lbd+randO*(ubd-lbd)
(2)
式(2)中,lbd为搜索范围第d维的下界,ubd为搜索范围第d维的上界,randO为[0,1]内的随机数.
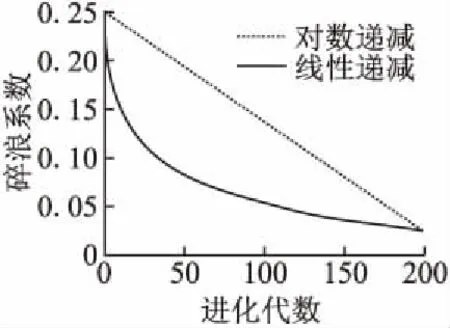
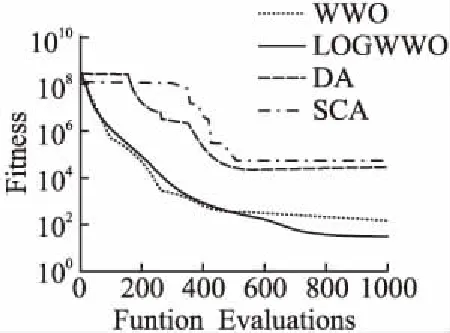
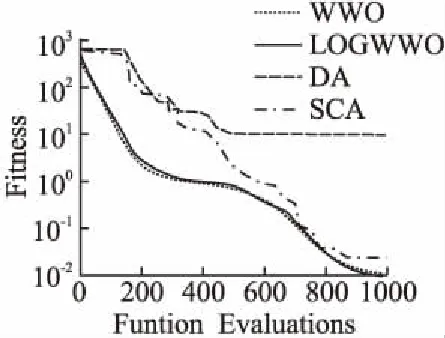
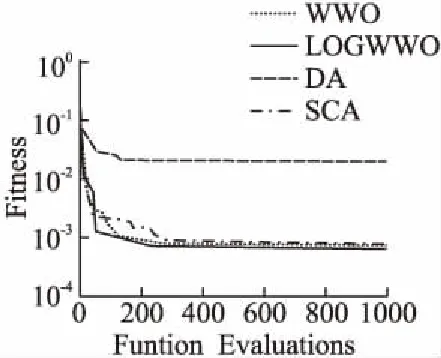
执行传播操作并得到x′后,需要判断f(x)是否大于f(x′),如果f(x) 每次迭代结束时,水波算法都会按公式(3)更新每个水波x的波长. λ=λ·a-(f(x)-fmin+ε)/(fmax-fmin+ε) (3) 式(3)中fmax、fmin分别表示当前水波种群中最大适应度值和最小适应度值,a是波长的衰减系数,ε是为了避免分母为0而设置的一个很小的正数. 随着水波运动过程中能量不断的增加,水波的波峰会变得越来越陡峭,当其速度超过水波传播的速度时会破碎成一连串孤立的水波.当WWO在传播后搜索到最优的解x时,会执行碎浪操作来生成一连串的孤立波来扩充水波种群的多样性.碎浪操作的方式如下:首先随机选择k=[1,kmax],选择的每一维按公式(4)进行搜索得到一个孤立的波x. (4) 式(4)中,β表示碎浪系数,如果在执行碎浪操作之后k个孤立波的适应度值都小于原水波x,则保留x,否则用种群中孤立波的最优解来替代x. 水波在经过若干次传播操作后仍然没有得到改善的情况下,为了模拟其在这一过程中能量的消耗,每次传播过后都会对波高进行减1操作,当波高减为h=0时,为了避免算法搜索的停滞,水波算法会按公式(5)对其进行折射操作: (5) 式(5)中,x*表示当前种群中的最优值,N(μ,σ)均值为μ,标准差为σ的高斯随机数. 折射操作结束之后,其波高重置为h=hmax,并且对水波的波长按公式(6)进行更新: λ=λf(x)/f(x′) (6) 在WWO中,碎浪系数β是用来控制在找到的最优水波附近进行密集搜索孤立波范围的一个重要参数,β越大,则搜索范围越大,反之,搜索范围越小.目前,原始水波算法通常采用碎浪系数β随着迭代次数线性递减的策略,即在算法执行过程中,碎浪系数随着迭代次数的增加而线性递减,虽然这种策略在一定程度上有利于算法搜索精度的提高.但碎浪系数的初始值、最终值和迭代次数一定的情况下,碎浪系数的变化幅度是固定的.因而碎浪系数线性递减策略无法满足算法在前期和后期两个不同时段搜索寻优的需要,无法很好的平衡算法全局和局部探索开发,不利于算法搜索精度的提高. 与原始WWO碎浪系数线性递减策略不同,本文提出的改进水波优化算法的碎浪系数采用对数递减策略,即在WWO执行的前期,以较大的碎浪系数支持算法进行全局搜索,从而获得更加优越的水波;而在算法执行的后期,则以较小的碎浪系数来支持算法进行局部精细化探索开发.以下为碎浪系数对数递减公式: βk=βmax-α(βmax-βmin)×logiterMaxk (7) 式(7)中,α为对数调整因子,0<α<1称其为对数压缩因子,α>1称其为对数膨胀因子. 