基于因子分解的语音转换研究
2018-08-31魏子怡
魏子怡
(山东省潍坊第一中学,山东 潍坊 261000)
0 引言
语音识别是为一门新兴的交叉性学科,2011年8月微软亚洲研究院通过引入DNN以后,语音识别准确率得到大幅提高,进入飞速发展时期。
语音识别最初发展时期采用语音模型的方法进行识别,已经能够实现初步的说话内容识别。例如云知声、百度(度秘)和苹果(Siri)等均能实现语音层面的在线人机交互;语种识别与说话人识别技术也已提出,目前已投入使用。
语音识别领域已显示出强劲的生命力,其中语音转换技术仍处于科技前沿,是一项创新性的科研项目,本实验将因子分解方法应用在此领域,可解开语言交流的神秘面纱,使生活发生翻天覆地的变化。
1 背景知识介绍
1.1 Kaldi介绍
当下的音频主要通过录音软件,以一定的频率对模拟信号进行采样、编码,将模拟信号通过数模转换器转换为数字信号,并进行一定的压缩后进行存储,得到音频的波形图,而电脑无法对波形图进行进一步的处理,必须转成向量中的数值形式的信息才能进一步处理。因此,需要利用Kaldi工具,将波形图转化为声谱图,声谱图以热图的形式将时间、频率、声音强度(数值用颜色的深浅加以呈现)展现到矩阵当中。
1.2 深度神经网络(DNN)的发展
神经网络是利用计算机模拟人脑思考过程对事物进行聚类与分类的一种算法,电脑可以按照事先设定好的聚类与分类层对所输入的事物进行分类。 神经网络中单个节点的工作原理是将输入数据与权重之积的和输入给激活函数,判断信息是否能在节点中继续运行。
传统的机器学习系统主要使用浅层神经网络。当一个神经网络拥有3层以上的系统时,就可成为深度神经网络。人脑的认知过程是一个深度多层的复杂过程,每深入一层就多一层抽象,深度神经网络使计算机能够更精确地模拟人脑的深度思考过程。
2 研究语音转换的目的及意义
2.1 语音转换的目的
从古到今人们为了更好地生存,产生了蕴含信息由少到多,表达清晰度由低到高的交流方式,其中口语更加多变——人体发声时,因为声道各部结构不同,导致音色因人而异;气流通过声道时也会因摩擦而产生噪声,胸腔和头部也会产生共振,对音色产生影响。
声音无论怎样千差万别,总离不开个性音色、表达内容和情感3个要素,而因子分解的方法恰好将音频分解为以上3部分。于是作者立即考虑到,因子分解方法的提出恰恰是为语音转换领域提供了一个全新的思路,若将这一方法应用于此,将是语音识别领域的一大可贺突破。
2.2 语音转换的军事及娱乐意义
身份识别技术广泛地存在于生活中,例如:密码登录技术、中国三代身份证的指纹验证技术、DNA检测技术,以及虹膜识别技术等。语音蕴含着丰富的身份信息,相应的语音识别技术也迅速崛起,音频加密方法逐渐被攻破。因此,针对语音识别技术的保密工作也应该得到重视。而通过语音转换可实现说话人身份的更改,从而可以保障重要人员的人身安全。
