DF-MAP:一种基于概率图模型的案件判决路径挖掘算法
2018-09-07彭敦陆
高 丹,彭敦陆
(上海理工大学 光电信息与计算机工程学院,上海 200093) E-mail:gaodan223@126.com
1 引 言
随着计算机技术的发展以及互联网技术的飞速普及,海量法律文书数据产生.截至2017年3月22日,中国裁判网的文书总量达到27,248,664篇.如何有效地利用这些海量文本数据产生有价值的信息,是信息抽取领域要解决的重要任务之一.
审判事务中,案由确定是人民法院正确审判案件的基础和保障,案由的准确判断直接关系到当事人法律关系的认定以及适用法律的正确选择,一直以来备受社会各界关注.最高人民法院的司法数据表明法院新收、审执结案件数量持续上升:2015年,全国法院新收各类案件17,659,861件,同比上升22.81%,审执结案件16,713,793件,同比上升21.14%.同时,法院编制人员约34万,其中法官人员仅仅19.6万.各项数据意味着:
1)全国法院平均每天处理的案件高达4万多件;
2)“案多人少”成为各国法院的突出矛盾.以上事实均为构建高效的审判服务体系,同时保证立案的准确性提出了巨大的挑战.
针对上述挑战,自然语言处理作为一门实现人机间自然语言通信的学科,为其提供了实现的途径.文献[1]中提出一种短文本自动分类模型,该模型挖掘已有的语义单元进行聚类,在此基础上结合CNN的自动学习能力对短文本进行自动分类;文献[2]中作者深度剖析Tweet网站的领域特征,基于斯坦福CoreNLP与POS工具,运用规则增强解析能力与语料库,实现tweet的关键词自动抽取.这些研究表明,人工智能与计算机技术的结合在文本信息自动挖掘方面具有重要的应用价值.受上述研究的启发,论文试图通过对海量历史法律文书进行深入分析,提取案情描述关键词与适用法律中隐藏的规则集合,并基于Rete算法构建Rete-PGM(Probability Graph Model Based on Rete Algorithm).在此基础上,提出算法DF-MAP(Deep First Max A Posterior)对法律文书进行高效的判决路径挖掘过程.
在提取规则集合时,本文试图采用概率图模型的相关理论来研究不同关键词组合与适用法律同时出现的概率,并准确描述它们之间的逻辑关系.概率图模型是一类用图模式表达基于概率相关关系的模型总称,包含概率图模型表示理论,概率图模型推理理论和概率图模型学习理论三部分[8].目前,基于概率图的推理模型主要有4种:贝叶斯网络、马尔科夫网络、混合网络、动态贝叶斯网.在此基础上,论文提出了基于Rete算法的概率图模型—Rete-PGM.Rete-PGM不仅反映了每条适用法律中包含的司法解释与量刑标准,而且还描述了特定案件中隐含的判决路径的概率分布.利用提出的DF-MAP算法对Rete-PGM进行最大可能路径的挖掘,最终实现案件判决路径的挖掘.
文章剩余部分组织如下:第二部分介绍Rete算法的相关研究工作;第三部分给出问题描述及法律文书数据的预处理过程;第四部分基于Rete算法构建概率图模型Rete-PGM,并对案件判决路径挖掘算法DF-MAP进行详细描述;第五部分通过实验对所提算法进行有效性验证;第六部分是论文的结论.
2 相关工作
Rete算法与Treat算法是最好的两个规则匹配算法[3],本文引用Rete算法的匹配原则对各项法律法规的规则进行抽取.1974年,Charles L Forgy在工作论文[4]中首次提及Rete算法,并相继在1979年的博士论文[5]、1982年发表的论文[6]中详细描述并部署Rete算法.除此之外,Forgy还提出Rete-II,Rete-III,Rete-NT等变种算法对Rete算法进行完善,不仅提升了Rete算法的匹配效率,而且被应用与各种推理引擎中.
作为针对基于规则知识表现的高效模式匹配算法之一,Rete算法是对一系列元组数据(Facts)匹配规则集(Rules)的过程描述.Rete算法的匹配过程由表示系统当前状态的事实库(Working Memory,WM)和表示一系列规则集合的规则库(Production Memory,PM)组成.其中,WM中每一个工作单元被称为Working Memory Element(WME),由一个三元组表示:(identfier^attributevalue),表示将要被处理的数据.例如,w1:(B1^onB2)中的B1为identfier,on为attribute,B2为value.PM的每一条规则由LHS(Left-Hand Side)与RHS(Right-Hand Side)两部分构成:LHS:使用逻辑符号and或or连接多个条件(Conditions),表示一条规则的条件前提;RHS:由一系列动作(Actions)组成,表示一条规则的结论部分.