图2 碎浪系数递减曲线Fig.2 Breaker coefficient decline curve 图3 不同值碎浪系数递减曲线Fig.3 Different values of a breaker coefficient decline curve 图2为对数调整因子α=1,iterMax=200,时碎浪系数β对数递减和线性递减的对比曲线.从图中可以看出,按公式(7)对算法的碎浪系数进行对数递减策略相较线性递减策略而言,前期以较大碎浪系数支持算法进行全局搜索取得最优水波后,随着迭代次数的增加,碎浪系数以较快的迅速下降并进入局部探索;而在算法迭代后期,碎浪系数递减速度逐渐缓慢,这一阶段则以较小的碎浪系数支持算法在局部进行精细开发.上述策略更好的平衡了算法的全局和局部探索能力,从而有利于算法整体性能的提升. 图3为不同对数调整因子下碎浪系数递减曲线,其中,当0<α<1时,碎浪系数β的最终值大于设定的最小值,此时算法进行精细搜索的范围相对上移,即在α=1的初期进行精细化的搜素;而当α>1,β终值小于设定的最小值,算法精细搜索的范围则相对下移,即在α=1时进行相对更加精细的搜索.由此可见,α不同的取值在一定程度上保证了碎浪系数对数递减策略可以使得算法在不同的搜索空间中进行更好的寻优,进一步提高了算法的收敛速度和搜索精度. 综上所述,α值越小,碎浪系数β递减的速度就越慢,从而能更好地适应算法在迭代后期进行精细化局部开发,有利于算法整体性能的提升. 在WWO中,每次迭代结束后,算法会按公式(3)对每个水波的波长进行更新.由公式(3)可知,如果水波所得的适应度值越高,其波长也就越短,相应的其搜索范围就越小,反之则搜索范围越大.由此可知,适应度值较大的水波能更好地进行局部探索,衰减系数a作为水波优化算法波长更新中的一个重要参数,其范围的合理选择对于算法的整体性能具有重要影响.关于怎样合理的设置衰减系数a的范围,文献[8]研究表明,当衰减系数a的范围设为[1.001,1.01]时,水波优化算法所取得的优化效果更好. LOGWWO具体执行步骤如下: Step1.初始化具有n个水波的种群p,并分别计算每个水波的适应度值f(x),找到最优的水波x*. Step2.如果没有满足终止条件,则转到Step 3;否则算法结束,并返回. Step3.对种群中的每个水波x执行以下操作: Step3.1.根据公式(1)进行传播操作; Step3.2.得到一个新的水波x′,如果f(x′)>f(x),转Step 3.2.1;否则转Step 3.3. Step3.2.1.用新的水波x′替代原水波x; Step3.2.2.如果f(x′)>f(x*),根据公式(3)执行碎浪操作,用x′替代x*. Step3.3.将水波的h进行减1操作;如果h=0依据公式(5)、(6)对x进行折射操作. Step3.4.根据公式(3)对所有的水波的波长都进行更新. Step4.对每个水波的适应度f(x)计算,并对最优的水波进行更新,转Step 2. 为了进一步验证LOGWWO的优化效果和稳定性,将LOGWWO、蜻蜓算法(Dragonfly Algorithm,DA)、正余弦算法(Sine Cosine Algorithm,SCA)和原始WWO等四种算法在10个标准测试函数上进行求解函数最优值的对比实验.表1列出了实验中所用到的10个标准测试函数的信息. 在进行算法仿真实验时,参数的合理设置至关重要,算法参数的细微变化都会对其整体性能都会产生一定影响.