目前市场上有很多变声软件,如腾讯QQ的变声模块以及手机魔音变声,但方法简单,变声后的声音失真,而且要想真正模拟一个人的音色很难实现。若成功实现语音转换,换声的设想就能实现,其娱乐色彩也就更加浓厚。
3 语音转换的研究方法
3.1 传统的研究方法
以往语音转换的研究主要对音频信号进行直接处理,例如改变音频的播放速度,进而改变声音频率及波长;或通过改变声音的相位与共振峰信息以及将音频的高频降低、低频升高来改变音色。随后发展出语音模型、频谱弯曲与单元挑选的方法。但以上方法大都保留了音频的完整性,未能深一层次地触及语音的本质特点。
3.2 本实验的研究方法
本实验前期主要通过国内外期刊论文对关键技术的研究进展、理论基础和现实背景进行了解,寻找独特的研究视角来查找数据。最终,本论文借鉴了清华大学CSLT实验室发表的一篇关于“语音信号关于因子分解”的文章。
将因子分解方法应用于语音转换将带来一个全新的视角。其透彻直观地将音频划分为三大部分:能表达说话人特征的Peaker部分、传达交流内容的Phone部分、与交流的语境相关的Emotion部分,只要将语音以以上三部分呈现,便可随心所欲地转换。如将说话人1的Speaker部分替换为说话人2的Speaker部分。
因子分解不仅可以实现身份的转换,还可以进一步实现先前未曾有的内容转换、情感转换,其在语音转换领域的应用是一个里程碑式的创新。
4 语音转换实验
4.1 实验原理介绍
4.1.1 傅里叶变换(Fourier Transform简称FT)
当得到一个波形图的函数表达式X(t)时,可通过傅里叶变换:
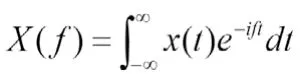
将频域的频谱图的函数表达式X(f)表示成X(t)的积分的形式,从而得到频谱图。
若将频谱图函数表达式转化回波形图函数表达式,则需要用到傅里叶变换逆变换(Inverse Fourier Transform简称IFT):
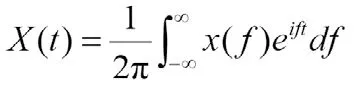
4.1.2 短时傅里叶变换(STFT)
通过傅里叶变换得到的频谱图不具有时间轴,无法反映出音频随时间的变化,所以无法分析语音。欲得到音频的变化与时间的关系,则需要使用短时傅里叶变换。
首先规定矩形窗口函数ω(t),ω(-t)=ω(t),在波形图函数表达式上截取音频,窗口函数可移动截取,移动后的窗口函数记为ω(t-τ),得到采样信号x′(t,τ)=x(t)ω(t-τ).再对采样信号进行傅里叶变换,得到此段波形图函数表达式的频谱图。像这般对整个波形图函数表达式进行小时段的分割,继而进行傅里叶变换,成为短时傅里叶变换(图1)。
随后将采样信号函数表达成积分形式
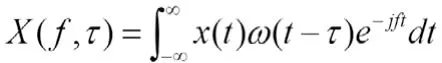
由于t与τ同样可以表示出音频随时间的变化,于是将X(f,τ)中的τ替换为t,X(f,t)为时频图的函数表达式