Rete算法的匹配过程就是决定系统中当前WM匹配哪一条规则,以及该WM中哪些WMEs匹配对应条件的过程.Rete算法利用一个由alpha网络、beta网络构成的数据流网络对该匹配过程进行描述.alpha网络的功能是利用alphamemories(AMs)存储符合模板的所有WMEs,并根据规则对其进行过滤,筛选出符合这条规则的模式集合.其中,模板(Pattern)表示事实(Fact)的一个抽象模型,每一个WME都必须满足模板库中的一个模板.beta网络则由Join Node和Beta Memory组成:Join Node对当前两个WME进行匹配筛选操作,而Beta Memory则对当前完成匹配过程并满足条件的WMEs进行存储.
迄今,众多学术研究都对Rete算法做出了不同程度的描述,并结合不同的技术应用于不同领域.譬如,在自然语言处理领域中,Rete算法针对特定的词汇与语料库产生了一系列监督式规则以提高提取关键词等任务的速度[7].本文试图基于Rete算法,引入概率图模型的相关理论来解决案情特征多样性问题,并完成法律文书的判决路径挖掘任务.论文中,首先分析并求解案情描述的关键词与适用法律规则同时出现的概率关系,并使用提出的Rete-PGM来描述这种关系.然后,针对Rete-PGM图集合,论文结合最大后验概率(Max A Posterior,MAP)[9]查询思想,提出DF-MAP (Deep First Based on Max A Posterior)算法,对案件的判决路径进行挖掘.最后,在真实的海量法律文书数据集上进行实验,很好的验证了所提算法的有效性.
3 数据预处理
本小节首先给出案件判决路径挖掘任务的问题描述,再介绍法律文书数据的预处理过程,以便后续章节的模型计算.3.1节对问题进行描述,提出Rete-PGM的概念;3.2节基于Rete算法思想,对现有的各项法律法规进行规则集合进行抽取;3.3节提取法律文书数据中案情描述关键词及适用法律集合.
3.1 问题描述
事实:在法律条规中,影响量刑范围的事实、行为,被称为“事实”,记为f.
动作:法律条规中的量刑结果被称为“动作”,记为a.
例如,交通肇事罪中,“死亡一人以上,负事故主要责任的,处三年以下有期徒刑或者拘役”,其中“死亡一人”、“负同等责任”为事实,“三年以下有期徒刑”、“拘役”为动作.
定义1.法律规则是由若干事实f以及相应的动作a构成的序列,记为p=[f1,f2,…,fn,a].案件判决路径挖掘过程被描述为求解最有可能的法律规则的过程.
通常,法律文书的正文部分包括:案件事实、证据;立案理由、依据两部分.其中,立案理由及依据必须满足以下条件:准确概括犯罪性质、认定罪名及犯罪情节;准确引用法律;准确阐明定罪处罚的倾向意见;程式化写明起诉决定.案件事实应当根据具体案件情况叙写,同时,分列相关证据.立案理由与依据则需要法官对案情描述进行分析,综合考虑各项相关法律条文,给出准确的罪名及依据.通常,尽管海量历史法律文书的案情描述细节存在差异性,但案件判决路径却相差无几.因此,论文通过深入挖掘海量历史法律文书的正文部分,基于Rete算法,引入概率图模型,构建Rete-PGM.再结合所提算法DF-MAP,对特定的案件进行判决路径进行挖掘.
基于Rete算法抽取的实体法与程序法中蕴涵的规则集合,构成一个由alpha网络与beta网络组成的有向图;同时,从法律文书的案情描述中提取的关键词直接影响到适用法律规则的选取,并且存在概率联系.这里,用概率图表示关键词集合与规则集合的组合关系,称之为Rete-PGM.
Rete-PGM:由网络结构G=(WMES,E)与参数模型P两部分构成.WMES为顶点集,由若干法律规则的事实、动作组成;E为有向边集,表示两个顶点之间的概率关系.P是网络结构G的概率分布模型,通过计算海量历史法律文书中案情描述关键词集合中每一个关键词分别与每一条规则中的事实、动作共同出现的概率关系解得.