为了使实验更加公平和客观,本实验将LOGWWO、WWO、DA、SCA的种群规模统一设置为30,各个算法评价次数也都统一设置为1000次;在实验中,每个算法在每个测试函数上独立运行30次.各算法的其它参数设置如下: LOGWWO的波高hmax=12,波长设置为λ=0.5,衰减系数α=1.0026,碎浪系数β最大值设为β=0.25,最小值设为β=0.001. WWO的波长λ=0.5,波高设置为hmax=12,波长衰减系α=1.0026,碎浪系数最大值设为β=0.25,最小值设为β=0.001[8]. DA的惯性权重最大值设为ω=0.9,最小值设为ω=0.4,常数β=0.5[6]. 仿真实验环境如下:处理器为Intel(R)Xeorn3.5GHz,内存为8GB,操作系统为Windows10;所采用的仿真软件为Matlab2012a. 表2列出了LOGWWO以及WWO、DA、SCA等四种算法在10个标准测试函数上经过30次独立运行后所得的实验结果.其中“Max”表示运行30次后所得的函数最大值,“Min”表示寻找到的函数最小值,“Ave”和“Std”分别表示函数经过30次迭代后得到的平均值和标准方差.其中最优的平均值(Ave)和标准差(Std)用粗体显示. 图4~图7为LOGWWO、WWO、DA、SCA等四种算法在标准测试函数f1、f3、f5、f7上搜索函数最优值过程中随迭代次数增加的收敛曲线. 表1 标准测试函数f1-f10Table 1 Standard test functions f1-f10 从表2的实验结果可知,相较其他三种启发式算法,基于自适应参数调整的水波优化算法(LOGWWO)在所测试的10个标准测试函数上对其性能的测试结果具有相对优势.在f1~f5这5个30维的函数测试中,经过30次独立运行后,LOGWWO所获得的函数平均值和标准差在4种算法中都取得了最小值,这充分说明其在函数搜索最优值方面表现出较强的性能. 在进行单峰函数f1测试中,经过30次运行后,LOGWWO在平均值和标准差上都要明显好于DA、SCA和WWO等3种算法,说明LOGWWO具有较高的搜索精度和较好的稳定性能.在对于单峰函数f2进行的测试中,LOGWWO同样也获得了最优的精度值,其获得的平均值和标准差相较其他3种算法同样也为最优. LOGWWO在处理多峰函数优化中同样也表现出了优越的性能,在函数f3测试中,LOGWWO经过30次测试后,相较于其他3种算法,其在函数最小值和平均值两项指标中均获得了最优值,在4种算法中表现出较为明显的优势.由图5可知,LOGWWO在函数f3上寻找最小值过程中具有较快的收敛速度.在多峰函数f4测试中,LOGWWO和WWO在平均值和标准差上相同,但较DA、SCA两种算法,仍然在30次迭代后在函数平均值、标准方差等指标上具有较为明显的优势.函数f5是一个多峰、多局部函数,其在搜索全局最优解时具有一定困难,但LOGWWO在f5测试上经过30次独立运行后所获得的标准方差和平均值相较DA、SCA和WWO等其他三种算法都得到了最优值.由此可知,LOGWWO在多峰、多局部函数上的寻优能力具有一定优势,同时在函数寻优过程中表现出较高的搜索精度和稳定性能. 