再利用短时傅里叶变换逆变换
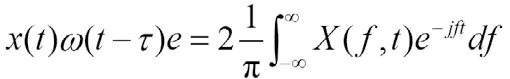
可将时频图函数表达式转换为波形图函数表达式。
4.1.3 深度神经网络因子分解
利用Kaldi工具将波形图转化为声谱图后,需要利用深度神经网络进行因子分解。
深度神经网络进行因子分解时,识别出的Phone谱作为下一层的输入信息,分离出的Speaker谱再与Phone谱一同作为输入信息输入,分理出Emotion谱。此图中的ASR,SRE,AER分别是系统的简化形式,ASR(automatic speech recognition)代表自动说话人识别系统,SRE(speaker recognition)代表说话人识别系统,AER(automatic emotion recognition)代表自动情感识别系统。
将分离的3个声谱图重新组合(图2),利用公式In(x)=In{f(q)}+In{g(s)}+In{h(e)}+e,将三个谱相加得到新的谱,即可得到一个恢复的声谱图。
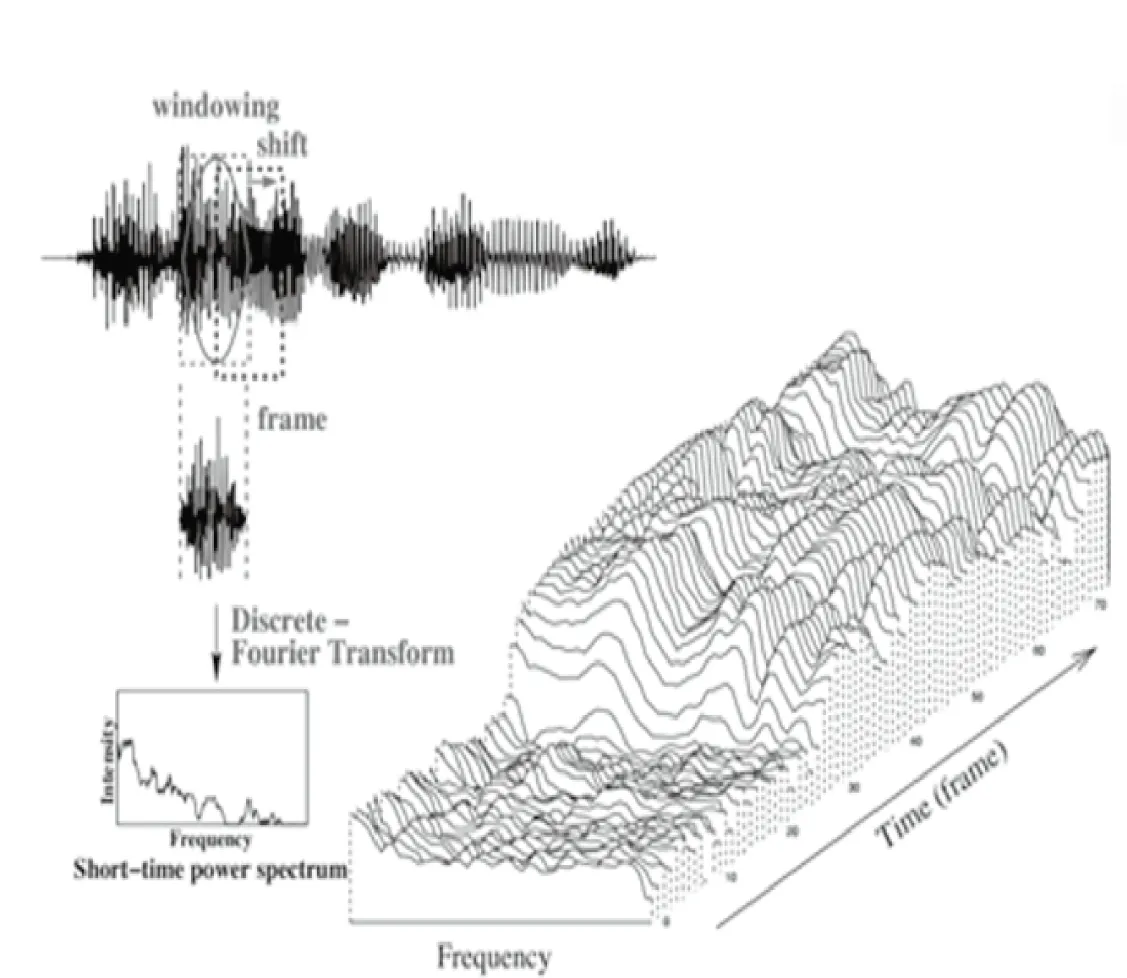
图1 短时傅里叶变换(右下角为时频图)
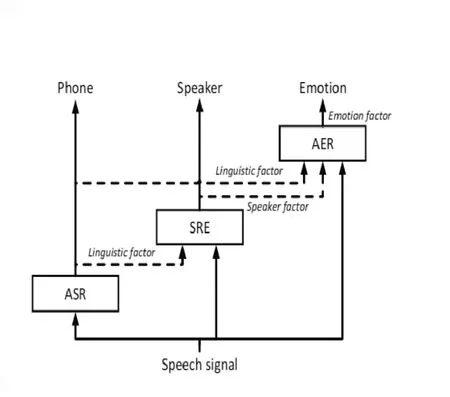
图2 深度神经网络分离Phone、Speaker、Emotion谱
4.2 实验介绍
利用Kaldi工具将音频文件转换为声谱图,再利用深度神经网络将其分离为Speaker谱、Phone谱和Emotion谱。
然后利用Python代码提取语音信号的幅度谱和相位谱,在Python读取Speaker1,Phone2 和Emotion2的数据,分别存档于矩阵ss1,ss2和ss3,分别标记为metrix_speaker,metrix_phone和metrix_emotion,并将其和标记为metrix,即metrix=ss1+ss2+ss3,最后将其转换为音频文件。
4.3 实验结果及分析
本实验探究了基于因子分解的语音转换实验。利用深度神经网络分离出3个声谱图时,由于提取特征时丢掉了一些无关特征,这样影响到还原的音频有一定的杂音,其中的权值参数或许仍需进一步进行调整,但本次试验的整体效果比较理想,创新性地将新方法应用到了语音转换领域。
除此之外,本实验将3个谱重组时,Speaker谱与Phone谱有一定的粘连关系,特征与说话人1还是说话人2有关主要与Phone谱来自说话人1还是2有关,为解决该问题,接下来需要再多做几组实验,调节其中的一些参数,进而达到一个完美的效果。
结论
作为因子分解方法的创新性应用实验,本实验结果非常可观。虽然仍有需要改进之处,但是本实验走出了语音识别领域的突破性的一步,结果的优化目前来看只是时间问题。接下来需要做的是通过深度学习继续调整实验中的参数,重复几组不同的实验:如相同性别的说话人、情绪相近的说话人等,挑战细微差别下的语音转换。