在Rete-PGM中,若两个WMEA和B之间存在一条通路,表示A和B是串行组合关系,遵循顺序匹配原则,若不存在,则表示A和B之间是并行组合关系,不存在数据匹配过程.图2是一个案件文本的Rete-PGM示例图.在图2的网络结构G中,“死亡一人”和“重伤三人”为开始顶点,也是并行组合关系,而“死亡一人”、“主要责任”以及结束顶点“有期徒刑”之间则是串行组合关系,所有的节点组合在一起是混合组合关系,共同构成了一份法律文书的Rete-PGM的网络结构G.为了使网络结构G能够更好地刻画适用法律规则集合,经深入分析海量历史案件文书发现Rete-PGM中网络结构具有如下的特点:
1)顶点互异性:在同一个Rete-PGM中不会出现两个完全相同的事实、动作.
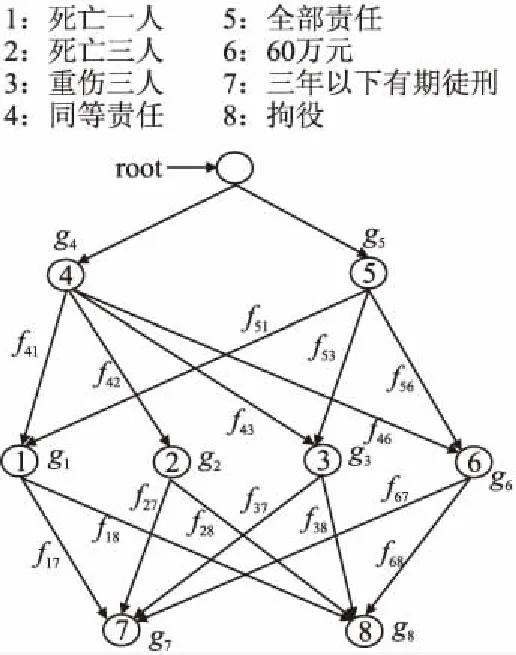
图2 Rete-PGM示意图Fig.2 Example of Rete-PGM
2)若干开始顶点和结束顶点:一个Rete-PGM的开始点是指入度为0的顶点,开始顶点对应于规则集中可以用于首个匹配的事实集合,由适用法律包含的量刑标准中变量个数决定.结束顶点是指出度为0的顶点,结束顶点对应整个规则集中的动作集合,由适用法律中包含的刑罚类别决定.
3)任意开始顶点到结束顶点之间必连通,即存在通路:一个Rete-PGM中,开始顶点与结束顶点之间必然存在一条通路,且这条通路对应法律规则库中的一条规则.
3.2 法律规则提取
结合全国人民代表大会制定的刑法及全国人民代表大会常委会先后出台的九个刑法修正案,至今刑法的罪名种类分为10大类,共468个.在实体法及程序法中,每条法律均可以被细分到款、项.在此,论文运用Rete算法抽取各项条款中的规则,形成规则库,便于获取单个案件文档中适用法律规则.对468个罪名的所有相关法律以及司法解释、量刑标准进行规则抽取,共获得8603条规则,构成规则库R={r1,r2,…,rn},n为规则库中规则的数目.以《最高人民法院关于审理交通肇事刑事案件具体应用法律若干问题的解释》第二条第一款第(一)项的具体内容:“死亡一人或者重伤三人以上,负事故全部或者主要责任的,处三年以下有期徒刑或者拘役”为例,抽取的规则使用Rete数据流网络表示如图1所示.图1中,右图给出上述法律条款的所有模板规则集合P1、P2,左图则给出了P1的具体匹配过程.


图3 法律文书预处理过程
Fig.3 Preprocess of law case filies
3.3 关键词与适用法律抽取
利用关键词提取技术,可以自动地选择一个小特征项集对案情细节进行概括.目前,针对关键词提取技术的研究已经取得较多的研究成果,如TF-IDF[10],LDA[11],Text-Rank[12],Rake[13].论文应用HanLP自然语言处理包对案情描述部分进行关键词抽取,即Text-Rank方法.
算法1(图3)详细描述了法律文书中案情描述关键词与适用法律集合的抽取过程.第1行建立空集合HK,HL分别用来存储案情描述关键字、适用法律.2-9行依次遍历所有文件抽取关键字及适用法律:第3行函数getDocContext()根据文件名获取案件文书的内容,并存储为字符串格式;第4-5行利用HandLP工具抽取案情描述关键字;6-7行运用准确的正则表达式对适用法律进行抽取;第8行将关键字与适用法律分别存入对应的HashMap集合中.