图4 函数收敛曲线Fig.4 Convergence curve of f1 图5 函数收敛曲线Fig.5 Convergence curve of f3 图6 函数收敛曲线Fig.6 Convergence curve of f5 图7 函数收敛曲线Fig.7 Convergence curve of f7 在f6、f7、f8、f9和f10这5个固定维度多峰函数测试中,相较其他3种算法,LOGWWO也同样表现不俗.其中函数f6是一个固定维度为2的多峰函数,四种算法在f6上运行30次后,在函数标准方差指标上LOGWWO获得了最优值,在平均值指标上,LOGWWO和WWO获得了同样的值,但在平均值和标准差上所得的值比DA、SCA两种算法优.其中函数f7、f10都为固定维度为4维的多峰函数,四种算法在这两个函数上经过30次运行后的结果可以看出,在f7、f10这两个函数上,WWO的优化效果要比LOGWWO略胜一筹,但与SCA、DA两种算法比起来,LOGWWO仍然具有一定的优势.函数f9是维度为6的多峰函数,在函数f9上对四种算法的性能进行测试,实验结果显示,与WWO、DA和SCA等三个算法相比,LOGWWO在30次评价之后所获得的平均值在四种算法中为最优,说明其在收敛精度上要比其它三种算法具有优势;而在标准方差指标上,DA获得最优值,LOGWWO次之.函数f8同样为固定维度为2的多峰函数,LOGWWO、WWO和SCA这三种算法30次运行的平均值相同,在标准方差方面,SCA获得最优值.以上分析结果印证了NFL(NO Free Lunch)定理,并不存在某一种算法是万能的,也不存在一种算法在所有问题优化上都表现出优越的性能这一论断. 通过以上分析可知,在大部分函数优化问题中,改进的自适应参数调整的水波优化算法(LOGWWO)的求解精度和稳定性方面整体优于DA、SCA、WWO等算法.除了在f7和f10两个函数测试上,WWO要略好于LOGWWO;f9函数测试中,DA在标准差上获得最优,LOGWWO次之.LOGWWO在其他测试函数上寻优的标准差都取得了最小值,并且在几个多极值、多局部多峰函数上,LOGWWO依然寻找到了最优的精度值,从而说明LOGWWO具有较好的全局和局部探索寻优性能,并且在函数优化问题上具有较好的鲁棒性. 针对水波优化算法在求解精度方面表现出的不足,本文在对水波优化算法在解决优化问题过程中对控制参数变化进行分析的基础上,提出了一种自适应参数调整的改进策略,即在算法执行的前期以较大的碎浪系数支持算法进行全局搜索,以得到较优的水波;在算法的后期,则以较小的碎浪系数支持算法进行局部精细化探索.改进的水波优化算法通过碎浪系数对数递减策略更好的平衡了算法的全局和局部搜索,从而在整体上提升了算法的搜索精度和收敛速度.水波优化算法作为一种新兴的启发式群体智能算法,尽管已研究证明其在很多优化问题上要比其他几个新型智能算法优越,但其仍然存在一些不足,比如其在局部搜索方面较弱,收敛速度较慢等.所以,如何考虑将其他局部搜索能力强的算法融入到水波优化算法中,来全面提升水波优化算法的性能的研究将是下一步研究的重点.2.3 碎浪
2.4 折射
3 自适应参数调整的水波优化算法
3.1 自适应碎浪系数调整策略

3.2 衰减系数范围选择
4 仿真实验与结果分析
4.1 测试函数
4.2 实验参数设置与实验环境
4.3 实验结果

4.4 实验结果分析

5 总结与展望