4 Rete-PGM与案件判决路径挖掘算法DF-MAP
第3节详细阐述了法律文书数据的预处理及适用法律规则库生成过程,本小节重点讨论案件判决路径的挖掘过程.首先基于Rete算法、概率图模型建立Rete-PGM;然后结合最大后验概率(Max A Posterior,MAP)推理思想,提出算法DF-MAP对案件判决路径进行挖掘.
4.1 Rete-PGM
概率图模型利用网络结构中变量的独立性,将高维联合概率分布为节点上低维概率分布的乘积.在此,论文首先分析法律规则库,获取事实、动作之间的条件概率分布,再结合案情描述关键词与使用法律规则同时出现的概率,就可以解得Rete-PGM的参数模型.因此,Rete-PGM的参数模型包含两种概率值:顶点WME本身具有的概率值,记为g;边e∈E的概率值,记为f.
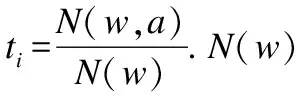




图4 顶点结构
Fig.3 Structure of node
本文采用邻接表结构对Rete-PGM进行存储,如图4所示.data存储顶点;pro表示顶点本身的概率值g;next为指向第一个邻接点的指针,默认值为null.f为指向该邻接点的概率值,初始值为0.


图5 Rete-PGM构建过程
Fig.5 Construction of Rete-PGM

图6 DF-MAP算法
Fig.6 Algorithm of DF-MAP
算法2(图5)详细描述了构建一篇法律文书的Rete-PGM过程.算法前两行完成初始化:第1行通HK,HL过获取关键字与适用法律集合K,L,第2行初始化Rete-PGM的邻接表G为空集.第3行利用createReteNetwork()函数将适用法律转换成Rete网络结构.4-15行依次遍历Rete网络的模板pattern,构建Rete-PGM的网络结构:第5行completeMathes()进行匹配,得到WMEs与Actions列表;第8-13行判断是否该WME存在于邻接链表中,若不存在则创建顶点,并填充数据保存到邻接表中;否则,第13行获取顶点,并指向下一个WME.最后,16-18行根据定义5更新Rete-PGM中每条边的概率.
4.2 DF-MAP算法
结合前文描述的Rete-PGM 的特点,运用MAP推理思想,提出适用于Rete-PGM的案件判决路径挖掘算法—DF-MAP算法.在DF-MAP算法中,案件判决路径挖掘的基本思想是查找开始顶点到结束顶点的关键路径,即寻找一条概率值最大(最有可能)的通路.图6给出了DF-MAP算法的描述.算法可分为两部分:寻找Rete-PGM中开始节点到结束节点的所有连通路径(2-5行)和应用MAP概率计算公式求解概率值最大的路径(6-11行).
5 实验与分析
5.1 数据采集
实验在两个数据集上进行:真实数据集和模拟数据集.真实数据集是来自中国裁判网的一审刑事法律文书,共计13,853,580个文件.模拟数据是根据Rete-PGM特征随机产生的10,000个模拟的Rete-PGM,包含300种概率值最大的路径模式,为了验证所提算法对复杂的Rete-PGM查询也有较好的计算效果,每个模拟Rete-PGM中开始顶点数和结束顶点数在4-11之间,中间结点在30-50之间,而真实数据集中的开始顶点数和结束顶点数一般在3-8个.同时,论文根据算法1对真实的法律文书数据集进行了预处理,剔除无关信息,只保留了案情描述与适用法律部分,以便于计算.
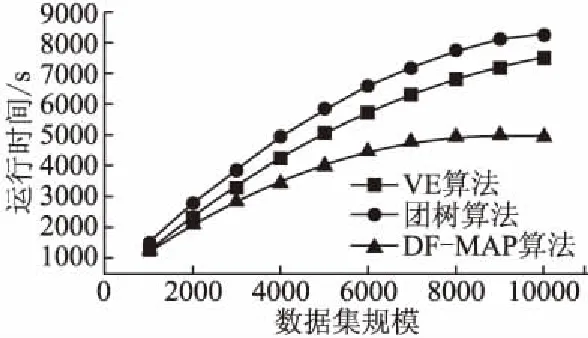
图7 不同数据集规模下算法的运行时间比较Fig.7 Different algorithms runtime vs.data set

图8 不同数据集规模下算法的F1-measure值比较Fig.8 F1-measure in different algorithms vs.data set

图9 不同关键词数目下的案件判决路径的挖掘结果比较Fig.9 Case decision path mining in DF-MAP vs.key word number
5.2 实验结果与分析
第1组:考察DF-MAP算法的计算性能
实验1 验证DF-MAP算法的运行效率.图7中显示了算法VE算法[14]、团树算法[15]和DF-MAP在数据集规模不同的情况下,寻找最大概率值路径所需要的运行时间.在数据集规模较小的情况下,相对其它两种算法,算法DF-MAP在较短的时间内找到最优路径.随着数据的增加,每个算法运行时间的上升趋势逐渐减缓,这是因为随着数据集规模的增加,概率值最大的路径模式增长减少,意味着需要的计算量也明显减少.
实验2 验证DF-MAP算法的挖掘结果的有效性.图8显示了三个算法在数据集规模不同下寻找最大概率值路径的结果.文献[14,15]显示,VE算法和团树算法能够求解变量集的最有可能取值,而算法DF-MAP发现的结果与它们近乎相同.由此,可以认为DF-MAP算法能够有效地挖掘Rete-PGM中的最有可能的案件判决路径.
第2组:在真实数据集上实现案件判决路径的挖掘
上述两个实验结果表明,DF-MAP算法在保证挖掘结果有效性的基础上,较其它两个算法能够更高效地实现对最有可能的案件判决路径挖掘.下面,将所提算法运用到真实的法律文书数据集上进行案件判决路径挖掘,并对挖掘结果进行分析.从下述两个方面对所提算法DF-MAP进行考察:
实验3考察在相同数据集规模下,案情描述的关键词个数的变化对案件判决路径挖掘结果的影响.已知在真实的法律文书数据集中,案情描述关键词的选取对适用法律的选取具有决定性作用,关键词数目太少无法完整而准确地总结案情描述的细节,而关键词数目太多则降低算法的效率.实验中对关键词数目在5-11之间取不同的值进行测试.图9中,折线图和柱状图分别显示了使用不同关键词数目对案情进行描述的情况下,案件判决路径挖掘过程的运行时间与挖掘结果的准确率、召回率、F1值.柱状图的结果显示,关键词数目从5-7变化时,三个指标值逐渐提升,而当其大于8后,三个指标值则趋于平缓,反映了8个或8个以上的关键词对案情描述部分能够较为充分的对案情进行描述.同时随着关键词数目的增加,算法DF-MAP的运行时间逐渐上升,但上升的趋势逐渐缓慢.对比图9,可以发现选取8个或8个以上关键词时案件判决路径挖掘效果较好,既能保证挖掘结果有较高的准确率、召回率,又能保证运行时间较低.在实际应用中,可结合实际需要来选择关键词数目.

图10 不同类别法律文书的判决路径挖掘结果比较Fig.10 Case decision path mining in different kind of case files
实验4 考查在相同数据集规模下,算法DF-MAP挖掘不同类别的法律文书数据集的结果分布情况.图11给出的实验结果显示,所提算法DF-MAP针对10个类别的法律文书数据集的案件判决路径挖掘效果存在过大或过小的差异.其中,“破坏社会主义市场经济秩序罪”、“渎职罪”的三个评估值都较低,这反映了其成因的复杂性,导致DF-MAP的挖掘结果缺乏准确性.同时,“危害国家安全罪”、“侵犯财产罪”、“妨害社会管理秩序罪”等类别的法律文书的挖掘结果的准确度均接近74%,这反映了这些类别的案件具有明确、清晰的社会构成因素.由此可见DF-MAP算法的案件判决路径挖掘具有良好的效果.
6 总 结
构建高效的案件判决路径挖掘应用不仅能够为法官提供可参考的法律文书,而且有利于解决法院“案多人少”的困境.基于Rete算法的概率图模型Rete-PGM充分反映了适用法律规则模式,同时形象地描述了案情描述关键词组合与适用法律之间的概率关系.在此基础上,提出了案件判决路径挖掘算法—DF-MAP算法,并将所提算法应用于真实的海量历史法律文书数据集上,最终实现了对指定案情描述的案件判决路径挖掘过程.此外,所提图模型Rete-PGM还可以作为案情描述中关键词选取的依据.因此,在下一步的工作中,将首先对法律规则集的自动化抽取方法进行研究;再结合Rete-PGM实现案情描述关键词更加准确地提取过程.
